- AWS Marketplace
- AI agent learning series
- Module 4 - Multi-agent architectures
Multi-agent architectures on AWS
Multiple agents are a distributed system. Build production multi-agent pipelines with LangGraph, AWS Step Functions, Amazon EventBridge, and Amazon MQ — from supervisor patterns to reliable inter-agent messaging.
Overview
Technical workshop: Multi-agent architectures
Build a multi-agent pipeline using the supervisor pattern in LangGraph, then deploy it on AWS. You’ll wire durable orchestration with Step Functions (retries, branching, parallel fan-out), event-driven agent coordination with EventBridge, and reliable inter-agent messaging with Amazon MQ. Walk away with a working architecture you can extend — not just slides.
📅 April 28, 2026
🕐 10:00 AM PT
🎓 Practical demos
📊 Intermediate
✓ Free to attend

Multi-agent architectures
Single-agent systems hit a ceiling when tasks require diverse expertise, parallel execution, or domain isolation. Multi-agent architectures break complex work into specialized agents that collaborate through well-defined interfaces. This guide covers three core patterns — supervisor, hierarchical, and peer-to-peer — and shows how to implement each with LangGraph on AWS Step Functions, Amazon EventBridge, and Amazon MQ. You’ll learn when to choose each pattern and the infrastructure trade-offs that determine whether your system scales or stalls.
Featured AI tools in AWS Marketplace
Build with foundation models, deployment platforms, and AI infrastructure—all available through your AWS account.

Page topics
- Introduction
- Why multi-agent? The case for collaborative AI systems
- Anatomy of a multi-agent system
- Orchestration patterns — how agents coordinate
- Non-determinism at scale — managing uncertainty across agents
- Shared context and knowledge exchange
- The MCP protocol — a standard interface for agent capabilities
- The A2A protocol — agent-to-agent communication
- Trust, identity, and security in multi-agent systems
- Failure modes and resilience patterns
- Observability across agent boundaries
- Worked example — the DevOps Companion as a multi-agent system
- Conclusion and looking ahead
Introduction
Modules 1 through 3 gave us the complete toolkit for a single agent: how to reason, how to use tools, how to evaluate performance, and how to route decisions. For many use cases, that’s enough.
But some problems don’t fit inside a single agent. When a task is too complex for one context window, too broad for a single specialty, or too slow if executed sequentially, the right answer is to bring multiple agents to bear on the problem — each contributing what it does best, coordinated by a system that understands how to sequence, parallelize, and synthesize their contributions.
This is the shift from a single intelligent worker to an intelligent team. And like any team, multi-agent systems require architecture: clearly defined roles, reliable communication, shared information, and rules for what happens when something goes wrong.
The DevOps Companion runs throughout this module as the concrete example. We watch it evolve from a single agent into a four-agent system handling the full software delivery lifecycle — repository inspection, infrastructure generation, CI/CD configuration, deployment, and observability. The architecture concepts here aren’t abstract: each one maps to a decision you’ll need to make when you build your own system.
Why multi-agent? The case for collaborative AI systems
Moving from a single agent to a multi-agent system is an architectural decision with real engineering cost. Move too early and you’ve added unnecessary complexity. Move too late and your system breaks under the weight of tasks it was never designed to handle. I’ve seen teams skip this decision entirely and just keep piling tools and prompt instructions onto a single agent — it doesn’t end well.
The most common trigger for the transition is context window saturation. Every agent has a finite working memory — the context window of the underlying language model. Complex, long-horizon tasks generate more intermediate state than any single context window can hold. When an agent is asked to inspect a large repository, generate infrastructure code, configure a CI/CD pipeline, and plan a deployment strategy all in a single session, it will eventually lose track of earlier information. The agent doesn’t know it has forgotten; it simply works with an incomplete picture.
The second trigger is task specialization. Some tasks require deep expertise that’s difficult to combine in a single agent without degrading quality. An agent optimized for security auditing produces different outputs than one optimized for infrastructure generation. When these specialties are combined into a single agent with a single system prompt and a shared tool set, the result is often mediocrity across the board rather than excellence in either domain. Separate agents, each with a focused persona, a curated tool set, and a purpose-built retrieval corpus, consistently outperform a single generalist on multi-domain tasks.
The third trigger is latency and parallelism. Sequential execution is often unnecessarily slow. If a deployment workflow requires a security audit, a cost estimate, and a compliance check, and if these three tasks are independent of each other, running them in parallel rather than in sequence can cut total execution time by a factor of three. Multi-agent systems support this parallelism naturally through fan-out orchestration patterns.
The fourth trigger is fault isolation. In a single-agent system, a tool failure or a reasoning error can derail the entire workflow. In a multi-agent system, failures are localized. A failure in the infrastructure generation agent doesn’t prevent the CI/CD agent from completing its work. Circuit breakers, retries, and fallback strategies can be applied at the agent boundary rather than requiring the entire workflow to restart.
