Agent memory systems
Design short-term, long-term, and episodic memory that preserves context across sessions and turns stateless agents into persistent ones.
Overview
Technical workshop: Designing persistent memory for stateful agents
Your agents forget everything the moment a session ends. This workshop tackles session amnesia head-on: short-term, long-term, and episodic memory architectures using Amazon Bedrock and tools from across the AI landscape available in AWS Marketplace. Walk away with agents that remember what they’ve learned — across sessions, across tasks, and across agent boundaries.
📅 June 30, 2026
🕐 10:00 AM PT
🎓 Practical demos
📊 Intermediate
✓ No cost to register
Agent memory architecture: From session amnesia to persistent context
Move agents from stateless defaults to persistent, context-aware systems. Design memory architectures that maintain continuity across sessions, share knowledge across agent boundaries, and reduce token consumption.
Topics covered:
- Short-term, long-term, and episodic memory: a practitioner’s taxonomy with decision criteria for choosing the right pattern based on access frequency, latency, and cost
- Seven vector databases compared: purpose-built, document-model, and graph-based options evaluated against real agent memory workloads
- Multi-agent memory coordination — designing shared context and isolation boundaries so agents collaborate without contaminating each other’s state
- Memory architecture trade-offs: durability vs. speed, managed vs. self-hosted, and the infrastructure decisions that shape how agents remember
Featured AI tools in AWS Marketplace
Top tools from across the AI landscape — available through your AWS account.
Featured tools in this module:

Page topics
- Introduction
- Agent memory can be organized along two independent dimensions
- In-context working memory
- Short-term session memory
- Long-term semantic memory and vector stores
- Extending memory capabilities: Redis Cloud and MongoDB Atlas
- Graph RAG: relationship-aware retrieval with Neo4j
- Shared cross-agent memory
- Memory as a first-class data asset
- Extracting and consolidating memory
- Conclusion and looking ahead
Introduction
Memory is the difference between an agent that handles a task and an agent that builds understanding. Without it, every interaction starts from an empty slate: the agent has no knowledge of what the user asked yesterday, no record of what was decided in the last workflow run, no awareness of what infrastructure was deployed last week, and no ability to notice that the same problem has occurred three times this month. These aren’t minor inconveniences; they fundamentally constrain what an agent can accomplish in the context of ongoing, evolving work.
Memory has appeared throughout this series, but always at the surface level required by the topic at hand. Module 2 introduced LangGraph’s checkpointer as the mechanism for session memory. Module 3 touched on long-term knowledge stores as context for evaluation. Module 4 introduced the state plane as the shared memory layer in multi-agent systems. Module 6 discussed workflow state persistence as the foundation of durable execution. Each of these is a facet of memory, but none constitutes a complete treatment of memory as an architectural concern.
This module provides you with just that. Memory in agentic systems isn’t a single mechanism; it’s a family of mechanisms with different duration, scope, retrieval characteristics, operational requirements, and governance obligations. Understanding these distinctions and knowing which combination to use for a given system is one of the most consequential architectural decisions in agentic system design.
The module proceeds in two arcs. The first arc, covering Sections 1 through 6, is a technical treatment of each memory type: what it is, how it works at the implementation level, what the tradeoffs are, and how it’s deployed on AWS. The second arc, covering Sections 7 through 9, addresses memory as a data discipline: how to govern it, how to consolidate it, and how to design a coherent memory architecture for a real system. The module concludes with a design exercise applying all these concepts to the DevOps Companion.
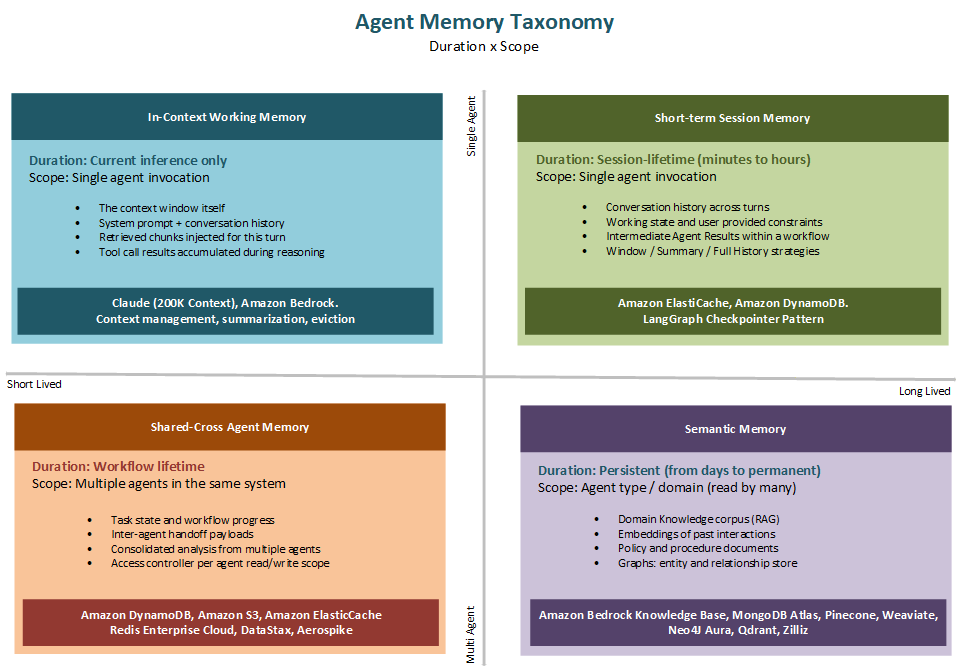
Figure 1. Taxnomy of agent memory
Throughout this module, you'll work with AWS tools like Amazon Bedrock, Amazon DynamoDB, and Amazon ElastiCache alongside AWS Marketplace partner solutions including Redis Cloud, MongoDB Atlas, Pinecone, Weaviate, Qdrant, Zilliz Cloud, and Neo4j AuraDB — each introduced in the context of a specific memory challenge it solves.
Agent memory can be organized along two independent dimensions
The first is duration: how long does the memory persist? Memory can last for the duration of a single model inference, for the duration of a user session, for the operational lifetime of the system, or permanently. The second is scope: which agents or sessions can access the memory? Memory can be private to a single agent invocation, shared within a single user session, shared across all instances of a specific agent type, or shared across the entire multi-agent system.
