Domain-specific agent applications on AWS
Learn the four levers of domain specialization: system prompt, knowledge corpus, tool selection, and guardrails. Applied across three production domains on AWS.
Overview
Technical workshop: The architectural shift to domain-specific agents
You’ve built agents, connected them to tools, and coordinated them in multi-agent systems. This workshop tackles the next challenge: making agents work beyond the happy path in a specific domain. Learn the four levers of domain specialization (system prompt, knowledge corpus, tool selection, and guardrails) applied across three production domains using AWS services and tools from across the AI landscape.

The four levers of domain specialization
Transform general-purpose agents into domain specialists using four architectural levers applied across three production domains on AWS.
Topics covered:
- System prompt engineering for domain-scoped behavior
- Knowledge corpus curation with verified domain sources
- Tool selection and boundary enforcement per domain
- Guardrail design for production output constraints
Featured AI tools in AWS Marketplace
Build with foundation models, deployment platforms, and AI infrastructure—all available through your AWS account.

Page topics
- Introduction
- The domain specialization problem
- Adapting the architecture for domain requirements
- Agents in customer engagement and sales
- The age of API economy
- Voice-enabled agents — speech as a first-class interface
- Grounding domain agents in knowledge
- Guardrails and constraints for domain agents
- Domain-specific evaluation
- Integrating domain agents into the multi-agent architecture
- Worked example — three domains, one unified system
- Conclusion and looking ahead
Introduction
Modules 1 through 4 built the engineering foundation: what agents are, how to construct and evaluate them, and how to coordinate multiple agents in a production system. The architecture is in place. The question this module addresses is a different one: how do we build agents that are genuinely excellent at specific, real-world tasks, not merely adequate, but demonstrably better than a general-purpose agent would be?
The answer is domain specialization. A general-purpose agent is a capable generalist. It can reason about a wide range of topics, use a broad set of tools, and produce coherent output across domains. But a generalist, applied to a specific domain, tends to be inconsistently reliable. It may produce excellent output most of the time and subtly wrong output in edge cases. In domains where subtly wrong output has real consequences, a customer receiving incorrect product information, a delivery route calculation that ignores a road closure, a voice interaction that mishears a command in a noisy environment, inconsistency is not acceptable.
Domain specialization is the practice of taking a general-purpose agent and deliberately shaping its behavior, knowledge, and constraints to match the requirements of a specific domain. It’s not about restricting the agent, it’s about focusing it, grounding it, and giving it the domain expertise it needs to be reliably excellent rather than inconsistently good.
This module covers domain specialization through three distinct lenses, each representing a major category of real-world agent application. The first is customer engagement and sales: agents that interact directly with users, understand their intent, personalize responses, and drive business outcomes. The second is location-aware logistics: agents that reason about physical geography, optimize routes, and integrate real-time spatial data. The third is voice-enabled interaction: agents that operate through spoken language, handling speech recognition, natural language understanding, and speech synthesis as first-class concerns.
Each domain brings its own technical challenges, its own ISV ecosystem on AWS Marketplace, and its own specialized AWS services. Throughout the module, we return to the DevOps Companion, not as a DevOps tool, but as the platform on which we add domain-specialized agents that extend its capabilities.
The domain specialization problem
A domain-specialized agent isn’t a restricted agent, it’s a focused one. The specialization doesn’t limit the agent’s general reasoning capacity; it channels that capacity toward the domain’s specific requirements.
The core problem with a general-purpose agent in a specialized domain is the gap between general reasoning capability and domain-specific reliability. General capability is about breadth, the model has been trained on vast amounts of data across many domains and can reason coherently about most topics. Domain reliability is about depth and consistency, the agent produces the correct output for this specific domain, in this specific context, with a level of consistency that meets the domain’s quality threshold.
This gap shows up in several specific ways in production. Without a domain-constrained system prompt, a general agent may apply reasoning patterns from adjacent domains that are subtly incorrect in the target domain. A customer engagement agent without explicit tone constraints may produce technically accurate responses that are inappropriate for the brand’s voice. A location-aware agent without geospatial tool scoping may try to use general web search to answer routing questions, producing less accurate results than a purpose-built spatial API would provide. A voice agent without latency constraints may produce responses that are correct but too verbose to be delivered as natural-sounding speech within the latency budget of a real-time voice interaction.
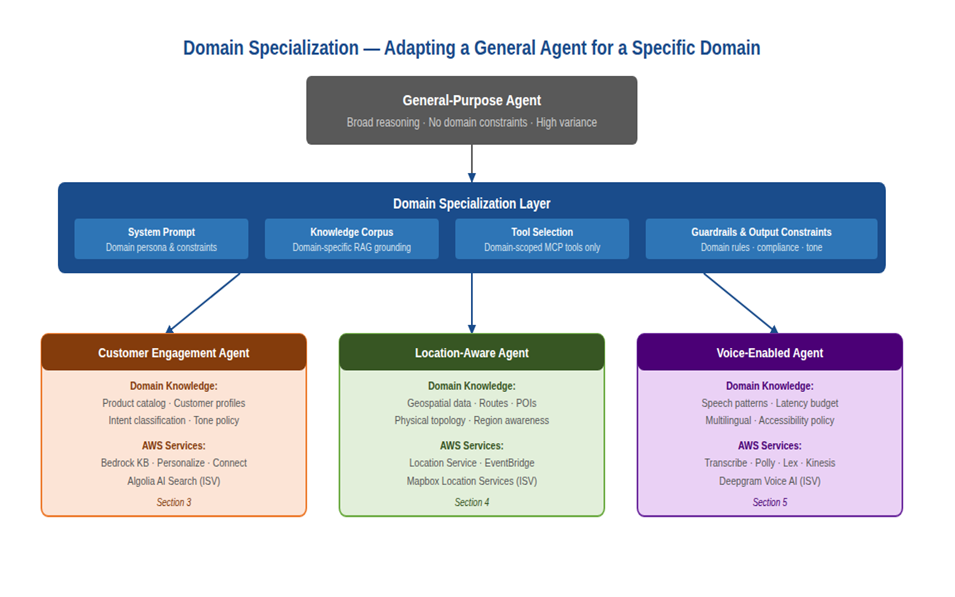
Figure 1: The domain specialization layer — four levers that shape a general agent for a specific domain
The four levers of domain adaptation
Every domain specialization effort works with the same four levers. Understanding what each lever does and how they interact is central to designing domain agents that work reliably in production.