When to stay single-agent
- Tasks that fit comfortably within one context window with room to spare
- Workflows where the steps are tightly interdependent and parallelism provides no benefit
- Prototyping or early development phases where simplicity matters more than scale
- Cases where the orchestration overhead would exceed the performance benefit
Amazon Bedrock multi-agent collaboration is the AWS-native foundation for building multi-agent systems. It provides a managed orchestrator that can delegate tasks to subagents, each running on Amazon Bedrock with their own system prompts, knowledge bases, and tool configurations. Amazon Bedrock AgentCore provides the runtime layer for hosting individual agents with production-grade security, observability, and lifecycle management. AWS Step Functions complements both, by providing durable, stateful workflow orchestration that keeps complex multi-step agent workflows running reliable even when individual agents fail.
That said: these services don’t eliminate the hard architectural decisions. They give you the infrastructure. You still have to design the agent boundaries, the handoff contracts, and the failure handling.
Anatomy of a multi-agent system
Four planes make up every production multi-agent system, regardless of orchestration pattern: the control plane, the execution plane, the state plane, and the capability plane. Get one of these wrong and the whole system is harder to build, debug, and maintain than it needs to be.
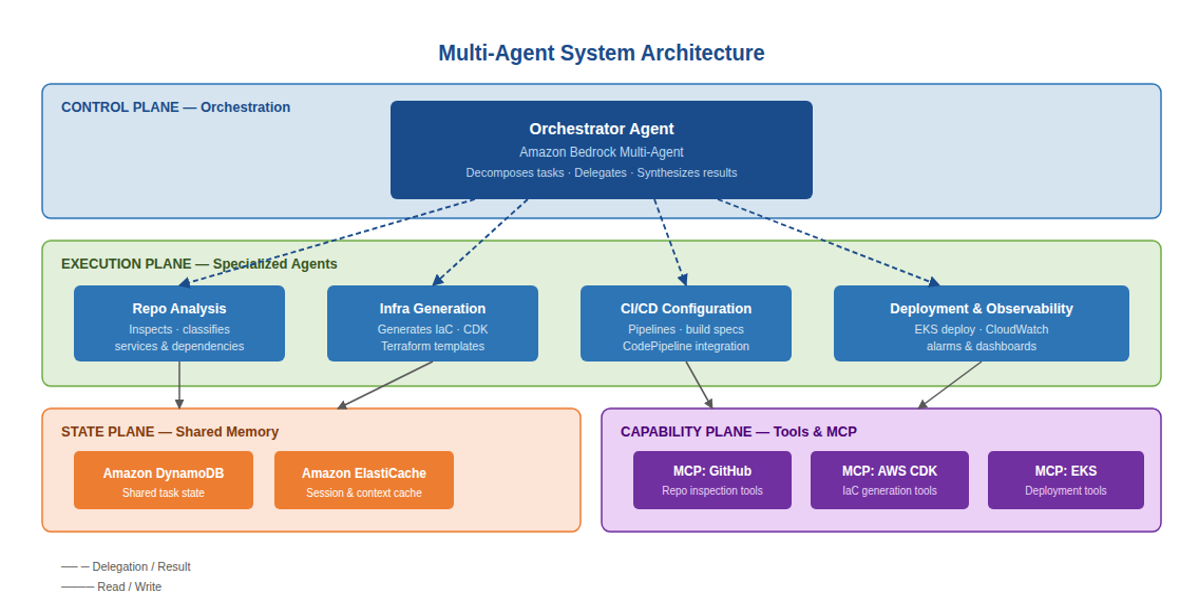
Figure 1: The four planes of a multi-agent system, illustrated with the DevOps Companion
The control plane — orchestration
The control plane is where decisions about delegation are made. The orchestrator agent sits in this plane, maintaining a high-level understanding of the overall goal, decomposing it into tasks, assigning those tasks to appropriate subagents, monitoring progress, and synthesizing results when subtasks complete.
The orchestrator doesn’t perform the work itself — it directs. This is an important distinction. An orchestrator that also tries to directly execute domain-specific tasks conflates two concerns and undermines the clean separation of responsibilities that makes multi-agent systems effective. In Amazon Bedrock multi-agent collaboration, the supervisor agent occupies the control plane exclusively, delegating all substantive work to subagents.
The control plane also handles conflict resolution when subagents return inconsistent results, and it makes the final determination about when the overall goal has been achieved. In AWS Step Functions, the state machine itself plays a control plane role, determining which branch to take, which parallel steps to execute, and how to handle failures at each transition.
The execution plane — specialized agents
The execution plane contains the specialized agents that do the actual work. Each agent in the execution plane has a clearly scoped responsibility, a system prompt tailored to its domain, a set of MCP tools appropriate to its function, and a retrieval corpus aligned with the knowledge it needs.
The DevOps Companion’s execution plane contains four specialized agents: a repository analysis agent that inspects codebases and classifies services and dependencies; an infrastructure generation agent that produces CDK templates and Terraform configurations; a CI/CD agent that generates pipeline configurations and build specifications; and a deployment and observability agent that manages EKS deployments and configures CloudWatch alarms and dashboards.
Each of these agents is independently deployable, independently evaluatable, and independently scalable. When the infrastructure generation agent needs to be updated to support a new IaC pattern, that update doesn’t require touching the other agents. This independent evolution is a major operational advantage, and one that’s very hard to replicate if you’ve built everything into a single agent.
The state plane — shared memory
The state plane provides the shared information layer that agents use to coordinate without direct coupling. Two agents that never communicate directly can still collaborate effectively if they both read from and write to a shared state store.
