- AWS Marketplace
- AI agent learning series
- Module 2 - AI agent frameworks & building blocks
AI agent frameworks and building blocks
Break down the core components and architectural patterns behind agentic systems. Build a solid mental model for designing and extending agent-based solutions.
Overview
Technical workshop: Agent frameworks and building blocks
Join AWS experts for a hands-on workshop featuring tools from LangChain and Anthropic. Real demos, real code, ship faster.

Understanding agent frameworks
Explore the frameworks that make agent development practical, set up a working development environment, and connect agents to external systems through memory, tools, and models. By the end of this module, you’ll understand how to build agents with LangChain and Anthropic Claude.
Featured AI tools in AWS Marketplace
Build with foundation models, deployment platforms, and AI infrastructure—all available through your AWS account.

Page topics
- Understanding agent frameworks
- 1. What is a framework anyway?
- 2. Revisiting the thought-action-observation loop
- 3. Understanding LLM chains and reasoning
- 4. Revisiting the reasoning, orchestration, and tool layers
- 5. The role of frameworks in agentic system development
- 6. Building agentic systems on AWS
- 7. Agents and external systems
- 8. Designing future-proof architectures
Understanding agent frameworks
In Module 1, we introduced the concept of AI agents—autonomous software systems that use large language models (LLMs) to reason, plan, and take actions in the real world. We explored how agents differ from traditional chatbots, examined the Thought-Action-Observation loop, and outlined the three-layer architecture (reasoning, orchestration, and tools) that underpins every agentic system.
Module 2 takes the next step: frameworks and building blocks. If Module 1 answered “What are agents?”, this module answers “How do we start building them?” We’ll go deeper into the patterns introduced in Module 1, explore the frameworks that make agent development practical, set up a working development environment, and connect agents to external systems through memory, tools, and models. By the end of this module, you’ll understand how to build agents with LangChain and Anthropic Claude.
What you’ll learn
- How AI agent frameworks differ from traditional software frameworks and why they’re essential for building agentic systems
- How to set up a development environment for building agents using LangChain, LangGraph, and Anthropic Claude
- How agents connect to external systems through memory, tool protocols (MCP, A2A), and multi-model architectures
Prerequisites
- Completion of Module 1 - Introduction to AI Agents recommended
- Basic Python programming knowledge
- An AWS account with Amazon Bedrock access enabled and IAM permissions for bedrock:InvokeModel (see Amazon Bedrock access setup)
- AWS credentials configured locally (via AWS CLI aws configure, IAM Identity Center, or environment variables)
- Python 3.10+ installed on your development machine
1. What is a framework anyway?
If you’ve built web applications, you’ve likely worked with frameworks like Django, Spring, or React. These traditional frameworks manage explicit control flow—developers write conditional logic to determine what happens next, and the application behaves predictably because every path is predetermined. A request comes in, hits a route, calls a controller, queries a database, and returns a response. The developer decides every step.
AI agent frameworks solve a fundamentally different problem. Instead of hardcoding control flow, they enable the LLM itself to decide which tools to invoke, what order to call them in, and how to combine their results — even chaining multiple tool calls dynamically based on intermediate results. The framework provides the scaffolding; the model provides the decisions.
What agent frameworks provide that traditional frameworks don’t
An AI agent framework is “a toolkit that provides the building blocks to design, deploy, and manage AI agents,” including LLMs, tool integrations, memory, orchestration, and safety features. Six capabilities distinguish them from their traditional counterparts:
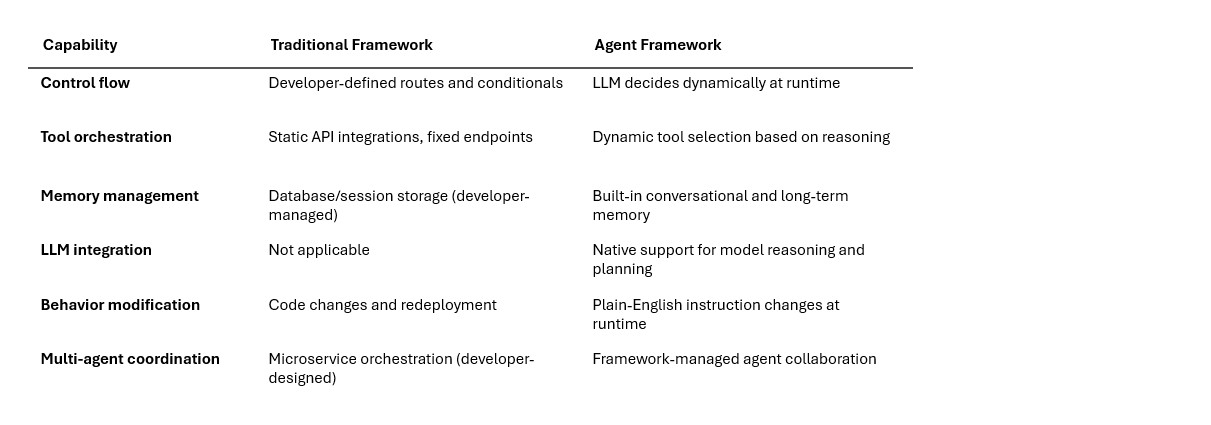
Without frameworks, developers face an intractable problem: “in a complex system with dozens or hundreds of scenarios, you cannot hardcode every combination of decisions and tool calls”. Frameworks provide the ready-made building blocks — LLM integration, tool management, memory handling, and agent orchestration—so developers can focus on what their agent should accomplish rather than how to wire everything together.
A brief history
LangChain, one of the earliest and most widely adopted agent frameworks, was created by Harrison Chase in late 2022. It initially focused on “chaining” multiple LLM calls together to create more sophisticated workflows. As of 2026, LangChain has over 90,000 GitHub stars and supports integration with over 100 LLM providers including Anthropic, OpenAI, Google, and open-source models. LangChain 1.0 and LangGraph 1.0 were released in November 2025, marking a major milestone for production-readiness.
The landscape has expanded rapidly. LangGraph emerged in early 2024 to handle complex stateful workflows as directed graphs. CrewAI and AutoGen brought multi-agent collaboration patterns. AWS released the Strands Agents SDK in May 2025 (reaching 1.0 in July 2025) to address customer pain points: “too much plumbing code required for simple agents,” “difficulty understanding what agents are doing internally,” and “challenges making agentic code modular for unit testing”. Amazon Bedrock Agents added fully managed agent orchestration on AWS.
Diagram: Traditional software vs. agentic framework
The following diagram illustrates the fundamental architectural difference between traditional and agentic approaches:
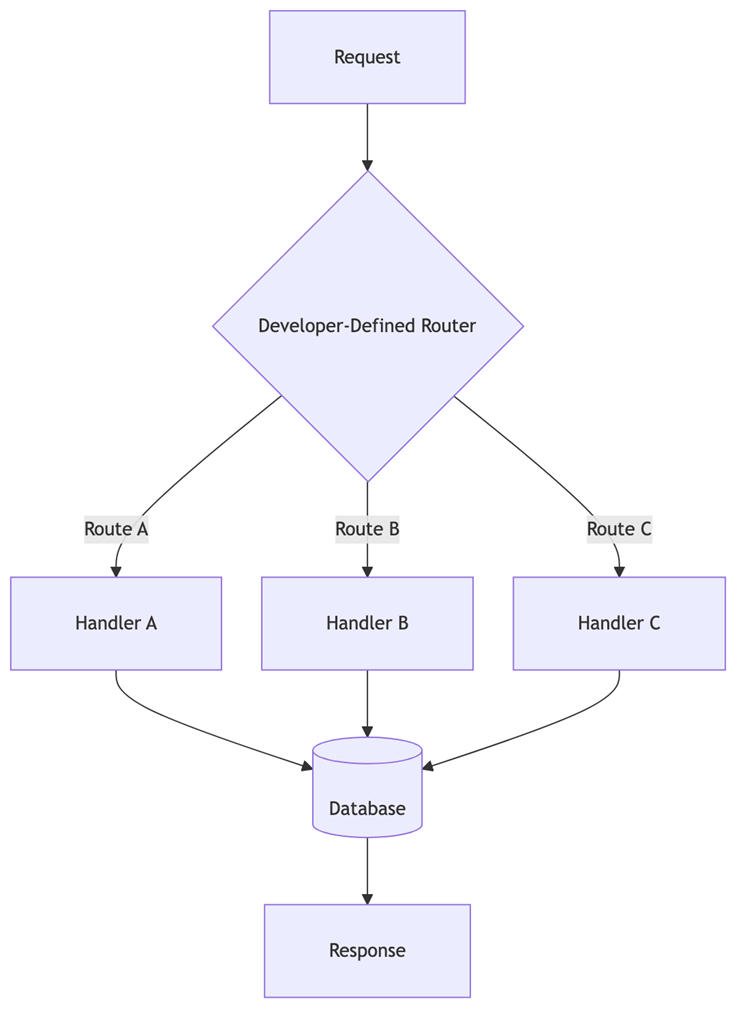
Diagram 1 - Figure 1a: Traditional software framework. Developers hardcode every route and handler. Control flow is deterministic — each request follows a predefined path through the system.
