Amazon Web Services ブログ
AWS を活用した小売業の需要予測
小売業者は、需要予測を使用して顧客のニーズを予測し、供給の意思決定を最適化します。 ほとんどの業界と同様に、小売業界の需要予測では、大量の履歴データを使用して将来の消費者需要を予測します。 これらの予測は、季節性、プロモーション、在庫レベル、市場動向など、需要に影響を与える変数の分析に基づいています。 予測精度は、モデルの複雑さと大量のデータを処理するモデルの性能に影響されます。
機械学習 (ML) を使用すると、ML が処理できる小売データのサイズと種類が多種多様であるため、予測の精度が向上することが示されており、小売データに固有のこれらの課題に対処するのにも役立ちます。
多くの小売業者は、需要予測の精度を向上させるためにMLによる予測手法を導入したいと思っています。機械学習の反復プロセスを需要予測に使用することで、顧客は在庫コストを削減し、収益を増やすことができます。 MLは、在庫とサプライチェーンの運用を最適化することで商品の価格を下げます。
しかし、MLベースの需要予測を小売業者が採用することには課題があります。 データソースと品質が不十分であること、モデルチューニングに多大な時間とリソースが必要であること、データサイエンスの専門知識が不足していること、その他の組織上および技術上の課題が含まれます。
アマゾンウェブサービス(AWS)は、データの取り込みから複雑なモデリング、デプロイ、大規模な推論まで、ML プロジェクトのライフサイクル全体を処理できる最も包括的な一連のサービスを提供しています。 小売業界は変化しており、利用できるデータポイントがかつてないほど増えているため、需要予測はデファクトスタンダードとなっています。 このブログでは、小売業者が AWS サービスを使用して需要予測を行う方法について説明します。
リファレンスアーキテクチャ
需要予測は多段階のプロセスであり、各ステップには個別の目的があります。 下の図は、ライフサイクルをデータの取り込みからモデルのデプロイまで、8 つのフェーズに分けて示しています。
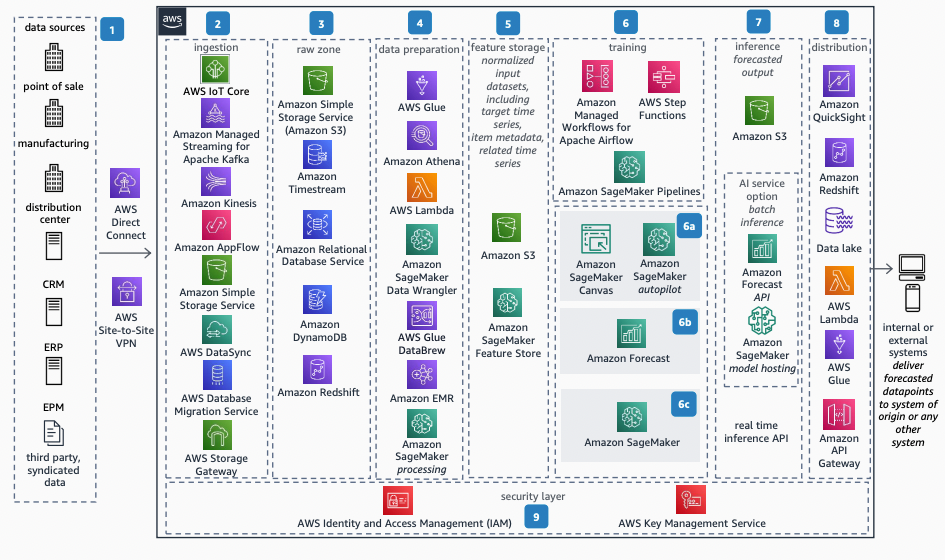
それぞれのフェーズは、プロセス全体において特徴的な役割を担っています。詳しく見ていきましょう。
アーキテクチャの説明
1. データソース
予測は過去と現在のデータについて信頼できる情報源に大きく依存しています。 これらのソースにはさまざまな形式(JSON、XML、構造化ログなど)があり、小売店、製造・配送センター、顧客関係管理(CRM)、エンタープライズリソースプランニング(ERP)、エンタープライズパフォーマンス管理(EPM)、製品ベンダーや物流パートナーなどのサードパーティシステムなど、さまざまなソースから取得できます。 クラウド内のイベントによってデータが生成される場合、エンドポイント間の接続オプションはさまざまです。 ハイブリッド環境では、AWS への専用ネットワーク接続を確立するために使用できる AWS Direct Connect、データセンターまたは支店と AWS リソース間の安全な接続を確立するフルマネージドサービスである AWS Site-to-Site VPN、またはインターネットを介したダイレクトで安全な転送など、オンプレミスのインフラストラクチャをクラウドに接続するオプションがあります。
入力データの構成は以下のようになります。
- 時系列データ—小売需要予測のユースケースにおいて過去の時系列データには、item_id、timestamp、ターゲットフィールドとなるdemand(販売履歴)を含めることができます。
- 関連時系列データセット — 関連時系列データセットには、ターゲットの時系列データセットには無い時系列データが含まれているため、ユーザーの予測子の精度が向上する可能性があります(プロモーション、営業日、営業時間、商品の在庫状況など)。