Shared state typically includes: the overall task definition and its current status; intermediate results produced by agents that other agents need as inputs; conversation context that needs to be accessible across agent boundaries; and metadata about which agents have completed which subtasks.
Amazon DynamoDB serves as the durable shared state store for the DevOps Companion — holding task state, agent results, and workflow progress with single-digit millisecond latency. Amazon ElastiCache provides the in-memory cache layer for session data and short-lived context that needs to be accessed with sub-millisecond response times. Amazon Bedrock Knowledge Bases provides the shared retrieval layer, giving all agents access to the same domain knowledge without each agent needing to maintain its own copy.
The capability plane — tools and MCP
The capability plane contains the tools that agents use to interact with the world: reading from repositories, writing infrastructure templates, triggering deployments, querying monitoring systems, and calling external APIs. In a multi-agent system, tools are exposed through MCP servers that provide standardized, discoverable interfaces.
The capability plane is shared across the execution plane — multiple agents may use tools from the same MCP server, subject to their individual access controls. This sharing is intentional: it prevents tool duplication and ensures that when the GitHub MCP server is updated, all agents that use it immediately benefit from the update without requiring individual agent changes.
Orchestration patterns — how agents coordinate
The orchestration pattern is the most consequential architectural decision you’ll make in a multi-agent system. It determines how tasks flow between agents, how results are aggregated, and how failures are handled. I’d recommend starting with the simplest pattern that fits your workflow and only moving to a more complex one when you hit a concrete limitation. There are four primary patterns.
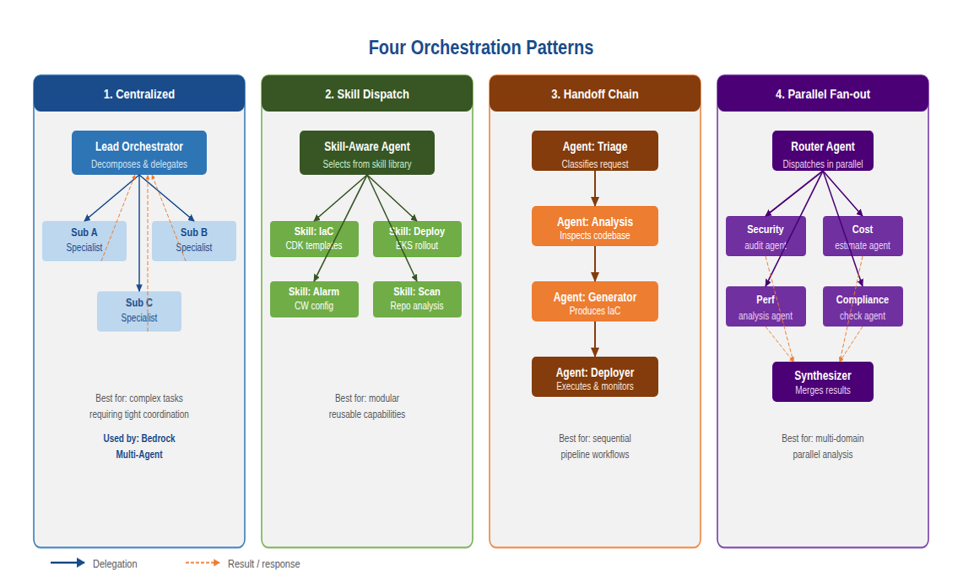
Figure 2: The four orchestration patterns and their best-fit scenarios
Pattern 1: Centralized orchestration
In centralized orchestration, a lead agent decomposes the task and delegates subtasks to specialized subagents. The lead agent maintains the full task context, tracks what each subagent has completed, and synthesizes their outputs into a final result.
This is the most flexible and powerful pattern. The lead agent can make dynamic decisions about delegation order, handle unexpected results from subagents by re-routing, and adapt the plan in real time as new information arrives. It’s the natural fit for complex, open-ended tasks where the exact sequence of subtasks can’t be determined upfront.
Amazon Bedrock Multi-Agent Collaboration implements centralized orchestration natively. The supervisor mode allows a designated orchestrator agent to invoke other Bedrock agents as subagents, with the full conversation history and task context passed at each delegation step. The orchestrator handles synthesis of subagent responses and manages the overall dialogue state.
The primary risk: the lead agent becomes a single point of failure and a reasoning bottleneck. If the orchestrator makes poor decomposition decisions, the entire workflow suffers. This makes the orchestrator’s system prompt, evaluation, and monitoring more important than any individual subagent’s. Don’t underinvest there.
Pattern 2: Skill-based dispatch
In skill-based dispatch, an agent maintains a library of pre-built capabilities — skills — and selects which skill to invoke based on the current task. Each skill is a well-defined, parameterized operation that executes a specific workflow and returns a structured result.
Skills are simpler than full agents. They don’t reason or make decisions; they execute a defined process. This makes them highly reliable and easy to test. A skill that generates a CloudFormation template from a service specification will produce consistent, predictable output that can be validated against a schema.
Skill-based dispatch works well when the set of required operations is known in advance and relatively stable. It’s less appropriate for open-ended tasks where the agent may need to improvise or combine operations in novel ways. In the DevOps Companion, the IaC generation workflow is implemented as a skill — the orchestrator identifies the target infrastructure pattern and invokes the IaC skill with the appropriate parameters, receiving a structured template in return.