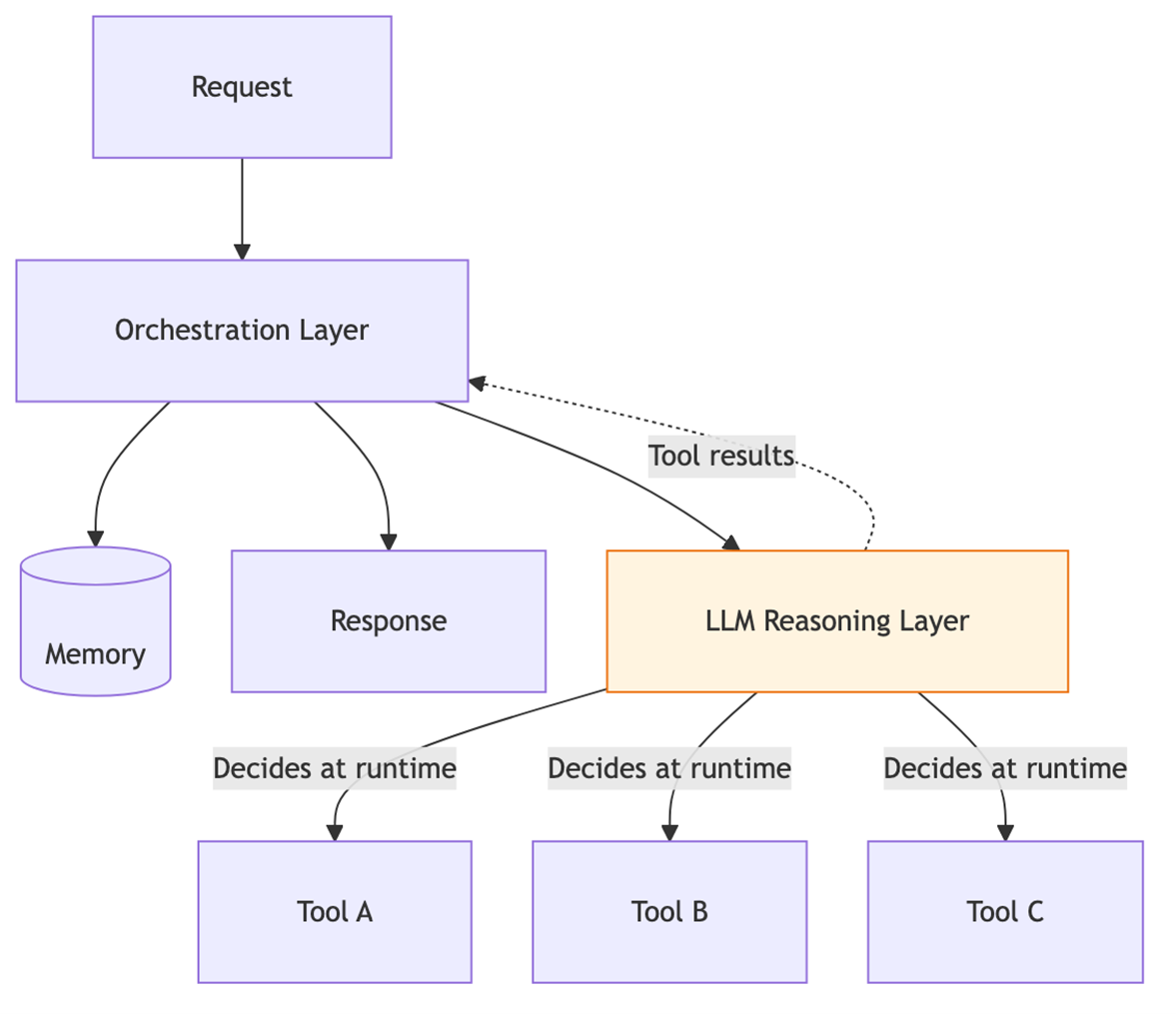
Diagram 2 - Figure 1b: AI agent framework. The LLM dynamically decides which tools to invoke based on reasoning about the current task. Control flow is determined at runtime, not at build time.
2. Revisiting the thought-action-observation loop
In Module 1, we introduced the idea that agents work through a cycle of thinking, acting, and observing. Now let’s examine the formal pattern behind this cycle.
The ReAct pattern
The ReAct (Reasoning + Acting) pattern was introduced by Yao et al. in the paper “ReAct: Synergizing Reasoning and Acting in Language Models,” published at ICLR 2023. The research — a collaboration between Princeton University and Google Research — addressed a gap where “the reasoning capabilities of large language models and their action-planning abilities had been studied predominantly as separate research directions”.
ReAct formalizes the Thought-Action-Observation loop into three repeating steps:
- Thought (Reasoning): The agent reasons about the current state — what it knows, what it doesn’t know, and what action to take next. The agent “expresses its internal reasoning” as an explicit text trace.
- Action (Acting): Based on the thought, the agent executes a structured call to an external tool — for example: query a search engine, run a calculator, query a database, or call some API.
- Observation: The system feeds the result of the action back to the LLM. “If the action was a web search, the observation is the search snippet. If it was a failed API call, the observation is the error message”.
This cycle repeats until the agent determines through its reasoning that the task is complete, at which point it generates a final answer.
Why ReAct matters: Performance data
ReAct’s combination of reasoning with real-world actions produces measurable improvements over reasoning alone:

The FEVER result is particularly significant: ReAct reduces false positives from 14% to 6% because “external verification grounds the reasoning in actual facts” rather than relying on potentially hallucinated knowledge.
Diagram: The ReAct loop
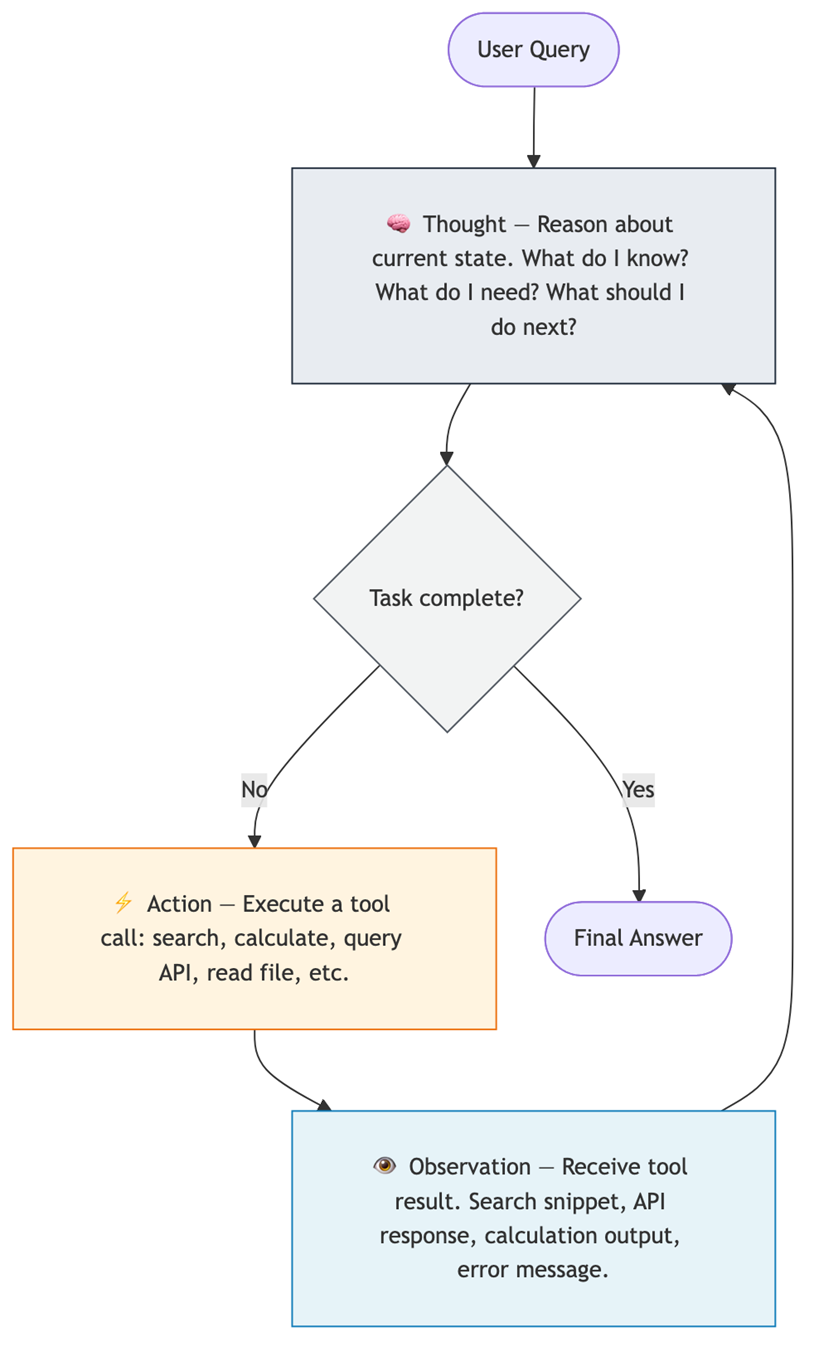
Diagram 3 - Figure 2: The ReAct loop cycles through Thought → Action → Observation until the agent determines the task is complete. Each cycle grounds the agent’s reasoning in real-world data.