Plotting these two dimensions against each other produces a two-by-two matrix with four quadrants. In practice, the boundaries between quadrants aren’t sharp — a session memory that’s archived becomes a form of long-term memory, and cross-agent shared memory can have session-scoped or permanent variants — but the taxonomy provides a useful framework for making deliberate architectural choices rather than reaching for the first available mechanism.
In-context working memory
The most immediate form of agent memory is the context window itself. When a model processes a request, everything it can directly reason about — the system prompt, the conversation history, retrieved document chunks, tool call results, intermediate reasoning steps — is held in the context window. From the model’s perspective, this is its working memory: the complete set of information available for reasoning at this moment.
In-context working memory is fast, there’s no retrieval latency, and rich, because the model can reason over any part of it with equal ease. Its limitations are capacity and cost: context windows are measured in tokens, each token costs money to process, and every token in the context window contributes to the latency of the model response. Managing context window occupancy and deciding what to include, what to summarize, and what to evict, is therefore a design decision with direct operational consequences.
Short-term session memory
Session memory persists for the duration of a user interaction. It’s the mechanism by which an agent remembers what was said earlier in the same conversation, what tasks are in progress, and what constraints the user has established. Session memory is typically stored externally in a database, a cache, or an in-process data structure and loaded into the context window at the start of each turn.
The distinction between session memory and in-context working memory is temporal: working memory exists only during a single model inference, while session memory persists between inferences within the same session. A well-designed session memory system persists the full conversation history, the current task state, and any user-established preferences, loading the most relevant subset into the context window for each turn rather than loading the entire history unconditionally.
Long-term semantic memory
Long-term semantic memory is the persistent knowledge store that an agent draws on to answer questions, ground its reasoning, and apply domain expertise. It’s populated through an offline ingestion process; documents are chunked, embedded, and stored in a vector database and accessed at inference time through semantic retrieval: the agent’s query is embedded, and the vector database returns the chunks whose embeddings are most like the query embedding.
Long-term semantic memory differs from session memory in two ways: duration (it persists indefinitely, surviving session boundaries and system restarts) and retrieval mechanism (semantic similarity rather than direct lookup). It’s the foundation of Retrieval-Augmented Generation (RAG), the technique of grounding model responses in retrieved facts rather than relying solely on the knowledge embedded in the model’s weights.
Shared cross-agent memory
Shared cross-agent memory is the state plane introduced in Module 4: the shared data infrastructure that allows multiple agents in a multi-agent system to coordinate through a common store of facts, task records, and intermediate results. It differs from session memory in scope; multiple agents read and write it and from long-term semantic memory in its structure, it holds structured records that agents update as workflow progresses, rather than document embeddings queried by semantic similarity.
Shared cross-agent memory is the glue that binds multi-agent workflows together. Without it, agents can only communicate through direct message passing, which creates tight coupling and makes the system fragile. With it, agents can be developed and deployed independently while still sharing the information they need to coordinate effectively.
In-context working memory
The context window is the agent’s immediate cognitive workspace. Understanding how to manage it effectively is foundational to building agents that perform well consistently, not just on short interactions but on complex, multi-turn, tool-heavy workflows where context pressure is a constant concern.
Context window architecture on Amazon Bedrock
Claude models on Amazon Bedrock support a context window of 200,000 tokens (1M beta). To put this concretely: 200,000 tokens correspond to roughly 150,000 words of English text, or approximately 500 pages of a standard book. This is large enough to hold entire codebases for medium-sized projects, multiple lengthy documents simultaneously, and hundreds of turns of conversation history.
Despite this generous size, context management still matters for two reasons. First, every token in the context window adds latency and cost. A response with 200,000 tokens in context takes longer and costs more than the same response with 10,000 tokens, even if the additional tokens aren’t directly relevant to the query. Second, model attention isn’t uniform: research consistently shows that models attend more strongly to content at the beginning and end of the context window, with content in the middle receiving less attention. A context window filled with marginally relevant content may cause the model to underweight the most important information.
What to include in the context window
The context window for an agent turn typically contains several categories of content. The system prompt defines the agent’s role, capabilities, constraints, and output format. It’s present at the start of every context window and should be as concise as possible while remaining complete. The conversation history provides the short-term session memory for the current interaction. Depending on the length of the conversation, the full history may be included, a windowed subset may be included, or a summary may substitute for the older portion. Retrieved context holds the document chunks returned by the long-term semantic memory retrieval step. Tool call results hold the structured outputs of tool calls made earlier in the current turn, these must be included so the agent can reason about the tool outputs and incorporate them into its response.
The practical guidelines include only what the model needs to reason in this specific turn, and prefer structured, dense representations over verbose, redundant ones. A structured summary of a three-hundred-line file is more context-efficient than the raw file content if the agent only needs to reason about the file’s high-level properties.
Context window management strategies
Four strategies are commonly used to manage context window occupancy as conversations grow long.
Full history retains every message from the beginning of the conversation. It’s the simplest strategy and appropriate for short conversations, but context grows linearly with the number of turns and eventually exceeds capacity or becomes prohibitively expensive.
Windowed history retains only the most recent k turns. This keeps the context window constrained at the cost of losing older context. It works well when the most recent turns are the most relevant, true for many conversational interactions, but fails for workflows where a decision made many turns ago remains relevant.
Summary history compresses older turns into a rolling summary. When the conversation history exceeds a length threshold, a summarization step compresses the oldest portion into a paragraph-length summary that captures the key facts and decisions. The summary replaces the raw older turns in the context window. This retains some information about older context at the cost of losing detail. Amazon Bedrock’s text generation capability is used to run the summarization step as a lightweight inference call before the main agent turn.
Hybrid summary-plus-window combines the previous two: recent turns are retained in full, while older turns are compressed into a summary. This provides the best balance of recency and long-term context, at the cost of additional complexity. LangChain’s ConversationSummaryBufferMemory implements this strategy and integrates with LangGraph’s state management.
Context window design principle
Design for the specific information requirements of each agent role. An agent that analyzes code needs the code and its immediate dependencies in context; it doesn’t need the full conversation history. An agent that maintains a dialogue with a user needs the conversation history; it doesn’t need raw code files. Specialization, the principle that drives domain-specific agent design in Module 5 also applies to context management: each agent should be given exactly the context it needs and no more.