Pattern 3: Handoff chains
In a handoff chain, agents transfer control to the next agent in a sequence. Each agent receives the output of its predecessor, performs its specific function, and passes the enriched result forward. The final agent in the chain produces the overall output.
Handoff chains are the right pattern for linear, sequential workflows where each step depends on the completion of the previous step and where the processing steps are well-understood in advance. They map naturally to pipeline architectures and are easy to reason about and debug.
AWS Step Functions implements handoff chain semantics through its state machine model. Each state in the machine represents an agent invocation, and the output of each state is passed as input to the next. Step Functions handles the durable execution, retry logic, and error handling at each handoff boundary, ensuring that failures in one agent don’t cause silent data loss or incomplete execution.
The risk of handoff chains is rigidity. When the workflow needs to branch based on intermediate results — for example, routing to different downstream agents based on what the analysis agent discovers — a pure handoff chain becomes unwieldy. In practice, handoff chains are often combined with routing logic at each step, implemented through AWS Step Functions Choice states.
Pattern 4: Parallel fan-out and synthesis
In parallel fan-out, a router agent dispatches the same task to multiple specialist agents simultaneously. Each agent works independently on its area of expertise, and a synthesizer agent collects their results and produces a unified output.
This pattern is purpose-built for tasks that span multiple independent domains. When asked to evaluate a proposed deployment — assessing security posture, cost impact, performance characteristics, and compliance status — running four specialist agents in parallel and synthesizing their findings is dramatically faster and more accurate than running them sequentially or attempting to cover all four domains in a single agent.
Amazon EventBridge and Amazon SQS are the natural AWS services for implementing fan-out messaging in multi-agent workflows. EventBridge rules can dispatch a single task event to multiple agent Lambda functions simultaneously. SQS FIFO queues provide ordered, exactly-once delivery for cases where the order of agent execution matters even within parallel processing.
The synthesis step is critical and routinely underbuilt. When multiple specialist agents return conflicting assessments, the synthesizer must resolve the conflict intelligently. A security agent may flag a configuration as a risk while the operations agent treats the same configuration as a reliability best practice. The synthesizer needs domain context — and in some cases human judgment — to handle these conflicts. I’ve seen teams wire up the fan-out correctly and then hand synthesis to a generic “summarize these results” prompt, which fails badly on disagreements.

Non-determinism at scale — managing uncertainty across agents
In Module 3, we examined non-determinism within a single agent — the probabilistic nature of language model outputs and how evaluation frameworks help us characterize and bound that uncertainty. In multi-agent systems, non-determinism doesn’t stay bounded within individual agents; it propagates and compounds across every delegation and handoff boundary.
The math is unforgiving. In a four-agent pipeline where each agent produces correct output 90% of the time, the probability that all four agents produce correct output in a single complete run is approximately 66%. At 95% per agent, it’s 81%. At 99% per agent, it’s still only 96%. Individual agent quality must be substantially higher than the acceptable overall error rate — and full end-to-end evaluation is non-optional, not a nice-to-have.
Structural outputs as a non-determinism boundary
The single most effective technique for stopping non-determinism from propagating across agent boundaries: require structured, schema-validated outputs at every handoff point. An agent that returns free-form prose creates downstream ambiguity. The next agent must interpret the output and may misinterpret it. An agent that returns a validated JSON document conforming to a known schema creates a precise, unambiguous contract. You should treat free-form inter-agent prose as a bug, not a design option.
In the DevOps Companion, the repository analysis agent always returns a structured service manifest: a documented schema defining each discovered service, its runtime, its dependencies, its estimated scale characteristics, and a confidence score for each field. The infrastructure generation agent consumes this schema directly, with no natural language interpretation required. When the repository analysis agent is uncertain about a field, it returns a low confidence score rather than a guess — signaling to the orchestrator that human review or additional analysis may be warranted.
Amazon Bedrock’s structured output capabilities, combined with Claude’s native support for JSON schema constraints, allow agents to produce reliably structured outputs without sacrificing reasoning quality. The model reasons in natural language internally but produces its final output in the constrained format.
Confidence scoring and abstention
Not every agent should be required to produce an answer for every task. When an agent is uncertain — when the evidence is insufficient, when the task is outside its training distribution, or when conflicting signals can’t be resolved — the correct behavior is abstention: returning a structured indication that the task can’t be completed with acceptable confidence, rather than producing a low-quality output that will silently degrade downstream results.
Building abstention behavior requires explicit evaluation. The golden datasets used in Module 3’s evaluation framework should include cases that are deliberately outside the agent’s scope, and the expected output for those cases should be a well-formed abstention response rather than a best-effort answer. Agents that never abstain, regardless of input quality, are a reliability risk in multi-agent systems.
End-to-end evaluation across agent boundaries
Evaluating individual agents in isolation, as described in Module 3, is still necessary — but it’s not sufficient. Full evaluation means running the complete multi-agent workflow against a test suite and measuring the final output against expected results. That’s what catches the compounding failure modes that only appear when agents interact. A test harness that only covers individual agents will miss a significant class of real bugs.