3. Understanding LLM chains and reasoning
Before agents can reason and act autonomously, they need a way to compose multiple operations into coherent workflows. This is where chains come in — the foundational building block that gave LangChain its name.
What are chains and why they matter
LangChain was “born from the idea of making these types of operations easy” — chaining multiple operations involving LLMs together. Chaining takes several forms:
- Making multiple LLM calls: Breaking larger tasks into bite-sized steps or checking previous outputs improves results because “language models are often non-deterministic and can make errors”.
- Constructing LLM inputs: Combining data transformation with a call to an LLM — for example, formatting a prompt template with user input or using retrieval to look up additional information to insert into the prompt.
The simplest chain connects three components in sequence: a prompt template (formats the input), a language model (generates a response), and an output parser (extracts structured data from the response).
LangChain Expression Language (LCEL)
LCEL is LangChain’s declarative syntax for composing chains. It uses the pipe operator (|) to connect components, where “the output from the left is fed into the function on the right”. A basic chain in LCEL connects a prompt template, a model, and an output parser in sequence (e.g., prompt | model | output_parser).
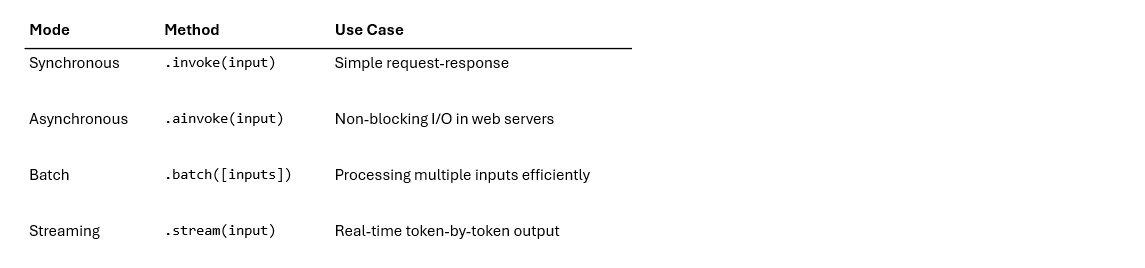
LCEL “takes a declarative approach to building new Runnables from existing Runnables. This means that you describe what should happen, rather than how it should happen, allowing LangChain to optimize the run-time execution of the chains”. Out of the box, every LCEL chain supports four execution modes:
Key LCEL primitives
LCEL provides five core building blocks for composing workflows:
- RunnableSequence—Chains components in sequence; created automatically with the | operator.
- RunnableParallel—Sends input to multiple branches simultaneously, reducing latency. A dictionary literal in LCEL is automatically converted to a RunnableParallel.
- RunnableLambda—Wraps any Python function as a Runnable component, letting you insert custom logic anywhere in a chain.
- RunnablePassthrough—Forwards input unchanged; useful for passing original data through parallel branches alongside transformations.
- RunnableBranch—Enables conditional logic, routing execution down different paths based on intermediate results.
Chain types
Sequential chains execute steps one after another, where each step’s output feeds into the next. This is the most common pattern: prompt → model → parser.
Parallel chains use RunnableParallel to execute multiple operations simultaneously — for example, fetching context from two different retrievers at the same time before combining results for the LLM.
Branching chains use RunnableBranch for conditional logic, routing execution down different paths based on intermediate results.
When to use LCEL vs. LangGraph: The LangChain documentation recommends: “If you are making a single LLM call, you don’t need LCEL; call the underlying chat model directly. If you have a simple chain (e.g., prompt + LLM + parser), LCEL is a reasonable fit. If you’re building a complex chain with branching, cycles, or multiple agents, use LangGraph instead”.
Chain-of-thought reasoning
Chain-of-Thought (CoT) prompting “enables LLM models to perform complex reasoning tasks by forcing the model to break them down into step-by-step logical sequences”. Three main variants exist:
- Zero-shot CoT: Adding “let’s think step by step” to a prompt enables step-by-step reasoning without examples.
- Few-shot CoT: Providing example problems with their reasoning sequences so the model learns the pattern.
- Auto-CoT: Combining zero-shot and few-shot approaches to automatically generate reasoning sequences. “Studies have shown that Auto-CoT often outperforms both zero-shot and few-shot CoT”.
CoT reasoning forms the foundation for the Thought step in the ReAct loop. As one analysis notes: “ReAct augments chain-of-thought prompting by enabling the incorporation of real-time information as part of the iterative reasoning-action loop”.
4. Revisiting the reasoning, orchestration, and tool layers
In Module 1, we introduced the three-layer architecture that structures every agentic system. Now let’s examine each layer in depth and understand how they interact during agent execution.
The reasoning layer (LLM)
The reasoning layer is the cognitive engine of an agentic system. Powered by large language models like Anthropic Claude, this layer functions as “a sophisticated cognitive architecture capable of complex reasoning patterns, planning, and decision-making”. It generates chains of thought that “decompose a complex task, identify dependencies between subtasks, and develop coherent strategies for problem-solving”.
Anthropic Claude brings several capabilities to the reasoning layer:
- Extended thinking: Claude “can reason through problems step-by-step before generating visible output,” creating “a buffer against hallucinations and errors because the model has already identified and rejected approaches that don’t work before generating the final response”.
- Adaptive reasoning: The model “dynamically adjusts how much computational effort it applies based on task complexity” — spending more time on hard problems and responding quickly to simple ones.
- Large context windows: Claude supports 200,000-token context windows natively (with 1 million tokens in beta), enabling it to process hundreds of pages of context in a single pass.
- Native tool use: Claude’s architecture supports structured tool invocation, enabling it to “interleave tool use and reasoning” as a first-class capability.
The orchestration layer (framework)
The orchestration layer “functions as a control plane that translates high-level objectives into executable workflows, manages task dependencies, coordinates tool execution, and enforces governance constraints”. This is where frameworks like LangGraph and Amazon Bedrock Agents operate.
Without the orchestration layer, “agents would simply be stateless models making uncontrolled decisions without clear boundaries or recovery mechanisms”. Key responsibilities include:
- State management: Maintaining execution state across multiple inference passes and tool executions through checkpointing mechanisms. If an agent is interrupted mid-task, it can resume from the last checkpoint.
- Memory management: Distinguishing between short-term working memory (current conversation) and long-term persistent memory (facts that span conversations).
- Context management: Implementing consolidation strategies to prevent context window overflow — summarizing older messages, pruning irrelevant information, and prioritizing recent context.
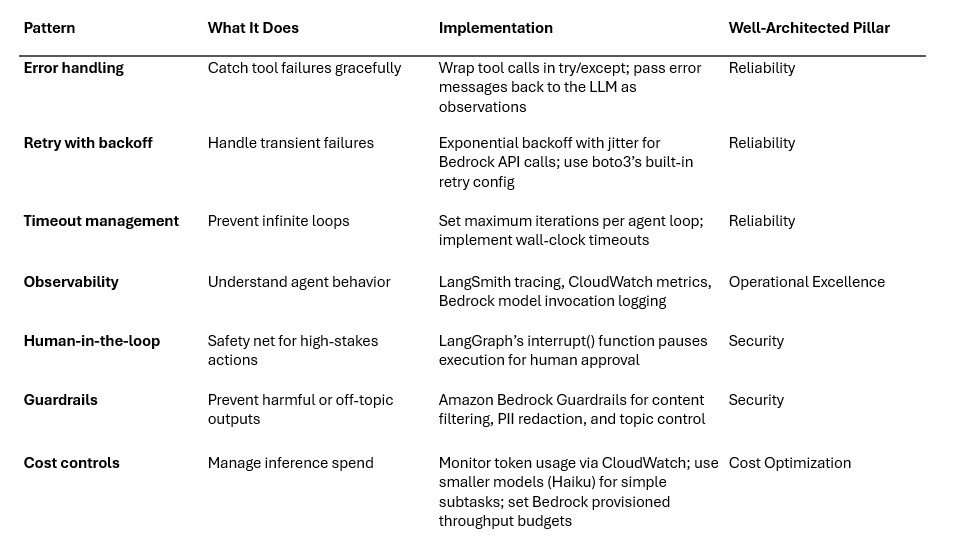
- Error handling: Catching tool errors, formatting them for the reasoning layer, and implementing retry mechanisms with exponential backoff.