- 項目メタデータ — ターゲットの時系列データセット内のアイテムに関する有益なコンテキストを提供するカテゴリーデータが含まれます(色、種類など)。
- その他のデータ—これには、位置情報、タイムゾーンなどの他のデータが含まれます。市場分析の傾向などの第三者情報も含まれる場合があります。
2. データ取り込み
小売業者のニーズに応じて、AWS クラウドはデータをバッチ、またはニアリアルタイムで取り込むのに役立つ複数のサービスを提供します。 ストリーミングデータに適したサービスの一例として、ニアリアルタイムのストリーミングデータを簡単に収集、処理、分析できる Amazon Kinesis があります。また、ユーザーが何十億ものモノのインターネット (IoT) デバイスを接続し、何兆ものメッセージを AWS サービスにルーティングできる AWS IoT Core は IoT デバイスに適しています。 お客様は、マネージド型の移行およびレプリケーションサービスである AWS Database Migration Service (AWS DMS) を使用して、既存のデータベースからデータを取得できます。 オンプレミス環境からの移行には、セキュアなデータ移行を簡素化・高速化する AWS DataSync や、ハイブリッドクラウドストレージサービスの AWS Storage Gateway を利用することが可能です。加えて、お客様は Amazon S3 コマンドラインインターフェイス (CLI) コマンド、API、またはコンソールを使用して、オブジェクトストレージサービスである Amazon Simple Storage Service (Amazon S3) にデータをアップロードできます。 お客様は、SAP と Salesforce 向けのフルマネージドのインテグレーションサービスである Amazon AppFlow を利用することもできます。
3. 未加工ゾーン
取り込まれたデータは、中間のステージング/ランディングエリアまたは未加工ゾーンに保存できます。 次のようなデータストアが過去およびニアリアルタイムの時系列データ、項目メタデータ、および関連時系列データ用の未加工ゾーンを提供します。
- Amazon S3
- Amazon Timestream は高速でスケーラブルなサーバーレスの時系列データベースサービスです。
- Amazon Relational Database Service (Amazon RDS) はマネージドサービスの集合です。
- Amazon DynamoDB はフルマネージド型のサーバーレスのキーバリュー型 NoSQL データベースです。
- Amazon Redshift はSQL を使用して構造化データおよび半構造化データを分析します。
お客様はデータレイクを未加工ゾーンとして使用できます。
4. データ準備
データ準備、すなわちデータ前処理は、データサイエンティストやアナリストが ML アルゴリズムを実行して洞察を見つけたり、予測を行ったりできるように、未加工データを変換するプロセスです。 この段階では、サイエンティストやアナリストはさまざまなソースからデータを選択してクエリし、クレンジングして探索し、外れ値や統計的偏りがないか確認し、データを可視化し、データを分析して特徴量の重要性を特定し、特徴量エンジニアリングを行い、最後に ML モデルに使用できる形式でデータをエクスポートできます。 この段階では、ML 用のデータをすばやく簡単に準備できる Amazon SageMaker Data Wrangler がローコード/ノーコードのオプションとなります。 Amazon SageMaker Data Wrangler を使用すると、ユーザーは Amazon S3や、ペタバイト規模のデータを分析する Amazon Athena、Amazon Redshift、安全なデータレイクを簡単に作成できる AWS Lake Formation、AWS パートナーの Snowflake、Databricks のソリューションなど、複数のデータソースからデータをすばやく選択できます。