Short-term session memory
Session memory solves a specific problem: the model has no native memory between inferences. Each call to the Amazon Bedrock model API is stateless, it receives a context window and returns a response, with no awareness of previous calls. Session memory is the mechanism by which the application layer reconstructs the relevant history and loads it into the context window for each new turn, creating the experience of continuity from the model’s perspective.
LangGraph checkpointer as the session memory implementation
In LangGraph-based agents, session memory is implemented through the checkpointer abstraction. A checkpointer is a persistent store that serializes and saves the agent’s state object at the end of each node execution in the graph. When the graph is resumed for the next turn, identified by a thread ID that corresponds to the user session, the checkpointer loads the saved state and makes it available as the starting state for the new execution.
The state object in a LangGraph agent is a typed data structure containing everything the agent needs to maintain context across turns: the message history, the current task state, any user-established preferences, and any intermediate results that need to persist between turns. The checkpointer serializes this entire object, not just the message history, to the backing store ensuring that complex multi-turn workflows can be interrupted and resumed without losing any working state.
LangGraph provides checkpointer implementations for several backing stores. The in-memory checkpointer is appropriate for development but doesn’t survive process restarts. The Amazon DynamoDB checkpointer persists state to Amazon DynamoDB, providing durability and the ability to distribute the agent across multiple Lambda invocations without losing session state. The Redis checkpointer writes to Redis Cloud or Amazon ElastiCache, providing sub-millisecond load latency at the cost of the volatility inherent in a cache, appropriate for session state that can be reconstructed if lost, but not for workflow state that must survive cache evictions.
Storage backend selection
The choice of session memory backend depends on the durability and latency requirements of the specific agent. For agents handling user-facing conversational interactions where session state can be reconstructed from the user if lost, Amazon ElastiCache (Redis) is the right backend: It provides the sub-millisecond read latency that conversational agents require, and it supports TTL-based automatic expiration of sessions that have been inactive for a configured period.
For agents handling multi-step workflows where session state must survive process failures and can’t be reconstructed without re-executing completed steps, Amazon DynamoDB is the right backend. DynamoDB provides strongly consistent reads, automatic durability, and the ability to query sessions by attributes other than the primary key, useful for operations teams who need to inspect the state of in-progress workflows. DynamoDB On-Demand capacity mode is appropriate for most agentic workloads, where session creation rates are variable and capacity planning is difficult.
For agents requiring extremely high throughput session memory, handling thousands of concurrent sessions with sub-millisecond latency requirements, Redis Cloud, available in AWS Marketplace, provides advanced Redis features including clustering, active-active geo-replication, and enterprise support that exceed ElastiCache’s capabilities.

Session identity and multi-session scenarios
Each session is identified by a thread ID, a unique string assigned when the session is created and passed with every subsequent turn. The thread ID is the key under which the session state is stored in the backend. The application layer is responsible for generating thread IDs, typically using a UUID, and for associating them with user sessions in whatever authentication and session management system the application uses.
Multi-session scenarios arise when a single user has multiple concurrent sessions, a user with multiple browser tabs open, each running a separate agent workflow. Each tab has its own thread ID and its own independent session state. The sessions don’t share state by default; if the application requires cross-session context, a user preference established in one session should be available in all sessions, for example, this requires a separate long-term memory layer, not session memory.
Long-term semantic memory and vector stores
Long-term semantic memory lets agents retrieve relevant information from large knowledge corpora at inference time. The retrieval is semantic, meaning-based rather than keyword-based, which lets agents find relevant information even when the user’s query doesn’t share exact vocabulary with the stored documents. This is the foundational capability that makes Retrieval Augmented Generation (RAG) practical for knowledge-intensive agent applications.
How vector embeddings work
An embedding is a numerical representation of a piece of text as a point in a high-dimensional vector space, where texts with similar meanings are mapped to nearby points. The embedding model, a neural network trained specifically for this purpose learns to place semantically related texts close together and semantically unrelated texts far apart.
Two texts can be compared by computing the distance between their embedding vectors. A small distance, typically measured as cosine similarity, which gives a value between -1 and 1 indicates semantic similarity. A large distance indicates semantic dissimilarity. This lets retrieval be formulated as a nearest-neighbor search: given the embedding of a query, find the k document embeddings that are closest to it in the vector space.
Amazon Bedrock provides two embedding models for RAG systems. Amazon Titan Text Embeddings v2 produces 1,024-dimensional embeddings optimized for English-language retrieval tasks, with strong performance on technical documentation and conversational queries. Cohere Embed Multilingual v3 produces 1,024-dimensional embeddings that support over 100 languages, making it the right choice for multilingual knowledge bases. Both are accessed through the Amazon Bedrock InvokeModel API and can be integrated with any vector store that accepts numerical embedding vectors.
Vector index architectures
A vector database stores document embeddings and provides efficient approximate nearest neighbor (ANN) search, finding the k most similar embeddings to a query vector without examining every stored embedding. The efficiency of this search depends on the indexing structure used. Three index architectures are in common use.
The flat index stores all embeddings without any additional structure and performs exact nearest-neighbor search by comparing the query embedding to every stored embedding. It provides perfect recall but doesn’t scale: search time grows linearly with the number of stored embeddings. Flat indexes are appropriate for small knowledge bases with fewer than one hundred thousand documents.
Hierarchical Navigable Small World (HNSW) is the most widely used ANN index for general-purpose semantic retrieval. It constructs a multi-layer graph where each node represents a document embedding and edges connect nearby documents at multiple granularities. Search navigates this graph efficiently, typically examining only a small fraction of stored embeddings to find high-quality approximate nearest neighbors. HNSW provides excellent recall (typically above 95%) with search times that grow linearly rather than logarithmically with the number of stored embeddings, making it practical for knowledge bases with tens of millions of documents. Pinecone, Weaviate, and Qdrant all use HNSW as their primary index type.
Inverted File Index (IVF) partitions the embedding space into clusters and assigns each document to its nearest cluster centroid. At query time, the query is assigned to the nearest clusters and only the documents within those clusters are compared to the query. IVF provides good recall at lower memory cost than HNSW for very large datasets, at the cost of requiring an offline training step to learn the cluster centroids. Zilliz Cloud (managed Milvus) provides IVF-based indexes alongside HNSW, making it a strong choice for very large-scale deployments where memory efficiency is a priority.