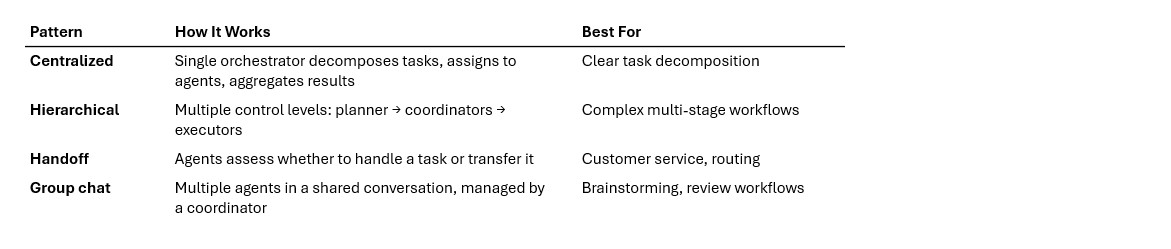
The orchestration layer implements several architectural patterns:
The tool layer (external integrations)
The tool layer “represents the interface between the agentic system and the external world of APIs, databases, services, and computational resources”. Tools are defined using JSON Schema format with descriptions that help the reasoning layer understand when and how to use each tool.
Tool definitions matter more than you might think. According to an AWS evaluation study: “Poorly defined tool schemas and imprecise semantic descriptions result in erroneous tool selection during agent runtime, leading to invocation of irrelevant APIs that
unnecessarily expand the context window, increase inference latency, and escalate computational costs”.
Anthropic introduced the Model Context Protocol (MCP) as “an open standard for connecting AI systems with data sources, tools, and applications,” providing “a universal protocol that allows Claude and other AI assistants to interact with any data source or tool through a standardized interface”. We’ll explore MCP in depth in Section 7b.
Diagram: Three-Layer Agent Architecture
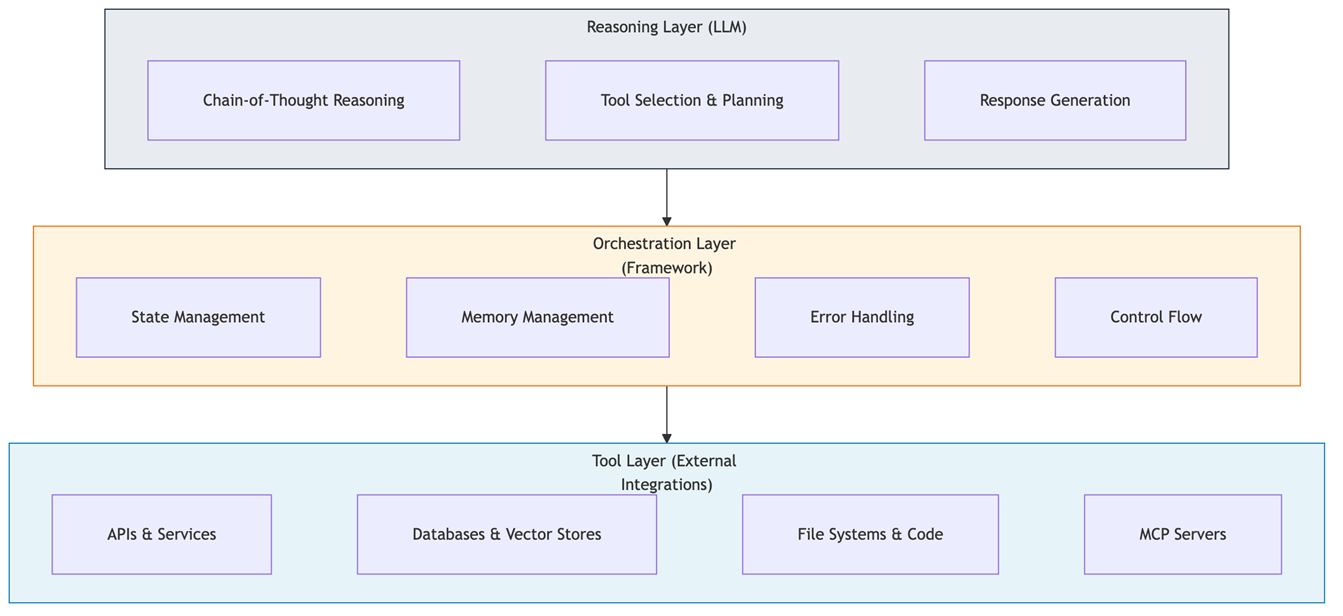
Diagram 4 - Figure 3: The three-layer architecture. The reasoning layer (Claude) makes decisions. The orchestration layer (LangGraph, Bedrock Agents) manages state and coordinates execution. The tool layer connects to external systems through standardized interfaces like MCP.
How the layers interact: The agent loop
The fundamental interaction pattern is the agent loop — the runtime cycle that drives every agent execution:
- User input arrives at the orchestration layer
- The orchestration layer formats input and passes it to the reasoning layer
- The reasoning layer (LLM) generates reasoning about what to do next
- If the LLM decides to invoke a tool, it generates a structured tool invocation request
- The orchestration layer validates the request and invokes the tool
- Tool results are passed back to the reasoning layer as an observation
- The loop continues until either a final response is generated or a termination condition is met
This pattern is “isomorphic to control theory feedback systems where the reasoning layer represents the controller, the current state represents the system state, errors represent unmet goals, tool invocations represent control actions, and tool results represent feedback signals”.
Diagram: The agent loop
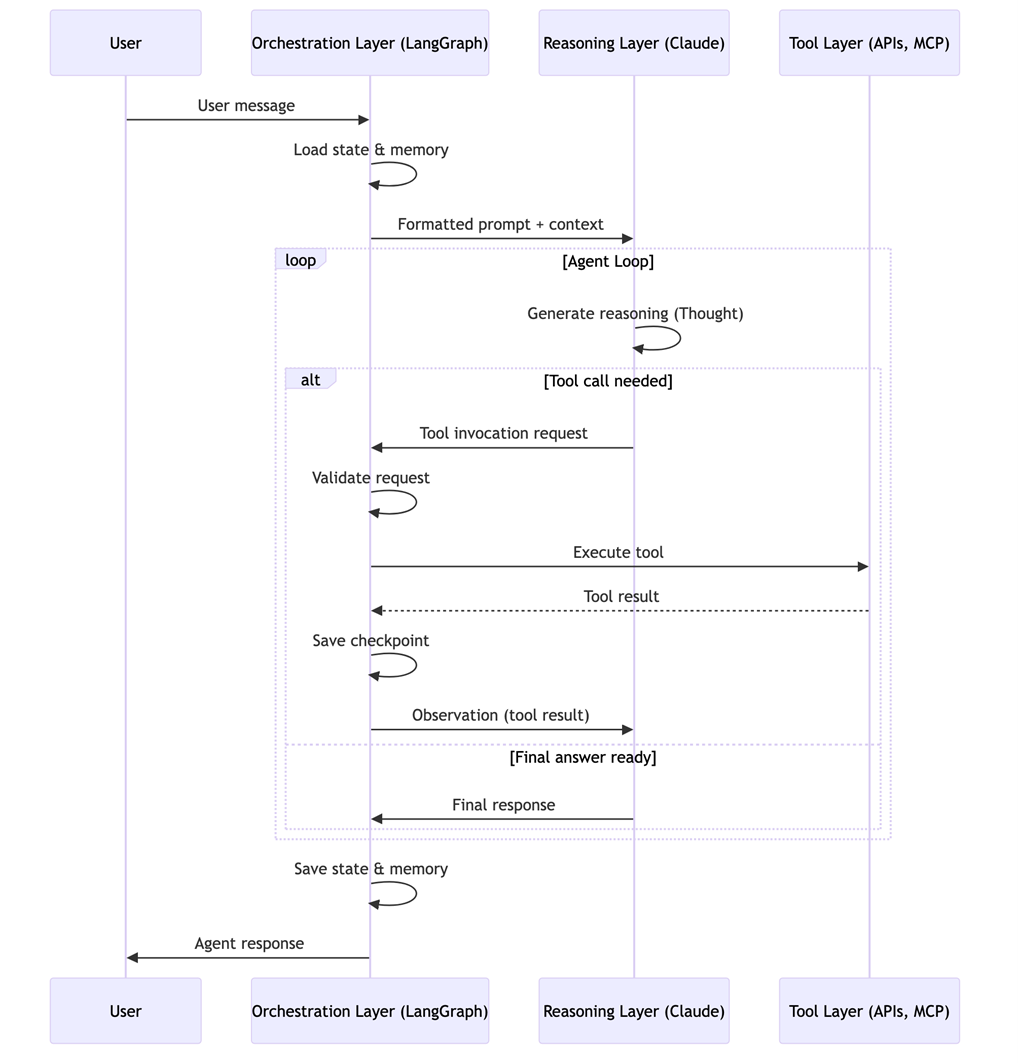
Diagram 5 - Figure 4: The agent loop in action. The orchestration layer manages the cycle between reasoning and tool execution, checkpointing state at each step for durability.