その後、ユーザーは 300 種類以上の事前設定済みデータ変換を使用してデータを変換し、データを探索して可視化できます。 もう 1 つのローコードオプションとして AWS Glue DataBrew があります。これは、MLに備えるためのデータのクリーンアップと正規化に役立つビジュアルデータ準備ツールを提供します。上級ユーザーは、ペタバイト規模のデータ処理のためのクラウド上のビッグデータソリューションである Amazon EMR と、データ変換と特徴量エンジニアリングの高度なオプションであるProcessingジョブに Amazon SageMaker (ML モデルの構築、トレーニング、デプロイが可能) を使用できます。 サーバーレスのデータ統合サービスである AWS Glue は、データのフィルタリング、集約、加工にも使用できます。 データが複数のリレーショナルデータソースと非リレーショナルデータソースにある場合、Amazon Athena を使用して、複数のリレーショナル、非リレーショナル、オブジェクト、およびカスタムデータソースに対してフェデレーションクエリを実行できます。 サーバーレスのイベント駆動型コンピューティングサービスである AWS Lambda は、データ変換に使用できます。
5. 特徴量ストア
これで、最終的な形式のデータを ML モデルで使用できるようになりました。 Amazon S3 またはML モデルの特徴量を保存、共有、管理するためのフルマネージド型の専用リポジトリである Amazon SageMaker Feature Store 上の特別なデータセットに配置されます。特徴量は、学習や推論の際に使用される ML モデルへの入力です。 特徴量は複数のチームで繰り返し使用され、精度の高いモデルには特徴量の品質が不可欠です。また、オフラインでバッチ的にモデルを学習するために使用した特徴量を、ニアリアルタイムに推論できるようにする場合、2つの特徴量ストアを同期させることは困難です。Amazon SageMaker Feature Storeは、MLライフサイクルにわたり特徴量を利用するための安全で統一されたストアを提供します。
6. 学習とハイパーパラメーターチューニング
お客様のユースケース、プロジェクトチーム、スキルセット、時間や精度の要件に応じて、お客様は AWS からさまざまなオプションを選択できます。 モデル学習のプロセスでは、お客様が取り得る方法が3つあります。 これについては、「モデル学習の方法」セクションで詳しく説明し、その後に実際の例を示します。
MLOps とオーケストレーションは、あらゆる ML プロセスの重要な部分です。 お客様は以下のソリューションを使用して、MLプロセス全体のオーケストレーションを行うことができます。
- AWS Step Functions は、開発者が AWS のサービスを利用するのに役立つビジュアル・ワークフローサービスです。
- Amazon Managed Workflows for Apache Airflow (Amazon MWAA)は有向非巡回グラフ (DAG) を使用してワークフローをオーケストレーションします。
- Amazon SageMaker Pipeline はML のための継続的インテグレーション・継続的デリバリーサービスです。
7. 推論