The system prompt is the primary mechanism for establishing domain persona, constraints, and behavioral norms. A well-designed domain system prompt doesn’t just describe the domain, it encodes the implicit knowledge that an expert in that domain would apply automatically. It defines what the agent should prioritize, what it should refuse to do, how it should handle uncertainty, and how it should communicate with users in this specific context.
The knowledge corpus is the retrieval layer, the domain-specific documents, facts, policies, and precedents that the agent can access at inference time through retrieval-augmented generation. The composition of this corpus is one of the most consequential design decisions in domain specialization. A customer engagement agent with access to a current, well-curated product catalog and FAQ corpus will consistently outperform one with access to a generic company knowledge base. Corpus curation matters as much as prompt engineering.
Tool selection determines which MCP-exposed capabilities are available to the domain agent. Scoping the tool set to domain-relevant tools serves two purposes: it improves quality by preventing the agent from trying to use inappropriate tools for domain tasks, and it improves security by limiting the blast radius of a compromised or misbehaving agent. The routing tools available to a logistics agent should not include the deployment tools used by the infrastructure agent.
Guardrails and output constraints define what the agent must never do in this domain, independent of what its reasoning might otherwise suggest. Domain guardrails are typically stricter and more specific than general safety guardrails. A medical information agent must never provide specific drug dosage recommendations; a financial agent must never provide personalized investment advice without appropriate disclaimers; a children’s educational agent must apply strict age-appropriate content filtering to both inputs and outputs. These constraints are implemented at the Amazon Bedrock Guardrails layer, not in the system prompt, precisely because they must be enforced even when the agent’s reasoning would lead it to override them.

Domain reliability thresholds
Every domain has a quality threshold, a minimum level of reliability below which agent output causes more harm than it prevents. For internal productivity tools, that threshold may be 80–85%: users can identify and correct errors. For customer-facing interactions, it’s typically higher: 90–95%, because errors erode trust and can’t always be corrected after the fact. For safety-critical domains, medical, financial, legal, it may approach 99%.
The evaluation framework established in Module 3 provides the infrastructure for measuring domain reliability. The critical addition for domain-specific evaluation is that the golden datasets must be domain-representative: test cases drawn from the actual distribution of inputs the agent will encounter in production, including edge cases, adversarial inputs, and the specific failure modes that matter in this domain. A customer engagement agent’s evaluation dataset should include angry customers, ambiguous product questions, and requests that are outside the agent’s scope, not just representative positive examples.
Adapting the architecture for domain requirements
Domain specialization doesn’t require a different agent architecture. The building blocks from Module 2, including reasoning loop, memory, MCP tools, LangGraph state management all remain the foundation. What changes is how those building blocks are configured and composed for the specific domain.
System prompt engineering for domains
The domain system prompt has a different structure and purpose than the general system prompts used in earlier modules. A general system prompt establishes broad behavioral guidelines. A domain system prompt establishes a domain identity, a specific role, a specific knowledge context, and a specific set of operating constraints that define exactly how this agent should behave in this domain.
Effective domain system prompts follow a layered structure. The first layer establishes the agent’s domain role: who it is, what it’s responsible for, and what authority it has. The second layer establishes domain knowledge context: what the agent knows, what sources it should consult, and how it should handle gaps in its knowledge. The third layer establishes behavioral constraints: what it must always do, what it must never do, and how it should handle uncertainty. The fourth layer establishes communication norms: tone, format, length constraints, and escalation procedures.
Tone and length constraints are especially important for domain agents that interact with end users. A customer engagement agent should produce responses that are appropriately warm and concise. A voice agent should produce responses that are brief enough to be delivered within the latency budget and natural enough to be synthesized as fluent speech.
An agent producing three-paragraph responses in a voice interface is a UX failure regardless of technical accuracy.
Knowledge corpus design
The knowledge corpus for a domain agent should be designed with three criteria in mind: relevance, freshness, and coverage. Relevance means the corpus contains primarily information that is directly useful for the agent’s tasks. Freshness means the corpus is updated when domain facts change, product prices, policies, geographic data, or regulatory requirements. Coverage means the corpus addresses the range of topics the agent will encounter, with particular attention to the edge cases and long-tail queries that are disproportionately likely to cause failures.
Amazon Bedrock Knowledge Bases provides the vector retrieval infrastructure for domain corpora. The embedding model selection should be aligned with the domain’s language characteristics: technical corpora with precise terminology benefit from models trained on technical text; customer-facing corpora with natural language queries benefit from models optimized for semantic similarity in conversational contexts.
Chunking strategy affects retrieval quality measurably. Documents should be chunked at semantically meaningful boundaries, paragraphs for narrative documents, individual records for structured data, complete policy statements for compliance documents, rather than at fixed character counts. Amazon Bedrock Knowledge Bases supports hierarchical chunking, which allows for multi-level retrieval that can surface both specific facts and the broader context in which they appear.
Evaluating domain fit
Before deploying a domain agent in production, evaluate it not just for general performance but for domain fit, the degree to which its outputs are appropriate for the specific domain, not just technically correct.
Domain fit evaluation requires domain-expert involvement. The golden dataset for a customer engagement agent should be reviewed and annotated by customer experience professionals, not just AI engineers. The evaluation rubric for a location-aware agent should include criteria defined by logistics experts who understand what constitutes a good routing recommendation in the context of their operations. Amazon Bedrock AgentCore Evaluations supports custom evaluators that encode domain-specific criteria, enabling teams to automate domain fit assessment as part of the continuous evaluation pipeline.