5. The role of frameworks in agentic system development
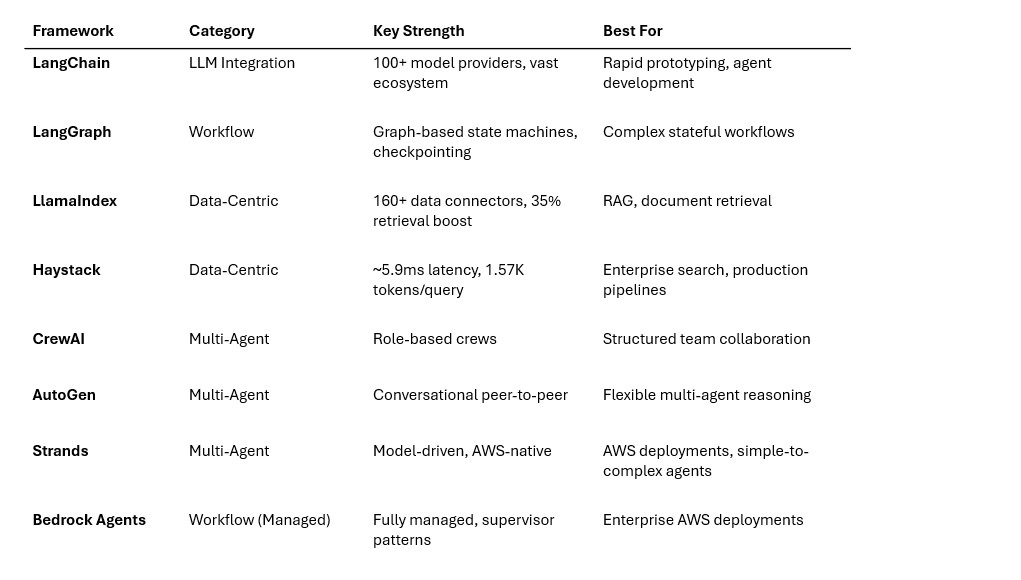
Now that we understand the architecture, let’s survey the framework landscape. Not all frameworks are created equal — they serve different purposes and excel at different tasks. Understanding the taxonomy helps you choose the right tool for the job.
What frameworks do for developers
At their core, agent frameworks reduce development time by providing ready-made abstractions for common patterns. The Strands Agents SDK team reports that customers achieved production deployment “in weeks” rather than months. As one customer put it: “What would traditionally take months of development, Strands allowed us to achieve in just 10 days”.
More specifically, frameworks handle the infrastructure that every agent needs: LLM communication, tool binding, memory persistence, state management, and error recovery. Without a framework, you’d rebuild this infrastructure for every project.
Framework taxonomy
The 2025-2026 framework landscape falls into four categories:
a. Workflow frameworks
Workflow frameworks give you explicit control over agent execution flow through graph-based or pipeline architectures.
LangGraph treats agent workflows as directed graphs where nodes represent computation steps and edges control flow. Unlike simple DAG (directed acyclic graph) systems, LangGraph supports cyclical graphs — meaning agents can loop back to previous steps, which is essential for the ReAct pattern. LangGraph 1.0 (released November 2025) provides “durable execution,” “human-in-the-loop,” “comprehensive memory,” and “debugging with LangSmith” as core features.
LangGraph is “trusted by companies shaping the future of agents — including Klarna, Replit, Elastic, and more”. LinkedIn uses it for “SQL Bot, an internal tool that transforms natural language into SQL queries,” and AppFolio’s Realm-X copilot “reportedly improved response accuracy by 2x after migrating to LangGraph”.
Amazon Bedrock Agents implements orchestration “primarily through the ReAct pattern by default” with an option for custom orchestration via AWS Lambda functions. Bedrock Agents supports multi-agent collaboration “allowing multiple specialized agents to work together on complex business challenges” under a supervisor agent. Amazon Bedrock AgentCore (announced late 2025) adds Policy (deterministic controls), Evaluations (13 pre-built evaluators), and episodic Memory for agents to learn from experience.
b. LLM integration frameworks
These frameworks focus on making it easy to connect LLMs with tools, data, and external systems.
LangChain is “one of the most widely adopted AI agent frameworks” with “a modular approach to building AI agents, allowing developers to chain large language models with external tools, memory modules, and APIs”. It supports integration with over 100 different language models. LangChain 1.0 introduced create_agent as “the fastest way to build an agent with any model provider,” along with standard content blocks for provider-agnostic model outputs.
LlamaIndex (formerly GPT Index) “focuses on optimizing document indexing and retrieval, making it the preferred choice for data-centric RAG applications”. It provides over 160 ready-made data connectors in LlamaHub and “achieved a 35% boost in retrieval accuracy” compared to baseline implementations.
c. Data-centric frameworks
Data-centric frameworks specialize in structuring, indexing, and retrieving data for LLMs.
LlamaIndex straddles both categories with its data-first design: data connectors for ingesting from APIs, PDFs, and SQL databases; hierarchical document indexing with metadata filtering; and adaptive query engines.
Haystack (by deepset) is “a powerful, modular framework often described as the Swiss Army knife of RAG”. It features explicit DAG pipelines for indexing, retrieval, re-ranking, and generation, plus built-in hybrid retrieval (BM25 + dense) and cross-encoder re-ranking. In benchmarks, Haystack achieves the lowest latency at approximately 5.9 milliseconds per query and the most efficient token usage at approximately 1,570 tokens per query.
d. Multi-agent collaboration frameworks
These frameworks coordinate multiple specialized agents working together.
CrewAI structures AI agents as specialized “crews” mimicking human teams, with “clear roles, tasks, and dependencies for coordinated execution”. It uses a coordinator-worker model where a planner delegates subtasks to role-specialized agents. CrewAI reportedly powers automations for PwC and IBM.
Microsoft AutoGen “enables multi-agent conversations where agents dynamically interact, negotiate, and iterate without rigid hierarchies” through peer-to-peer communication. AutoGen supports human-in-the-loop steps out of the box and is well-suited for “complex reasoning and stepwise decomposition”.
Strands Agents SDK is an open-source SDK by AWS that “takes a model-driven approach to building and running AI agents in just a few lines of code”. Multiple teams at AWS use Strands in production, including Amazon Q Developer, AWS Glue, and VPC Reachability
Analyzer. Strands 1.0 (July 2025) introduced four multi-agent primitives and supports the Agent-to-Agent (A2A) protocol.
Framework comparison
Decision guide: How to choose
Framework selection should be driven by your specific needs:
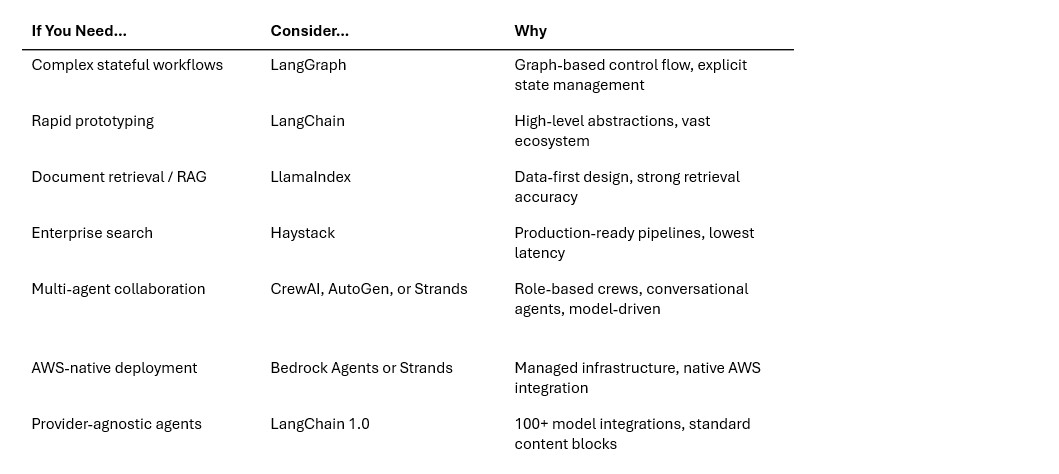
As Maxim’s framework guide recommends: “Start from tasks, not tech. List the top tasks your agent must perform and the non-functional constraints. Are you optimizing for latency under SLAs, or for correctness in long-horizon reasoning?”.