これで、予測を実行する ML 推論のためにデプロイ可能なモデルができました。非同期で予測するためにバッチ推論を選択するか、API を使用してニアリアルタイム推論を選択できるようになりました。 バッチ推論では、予測結果が Amazon S3 にカンマ区切り(CSV) ファイルとして格納されます。 この CSV ファイルはエクスポートして、内外のシステムで使用できます。 バッチ推論は、レイテンシを許容できる費用対効果の高い推論メカニズムです。 Amazon SageMaker はバッチ変換を提供しています。 さらに、時系列予測サービスである Amazon Forecast では、Amazon Forecast コンソール、AWS CLI、または AWS SDK を使用して予測を作成し、それを Amazon S3 バケットにエクスポートできます。
ニアリアルタイムの推論は、ユーザーがニアリアルタイム、インタラクティブ、低レイテンシーの要件がある推論ワークロードに最適です。 モデルを Amazon SageMaker ホスティングオプションにデプロイし、推論に使用できるエンドポイントを取得できます。 これらのエンドポイントはフルマネージド型で、自動スケーリングをサポートしています (「Amazon SageMaker モデルをオートスケーリングする」を参照)。 もう 1 つの選択肢は、Amazon SageMaker サーバーレス推論です。これは、ユーザーが ML モデルを簡単にデプロイしてスケーリングできるようにする目的別の推論オプションです。 サーバーレス推論は、トラフィックの急増の合間にアイドル期間があり、コールドスタートに耐えられるワークロードに最適です。 サーバーレスエンドポイントは、コンピューティングリソースを自動的に起動し、トラフィックに応じてスケールインとスケールアウトを行うため、インスタンスタイプを選択したり、スケーリングポリシーを管理したりする必要がありません。 これにより、サーバーの選択と管理という、差別化につながらない重労働が軽減されます。 サーバーレス推論は AWS Lambda と統合され、高可用性、ビルトインの耐障害性、自動スケーリングを実現します。 ペイロードサイズが大きく、処理時間が長く、非同期で推論する場合、お客様は非同期推論を使用できます。 Amazon SageMaker 非同期推論は Amazon SageMaker の新機能で、受信したリクエストをキューに入れて非同期的に処理します。
8. 活用
推論の結果は、組織がビジネスインテリジェンス、在庫計画、ロジスティクス計画、および在庫補充に使用できます。 予測出力は、Amazon API Gateway (開発者があらゆる規模で API の作成、公開、保守、監視、保護を容易に行えるフルマネージドサービス)を利用したAPIを通じて組織内のアプリケーション(CRM/ERP/EPM など)で使用したり、CSVファイルとしてエクスポートしたりすることが可能です。ビジネスアナリストやステークホルダーは、Amazon QuickSight(データ主導の組織にハイパースケールの統合ビジネスインテリジェンス (BI) を提供)などのサービスでビジネスインテリジェンスや可視化を行うために予測を参照することができます。予測データは、データレイクまたはデータウェアハウスにエクスポートして取り込むことができ、ビジネスプロセスの重要なデータとして機能します。
9. セキュリティ