Amazon Bedrock AgentCore Evaluations supports multi-agent evaluation across the full agent graph through its online evaluation mode, which can instrument production traffic. The Builtin.GoalSuccessRate evaluator is the right tool for multi-agent assessment — it measures whether the overall goal was achieved, regardless of which agent in the chain produced the final output. LangSmith, available on AWS Marketplace, provides trace visualization across multi-agent workflows and makes it straightforward to attribute failures to specific agents.
Shared context and knowledge exchange
A multi-agent system is only as good as its information sharing. An agent that produces a correct analysis that gets dropped at the handoff boundary is no better than an agent that never ran. Getting shared context right — what to store, where, and in what format — is as important as the agents themselves.
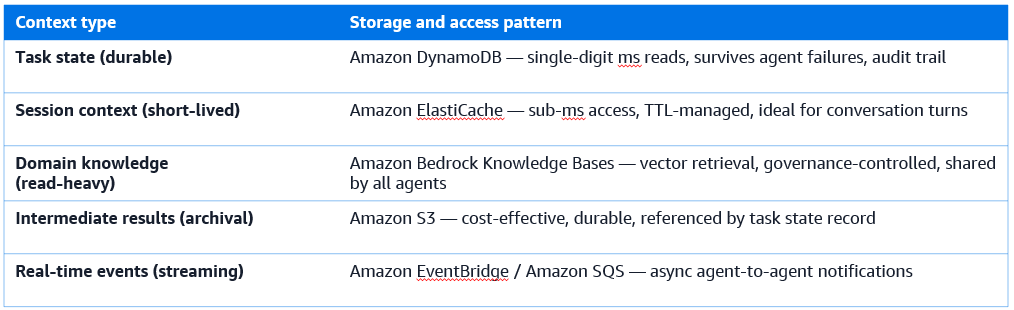
What needs to be shared
Not all information needs to be shared equally. There are three categories and mixing them up leads to poor storage choices and unnecessary latency.
Task state tracks what’s been requested, what’s been completed, and what remains. It’s durable — it must survive agent failures and restarts — and it’s the single source of truth for orchestration decisions. Task state belongs in Amazon DynamoDB, where it persists reliably and can be queried with single-digit millisecond latency by any agent in the system.
Session context makes agent responses coherent within a single interaction: prior conversation turns, user-provided constraints, intermediate results from earlier steps. It’s shorter-lived than task state and benefits from the sub-millisecond access latency of Amazon ElastiCache. Don’t put session context in DynamoDB if sub-millisecond access matters — you’ll pay for the extra latency at every agent step.
Domain knowledge is the shared retrieval layer: the corpora that agents consult for facts, specifications, or historical precedents. It’s read-only from an agent’s perspective and managed through Amazon Bedrock Knowledge Bases, which provides vector retrieval across large document collections with governance-controlled access for all agents.
Designing handoff payloads
The handoff payload — the data structure passed from one agent to the next — is one of the most consequential design decisions in the system. Too minimal and the downstream agent re-derives work that’s already been done. Too verbose and you bloat context windows with noise that degrades reasoning quality.
The right principle: include what the next agent needs to complete its task, and nothing more. For the DevOps Companion, the handoff from the repository analysis agent to the infrastructure generation agent includes the service manifest, the detected technology stack, and the estimated scale characteristics — but not the raw file content or intermediate analysis steps. Those go to DynamoDB for audit purposes, but they’re not forwarded in the active payload.
Context summarization strategies
In long-running workflows, context windows can saturate on accumulated history. Context summarization — condensing prior history into a compact summary before forwarding it to the next agent — is the standard technique.
There’s a real tradeoff here. Compressing history risks losing information a future agent will need. Free-form LLM summarization is particularly risky because the model decides what’s important, and it won’t always guess right. For the DevOps Companion, I’d recommend structured summarization instead: the orchestrator maintains a structured task manifest that records key decisions and outputs from each completed agent in a standardized schema. This produces a compact, lossless summary that any agent can consume in a few hundred tokens — no LLM judgment calls required.
The MCP protocol — a standard interface for agent capabilities
The Model Context Protocol (MCP) was introduced in Module 2 as the standard way for an individual agent to interact with tools. In multi-agent systems it becomes even more important: it’s the mechanism by which the capability plane is made accessible to all agents in a consistent, discoverable, and governable way. Without MCP, you end up with each agent team writing their own tool integration — which means tool updates break some agents but not others, and nobody has a consistent picture of what’s available.