Many teams combine frameworks. “Many enterprises use LangChain for experimentation and then migrate to LangGraph for production orchestration. Others pair Haystack with Microsoft’s GraphRAG for thematic question-answering and compliance”.
6. Building agentic systems on AWS
In Module 1, we introduced the concept of AI agents—autonomous software systems that use large language models (LLMs) to reason, plan, and take actions in the real world. We explored how agents differ from traditional chatbots, examined the Thought-Action-Observation loop, and outlined the three-layer architecture (reasoning, orchestration, and tools) that underpins every agentic system.
Module 2 takes the next step: frameworks and building blocks. If Module 1 answered “What are agents?”, this module answers “How do we start building them?” We’ll go deeper into the patterns introduced in Module 1, explore the frameworks that make agent development practical, set up a working development environment, and connect agents to external systems through memory, tools, and models. By the end of this module, you’ll understand how to build agents with LangChain and Anthropic Claude.
What you’ll learn
- How AI agent frameworks differ from traditional software frameworks and why they’re essential for building agentic systems
- How to set up a development environment for building agents using LangChain, LangGraph, and Anthropic Claude
- How agents connect to external systems through memory, tool protocols (MCP, A2A), and multi-model architectures
Prerequisites
- Completion of Module 1 - Introduction to AI Agents recommended
- Basic Python programming knowledge
- An AWS account with Amazon Bedrock access enabled and IAM permissions for bedrock:InvokeModel (see Amazon Bedrock access setup)
- AWS credentials configured locally (via AWS CLI aws configure, IAM Identity Center, or environment variables)
- Python 3.10+ installed on your development machine
7. Agents and external systems
An agent is only as useful as the systems it can access. This section covers the three pillars of external connectivity: memory (how agents remember), tools (how agents act), and models (how agents think).
7a. Memory and data access
Memory gives agents the ability to maintain context across interactions and recall relevant information from past conversations.
Short-term memory (conversation context)
Short-term memory “tracks the ongoing conversation by maintaining message history within a session. LangGraph manages short-term memory as part of your agent’s state. State is persisted to a database using a checkpointer so the thread can be resumed at any time”.
LangChain provides four short-term memory strategies:
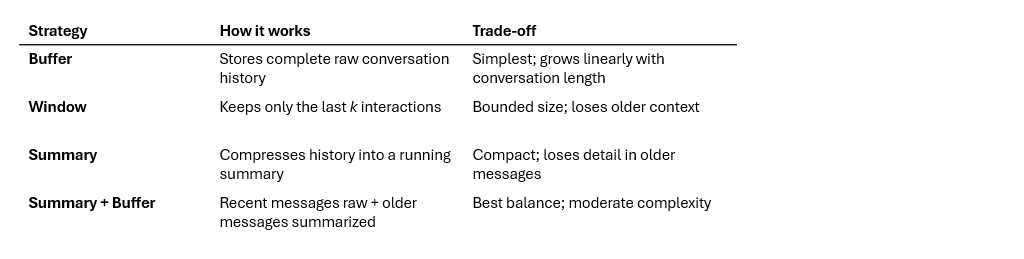
As conversations grow, “a full history may not fit inside an LLM’s context window, resulting in an irrecoverable error”. The summary and window strategies prevent this by keeping memory bounded.
Long-term memory (vector stores)
Long-term memory “stores user-specific or application-level data across sessions and is shared across conversational threads. It can be recalled at any time and in any thread”.
Vector store memory works by converting conversation messages into numerical vector embeddings, storing them in a vector database, and performing similarity searches when new queries arrive. This enables “semantic retrieval”—information is recalled based on meaning rather than recency.
Popular vector stores for agent memory include FAISS (in-memory, fast), Chroma (open-source, easy setup), Pinecone (managed, scalable), Milvus (high-performance), and
Weaviate (hybrid search). LangChain provides a unified vector store interface with methods including add_documents, delete, and similarity_search.
Claude’s context window and sub-agent architecture
Claude supports a 200,000-token context window natively—“meaning it can ingest enormous amounts of text (hundreds of pages) in one go”. Anthropic has experimented with a 1 million token context window, available in beta. Both Claude Sonnet 4.6 and Opus 4.6 support “200K and 1M context tokens (preview)” on Amazon Bedrock.
For agentic workloads that exceed even these limits, Anthropic uses sub-agent architectures: “The sub-agent can go off, blow up its context window figuring things out, report back to the main agent—‘here’s what I learned, here’s the things that matter’ — and the main agent can keep working and not take that context window hit”.
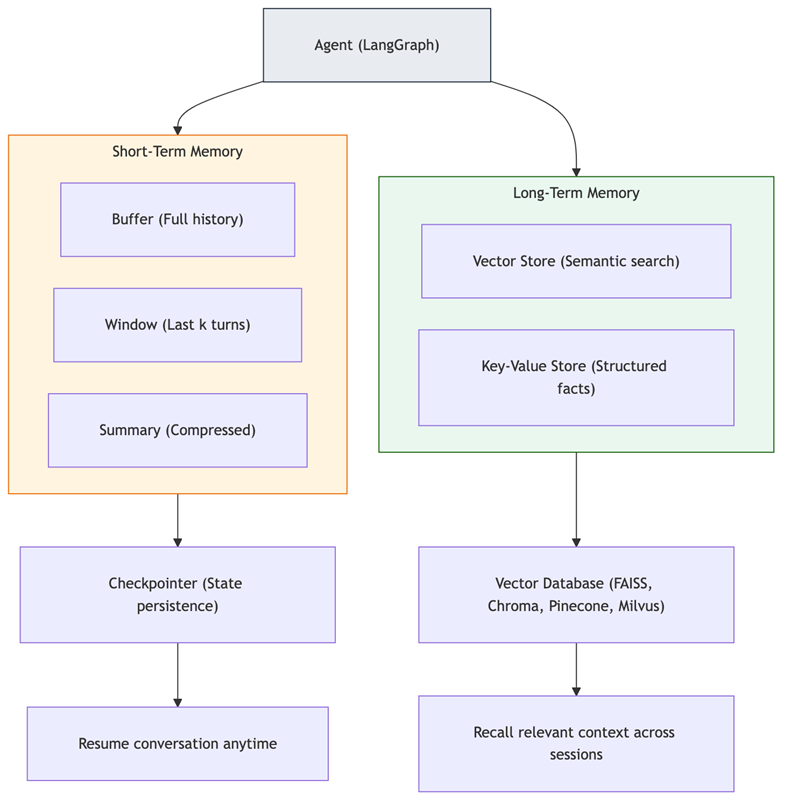
Diagram 6 - Figure 6: Agent memory architecture. Short-term memory maintains conversation context within a session (persisted via checkpointers). Long-term memory stores knowledge across sessions using vector databases for semantic retrieval.
The MemorySaver checkpointer stores conversation state in memory (for production, use SqliteSaver or PostgresSaver). The thread_id in the config identifies the conversation—using the same thread_id resumes the conversation with full history.
7b. Tools and integrations
Three emerging protocols are shaping how agents interact with tools, other agents, and payment systems.
MCP: Model Context Protocol
What it is: MCP is “an open standard that enables developers to build secure, two-way connections between their data sources and AI-powered tools”. Introduced by Anthropic in November 2024, MCP emerged from a developer’s “frustration with constantly copying code between Claude Desktop and his IDE”.
How it works - MCP uses a client-server architecture:
- Host application — The application housing the LLM (e.g., Claude Desktop, your agent)
- MCP client — Integrated within the host to handle connections with MCP servers
- MCP server — Exposes specific tools, resources, and prompts to AI applications
- Transport layer — STDIO for local servers, HTTP/SSE for remote servers
MCP servers expose capabilities through three primitives: tools (executable functions), resources (files and data), and prompts (templated instructions). The protocol uses JSON-RPC 2.0 for message exchange.