セキュリティはいかなる仕事よりも重要なので、ユーザーはプロセス全体を通してセキュリティを強化したいと思うでしょう。 AWS では、ID、リソース、およびネットワーク指向のアクセス制御を補完する追加のアクセス制御として、暗号化を推奨しています。 AWS では、お客様がデータを暗号化してキーを管理できるように、さまざまな機能を提供しています。 すべての AWS サービスには、保存中および転送中のデータを暗号化する機能があります。 ユーザーが暗号化キーを作成、管理、制御できる AWS Key Management Service(AWS KMS)は、AWSの大半の サービスと統合され、お客様に代わってデータの暗号化に使用する鍵のライフサイクルやパーミッションを管理できるようにします。 お客様は、ポリシーと設定ツールを使用して、AWS KMS と統合されたサービスで暗号化を実施および管理できます。 AWS 環境は、インターネット経由の仮想プライベートネットワーク (VPN) 接続や AWS Direct Connect 経由など、さまざまな方法でお客様の既存のインフラストラクチャに接続できます。 アクセス制御には AWS Identity and Access Management (AWS IAM) を使用することをお勧めします。 AWS IAM を使用すると、ユーザーは AWS のサービスとリソースにアクセスできるユーザーまたは対象を指定し、きめ細かい権限を一元管理し、アクセスを分析して AWS 全体の権限を絞り込むことができます。 これにより、最小権限でアクセスできるようになります。
モデル学習の方法
A. ローコード/ノーコード
ローコード/ノーコードオプションでは、ビジネスアナリストにビジュアルなマウス操作可能なインターフェースを提供することで ML の利用を拡大する Amazon SageMaker Canvas や、ML モデル構築の重労働を取り除く Amazon SageMaker Autopilot を簡単に利用することが可能です。これは、ML や開発に関する知識がほとんど必要ない、最も手間のかからない方法です。 ビジネスアナリストやデータアナリストは、アルゴリズムの選定や評価などの複雑な作業に頭を悩ませることなく使用できます。 データをブラウズしてターゲットを選択し、Amazon SageMaker にモデルを生成させるだけで済みます。 Amazon SageMaker では、事前定義されたメトリクスに基づいてハイパーパラメータのチューニングを実行することもできます。 ローコード/ノーコードの ML サービスは、需要予測をする上でのリソースの制約に対処します。 お客様は、モデルを学習させるための特徴量を数週間もかからず、数日で準備することができます。
Amazon SageMaker Autopilot は自動的にデータを準備し、表形式データセットに最適な ML モデルを構築、学習、チューニングします。 データに対して複数のアルゴリズムを実行し、フルマネージド型のコンピューティングインフラストラクチャ上でハイパーパラメータをチューニングします。 Amazon SageMaker Canvas を使用すると、ビジネスアナリストは ML の経験やコードの記述を必要とせずに、自分で正確な ML 予測を生成できます。 Amazon SageMaker Canvas を使用して売上予測を生成するソリューションについては、こちらをご覧ください。
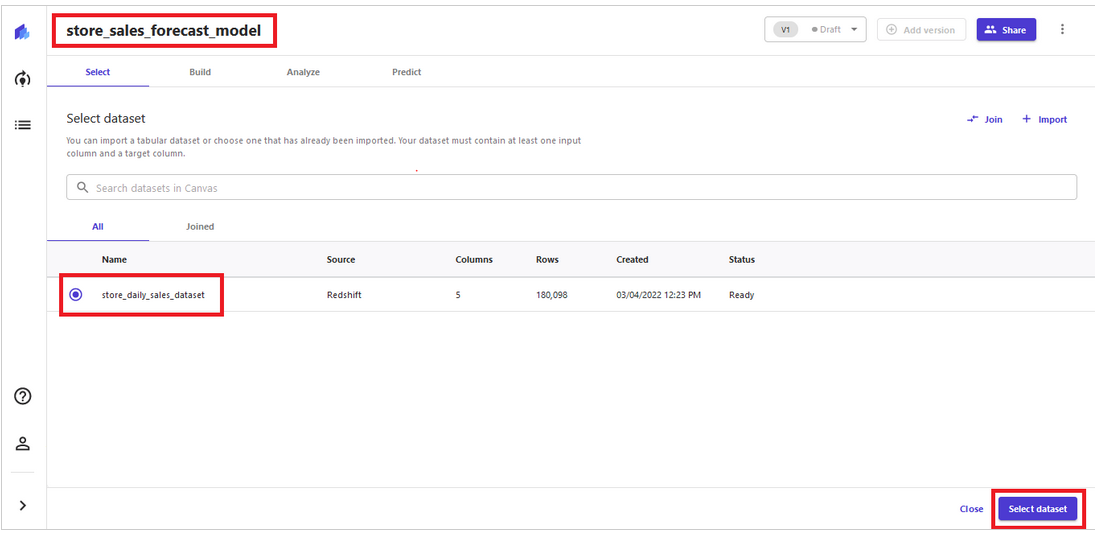
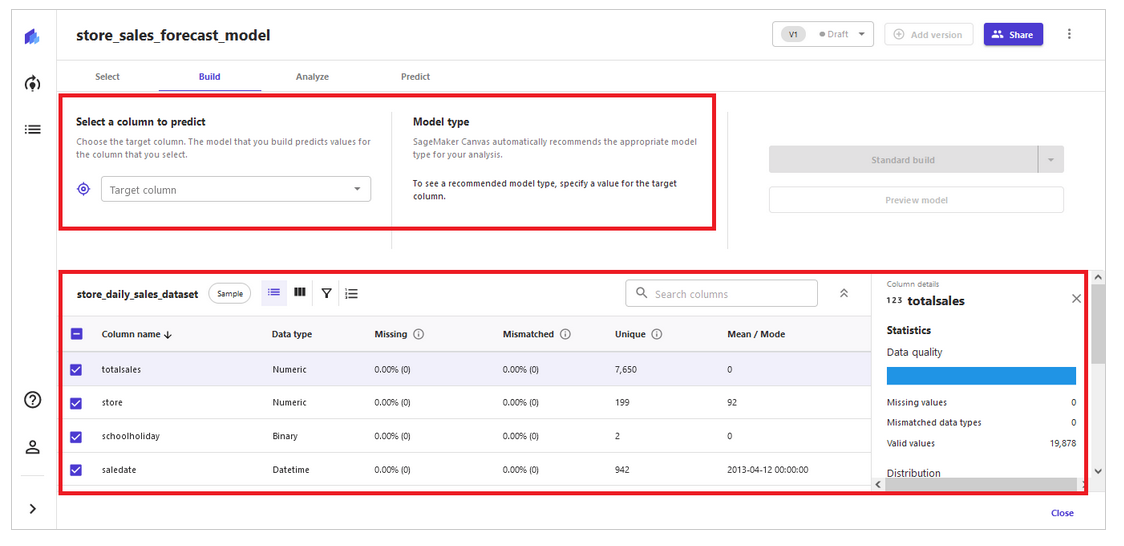
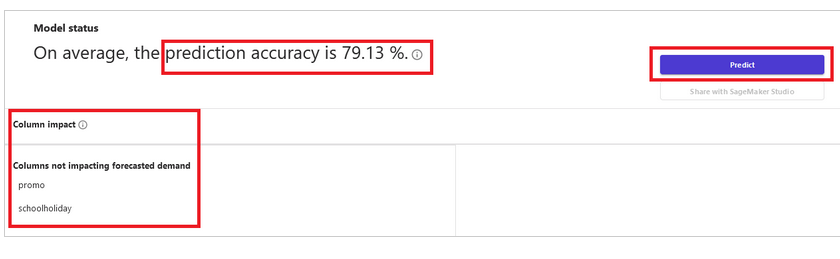
このソリューションでは、Amazon Redshift クラスターに保管されたデータと Amazon SageMaker Canvas を使用して ML モデルを構築します。 お客様は、サンプルデータセットのローカル.csv ファイルを直接アップロードすることもできます。 このソリューションでは、4 つのステップ ([データの選択] → [モデルの構築] → [結果の分析] → [予測の生成]) に従って小売予測モデルを構築します (下図参照)。 データサイエンスやプログラミングの専門知識を持たないセールスマネージャーやオペレーションプランナーは、この方法を使用して、意思決定を迅速化し、生産性を向上させて、オペレーション計画の策定に役立てることができます。