Hybrid search: combining semantic and keyword retrieval
Pure semantic search is excellent at finding conceptually related content but sometimes misses documents that contain the exact keywords the user is looking for, particularly for proper nouns, technical identifiers, and domain-specific terminology that the embedding model may not represent well. Keyword search, implemented through BM25 (Best Matching 25), is excellent at exact keyword matching but can’t find documents that express the same concept in different words.
Hybrid search combines both approaches. Each query is processed by both the semantic retrieval pipeline and the BM25 keyword pipeline, producing two ranked lists of results. The lists are merged using Reciprocal Rank Fusion (RRF), which assigns each document a score based on its rank in each list. Documents that appear highly in both lists receive the highest combined scores. The merged, re-ranked list is returned as the retrieval result.
Weaviate provides particularly strong hybrid search capabilities out of the box, with automatic BM25 index maintenance alongside the vector index and configurable alpha parameters that control the relative weight of semantic versus keyword results. Amazon Bedrock Knowledge Bases, which uses Amazon OpenSearch Serverless as its underlying storage layer, also supports hybrid search through the combination of OpenSearch’s BM25 engine and its vector search capability.
Re-ranking for retrieval quality
Even with hybrid search, the top-k results returned by the vector database may include irrelevant documents that happen to have similar embeddings to the query. Re-ranking adds a second-stage relevance assessment using a cross-encoder model, a model that takes a query and a candidate document together as input and outputs a relevance score, allowing much more nuanced relevance assessment than the embedding similarity computation that drives initial retrieval.
Cross-encoder re-ranking is computationally expensive, each candidate document must be processed independently with the query so it’s applied only to the top-k results from the initial retrieval, not to the entire knowledge base. A typical configuration retrieves the top 20 candidates from the vector database and re-ranks them with a cross-encoder model to produce the top 5 results actually injected into the context window. Amazon Bedrock Knowledge Bases supports re-ranking through its built-in reranking configuration, enabling high-quality retrieval without requiring a separate re-ranking service.
Vector store selection
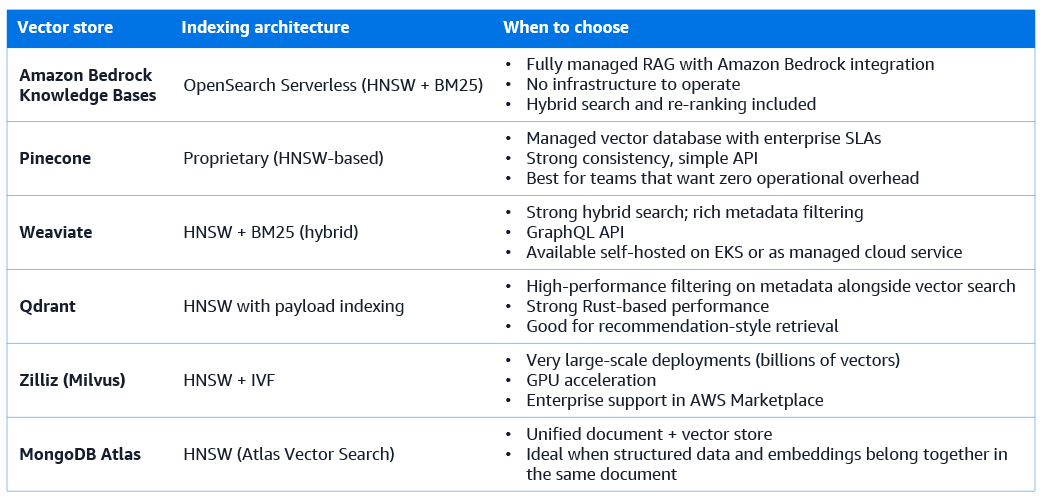
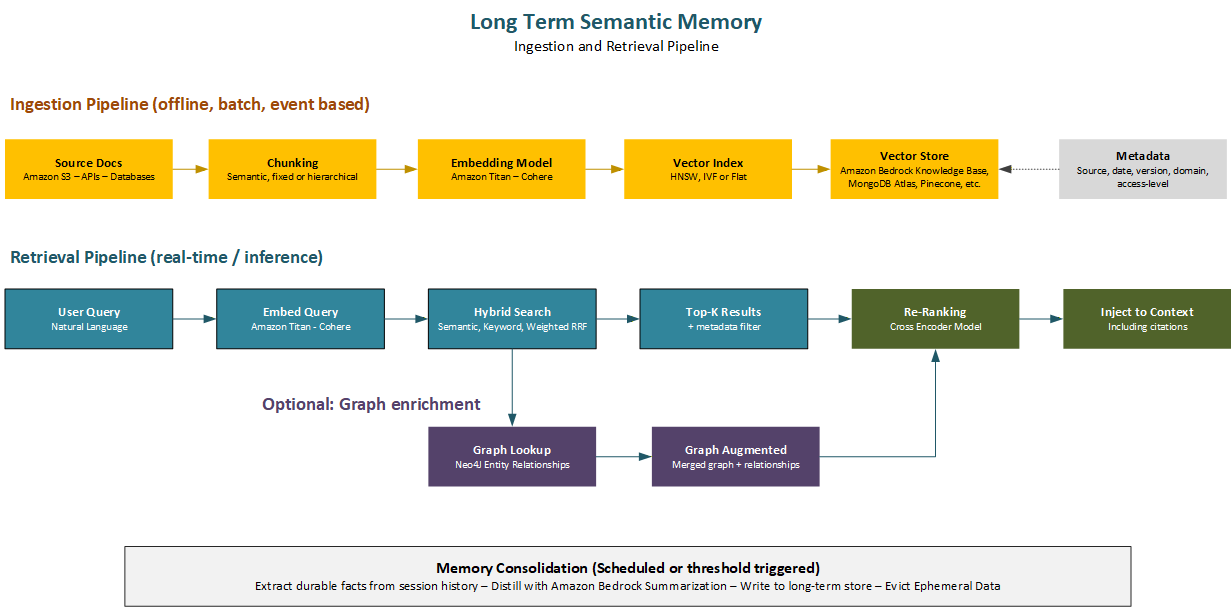
Figure 2. Long-term semantic memory
Extending memory capabilities: Redis Cloud and MongoDB Atlas
AWS native services cover the foundational requirements for most memory scenarios. Amazon ElastiCache provides managed Redis-compatible caching and Amazon Bedrock Knowledge Bases provides a fully managed RAG stack. But two products available in AWS Marketplace, Redis Cloud and MongoDB Atlas, extend the native capabilities in ways that matter at scale and in production-grade agentic deployments. This section covers each partner’s distinct role: Redis Cloud for short-term session memory at high performance, and MongoDB Atlas for long-term memory that unifies document storage with vector retrieval.