What problem it solves: MCP addresses the “N × M” integration problem. Instead of building N custom integrations for M tools, you build one MCP client and it can access thousands of MCP servers. As one review described: “Build one MCP server, and any MCP-compatible AI can use it. Build one MCP client, and it can access thousands of existing servers”.
Adoption (as of early 2026):
- More than 10,000 active public MCP servers - 97 million+ monthly SDK downloads across Python and TypeScript
- Adopted by ChatGPT, Cursor, Gemini, Microsoft Copilot, Visual Studio Code - OpenAI officially adopted MCP in March 2025
- In December 2025, Anthropic donated MCP to the Linux Foundation’s Agentic AI Foundation, co-founded by Anthropic, Block, and OpenAI, with support from Google, Microsoft, and AWS
A2A: Agent-to-Agent Protocol
What it is: A2A is “an open protocol designed to facilitate communication and interoperability between independent, potentially opaque AI agent systems”. Introduced by Google in April 2025 with 50+ technology partners.
How it differs from MCP: MCP connects agents to tools. A2A connects agents to other agents. Where MCP says “use this calculator tool,” A2A says “ask the finance agent to run this analysis”.
Key capabilities:
- Agent Cards — JSON descriptors detailing agent capabilities, endpoints, and requirements
- Task Management — Defined lifecycle states for tracking work across agents
- Flexible Interaction — Synchronous, streaming (SSE), and asynchronous push notifications
- Opaque Execution — Agents collaborate based on declared capabilities without sharing internal reasoning
A2A has grown to 150+ supporting organizations and has been contributed to the Linux Foundation. As Google states: “A2A complements Anthropic’s Model Context Protocol (MCP), which provides helpful tools and context to agents”.
x402: Payment Protocol for Agents
What it is: x402 is “a new open payment protocol developed by Coinbase that enables instant, automatic stablecoin payments directly over HTTP”. It revives the HTTP 402 “Payment Required” status code for the agentic era.
How it works: 1. Client sends an HTTP request to a protected endpoint 2. Server responds with 402 Payment Required, including payment details 3. Client constructs a signed payment payload using its crypto wallet 4. Client resends the request with an X-PAYMENT header 5. Server verifies and settles the payment on-chain (typically USDC) 6. Server returns the requested resource
Why it matters for agents: As agents begin to autonomously procure services — buying API calls, renting compute, purchasing data — they need a way to pay without human intervention. x402 makes this possible with sub-cent transaction costs.
Status: Launched May 2025, production-ready September 2025. By December 2025, x402 had processed 75 million transactions worth $24 million. Cloudflare has integrated x402 into its edge compute stack, and Google Cloud incorporated it into its Agent Payments Protocol (AP2).
How the protocols complement each other

Diagram: Protocol landscape — MCP + A2A + x402
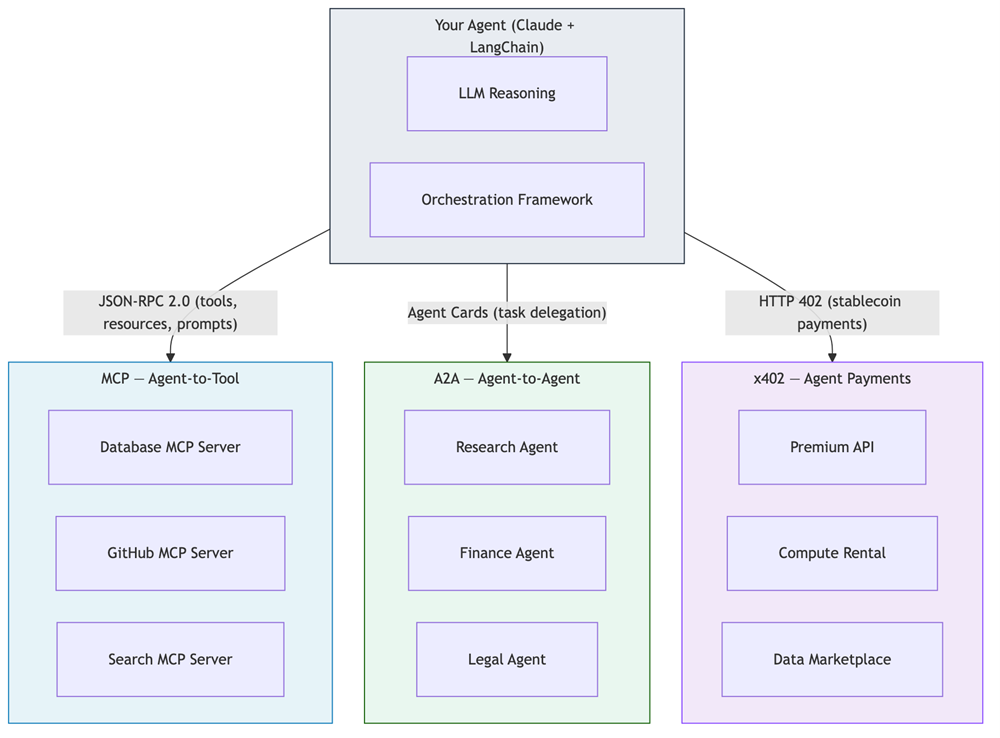
Diagram 7 - Figure 7: The three protocols serve complementary roles. MCP gives agents access to tools and data. A2A enables agents to delegate work to other agents. x402 allows agents to make autonomous payments for services.
7c. Models
The reasoning layer isn’t limited to a single model. Understanding the model landscape helps you choose the right model for each task.
Frontier models
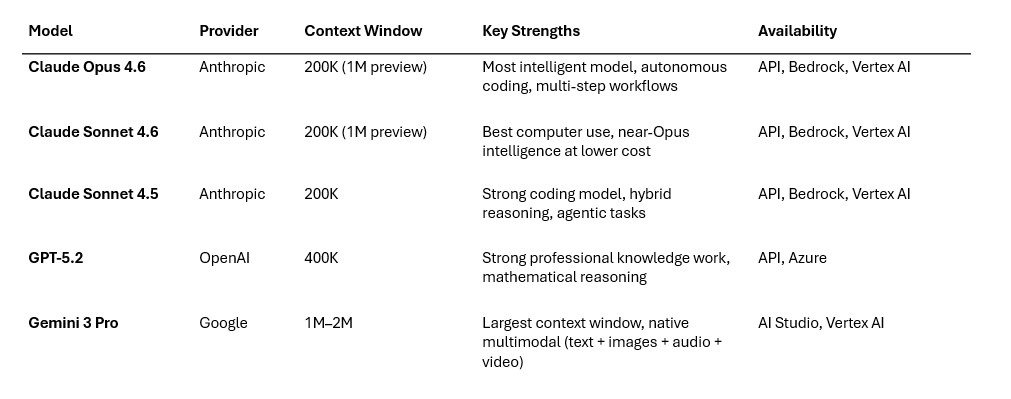
Claude models support tool use natively, with the ability to “interleave tool use and reasoning”. Claude Opus 4.5 scores 80.9% on SWE-bench Verified, a leading benchmark for real-world coding tasks.
Local models
For development, privacy, or cost reasons, you may want to run models locally:
A common hybrid approach: “Prototype in Ollama, scale in vLLM, embed in llama.cpp for edge deployment”. LangChain integrates with Ollama via langchain-ollama.
Beyond LLMs: Multi-model agents
Agents aren’t limited to text-generating LLMs. Modern agents leverage multiple model types:
- Vision Language Models (VLMs): Enable agents to understand images and screenshots. Claude supports screenshot interpretation and computer use; open-source options include Qwen3-VL and InternVL3.
- Speech Models: Whisper (speech-to-text), ElevenLabs (text-to-speech), and Kyutai’s Moshi (sub-120ms response times) enable voice-interactive agents.
- Embedding Models: Convert text into vectors for similarity search — essential for RAG and long-term memory.
- Specialized Models: Code generation, image generation (Runway, Sora), and domain-specific models for medical, legal, or financial tasks.
The emerging pattern is multi-model routing: “The most productive developers in 2026 aren’t choosing one model. They’re using the right model for each task” — for example, “Claude Sonnet for code generation, Claude Opus for complex reasoning, and Amazon Nova Canvas for image creation”.
8. Designing future-proof architectures
The agentic AI landscape is evolving rapidly — new models, new frameworks, and new protocols emerge every month. How do you build systems that survive these changes? The answer lies in modular design, clean abstractions, and emerging standards.
Modular design patterns
Production agentic systems follow the same principles that make any software maintainable:
- Single-responsibility agents: Each agent should do one thing well. A research agent researches. A coding agent writes code. A review agent reviews. This makes agents independently testable and replaceable.