Agents in customer engagement and sales
Customer engagement is one of the highest-impact domains for agentic AI. Direct customer interactions are high-frequency, high-visibility, and directly linked to business outcomes: customer satisfaction, retention, conversion, and brand perception. Getting them right matters enormously; getting them wrong is immediately visible.
Intent classification as the entry point
Every customer engagement agent interaction begins with an intent classification problem: what does the customer want? The answer determines everything that follows, which knowledge base sections to retrieve, which tools to invoke, what tone to adopt, and whether the request is within scope or should be routed to a different agent or a human operator.
Intent classification in customer engagement contexts is more complex than it appears. Customers rarely express their intent in precise, unambiguous language. A customer who says “my order is wrong” may want a refund, a replacement, an apology, information about what went wrong, or some combination. The agent must infer the most likely intent from context, prior conversation history, account information, recent transactions, and proceed accordingly, while remaining responsive to clarification.
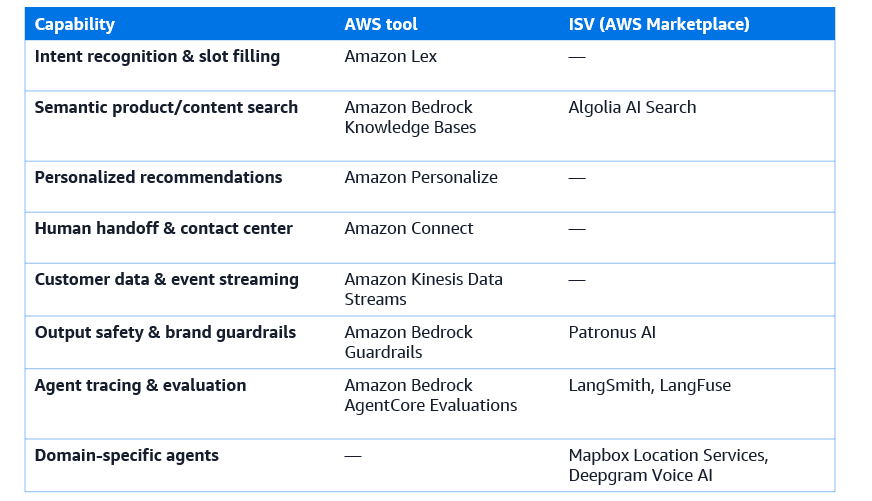
Amazon Lex provides intent recognition and slot filling for structured customer interaction flows, integrating natively with Amazon Connect for contact center deployments. For more open-ended customer engagement where intent is less structured, Amazon Bedrock agents with well-designed system prompts and retrieval grounding generally outperform rule-based intent classifiers on natural language queries.
Personalization at scale
The most effective customer engagement agents treat each customer as an individual, not as a representative of a user segment. Personalization requires access to customer-specific data: purchase history, product preferences, previous service interactions, stated preferences, and behavioral signals.
Amazon Personalize provides real-time personalization recommendations that can be surfaced to the agent as tool outputs. Rather than the agent reasoning from scratch about what product to recommend, it can query a Personalize endpoint that has been trained on the organization’s actual customer behavior data and receive a ranked list of relevant recommendations. The agent then uses its domain reasoning to select and present the most appropriate recommendation from that list in the context of the current conversation.
Algolia AI Search, available on AWS Marketplace, provides a complementary capability: high-performance semantic search over product catalogs, content libraries, and knowledge bases. When a customer asks about a specific product type, Algolia’s neural search surfaces the most semantically relevant results from the catalog, not just keyword matches, so the agent can respond with genuinely relevant product information even for long-tail or ambiguous queries. The combination of Personalize (personalized recommendations) and Algolia (semantic search) gives customer engagement agents both relevance and personalization without requiring either to carry the full burden of both.
Escalation design
No customer engagement agent should be deployed without a well-designed escalation policy. The escalation policy defines the conditions under which the agent should hand off the interaction to a human operator, and how that handoff should occur.
Escalation triggers typically fall into three categories: scope escalation, when the customer’s request is beyond the agent’s authorized scope; sentiment escalation, when the customer’s tone indicates distress, frustration, or dissatisfaction that requires a human response; and complexity escalation, when the agent’s confidence in its response falls below the domain reliability threshold.
Amazon Connect provides the human handoff infrastructure for voice and chat customer engagement. When the agent triggers an escalation, it passes the full conversation context, including its classification of the issue, the customer’s sentiment, and any relevant account information, to the Connect agent workspace, so the human operator can continue the conversation without requiring the customer to repeat themselves. This context-preserving handoff is one of the most significant quality improvements that agentic systems bring to contact center operations.
Customer engagement agent design checklist
- System prompt encodes brand tone, escalation triggers, and scope boundaries explicitly
- Knowledge corpus includes current product catalog, FAQ, policies, and common edge cases
- Intent classification handles ambiguous, multi-intent, and out-of-scope inputs gracefully
- Personalization tool queries Amazon Personalize or equivalent at the start of each session
- Semantic search through Algolia or Amazon Bedrock KB surfaces relevant content for product queries
- Escalation policy defines sentiment thresholds, scope boundaries, and handoff procedure
- Amazon Connect integration tested for context-preserving handoff to human agents
- Guardrails configured for brand safety, PII handling, and off-topic request deflection
- Evaluation dataset includes negative sentiment, ambiguous intent, and out-of-scope test cases
The age of API economy
Location-aware agents operate in a domain where the fundamental data is spatial: coordinates, routes, distances, boundaries, points of interest, and their relationships to each other and to real-world constraints. Reasoning about this data requires more than general knowledge — it requires access to authoritative, current geospatial data, and the ability to perform spatial computations that go beyond what a language model can reliably do from training data alone.
Why agents need geospatial tools
Language models have spatial knowledge encoded in their training data, they know that Paris is in France, that the Amazon River flows east, that Manhattan is an island. But they don’t have current, precise geospatial data: they don’t know the traffic conditions on a specific highway at a specific time, the current status of a specific delivery route, or the precise GPS coordinates of a specific address.