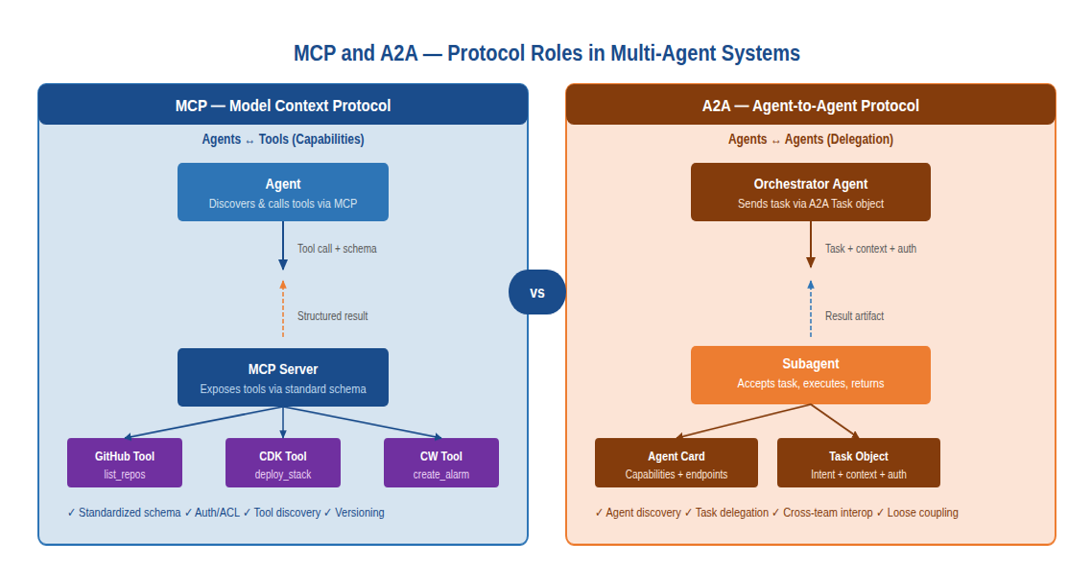
Figure 3: MCP and A2A — protocol roles and boundaries in multi-agent systems
MCP in the context of multiple agents
When multiple agents share access to the same MCP server, the server must be designed with multi-tenancy in mind. The authentication and authorization model determines which agents can call which tools, with what parameters, and subject to what rate limits. An MCP server that allows any agent to call any tool with any parameters is a security liability — a compromised or misbehaving agent gets unrestricted access to the entire capability layer.
Well-designed MCP servers in multi-agent systems implement agent-aware access controls: the repository analysis agent can call read-only GitHub tools but not write tools; the infrastructure generation agent can write CDK templates to a staging S3 bucket but not deploy them; the deployment agent can initiate deployments but only to explicitly approved target environments. Enforce these controls at the MCP server level, not in the agents’ system prompts. System prompt-based controls can be overridden by prompt injection or model reasoning errors. Server-level controls can’t.
Tool schema design for reliability
The quality of a tool schema directly affects the quality of agent behavior. A tool with an ambiguous schema — vague parameter descriptions, optional fields with unclear defaults, return values that vary in structure — produces inconsistent agent behavior because the model must infer intent where the schema is silent. Bad schemas are a surprisingly common root cause of agent quality problems.
Effective tool schemas for multi-agent systems need three things: precise parameter descriptions that explain not just what a parameter is but what values are acceptable and what the consequences of different values are; consistent return schemas where every call returns data in the same structure, including error cases; and error responses informative enough that the calling agent can determine whether to retry, fail gracefully, or escalate to the orchestrator.
MCP lifecycle management
MCP servers evolve over time — tools are added, parameters change, behaviors are updated. In a multi-agent system where multiple agents share the same MCP servers, a breaking change to a tool schema can silently corrupt the behavior of every agent that calls that tool. This is a real production hazard.
You should explicitly track the MCP server version in each agent’s configuration and test agents against new server versions before updating in production. Amazon Bedrock AgentCore provides lifecycle management for agents and their associated MCP server configurations, supporting staged rollouts with evaluation gates between stages.
The A2A protocol — agent-to-agent communication
Where MCP standardizes how agents interact with tools, the Agent-to-Agent (A2A) protocol standardizes how agents interact with each other. These are distinct problems requiring distinct solutions. Don’t try to use MCP for agent-to-agent delegation — it’s the wrong abstraction and you’ll end up fighting it.
MCP is a client-server protocol: an agent (the client) calls a tool exposed by a server. The agent initiates all interactions; the server responds. A2A is a peer protocol: any agent can act as either initiator or receiver, delegating tasks to or accepting tasks from other agents. The relationship is symmetric, and the communication is richer: A2A messages carry not just function calls but full task objects with context, intent, authorization, and expected output format.
The A2A task object
The fundamental unit of A2A communication is the task object. A task object carries the information an agent needs to begin working on a delegated assignment: the task description, the relevant context (including prior work by other agents), the authorized resources the receiver agent may access, the expected output format, and any constraints or guardrails that apply to this specific task instance.
The richness of the task object is what makes A2A more suitable than MCP for agent-to-agent delegation. When the DevOps Companion’s orchestrator delegates a subtask to the infrastructure generation agent, it doesn’t just send a function call — it sends a task object that includes the service manifest produced by the analysis agent, the deployment target constraints approved by the user, the IaC pattern preference, and a structured output schema that the orchestrator expects to receive in return.
Agent cards — discoverability and capability declarations
For A2A to support loosely coupled agent ecosystems, agents need a way to advertise their capabilities without requiring pre-built integration. That’s what agent cards do.
An agent card is a structured document, published at a known endpoint, that describes what the agent can do: the task types it accepts, the input schema it expects, the output schema it produces, its authentication requirements, its rate limits, and any constraints on tasks it will process. Orchestrators discover agents by querying a registry of agent cards and can dynamically compose multi-agent workflows from agents they’ve never been explicitly programmed to use.
This dynamic composability matters most at organizational scale. New specialized agents built by different teams — or different organizations — can be incorporated into existing orchestrated workflows immediately, without changes to the orchestrator’s code. That’s a significant reduction in integration overhead as your agent ecosystem grows.