ステップ1 – データの選択
ステップ2 – モデルの構築
ステップ3 – 結果の分析
ステップ4 – 予測の生成
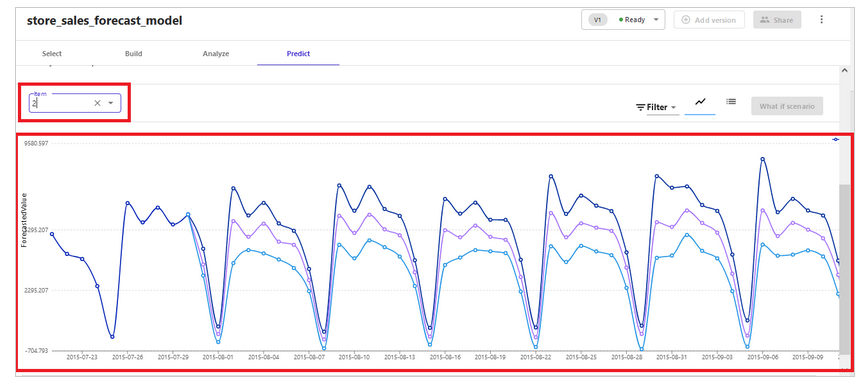
B. Amazon Forecast
データエンジニアと開発者は Amazon Forecast を活用できます。 この場合は、過去の時系列データ (および利用可能な場合は、関連時系列データや項目メタデータなどのオプションのデータセット) を提供し、将来予測を要求します。 Amazon Forecast は、データセット内の各時系列に最適なアルゴリズムの組み合わせを適用するAutoPredictorを作成します。 また、さまざまな選択肢を検討しながら、作業の効果を可視化することもできます。 Amazon Forecastは、Amazon.comでの20年以上の経験を基に構築されており、機械学習の知識がなくてもサービスを利用することができます。
Amazon Forecastに自動化と分析機能が追加された、デプロイ可能なソリューションのサンプルは、こちらにあります。ソリューションのアーキテクチャ図を以下に示します。
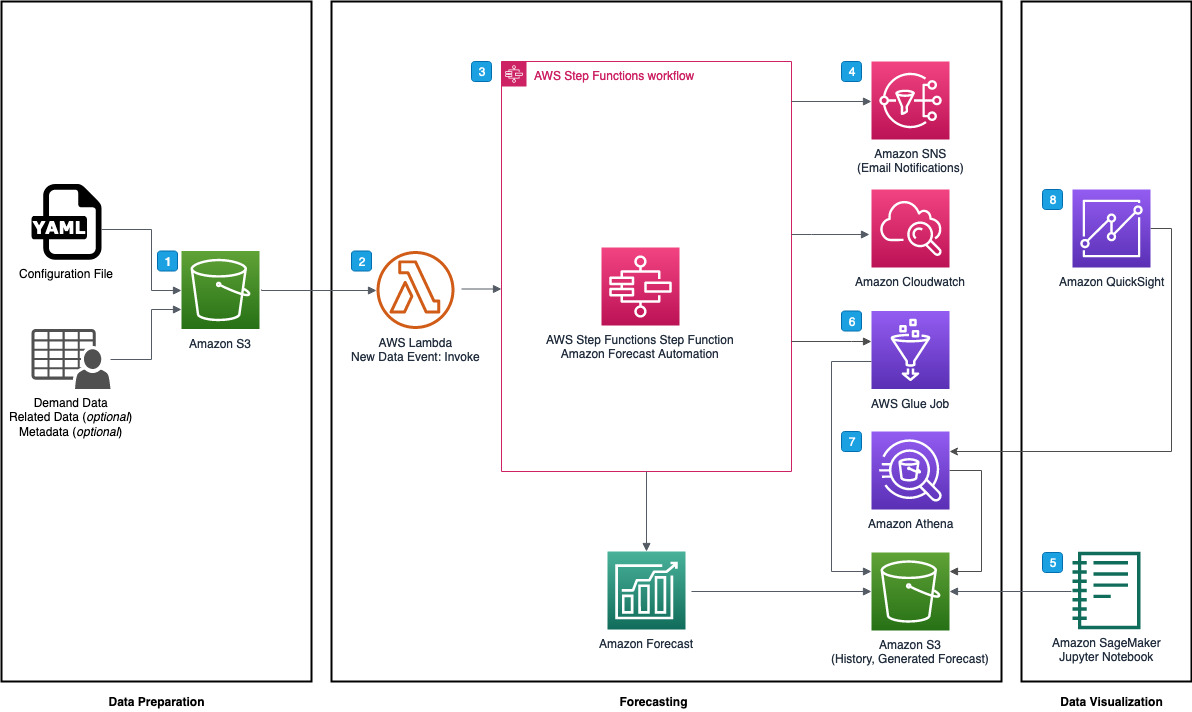
このソリューションでは、複数の予測と、予測ごとのパラメータ構成をサポートしているため、複数の予測を生成する際の反復的な作業を減らすことができます。 AWS Step Functions を使用すると、Amazon Forecast データセットや、データセットグループ、予測子、予測を作成するという面倒な作業が不要になり、開発者やデータサイエンティストは予測の精度に集中できます。 Amazon Forecastの予測子と予測は、需要データ、関連時系列データ、項目メタデータが最新化されるたびに更新できます。これにより、関連時系列データや項目メタデータに対するA/Bテストが可能になります。
予測の結果は、AWS コンソールで直接確認するか、Amazon Athena でクエリ、またはソリューションに含まれている Amazon QuickSight ダッシュボードから確認できます。
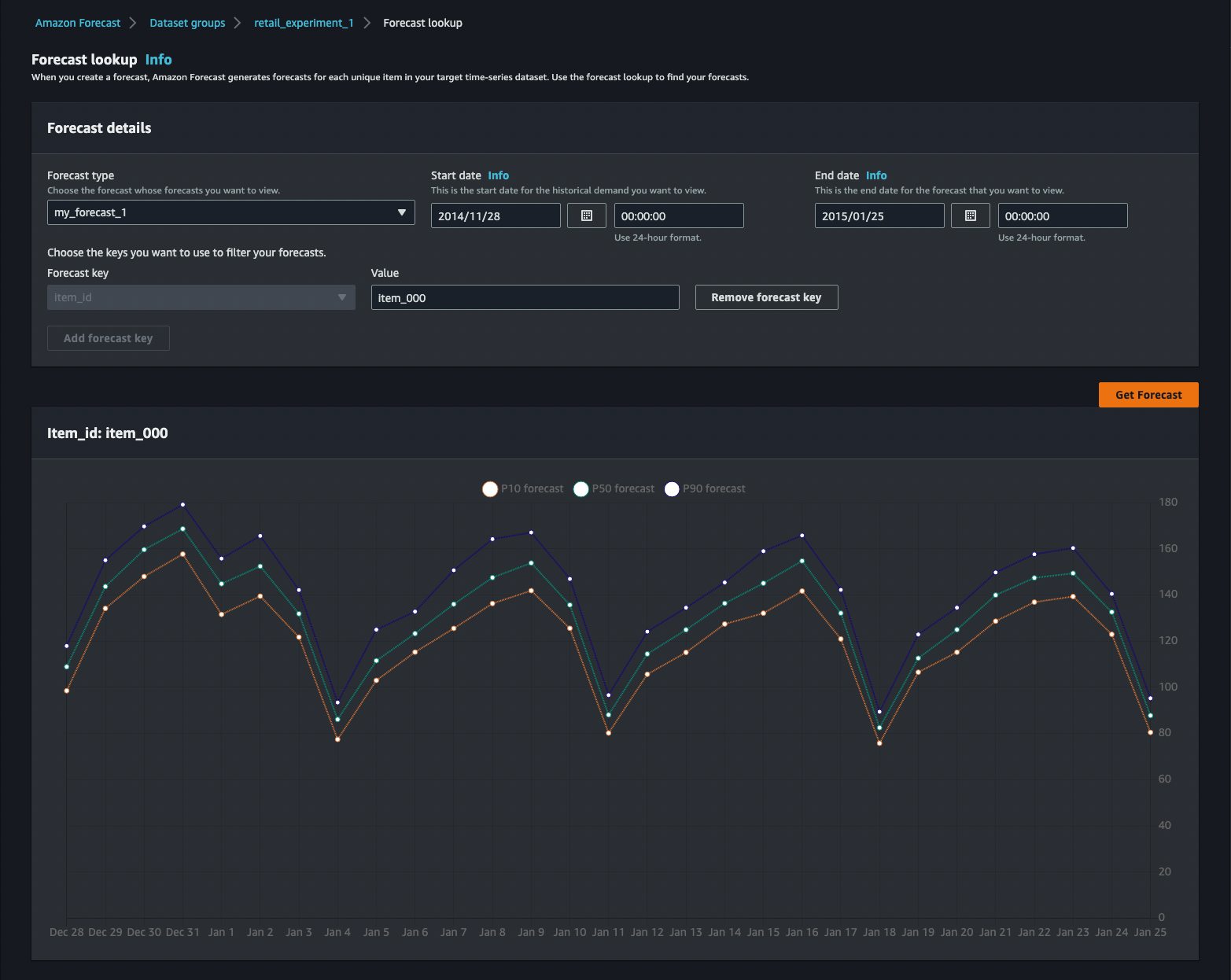
予測子の個々のアルゴリズムのメトリクスを表示することもできます。
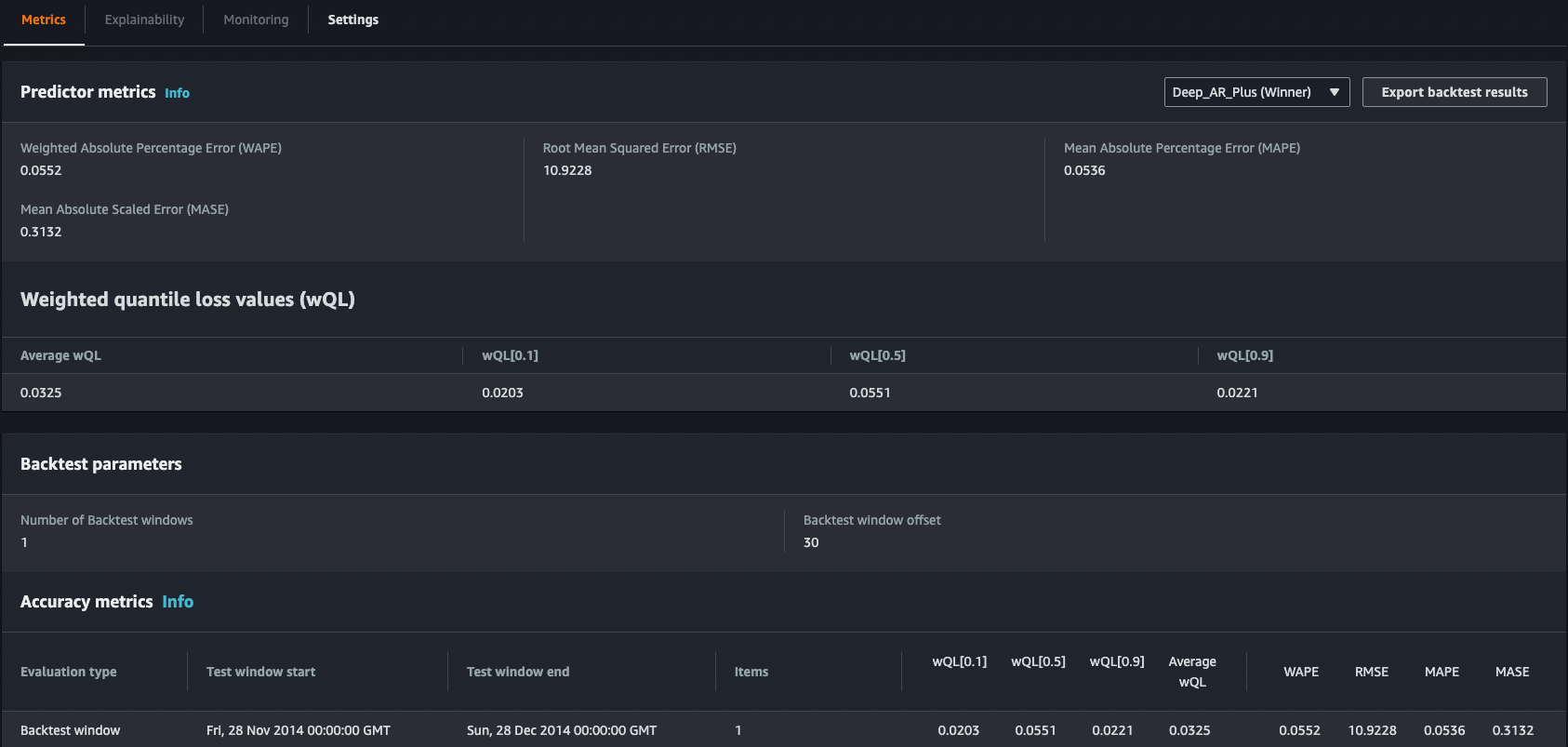
このソリューションは、需要予測を実装する必要があり、AWS 開発にはある程度精通しているが、ML の専門知識が足りない小売組織に特に役立ちます。 これは前述の方法からのステップアップであり、予測結果をより詳細に評価できるだけでなく、学習プロセスをより適切に管理できます。
C. 高度な方法
Amazon SageMaker は、DeepAR や AutoGluon などの AutoML ライブラリなどの組み込みアルゴリズムを使用したり、既存のモデルをインポートして転移学習を実行したりできる開発者やデータサイエンティスト向けの高度な方法です。 お客様は、データ並列処理やモデル並列処理などの高度な方法を使用し、次のようなビルトイン機能を使用できます。
- Amazon SageMaker Clarify: MLの学習データとモデル関する深い洞察を得られる専用ツールをML開発者に提供し、バイアスを確認することができます。
- Amazon SageMaker Model Monitor: ユーザーはコードを記述することなく、監視および分析したいデータを選択し、モニタリングすることができます。
- Amazon SageMaker Debugger: 学習中のトラブルシューティングを数日から数分に短縮してデバッグすることができます。