More subtly, language models don’t perform spatial computation reliably. Asking a language model to calculate the optimal delivery route among twelve stops subject to time window constraints and vehicle capacity limits is asking it to solve a variant of the Travelling Salesman Problem, a combinatorial optimization that even simple algorithmic implementations handle far more reliably than model inference. The right architecture is not to ask the model to reason about the spatial computation; it’s to ask the model to formulate the optimization parameters and then invoke a geospatial tool that performs the computation and returns a structured result.
This is the core design principle for location-aware agents: use the model for natural language understanding, intent interpretation, and result synthesis; use geospatial tools for all spatial data access and computation. The boundary between these two concerns must be explicit and enforced through the tool schema.
AWS location service as the geospatial foundation
Amazon Location Service provides the foundational geospatial capabilities that location-aware agents need as MCP-exposed tools: place search (finding addresses, points of interest, and coordinates from natural language descriptions), geocoding (converting addresses to coordinates and vice versa), route calculation (optimal paths between multiple waypoints subject to constraints), geofencing (detecting when a tracked entity enters or exits a defined area), and map rendering (generating map visualizations for user-facing outputs).
For the DevOps Companion, the deployment topology agent uses Location Service’s place search and distance calculation capabilities to understand the physical relationships between the deployment target regions and the user’s infrastructure. When a user specifies a multi-region deployment, the agent can reason about data residency requirements, latency implications, and inter-region replication patterns by grounding that reasoning in the actual geographic relationships between AWS regions, information that Location Service provides through its authoritative geospatial data.
Mapbox location services — advanced routing and intelligence
For use cases requiring more sophisticated routing, real-time traffic data, or high-resolution map visualizations, Mapbox Location Services (available on AWS Marketplace) provides capabilities that complement and extend the AWS Location Service foundation.
Mapbox’s routing engine incorporates real-time traffic data, turn restrictions, road closures, and multi-modal routing across driving, walking, cycling, and public transit. For a logistics agent managing delivery routes, this means route recommendations that account for conditions that change over the course of a delivery day, not just the fastest route at departure time, but the optimal route given current traffic as the day progresses.
Mapbox is exposed to the location-aware agent through an MCP server that wraps its routing and search APIs. The agent invokes the routing tool with a set of waypoints, time windows, and vehicle constraints, and receives a structured route plan as the tool result. The agent doesn’t perform the routing computation, it provides the parameters and synthesizes the result into a user-facing recommendation.
Freshness and caching in geospatial contexts
Geospatial data has variable freshness requirements. Some data changes slowly, administrative boundaries, major road networks, regional topology. Other data changes rapidly, real-time traffic, vehicle locations, delivery status, weather conditions affecting routes.
The agent’s tool schema should distinguish between these freshness categories and ensure that fresh data is retrieved when freshness matters. Amazon ElastiCache is appropriate for caching semi-static geospatial data, place search results, regional boundaries, pre-computed frequently-requested routes, where a small degree of staleness is acceptable in exchange for reduced latency and API cost. Real-time data, traffic conditions, vehicle locations, should always be fetched directly from the source API without caching.
Don’t cache traffic data. Even a five-minute-old traffic snapshot can produce a route recommendation that sends a driver into a jam that formed in the last few minutes. The cost of a stale cache hit here is operational, not just cosmetic.
Location-aware agent design principles
- Never ask the model to perform spatial computation — use geospatial tools for all spatial math
- Distinguish between static (cacheable) and dynamic (fresh-required) geospatial data in tool design
- Include coordinate validation in tool schemas — reject malformed or implausible coordinate inputs
- Design output formats to be map-renderable when the interface supports visualization
- Test routing tools against known edge cases: closed routes, invalid coordinates, impossible constraints
- Apply freshness TTLs to cached geospatial data aligned with the rate of change of the data type

Voice-enabled agents — speech as a first-class interface
Voice interfaces present a qualitatively different set of design constraints than text interfaces. The core difference is latency: in a text interface, a user will tolerate a two or three second response time without noticing. In a voice interface, a pause of more than one to two seconds is experienced as an awkward silence, the natural expectation of human conversation is a response within hundreds of milliseconds. This latency constraint propagates through the entire agent pipeline, affecting architecture decisions at every stage.
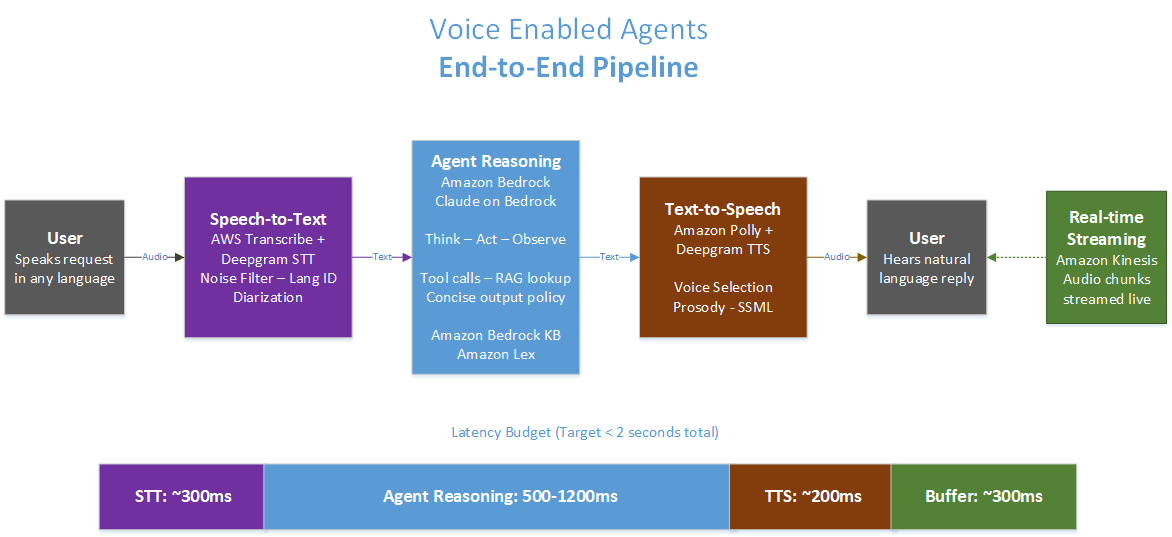
Figure 2: The voice-enabled agent pipeline, from speech input to spoken response, with latency budget
The voice agent pipeline
A complete voice agent interaction involves four distinct processing stages, each with its own latency and quality tradeoffs.