Redis Cloud for short-term memory
Short-term session memory has two non-negotiable requirements: low latency and automatic expiry. An agent that pauses for 50 milliseconds to retrieve the last two turns of conversation will feel sluggish in an interactive context. A session store that accumulates millions of stale sessions without cleanup will balloon in cost and eventually degrade under pressure. Redis — the in-memory data structure store — was designed around exactly these constraints, and Redis Cloud, available in AWS Marketplace, extends the open-source foundation with the operational characteristics required for high-scale, production agentic deployments.
Amazon ElastiCache for Redis is the right default for most teams: it’s managed, it integrates directly with IAM, and it eliminates cluster-level operations. Redis Cloud becomes relevant when the session memory requirements outgrow what a single ElastiCache cluster can offer. The specific capabilities that Redis Cloud adds beyond ElastiCache are active-active geo-replication, which keeps session state synchronized across multiple AWS regions so that a user whose request is routed to a different region mid-session doesn’t lose context; Redis on Flash, which extends the effective memory footprint by tiering less-frequently accessed session data to NVMe SSDs without material latency increase; and the Redis Data Integration pipeline, which can propagate session state changes to downstream systems in near real time without requiring the agent to manage that propagation explicitly.
From an integration standpoint, the LangGraph Redis checkpointer works identically against both ElastiCache and Redis Cloud. The connection string and authentication parameters change; the application code does not. This means teams can start with ElastiCache, validate that the session memory pattern works, and migrate to Redis Cloud when throughput or geo-distribution requirements emerge, without rearchitecting the agent logic.
Redis also provides native support for the data structures that agentic session state commonly requires beyond simple key-value storage. Hash types map directly to agent state objects with named fields. Sorted sets enable efficient retrieval of the most recent k turns from a session history, supporting windowed history strategies without requiring a full history scan. Streams provide an append-only log of session events that can be replayed for debugging or audit purposes. These built-in data structure semantics reduce the amount of serialization and deserialization logic that agent implementations need to manage.
MongoDB Atlas for long-term memory
Long-term memory is the persistent knowledge store that an agent draws on across sessions, workflows, and system restarts. In most RAG architectures, the knowledge base is a specialized vector database separate from the operational data store that holds structured records about users, deployments, incidents, and configuration. This separation creates friction: when an agent needs to retrieve both a semantic match from the knowledge base and a structured record from the operational store, it must execute two separate queries against two separate systems, then synthesize the results. MongoDB Atlas eliminates this friction by serving both roles from a single platform.
MongoDB Atlas Vector Search, the vector retrieval capability built into Atlas, uses an HNSW index to serve approximate nearest neighbor queries against embedding vectors stored as fields within regular MongoDB documents. This means a document that represents a deployment record can contain both the structured metadata about the deployment—timestamp, environment, services affected, outcome—and the embedding vector of its textual description, all within the same document. A query that asks “find deployments similar to this one that affected the payments service” can be expressed as a single Atlas query that filters on the structured metadata field and retrieves by vector similarity simultaneously, without joining across two stores.
This unified data model maps naturally to the memory consolidation pattern described in Section 8. When the nightly consolidation workflow extracts durable facts from session histories, it writes structured memory records to MongoDB Atlas documents. Each document stores the extracted facts in queryable fields alongside the embedding vector of the record’s text, making it retrievable both by exact attribute lookup—“find all records related to user X for service Y”—and by semantic similarity—“find records conceptually similar to this incident description.” A single store serving both query patterns is simpler to operate, simpler to govern with consistent retention policies, and simpler to reason about for auditing purposes.
MongoDB Atlas is available in AWS Marketplace and deploys into VPC-peered configurations that keep traffic off the public internet. Atlas Search and Atlas Vector Search are available without additional infrastructure configuration; both are enabled at the collection level and maintained automatically as documents are inserted or updated. For teams using LangChain, the MongoDBAtlasVectorSearch integration wraps the Atlas Vector Search API and makes it a drop-in replacement for any other LangChain-compatible vector store, including Bedrock Knowledge Bases, meaning existing retrieval chains require minimal modification to adopt Atlas.
How Redis and MongoDB fit together in a complete memory architecture
Redis and MongoDB are not competitors in this architecture; they occupy different tiers of the memory stack. Redis handles the hot path: the sub-millisecond reads that keep conversational agents responsive, the TTL-managed expiry that keeps the session store bounded, and the high-throughput writes that accompany multi-agent workflows executing many turns per second. MongoDB handles the cold path: the durable, richly structured records that persist across sessions, support complex filtered queries alongside semantic similarity retrieval, and provide the governance surface—consistent TTL policies, change streams for audit, and field-level access control—that long-term memory requires.
The hand-off between the two tiers happens at session close. When a session ends—explicitly by the user or implicitly by TTL expiry in Redis—the nightly consolidation workflow reads the session history from Redis (or from the DynamoDB workflow store), extracts durable facts, and writes the consolidated record to MongoDB Atlas. From that point forward, the session data no longer needs to live in the low-latency tier; it lives in the durable document store where it can be retrieved semantically in future sessions. The Redis key is expired and the memory footprint is reclaimed.
Graph RAG: relationship-aware retrieval with Neo4j
Vector retrieval is the right tool when the retrieval problem is fundamentally about meaning: find content that is conceptually similar to this query. But there is a second class of retrieval problem that vector similarity handles poorly: given an entity, find other entities that are structurally related to it, and reason about the nature of those relationships. A microservice architecture has dependency relationships. A deployment history has causal relationships between changes and incidents. An organization has ownership relationships between teams, repositories, and services. These relationships are not well-expressed as geometric proximity in a vector space. They are first-class structural facts, and they require a data model built around explicit relationships rather than implicit similarity.