A2A security considerations
A2A communication between agents introduces an expanded attack surface. Every A2A endpoint is a potential injection point — a compromised or adversarial agent could send a task object to a legitimate agent with malicious content in the task description or context fields, attempting to hijack the receiver agent’s behavior through what is effectively a prompt injection at the inter-agent boundary.
Defending against this requires that receiver agents validate task objects against their schema before processing them, apply content filtering to task descriptions and context fields, and enforce the access controls declared in their agent cards regardless of what the task object claims to authorize. Amazon Bedrock Guardrails can be applied at the agent boundary to filter both incoming task objects and outgoing responses, providing a consistent defensive layer regardless of the task’s origin.
Trust, identity, and security in multi-agent systems
Security in multi-agent systems is qualitatively different from security in single-agent systems. The threat surface expands at every new agent boundary, every new MCP connection, and every new A2A communication channel. Three specific security challenges require explicit architectural responses — and all three are easy to get wrong if you treat multi-agent security as a straightforward extension of single-agent security.
Agent identity
In a single-agent system, the identity question is relatively simple: the user authenticates, and the agent acts with the permissions granted to that user. In a multi-agent system, the orchestrator acts on behalf of the user, and subagents act on behalf of the orchestrator. This chain of delegation creates an authorization propagation problem.
Without careful design, this chain becomes a privilege escalation vector. If the orchestrator has broad permissions and passes its full credentials to every subagent, each subagent inherits those broad permissions regardless of whether its task requires them. A vulnerability in any subagent then exposes the orchestrator’s full permission scope.
I recommend least-privilege scoped delegation as the only acceptable pattern here: the orchestrator’s credentials are never passed to subagents. Each subagent receives a scoped, time-limited credential that authorizes exactly the resources it needs for its assigned task. AWS IAM Roles Anywhere and AWS STS generate these scoped credentials dynamically at task initiation. CyberArk Agent Guard, available on AWS Marketplace, provides production-level management of agent credentials including dynamic secret generation, rotation, and revocation.
Prompt injection propagation
Prompt injection — embedding instructions in user-controlled content that cause an agent to deviate from its intended behavior — is a well-known single-agent threat. In multi-agent systems it becomes a propagation risk. An injection in a repository document processed by the analysis agent can influence the infrastructure generation agent if the injected content ends up in the handoff payload. The injection doesn’t need to target the agent that reads it; it can ride through the pipeline targeting a downstream agent.
Your defensive architecture must assume that any content that originated outside the system — from repositories, user uploads, external APIs, or web content — may contain injection attempts. Filter this content before it enters the handoff payload. And agents that consume handoff payloads should treat all externally-originated content as untrusted, regardless of how many agents have processed it since it entered the system.
Amazon Bedrock Guardrails provides content filtering at any agent boundary. Ping Identity, available on AWS Marketplace, provides identity orchestration for multi-tenant agent deployments where different users’ agents must be isolated from each other.
Trust boundaries and zero trust architecture
The right security posture for a multi-agent system treats every agent boundary as a trust boundary — assuming that any message arriving at an agent boundary may be malicious, regardless of its declared origin. This zero-trust approach requires every agent to validate the schema of every incoming message, filter content for injection attempts, verify the sender’s authorization claims, and enforce its own access controls independently of what the sender claims to have already verified.
This means security controls are applied redundantly at every layer — at the MCP server level, at the agent boundary, and at the orchestration layer. That redundancy is intentional. A failure or compromise at one layer doesn’t expose the full system. Yes, it’s more work to implement. It’s less work than cleaning up after a breach.

Failure modes and resilience patterns
Multi-agent systems introduce failure modes that don’t exist in single-agent systems. A prototype can ignore most of these and still look good in a demo. A production system can’t. Understanding these failure modes and designing explicit defenses from the start is what separates a system you can operate at scale from one that requires constant firefighting.
Cascading failures
A cascading failure occurs when the failure of one agent causes downstream agents to fail, which cause further downstream agents to fail, until the entire workflow collapses. In a tightly coupled handoff chain, a failure at any step stops all subsequent processing.
Circuit breakers are the defense: control logic that detects when an agent is failing repeatedly and stops routing work to it, letting the rest of the system continue with degraded capability rather than complete failure. AWS Step Functions implements circuit breaker semantics through its error handling and catch configuration, letting you specify fallback paths when specific error types are encountered.
Temporal Technologies, available on AWS Marketplace, provides durable workflow execution that’s resilient to cascading failures by default. When an agent fails in a Temporal workflow, the failure is recorded durably, the workflow pauses, and when the agent recovers or is fixed, the workflow resumes from exactly where it stopped — without re-executing steps that already completed successfully. For long-running, high-value workflows, that resume capability is worth the additional infrastructure.
Orchestration loops and runaway agents
Orchestration loops occur when an orchestrator repeatedly delegates tasks to subagents in a cycle — the orchestrator asks a subagent to validate another subagent’s output, the validation fails, the orchestrator asks for a revision, the revision fails the validation again, and the cycle repeats indefinitely. Without explicit termination logic, this can run up unbounded costs.