Speech-to-text (STT) is the conversion of spoken audio into a text transcript. This stage must handle noise, accents, multiple languages, domain-specific terminology, and homophones that only resolve with context. Modern neural STT systems, Amazon Transcribe and Deepgram Voice AI, achieve high accuracy on clean audio and degrade gracefully on noisy audio, but they’re not infallible. The agent must be designed to handle transcription errors: requesting clarification when the transcript is ambiguous rather than proceeding on a potentially incorrect interpretation.
Intent and context understanding maps the transcribed text to agent reasoning. This stage is where the agent’s domain specialization, its system prompt, its knowledge corpus, its tools, does its work. It must produce a response in a format appropriate for speech synthesis: concise, naturally structured, free of formatting markup, and cognizant of the length constraints imposed by the latency budget and the conversational nature of voice interaction.
Text-to-speech (TTS) converts the agent’s text response into synthesized speech. The quality of this stage affects the user’s perception of the interaction measurably. Robotic or unnatural synthesis undermines even technically correct responses. Amazon Polly provides neural TTS voices across multiple languages with support for Speech Synthesis Markup Language (SSML), which allows the agent to control emphasis, pauses, and pronunciation for specific terms. Deepgram’s TTS models, available on AWS Marketplace, provide high-fidelity synthesis with particularly strong performance on conversational language.
Real-time streaming is not a stage in sequence but an architectural capability that runs alongside the pipeline. Rather than waiting for the complete STT transcription before beginning agent processing, or waiting for the complete agent response before beginning TTS synthesis, modern voice agent architectures stream at each stage boundary. Amazon Kinesis enables audio streaming from the user’s device to the STT service. STT services that support partial transcripts allow the agent to begin processing before the utterance is complete. TTS services that support streaming synthesis allow audio to begin playing before the complete response is synthesized. Each of these streaming optimizations reduces the perceived latency of the interaction.
Deepgram voice AI — end-to-end speech intelligence
Deepgram Voice AI, available on AWS Marketplace, provides both STT and TTS capabilities optimized for real-time conversational applications. Deepgram’s STT offers streaming transcription with word-level timestamps, speaker diarization (identifying which speaker produced which utterance, essential for multi-party voice interactions), and language detection that automatically identifies the spoken language without requiring the user to specify it.
For voice-enabled agent applications where latency is critical, Deepgram’s Nova-2 model provides particularly strong accuracy-latency tradeoffs, with streaming transcription latency measured in tens of milliseconds rather than seconds. The Deepgram MCP server exposes both STT and TTS as tool calls, so the voice agent can invoke transcription and synthesis as part of its standard tool-use pattern, the same pattern used for any other agent tool.
Designing for spoken interaction
Building a voice agent is not simply a matter of adding a speech layer to a text agent. The agent’s reasoning and response generation must be aware that its output will be spoken, not read. I’d put it plainly: if you haven’t specifically constrained response length for voice, your agent will talk too much. Several design principles apply specifically to agents operating in voice mode.
Responses must be concise. The typical voice interface response should be two to four sentences, enough to answer the question fully without overwhelming the user with information that’s difficult to process aurally. Longer responses should be structured as a brief direct answer followed by an offer to provide more detail: “The deployment completed successfully to us-east-1. Would you like me to walk through the observability configuration?”
Clarification requests must be specific. When the agent is uncertain about a transcription or an intent, it should ask a specific clarifying question: “Did you mean the production environment or the staging environment?”, rather than a general “I’m not sure I understood” response. Specific clarifications are faster to resolve and feel more natural in conversation.
The agent should handle interruptions gracefully. In voice interfaces, users may begin a new utterance before the agent has finished synthesizing its response. The agent architecture must support interruption detection, stopping the current TTS synthesis when new audio is detected and should be able to incorporate context from the interrupted exchange into the new response.
Multilingual support requires more than multilingual STT. If the agent supports multiple languages, its system prompt should declare the supported languages, its knowledge corpus should be available in each supported language, and its TTS configuration should use appropriate voice models for each language. Providing multilingual STT and then responding in English to a Spanish-speaking user is a design failure that defeats the purpose of multilingual support.

Grounding domain agents in knowledge
A domain agent without a well-designed knowledge corpus is an agent that relies on the language model’s parametric knowledge, facts encoded in model weights during training for domain-specific answers. Parametric knowledge has two problems for production domain agents: it can’t be updated when domain facts change without retraining the model, and it isn’t traceable, when the model produces a fact from parametric knowledge, there’s no way to audit where that fact came from or verify that it’s still current.
Retrieval-augmented generation (RAG) solves both problems. By grounding agent responses in retrieved documents from a curated, versioned corpus, we get updatable facts the corpus is updated when domain facts change without touching the model and traceable facts, every factual claim in the agent’s response can be attributed to a specific retrieved document.
Corpus curation for domain agents
The quality of a domain agent’s retrieval-augmented responses is bounded by the quality of its corpus. Corpus quality has four dimensions: relevance, accuracy, freshness, and coverage.
Relevance means the corpus contains primarily information that is useful for the agent’s tasks. A customer engagement agent’s corpus should contain product information, policies, FAQs, and escalation guidelines, not general company history or investor relations materials. Including irrelevant content doesn’t just waste retrieval capacity; it actively degrades retrieval quality by reducing the signal-to-noise ratio in semantic search results.