Graph RAG is the retrieval pattern that addresses this gap. It combines graph traversal over a property graph with semantic vector search, allowing an agent to answer questions that require both kinds of reasoning: find documents semantically related to this topic, but constrain the search to nodes that are within two hops of this specific entity in the dependency graph. The result is a retrieval pipeline that is simultaneously relationship-aware and meaning-aware, more precise than pure vector retrieval for structured domains, and richer than pure graph traversal for open-ended questions.
How graph databases model structured knowledge
A graph database represents the world as a collection of nodes (entities) and edges (typed, directional relationships between entities). Each node carries a label that identifies its type—Service, Repository, Deployment, Team, Incident — and a set of properties that describe it: name, version, environment, creation timestamp. Each edge carries a relationship type — DEPENDS_ON, OWNS, CAUSED, DEPLOYED_TO — and can itself carry properties such as the timestamp a dependency was introduced or the confidence score of a causal inference.
This explicit-relationship model is what makes graph databases uniquely efficient for traversal queries: find all Service nodes reachable from the authentication service within three DEPENDS_ON hops; find all Deployments that share at least one Infrastructure node with this deployment; find the shortest causal chain between this configuration change and this incident. These queries require navigating relationship structure, and graph databases are built to navigate it efficiently without the full-table scans that equivalent queries would require in a relational store.
For agentic systems, the entity types that benefit most from graph representation are those with many-to-many relationships, those where the relationship itself carries meaningful attributes, and those where multi-hop traversal is a natural part of answering operational questions. In the DevOps domain, service dependencies, infrastructure topology, deployment history, and incident causality all fit this description. Storing these as a graph lets agents ask questions about the structure directly rather than trying to infer structure from unstructured text via vector retrieval.
The Graph RAG retrieval pattern
Graph RAG extends the standard RAG pipeline with two additional steps that leverage the graph structure. The standard pipeline runs: embed the query, retrieve the top-k semantically similar chunks, inject them into context. The Graph RAG pipeline runs: embed the query, retrieve the top-k semantically similar nodes from the graph, traverse the graph from each matched node to collect structurally related entities, combine the directly matched content with the traversal-collected context, inject the enriched result set into the agent’s context window.
The concrete benefit becomes clear with an example. An agent asked “what is the blast radius of a failure in the payments service?” cannot answer well with vector retrieval alone: it would find documents that mention the payments service, but identifying which other services would be affected by a payments outage requires knowing the dependency graph. With Graph RAG, the retrieval step finds the payments service node via semantic search, then traverses all incoming DEPENDS_ON edges to collect the services that depend on it directly, then traverses one further hop to collect second-order dependents. The agent receives a structured list of affected services alongside any documentation associated with each, grounding its blast-radius analysis in actual topology rather than inferred proximity.
The Graph RAG pattern supports two traversal strategies. In entity-first traversal, the query is matched to a specific entity node and the traversal expands from there. This works well when the question is anchored to a known entity: “what depends on service X?”, “who owns repository Y?”. In community-first traversal, the graph is pre-processed to identify clusters of densely connected nodes (communities), and retrieval first identifies the most relevant community before retrieving representative nodes from it. Community traversal is better suited to open-ended questions that don’t name a specific anchor entity: “which part of our architecture is most interconnected?”, “where are our most critical single points of failure?”. In practice, agentic systems benefit from supporting both strategies and letting the query planner select the appropriate one based on whether the query contains a named entity anchor.
Neo4j AuraDB as the Graph RAG backing store
Neo4j AuraDB, available in AWS Marketplace, is the managed cloud deployment of the Neo4j graph database and is the most mature purpose-built platform for implementing Graph RAG in production. It provides three capabilities that make it particularly suited to this role. First, native vector index support within the graph store: each node can carry an embedding vector as a property, and AuraDB maintains a vector index over these embeddings that supports approximate nearest neighbor queries natively. This means the entity-finding step of Graph RAG—match the query to the most similar node—executes inside the same store that holds the graph structure, without a round-trip to a separate vector database. Second, the Cypher query language, a declarative pattern-matching language that expresses graph traversals intuitively and composes naturally with vector similarity lookups: a single Cypher query can find the top-5 nodes by semantic similarity and expand their first- and second-degree relationships in one round-trip. Third, native LangChain integration through the Neo4jVector and GraphCypherQAChain classes, which implement the Graph RAG pipeline out of the box and integrate directly with the LangGraph agent framework used throughout this series.
The graph population pipeline for the DevOps Companion works as follows. The Repo Analysis agent, which runs as the first step of each workflow, outputs a structured manifest of detected services and their inferred dependencies. A graph writer Lambda function, invoked as a Step Functions task immediately after the Repo Analysis agent completes, translates this manifest into Cypher MERGE statements that upsert Service and Repository nodes and create or update DEPENDS_ON edges. Each node is immediately enriched with an embedding of its description, generated via the Amazon Bedrock Titan Embeddings API, and stored as the node’s embedding property. The graph is therefore current by the time any downstream agent in the same workflow needs to query it.
Exposing graph RAG to agents through MCP
Agents interact with the Graph RAG pipeline through an MCP server that wraps the Neo4j driver and exposes two tools. The first tool, graph_search, accepts a natural language query, embeds it using Amazon Bedrock, executes a vector similarity search over the node embedding index to find the most relevant entry points into the graph, then runs a configurable traversal from those entry points and returns the collected nodes and their relationships as a structured JSON payload. The second tool, graph_query, accepts a Cypher query string directly, executes it against AuraDB, and returns the raw result set. The first tool is designed for agent-driven retrieval where the agent doesn’t know the graph schema in advance; the second is designed for situations where the orchestrator has pre-computed the traversal logic and needs to execute it precisely.
The MCP server is registered with Amazon Bedrock AgentCore, making its tools available to any agent in the multi-agent system without requiring each agent to manage a direct Neo4j driver connection. Access is governed by IAM: the AgentCore service role that the MCP server runs under is granted read-only access to the AuraDB instance, and write access is restricted to the graph writer Lambda function that runs as a Step Functions task. This separation ensures that agents can query the graph freely without any risk of inadvertently mutating it during reasoning.
When graph RAG is worth the complexity
Graph RAG introduces a graph store, a population pipeline, and an MCP server into the architecture. This is meaningful operational complexity that needs to pay for itself. The investment is justified when three conditions hold simultaneously: the domain contains entities with structured many-to-many relationships that matter for answering agent queries; those relationships are not reliably expressed in free-text documents that a standard vector store would capture; and the agent regularly needs to answer questions that require reasoning over the relationship structure, not just finding similar content.