最も複雑なプロジェクトには複数のデータソースがあることが多く、モデルの学習プロセスを高度に制御するとともに、高度なデータ変換が必要になります。 このようなユースケースには、Amazon SageMaker が最適です。
このプロセスをより深く理解するために、ユーザーは GitHub 上の AWS サンプルリポジトリにある既存のソリューションを調べることができます。
このノートブックには、Amazon SageMaker の scikit-hts ツールキットを使用して、アルゴリズムとハイパーパラメータの組み合わせで複数の階層型時系列モデルを学習、チューニングする方法を紹介する、架空の小売データの需要予測の例があります。 ユーザーは Scikit Learn のEstimatorを使用して Amazon SageMaker で scikit-hts をセットアップする方法を学び、次に Amazon SageMaker Experiments を使用して複数のモデルを学習し、最後に Amazon SageMaker Debuggerを使用して最適ではない学習を監視し、学習の効率を向上させる方法を学びます。 サンプルデータセットは以下のようになります。

最初に、ユーザーはデータの前処理、クレンジング、および可視化を行います。 次に、Amazon SageMaker のexperimentを作成し、Scikit Learn Estimator を使用してfitメソッドを呼び出し、学習を開始します。 オプションとして、お客様は Amazon SageMaker インスタンスのマネージドスポットトレーニングを使用して学習を行うことができます。これにより、費用対効果が高まり、オンデマンドインスタンスよりも 90% 節約することができます。

ML 用に統合された開発環境 (IDE) である Amazon SageMaker Studio のコンソールでは、ユーザーはすべてのexperimentやコンポーネントを調べることができます。
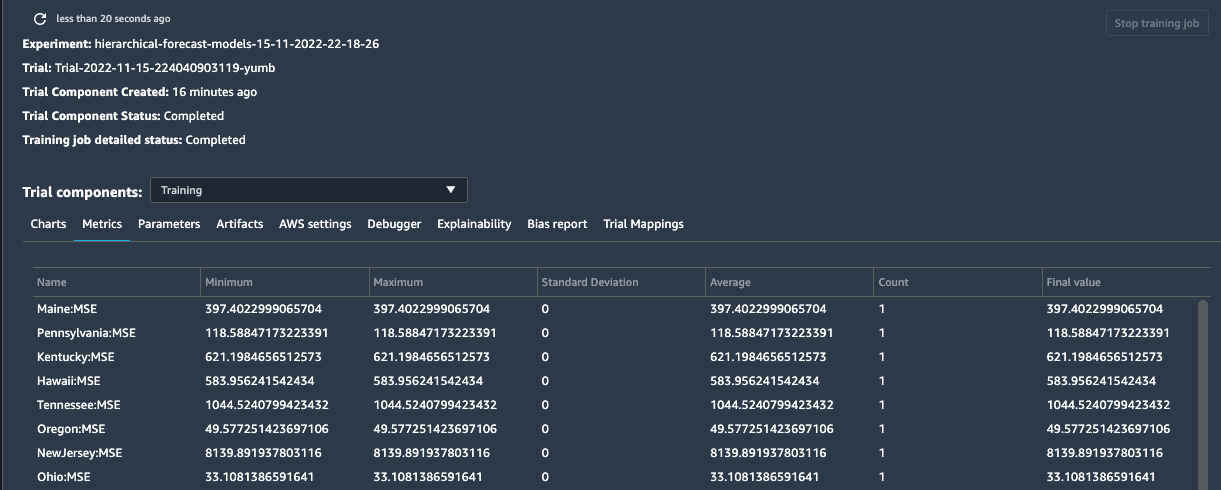
学習が終了すると、ユーザーはモデルをさらに分析し、選択した指標(MSE)に基づいて最良のモデルを選択し、それを使用して予測を開始できます。

最後に、ユーザーは matplotlib を使って予測を可視化できます。
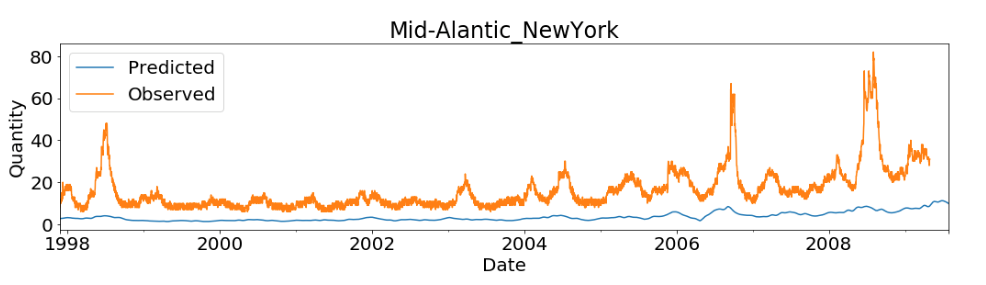
さらに、お客様は GitHub の AWS サンプルリポジトリにある他の複数のサンプルを使用できます。 有用な例を2つご紹介します。
- Amazon SageMaker の GluonTS ツールキットを使用して大規模な時系列予測を実行する方法:このユースケースは電力予測ですが、Amazon SageMaker の GluonTS ツールキットを使用して需要予測を実行する場合にも簡単に使用できます。
- 時系列に AutoGluon AutoML を使用してコールド スタート予測エンジンを構築する: このノートブックでは、コールド スタートアイテムの予測(訳注:過去の販売データがない新商品の需要予測)を取得する方法を示します。
どの方法を選択するか
前述の3 つのモデル学習の方法を以下にサマリーしていますが(A、B、C)、順にMLの専門知識、モデル構築とチューニングの経験が必要とされます。小売業者は、ビジネス目標とMLジャーニーの段階に基づいて最初の選択をすることになります。 たとえば、ビジネスユーザーは、表形式のデータがあればAから始めることができます。 ビジネスアナリストは、プロトタイプの結果をデータエンジニアや ML 開発者と共有できます。 Bは特に不規則な傾向を持つ大規模なデータを扱う場合に、時系列データからの需要予測の精度を向上させます。 小売業者がより詳細なシナリオや複雑なシナリオに移行するにつれて、 C はより柔軟にカスタマイズされた ML 予測モデルを深く掘り下げることができます。