Accuracy means the corpus contains factually correct information. This sounds obvious but requires active maintenance. Product specifications change, policies are updated, prices are revised. A corpus that isn’t actively maintained will accumulate stale or incorrect information that the agent will present to users with confidence, because retrieval systems don’t distinguish between accurate and inaccurate content, they retrieve the most semantically relevant content regardless of its factual status.
Coverage means the corpus addresses the range of queries the agent will encounter. The most common failure mode in production RAG systems is not retrieval of wrong information but retrieval of no relevant information, the query falls outside the coverage of the corpus. When this happens, the agent typically either hallucinates an answer or produces an overly cautious non-answer. Identifying and filling coverage gaps is an ongoing operational task, driven by analysis of queries that resulted in low retrieval confidence scores.
Chunking strategies for domain corpora
How documents are divided into chunks for indexing affects retrieval quality in ways that are easy to underestimate until you’re debugging a production system. The right chunking strategy depends on the document type and the nature of the queries the agent will process.
For policy documents and compliance materials, semantic chunking, splitting at paragraph or section boundaries rather than at fixed character counts, preserves the logical structure of the document and ensures that retrieved chunks contain complete, self-contained policy statements rather than fragments that could be misinterpreted out of context. Amazon Bedrock Knowledge Bases supports hierarchical chunking that maintains parent-child relationships between larger document sections and the smaller chunks within them, enabling retrieval to surface both the specific relevant chunk and the broader context it belongs to.
For structured data such as product catalogs, route definitions, and configuration specifications; record-level chunking, where each record is indexed as a single chunk, typically produces better retrieval quality than attempting to chunk across records. This ensures that a retrieved chunk about Product A is not contaminated with partial information about Product B.
Guardrails and constraints for domain agents
General-purpose guardrails, preventing harmful content, enforcing safety policies, avoiding profanity are necessary for all agents. Domain agents require these general guardrails plus a layer of domain-specific constraints that reflect the particular risks and obligations of their operating context.
The key principle for domain guardrail design is that the constraints that matter most in a domain should be enforced at the infrastructure level, not in the system prompt. System prompt constraints can be overridden by sufficiently adversarial inputs or by model reasoning that finds edge cases the prompt didn’t anticipate. Infrastructure-level guardrails, implemented through Amazon Bedrock Guardrails, Patronus AI, or Deepchecks, are enforced unconditionally, regardless of what the model’s reasoning produces.
Customer engagement guardrails
Customer engagement agents operate in a brand context with legal implications. The domain guardrails for a customer engagement agent typically include: prohibitions on making specific price guarantees that the agent can’t verify in real time; requirements to include specific disclosures when discussing regulated products; scope boundaries that prevent the agent from making commitments it’s not authorized to make; and sentiment-triggered escalation rules that route interactions to human agents when distress signals are detected.
PII handling is a particularly important guardrail category for customer engagement agents. The agent will encounter customer identifiers, payment information, and personal data in the course of normal interactions. Guardrails should prevent the agent from echoing PII back in its responses unnecessarily, storing PII in shared state where it isn’t needed, or transmitting PII to tool calls that don’t require it. Amazon Bedrock Guardrails provides built-in PII detection and redaction that can be applied to both the agent’s inputs and outputs.
Location and logistics guardrails
Location-aware agents have guardrails centered on data accuracy and liability. A routing agent that provides an incorrect route recommendation may not carry the same category of legal exposure as a medical agent that provides incorrect clinical advice, but in time-sensitive logistics contexts, incorrect route information has real operational and financial consequences.
The domain guardrails for a location agent typically include: accuracy confidence thresholds below which the agent must present recommendations as estimates rather than authoritative directions; data freshness requirements specifying the maximum age of geospatial data that the agent may use for route recommendations; scope boundaries preventing the agent from making route recommendations in areas where its data coverage is inadequate; and explicit disclaimers for recommendations that involve significant uncertainty.
Voice agent guardrails
Voice agents face a unique guardrail challenge: the same content that’s appropriate in a text interface may not be appropriate in a voice interface. Responses that contain markdown formatting, HTML, or code are problematic in voice, they produce spoken output that sounds wrong. Responses that are correct but very long will exceed the latency budget and produce an awkward experience.
Voice-specific guardrails should enforce output format constraints preventing the agent from producing formatted text, code blocks, or excessively long responses in voice mode — as well as the domain-specific content constraints that apply in the voice context. An agent that operates in both text and voice modes should have separate guardrail configurations for each interface mode, applied based on the active interface type.
Domain-specific evaluation
The evaluation framework from Module 3 provides the infrastructure for domain evaluation, but the evaluation design, the test cases, the scoring criteria, the quality thresholds must be domain-specific. Generic evaluation produces generic quality signals; domain evaluation produces the quality signal that predicts whether the agent will perform well for its intended users.
Building domain-representative golden datasets
A golden dataset for a domain agent should be drawn from the actual distribution of inputs the agent will encounter. This sounds obvious, but in practice most evaluation datasets are constructed by AI engineers who don’t have deep domain knowledge, resulting in test cases that are representative of how engineers expect users to interact with the system rather than how users actually interact with it.
Building domain-representative golden datasets requires involvement from domain experts and, ideally, analysis of real interaction data. For a customer engagement agent, the golden dataset should include examples of the most common customer requests, the most common edge cases, and the most common failure modes informed by analysis of existing customer support tickets, chat logs, and call recordings. For a location agent, it should include routing requests that represent the actual distribution of logistics scenarios the system will handle.
Amazon Bedrock AgentCore Evaluations supports custom evaluators that can encode domain-specific criteria. For a customer engagement agent, custom evaluators can assess whether the agent’s response adheres to the brand’s tone guidelines, whether it correctly identified the customer’s intent, and whether it provided a complete and accurate answer — criteria that the built-in evaluators don’t capture.