Good signals that Graph RAG will deliver measurable quality improvement over standard RAG: the agent frequently answers questions about blast radius, cascading failure, ownership chains, or deployment ordering; the knowledge base contains entities whose relationships are defined in code or configuration rather than in natural language documentation; and evaluation shows that pure vector retrieval returns topically relevant but structurally incomplete results for a meaningful fraction of queries. If vector retrieval already answers the queries well, adding graph infrastructure delivers diminishing returns.
For the DevOps Companion specifically, all three conditions hold. The service dependency graph, infrastructure topology, and incident causality chain are structured relationships that matter directly for the agent’s core tasks. These relationships are largely implicit in code and Terraform configuration, not in free-text documentation that a vector store would capture. And the queries that characterize the Companion’s most valuable outputs—impact analysis, deployment ordering, root cause investigation—are precisely the queries that graph traversal answers more precisely than vector similarity. Graph RAG is therefore a first-class part of the Companion’s memory architecture, not an optional enhancement.
Memory as a first-class data asset
In most early agent deployments, memory infrastructure is treated as an implementation detail. A vector store is deployed to make RAG work. A DynamoDB table is created to hold session state. A cache is added for performance. None of these components is treated with the same governance discipline as the organization’s primary data assets, they aren’t subject to retention policies, data lineage tracking, access controls, or regulatory compliance review.
This approach is a liability. Memory infrastructure holds sensitive data: conversation histories contain personal information and confidential business context, knowledge bases may include proprietary documents, and shared task state may contain credentials or security-sensitive configuration. As agentic systems mature from prototypes to production workloads, memory infrastructure must be brought into the same governance framework as any other enterprise data asset.
Data lineage for retrieved facts
When an agent uses a retrieved fact to support a decision or a recommendation, the fact’s provenance matters. Where did this fact come from? When was the source document ingested? Has the source been updated since the fact was ingested? Could the fact be stale? Answering these questions requires data lineage, a record of where each piece of information in the knowledge base came from and how it was processed.
Amazon Bedrock Knowledge Bases stores metadata alongside each document chunk: the source document URI, the ingestion timestamp, the document version or modification date, and any custom metadata provided during ingestion. When a retrieved chunk is included in an agent’s context, this metadata is available to the agent and can be included in the agent’s response as a citation or a confidence qualifier. An agent that retrieved a deployment guide last updated eighteen months ago can note this staleness rather than presenting the information as current.
AWS CloudTrail records all API calls to Amazon Bedrock Knowledge Bases, including ingestion operations and retrieval queries. This provides an audit log of what was ingested, when, by whom, and what was retrieved by which agent invocation. For regulated industries, this audit log is part of the evidence required to demonstrate that AI-generated outputs are grounded in appropriate, authorized sources.
Retention and deletion policies
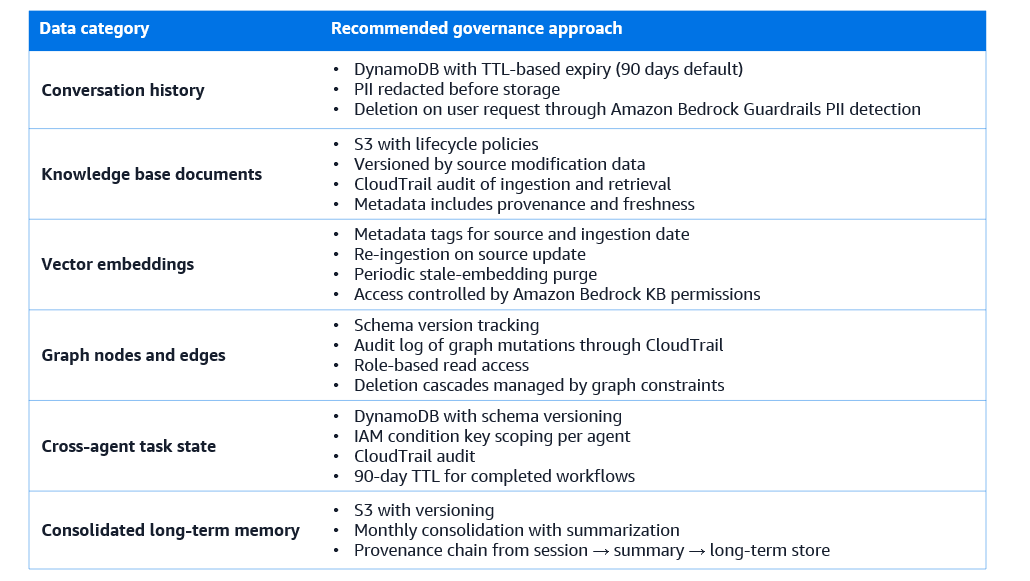
Memory infrastructure must be subject to data retention policies that specify how long different categories of data are kept and what happens when the retention period expires. Conversation histories may be subject to user data deletion requests under privacy regulations, a user who exercises their right to erasure must have their conversation history deleted from all memory stores, including any long-term memory derived from their sessions. Knowledge base content must be updated or removed when source documents change or are deleted.
Amazon S3 lifecycle policies provide automated retention management for knowledge base source documents and archived conversation histories. DynamoDB TTL (Time to Live) attributes enable automatic deletion of session records after a configured inactivity period. For vector stores, deletion of specific embeddings requires either the vector store’s native delete API or a periodic re-ingestion process that replaces the entire index depending on the vector store’s support for partial updates.
The specific retention periods depend on regulatory requirements, organizational policy, and the nature of the data. A common baseline for conversation histories is 90 days for operational purposes, with longer retention for regulatory compliance use cases. Knowledge base content is typically retained as long as the source documents are relevant, with automated refresh
PII handling in memory systems
Agentic systems that interact with users will inevitably encounter personally identifiable information (PII): names, email addresses, phone numbers, account identifiers, and in some domains, more sensitive categories like health information or financial data. PII that’s captured in conversation histories, stored in session memory, or ingested into knowledge bases creates compliance obligations and privacy risks.