- Clean tool boundaries: Separate workflow logic from tool implementations. If a tool changes its API, only the tool adapter needs updating—the agent’s reasoning logic stays the same.
- Tool-first design: Design your tool interfaces before building agent logic. Well-defined tool schemas are the contract between reasoning and action; poorly defined schemas are the #1 source of agent failures.
Abstraction layers for swapping components
Build your architecture so that models, tools, and frameworks can be swapped independently:
Model abstraction: Use ChatBedrockConverse to access any foundation model on Amazon Bedrock through a single, consistent interface. Switching models requires changing only the model_id — your agent code stays the same. LangChain 1.0 also provides init_chat_model for cross-provider abstraction beyond Bedrock.
Tool abstraction: MCP provides a universal tool interface. Instead of writing LangChain-specific tool wrappers, expose tools as MCP servers — any framework can consume them.
Framework abstraction: Amazon Bedrock AgentCore provides “framework-agnostic” agent hosting with Runtime (serverless hosting with Firecracker isolation), Gateway (centralized MCP tools), Memory, Identity (OAuth/IAM), Observability (CloudWatch/OTEL), and Policy (natural language guardrails).
Well-Architected — Sustainability Pillar: Reduce the environmental impact of your agentic workloads by right-sizing model selection. Use the smallest model that meets your accuracy requirements for each subtask. Cache frequently repeated tool results to avoid redundant inference calls. Design prompts to minimize unnecessary token generation — concise system prompts and structured output formats reduce both cost and compute.
Production readiness patterns
Moving from prototype to production requires systematic attention to failure modes. The AWS Well-Architected Framework provides a structured approach for evaluating and improving workloads across six pillars. The patterns below map directly to Well-Architected recommendations:
Well-Architected — Cost Optimization Pillar: Not every agent task requires a frontier model. Use a tiered model strategy: route simple classification or extraction tasks to smaller, cheaper models (e.g., Claude Haiku via Bedrock), and reserve larger models (Sonnet, Opus) for complex reasoning. Monitor InputTokenCount and OutputTokenCount CloudWatch metrics to identify cost hotspots. Amazon Bedrock’s on-demand pricing means you pay only for tokens consumed — but agentic loops with many iterations can accumulate significant token costs without visibility.
Well-Architected — Performance Efficiency Pillar: Choose the right model tier and inference configuration for your latency requirements. Amazon Bedrock supports streaming responses via InvokeModelWithResponseStream, which delivers first-token latency improvements for user-facing agents. For batch processing, use Bedrock batch inference. For latency-sensitive production workloads, evaluate Bedrock provisioned throughput to guarantee consistent response times.
Multi-agent architecture patterns
LangChain documents four multi-agent architecture patterns that address different coordination needs:
- Subagents (centralized orchestration) - A lead agent decomposes tasks and delegates to specialized subagents. Each subagent has its own tools and reasoning but reports back to the lead. Anthropic’s multi-agent system (Claude Opus 4 lead + Claude Sonnet 4 subagents) outperformed single-agent approaches by 90.2% on internal evaluations.
- Skills (progressive disclosure) - The lead agent has access to a library of “skills” — pre-built capabilities it can invoke as needed. Skills are simpler than full agents; they execute a defined workflow and return a result.
- Handoffs (state-driven transitions - Agents transfer control to each other based on the conversation state. Common in customer service: a triage agent routes to a billing agent or a technical support agent based on the user’s needs.
- Router (parallel dispatch) - A router agent dispatches the query to multiple specialist agents in parallel, then synthesizes their responses. Useful when a query spans multiple domains (e.g., “How does this code change affect performance, security, and cost?”).
Diagram: Single agent architecture
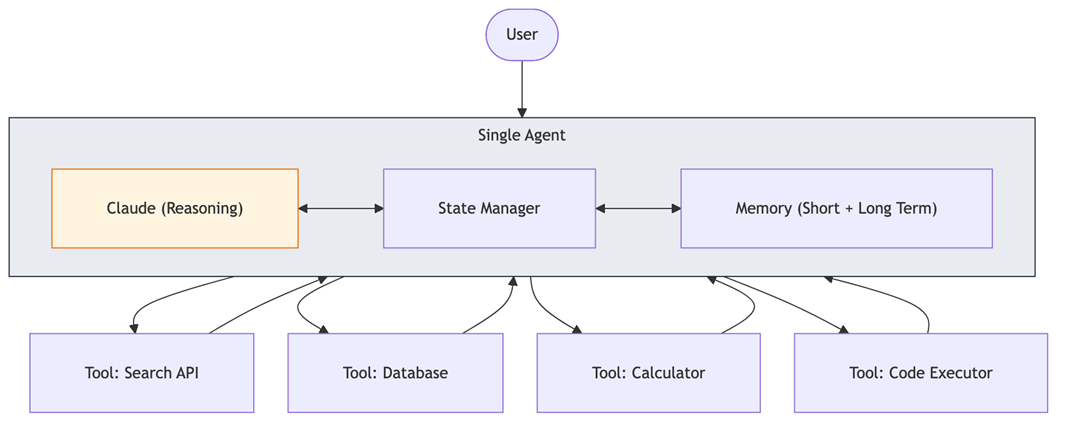
Diagram 8 - Figure 8: Single agent architecture. One LLM with state management, memory, and multiple tools. This is the right starting point for most projects — don’t add complexity until you need it.Diagram:
Diagram: Router architecture pattern
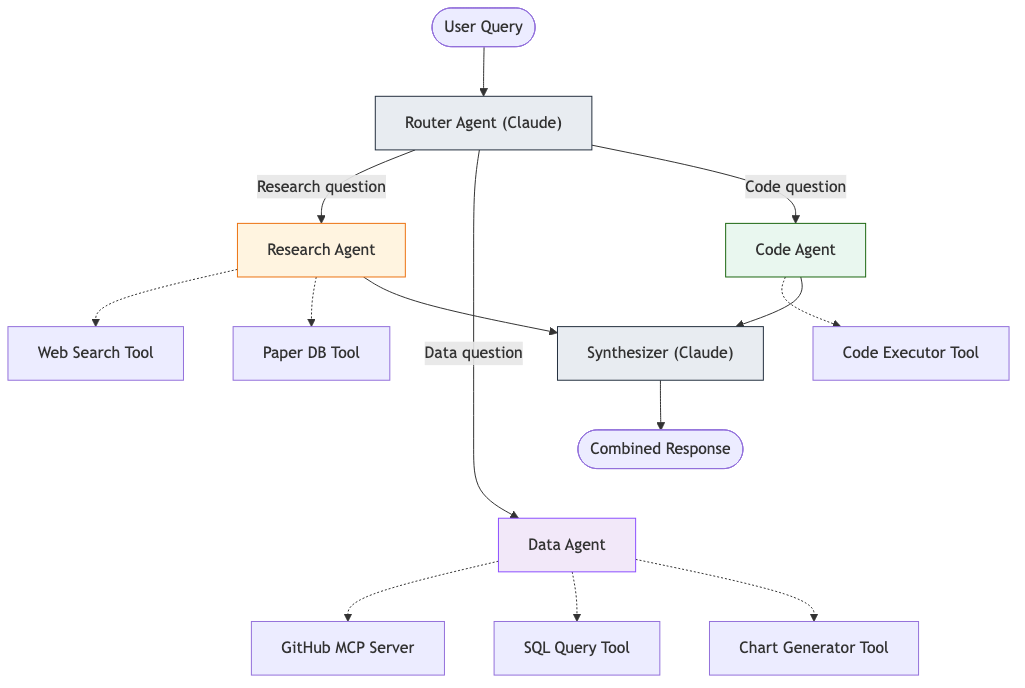
Diagram 9 - Figure 9: Router architecture. The router agent dispatches to specialists based on query type. Each specialist has its own tools. A synthesizer combines results into a unified response.
Featured AI tools in AWS Marketplace
Build with foundation models, deployment platforms, and AI infrastructure — all available through your AWS account.
Why AWS Marketplace for on-demand cloud tools
Free to try. Deploy in minutes. Pay only for what you use.
Featured tools are designed to plug in to your AWS workflows and integrate with your favorite AWS services.
Subscribe through your AWS account with no upfront commitments, contracts, or approvals.
Try before you commit. Most tools include free trials or developer-tier pricing to support fast prototyping.
Only pay for what you use. Costs are consolidated with AWS billing for simplified payments, cost monitoring, and governance.
A broad selection of tools across observability, security, AI, data, and more can enhance how you build with AWS.
Continue your journey
Module 2 builds your mental model. Continue with Module 1 foundations or Module 3 evaluation.