| 選択肢 | 該当するユーザー | モデル学習プロセスへのアクセス | 該当するデータセット | サービス | 制御/手動チューニング |
| (A)
ノーコード/ローコード |
ビジネスアナリスト、セールスマネージャー | 学習やハイパーパラメータチューニングのカスタマイズは不要 | 高品質でクリーンな表形式のデータセット | Amazon SageMaker Canvas、
Amazon SageMaker Autopilot |
低 |
| (B)
Amazon AI サービス |
データエンジニア、ソフトウェアエンジニア、ML 開発者 | 自動化されたプロセスで、一定のコントロール、カスタマイズは可能 | 定義済み小売データセットドメインの時系列データ、オプションで項目メタデータ | Amazon Forecast | 中 |
| (C) 高度な方法 | データサイエンティスト、経験豊富な ML エンジニア | カスタマイズされたMLモデル、学習プロセスの細かい制御 | 限られた履歴データ、複数のデータソース、高度なデータ変換が必要 | Amazon SageMaker | 高 |
AWS パートナーからの支援
さらに、小売業者はAWS で小売予測ソリューションを提供する AWS リテールコンピテンシーパートナーと連携することができます。 これらの AWS パートナー製品は、小売業に関する高度なデータサイエンスの専門分野で、技術的に熟練していること、小売業のお客様を成功に導いていることが証明されています。 一部のパートナーを以下に示します。
小売業の需要予測のソリューションを提供する AWS リテールコンピテンシーパートナーをご覧ください。
まとめ
ユースケースはそれぞれ異なり、プロジェクトごとに独自のアプローチが必要です。 この記事で紹介するリファレンスアーキテクチャは、一般的な ML の問題に対する体系的なアプローチを示しています。 場合によっては、ユーザーは特定の段階をスキップしたり、それらを組み合わせたりすることができます。また、途中で追加の手順が必要になることもあります。 ただし、AWS クラウド上で MLを使って現実の問題を解決するために必要なことを十分に理解するには、方法論に従うことが重要です。

Neelam Koshiya
Neelam Koshiya は AWS のエンタープライズソリューションアーキテクトです。 ソフトウェアエンジニアリングがバックグラウンドで、アーキテクトロールに転向しました。 彼女の現在のフォーカスは、企業顧客が戦略的なビジネス成果を得るためのクラウド導入を支援することです。 彼女はイノベーションとインクルージョンに注力しています。 余暇には、読書やアウトドアを楽しんでいます

Jing Ning
Jing Ning は AWS のパートナーソリューションアーキテクトです。 エンタープライズの ML/AI プロジェクトに携わり、AWS のローコード/ノーコードツールに注力しています。 現在のフォーカスは、AWS サービスパートナーが AWS のお客様のためにソリューションを検証し、差別化できるよう支援することです。 コーヒーと世界中を旅することが好きです。

Daniel Borek
Daniel Borek は AWS のテクニカルアカウントマネージャーです。 企業顧客がビジネス目標を最適化して達成しながら、クラウドへの移行を加速できるよう支援しています。 彼のバックグラウンドは、オペレーティングシステム、ネットワーク、ストレージです。 最近では、AWS クラウドの多くの MLサービスにも取り組み始めました。 旅好きで、ランナー、写真家です。
翻訳はソリューションアーキテクト千代田が担当しました。原文はこちらです。