Domain expert involvement in evaluation
Domain evaluation at scale requires a combination of automated evaluation, LLM-as-a-judge with domain-specific rubrics, schema validation, automated fact-checking and human evaluation by domain experts who can assess quality dimensions that automated methods miss.
The most efficient approach is to use automated evaluation for high-volume, continuously running assessment, flagging responses that fall below threshold on objective criteria and human evaluation for the edge cases and quality dimensions that automated methods can’t assess. Domain experts review the flagged responses, provide quality annotations, and contribute those annotations back to the golden dataset as new test cases. This creates a cycle where the evaluation system improves as the agent is used in production.
Integrating domain agents into the multi-agent architecture
Domain agents are most powerful not as standalone systems but as specialized components within the multi-agent architecture established in Module 4. A domain agent operating as a subagent in a coordinated system can contribute its specialized capabilities to complex workflows that require multiple domains of expertise.
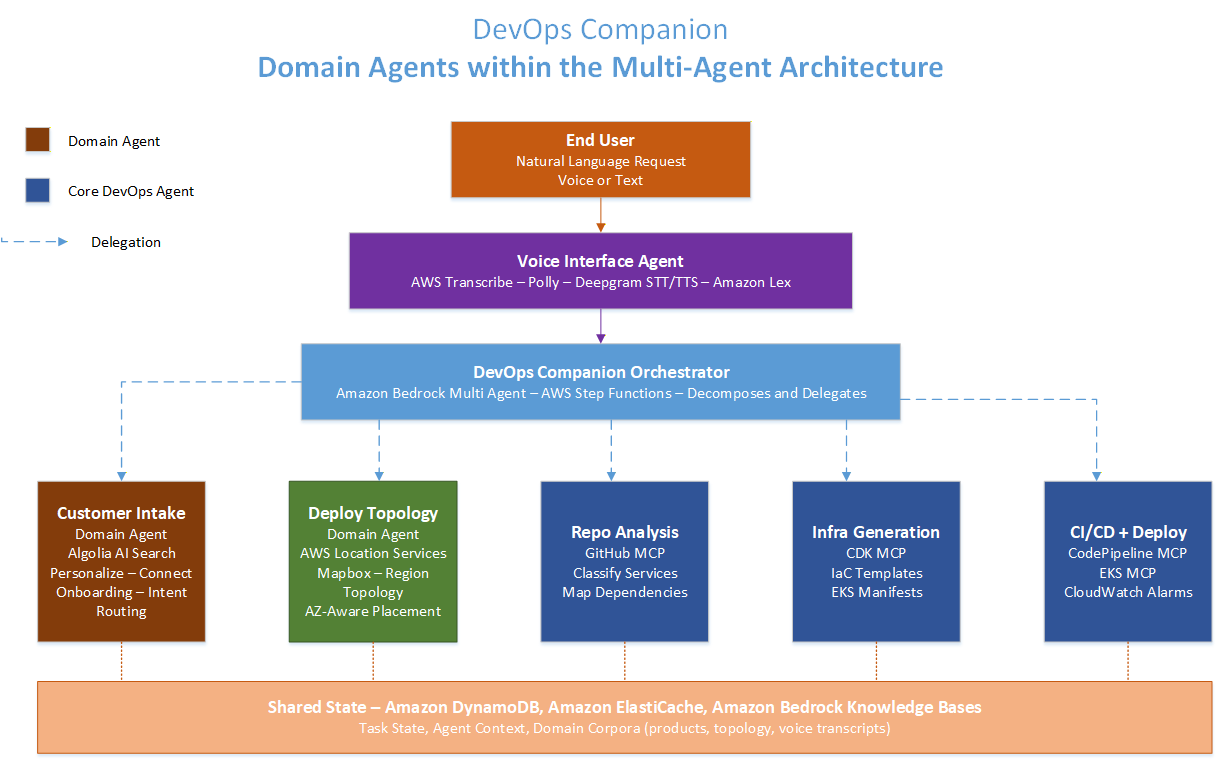
Figure 3: Domain-specialized agents integrated into the DevOps Companion multi-agent architecture
Designing domain agent interfaces for composability
For a domain agent to function as a composable component in a multi-agent system, its interface must be designed for programmatic consumption by an orchestrator, not just for direct user interaction. This means several things in practice.
The agent’s task schema, the structured format in which it receives delegated tasks, must be explicit and well-documented. An orchestrator can’t reliably compose a domain agent into a workflow if the agent’s input format is underspecified or inconsistent. The agent card (introduced in Module 4’s A2A discussion) should precisely describe the task schema, including required and optional fields, valid values, and the consequences of different field combinations.
The agent’s output schema must be equally explicit. The orchestrator needs to consume the domain agent’s output programmatically, extracting specific fields, validating the result against expected schemas, and passing relevant portions to downstream agents. An output format that’s appropriate for human reading but inconsistent in structure makes programmatic consumption fragile.
The agent’s scope boundaries must be enforced in a way that produces informative errors. When a domain agent receives a task that is outside its scope, it should return a structured error response that includes a clear indication of why the task is out of scope and, where possible, a suggestion for which agent or resource might be appropriate for the task. Generic error responses force the orchestrator to apply fallback logic without understanding the failure.
Independent versioning of domain agents
One of the key advantages of domain specialization is that domain agents can be updated independently. When the product catalog changes, the customer engagement agent’s knowledge corpus can be updated without touching the routing agent or the infrastructure agents. When Deepgram releases a new TTS model with better naturalness, the voice agent can be updated without requiring any changes to the agents it works with.
This independent evolution requires that the orchestrator treat domain agent versions as an explicit dependency. When a domain agent is updated, the orchestrator should run full evaluation against the updated version before routing production traffic to it — the same evaluation governance that applies to any other system component. Amazon Bedrock AgentCore’s version management capabilities support staged rollouts of agent updates, enabling gradual traffic shifting with automatic rollback if quality metrics degrade.
Worked example — three domains, one unified system
We now bring all the concepts in this module together in a walkthrough of the DevOps Companion extended with three domain-specialized agents, each operating within the multi-agent architecture established in Module 4.