Amazon Bedrock Guardrails provides PII detection and redaction capability that can be applied both to agent inputs (user messages before they’re processed by the model) and to agent outputs (model responses before they’re returned to the user). For memory systems, the recommended approach is to apply PII redaction before storing conversation histories, replacing detected PII with placeholder tokens — name → [PERSON], email → [EMAIL] — that preserve the semantic structure of the text without storing the actual values. The actual values can be stored separately in an access-controlled lookup table if needed for operational purposes, linked to the memory records by the placeholder tokens.
Extracting and consolidating memory
Session memory is ephemeral by design, it captures the details of a specific interaction and isn’t intended to persist indefinitely. But sessions contain valuable information: the user’s preferences and working style, the decisions made in a workflow, the problems encountered and how they were resolved, the patterns that emerged across multiple interactions. If this information is discarded when the session ends, the agent must rediscover it in every subsequent interaction. If it’s preserved, extracted from the session and stored in a more durable form, the agent can build on it.
Memory consolidation is the process of reviewing accumulated session memory, extracting the information worth preserving long-term, discarding the ephemeral detail, and storing the extracted information in a form that future interactions can efficiently retrieve. It’s the mechanism by which an agent’s long-term knowledge grows from its operating experience, rather than being limited to the documents it was pre-populated with at setup time.
What is worth consolidating
Not all information in a session deserves to be consolidated to long-term memory. The raw turn-by-turn message history is almost never worth consolidating, it’s verbose, contains conversational filler, and the signal-to-noise ratio is low. What is worth consolidating depends on the agent’s purpose, but some common categories include: explicit user preferences and constraints established during the session, facts about the user’s environment or configuration that will remain true across sessions, decisions made during a workflow and the rationale behind them, problems encountered and the solutions that resolved them, and patterns observed across multiple tool calls that suggest a systematic issue or opportunity.
The consolidation process is itself an agent task: a consolidation agent receives the session history as input and is asked to extract the valuable information in a structured format. The structure matters because it determines how the consolidated information can be retrieved and used. Free-form text summaries are easy to consolidate but hard to retrieve precisely. Structured records, user preference: deployment region = us-east-1; resolved problem: service X fails to start without environment variable Y, are harder to write but can be indexed for precise retrieval.
Consolidation patterns: scheduled and threshold-triggered
Scheduled consolidation runs on a regular cadence, nightly or weekly, and processes all sessions that haven’t yet been consolidated. It’s implemented as an EventBridge Scheduler-triggered Step Functions workflow that queries the session memory store for recently closed sessions, runs the consolidation agent for each, writes the results to the long-term semantic memory store, and updates the session record to indicate that consolidation has been completed. Scheduled consolidation is predictable and easy to operate but introduces a lag between session completion and long-term memory availability.
Threshold-triggered consolidation runs when the session memory size exceeds a configured threshold, when the session has accumulated more than 50,000 tokens of history, for example. Rather than waiting for the session to end, it runs a partial consolidation, extracting the valuable information from the oldest portion of the session history and replacing that portion with a compact structured summary. Threshold-triggered consolidation keeps the session memory bounded without requiring a windowing strategy that discards older context, and it makes consolidated information available within the same session.
Amazon Bedrock summarization for memory distillation
The summarization step in the consolidation process uses Amazon Bedrock’s text generation capability to distill a session history into a structured memory record. The prompt for the summarization model is carefully designed to extract specific categories of information rather than producing a generic summary. A well-designed consolidation prompt instructs the model to produce a structured JSON record with specific fields, user preferences, configuration facts, resolved problems, outstanding issues, and key decisions, making the output immediately usable as a structured long-term memory record rather than requiring further processing.
The consolidated record is ingested into the long-term semantic memory store, Amazon Bedrock Knowledge Bases, Pinecone, Weaviate, or whichever vector store is used with metadata that links it back to the original session: the session ID, the user identifier, the time range covered, and the consolidation timestamp. This metadata enables the retrieval layer to provide temporal context alongside the retrieved facts: “this was extracted from a session three months ago and may have changed since.”
Conclusion and looking ahead
Memory isn’t an add-on. It’s the infrastructure that determines whether an agent accumulates understanding over time or resets to zero with every interaction. The four memory types covered in this module, in-context working memory, short-term session memory, long-term semantic memory, and shared cross-agent memory, each solve a different part of this problem. A complete agent system requires deliberate choices about which combination to use, how to govern each component, and how to consolidate ephemeral session experience into durable long-term knowledge.
Here’s what I’d prioritize if you’re starting from scratch: get session memory right before investing in vector stores. Session memory is the most immediately visible capability users notice immediately when an agent loses context between turns and it’s the foundation on which consolidation into long-term memory depends. Get session memory working reliably with DynamoDB or ElastiCache, then add long-term semantic memory as your knowledge requirements grow beyond what you can put in the context window.
One honest caveat: memory consolidation is technically straightforward but operationally demanding. The consolidation workflow needs to run reliably every night, the prompts for extracting structured facts from session histories need to be tuned over time, and the consolidated records need to be monitored for quality degradation. Building the consolidation pipeline is the easy part; maintaining the quality of what it produces over months of production operation is the ongoing work. Budget for that maintenance before you commit to building a consolidation system.
Module 8 takes the next step in the security story this module has touched on through PII handling and access-controlled shared memory. Agent Identity and Access Management addresses how agents establish their identity, how they’re authorized to act on behalf of users, how credentials are managed securely across MCP server boundaries, and how the authentication models that enterprise organizations have built for human users must be extended to accommodate agents as first-class principals.
Featured AI tools in AWS Marketplace
Build agent memory architecture with vector search, semantic caching, and persistent storage tools — all available through your AWS account.
Why AWS Marketplace for on-demand cloud tools
Free to try. Deploy in minutes. Pay only for what you use.
Featured tools are designed to plug in to your AWS workflows and integrate with your favorite AWS services.
Subscribe through your AWS account with no upfront commitments, contracts, or approvals.
Try before you commit. Most tools include free trials or developer-tier pricing to support fast prototyping.
Only pay for what you use. Costs are consolidated with AWS billing for simplified payments, cost monitoring, and governance.
A broad selection of tools across observability, security, AI, data, and more can enhance how you build with AWS.
Continue your journey
Each workshop in the Building Agentic Systems on AWS series covers a standalone topic. If agent memory architecture interests you, these related workshops cover complementary patterns — multi-agent coordination and agent orchestration.