The customer intake agent
The customer intake agent is the first point of contact for new users engaging with the DevOps Companion platform. It handles onboarding conversations, captures user intent and deployment requirements, and routes users to the appropriate downstream agent or human operator based on their needs.
The intake agent’s system prompt establishes a warm, professional persona focused on understanding user needs and setting accurate expectations. Its knowledge corpus contains the platform’s capability documentation, onboarding guides, and a FAQ addressing the most common questions from new users. Its tool set is intentionally limited: it can query Amazon Personalize to surface relevant getting-started paths based on the user’s profile, it can query Algolia to search the capability documentation for user-mentioned concepts, and it can invoke the escalation tool to transfer to a human onboarding specialist when needed.
In terms of multi-agent integration, the intake agent operates at the entry point of the orchestration graph. When a new user session begins, the orchestrator delegates the intake phase to this agent. The intake agent’s output, a structured intake report containing the user’s deployment requirements, their technology stack, and any constraints they have specified, is stored in DynamoDB and consumed by the orchestrator as the input for its task decomposition and agent delegation logic.
The deployment topology agent
The deployment topology agent is a location-aware specialist that understands the physical and logical topology of the user’s target infrastructure. Its primary input is the deployment target specification produced by the orchestrator, the set of AWS regions, availability zones, and compute targets where the user’s services should be deployed.
The topology agent uses Amazon Location Service and Mapbox to compute geographic relationships between regions: latency distances, data residency zone boundaries, and physical separation relevant to disaster recovery requirements. It also queries the user’s existing infrastructure topology from DynamoDB and the AWS account context to understand the constraints that apply to the deployment. Its output is a structured topology plan that the infrastructure generation agent and deployment agent consume downstream.
For the voice interface use case, the topology agent is particularly valuable. When a user asks a voice query like “Is our deployment meeting the EU data residency requirements?”, the orchestrator delegates the question to the topology agent, which queries the deployment topology records and cross-references them with the geofencing boundaries configured in Location Service for EU data zones. The result is returned to the orchestrator, which uses the voice interface agent to synthesize a concise spoken response.
The voice interface agent
The voice interface agent serves as the speech processing layer for all user interactions that occur through voice. It’s not a domain specialist in the DevOps sense, it doesn’t understand infrastructure or deployment. It’s a domain specialist in voice interaction: handling STT, intent extraction from spoken input, and TTS for spoken output.
The voice agent’s pipeline integrates Amazon Transcribe for real-time streaming transcription and Deepgram TTS for response synthesis. When a user sends an audio stream to the system, the voice agent receives it, invokes the Transcribe streaming tool through MCP, extracts the transcript, identifies the user’s intent, and passes a structured intent object to the orchestrator as its output. When the orchestrator has produced a response, it passes the text to the voice agent’s TTS tool, which synthesizes the response using the appropriate Deepgram or Polly voice model and returns an audio stream to the user.
The voice agent’s system prompt explicitly encodes voice-appropriate response constraints: maximum response length, prohibition on formatted text and code blocks, preference for confirmation patterns (“I’ve started the deployment, shall I continue?”) over long monologues, and specific instructions for handling low-confidence transcriptions.
Shared state and evaluation
All three domain agents read from and write to the shared DynamoDB task state. The intake report, the topology plan, and the voice transcript history are all stored as structured records keyed to the session ID, accessible to all agents in the workflow.
Each domain agent has its own evaluation dataset. The intake agent is evaluated on a corpus of realistic onboarding conversation scenarios, scored by the platform’s customer experience team. The topology agent is evaluated against a set of topology queries with known correct answers, including edge cases around data residency boundaries and multi-region configurations. The voice agent is evaluated on audio recordings from a range of environments and speakers, with transcription accuracy measured against human-verified transcripts and response naturalness assessed by a panel of native speakers of each supported language.
Full evaluation runs complete user journeys, from voice intake through deployment, against a set of composite test cases, measuring goal success rate at the system level. This full evaluation is the primary quality gate before any agent update is promoted to production.
Conclusion and looking ahead
Here’s the practical upshot: domain specialization works, but only if you treat the four levers, system prompt, knowledge corpus, tool selection, and guardrails as active engineering concerns, not defaults. Teams that skip corpus curation or deploy without domain-representative evaluation datasets find out the hard way that a general-purpose agent behaving at 92% accuracy in testing can fall to 75% on the specific failure modes that matter in their domain. The difference between those two numbers is a production incident.
The three domains covered in this module: customer engagement, location-aware logistics, and voice interaction represent three different dimensions of agent specialization: the commercial dimension of user-facing value delivery, the spatial dimension of physical-world reasoning, and the interface dimension of multimodal human interaction. Together, they show how the same architectural foundation can support radically different capabilities through deliberate specialization.
Module 6: Agent Orchestration extends the multi-agent architecture in a new direction beyond the patterns and protocols covered in Module 4, into the operational concerns of orchestrating agents at enterprise scale: lifecycle management, dependency handling, workflow versioning, and alignment with existing enterprise processes.
Featured AI tools in AWS Marketplace
Build with foundation models, deployment platforms, and AI infrastructure — all available through your AWS account.
Why AWS Marketplace for on-demand cloud tools
Free to try. Deploy in minutes. Pay only for what you use.
Featured tools are designed to plug in to your AWS workflows and integrate with your favorite AWS services.
Subscribe through your AWS account with no upfront commitments, contracts, or approvals.
Try before you commit. Most tools include free trials or developer-tier pricing to support fast prototyping.
Only pay for what you use. Costs are consolidated with AWS billing for simplified payments, cost monitoring, and governance.
A broad selection of tools across observability, security, AI, data, and more can enhance how you build with AWS.
Continue your journey
This series builds progressively: from agent fundamentals and tool use, through evaluation and multi-agent coordination, to domain specialization. Module 5 is where architecture meets production reality. Look back at multi-agent patterns, or continue to enterprise-scale orchestration.