Every multi-agent workflow needs explicit loop detection and termination conditions. The orchestrator should maintain a step counter per task execution and enforce a maximum delegation count before forcing termination — either by surfacing the best available result with a quality warning, or by escalating to a human reviewer. Step Functions enforces maximum execution time and step limits natively.
Conflicting outputs from parallel agents
In parallel fan-out patterns, multiple agents may return conflicting assessments of the same subject. The security agent and the operations agent evaluate the same deployment configuration and reach opposite conclusions. The synthesis step must handle this conflict explicitly.
The synthesis strategy depends on the nature of the conflict. For safety-critical domains — security, compliance, regulatory — the conservative result should always win: if any specialist agent raises a concern, the concern is surfaced to the human user regardless of what other agents concluded. For operational domains, the synthesizer can apply domain-aware weighting, giving greater authority to the specialist whose domain is most relevant to the specific decision at hand.
Context corruption at handoff boundaries
Context corruption occurs when a handoff payload is malformed, truncated, or semantically inconsistent with what the agent on the receiving end expects. Serialization errors, schema version mismatches, and injected content are all causes. It’s more common than you’d expect in systems under active development.
The defense is schema validation at every handoff boundary. Every agent that consumes a handoff payload should validate it against the declared schema before acting on it. When validation fails, the agent returns a structured error to the orchestrator — it does not attempt to proceed with potentially corrupt data. The orchestrator can then decide whether to request the payload again or escalate the failure.
Observability across agent boundaries
Observability in a multi-agent system is a distributed systems problem. When a user reports that the DevOps Companion produced incorrect infrastructure code, you need to answer: was it the repository analysis agent that produced a wrong service manifest? The infrastructure generation agent that misinterpreted a correct manifest? The orchestrator that made a poor delegation decision? Without distributed tracing across agent boundaries, you’re guessing.
Distributed tracing in multi-agent systems
The key to multi-agent observability is a consistent trace identifier that propagates through every agent and tool call in a workflow. Every delegation, every MCP tool call, and every A2A message should carry the same trace ID, so that traces from different agents can be correlated into a single execution graph. If you skip this step, you’ll spend hours manually correlating log entries when something breaks in production.
Amazon CloudWatch Traces (formerly AWS X-Ray) provides distributed tracing across Lambda functions, Bedrock agent invocations, and Step Functions executions. With consistent trace ID propagation through the DevOps Companion workflow, CloudWatch renders the full execution graph — orchestrator invocation → repository analysis agent → MCP tool call → infrastructure generation agent → CDK template generation — as a single, navigable trace.
LangSmith, available on AWS Marketplace, provides purpose-built LLM tracing that renders multi-agent traces as a hierarchical tree, making it straightforward to navigate from the top-level orchestrator invocation down to individual tool calls within specific subagents. LangFuse, also on AWS Marketplace, provides similar capabilities with strong cost tracking — showing how token usage is distributed across agents and which agent is responsible for the majority of inference costs. On larger systems, that cost attribution data is genuinely useful for optimization decisions.
Per-agent evaluation in the context of the full system
Module 3’s evaluation framework applies at the individual agent level, but the evaluation results must be interpreted in the context of the full system. An agent that scores well in isolation may still contribute to system-level failures if its outputs are being consumed by other agents in unexpected ways. I’ve seen this pattern repeatedly: per-agent scores look great, system-level quality is poor, and the gap is in how agents interact.
I recommend a layered evaluation strategy:
- Per-agent evaluations on isolated test datasets characterize each agent’s individual quality
- Full evaluations on complete workflow test cases characterize system-level quality
- Differential analysis compares per-agent scores against system-level outcomes to identify agents whose isolated performance doesn’t predict their contribution to system-level results
Amazon Bedrock AgentCore Evaluations supports this layered approach. Per-agent evaluation uses on-demand mode with targeted test datasets. Full evaluation uses online mode, sampling production traffic and applying the Builtin.GoalSuccessRate evaluator at the system level. Differential analysis correlates per-agent evaluation scores with system-level outcomes.
Worked example — the DevOps Companion as a multi-agent system
Here’s where the concepts become concrete. We’ve been building toward this: a complete walkthrough of how the single-agent DevOps Companion from earlier modules is refactored into a coordinated multi-agent system.
From one agent to four
The original DevOps Companion was a single agent with a broad system prompt, a large set of tools, and a single context window handling the entire workflow: repository inspection, service classification, IaC generation, pipeline configuration, deployment, and observability setup. For simple repositories, that worked. For complex codebases, it didn’t — context saturation caused the agent to lose track of earlier analysis, tool call quality degraded as the context grew, and errors in one part of the workflow were hard to isolate.
The multi-agent refactoring creates four specialized agents, each with a focused responsibility, a scoped system prompt, and a tool set matched to that responsibility.
Agent specifications

Orchestration flow
The orchestrator receives the user’s request — a GitHub repository URL and a set of deployment target parameters. It constructs a task manifest and invokes the Repo Analysis agent through Amazon Bedrock multi-agent collaboration, passing the repository URL and the requested analysis depth.
When the Repo Analysis agent returns the ServiceManifest, the orchestrator validates it against its schema and stores it in DynamoDB. It then spawns parallel invocations of the Infra Generation and CI/CD Config agents, passing each the ServiceManifest and the relevant deployment target parameters. These two agents run concurrently, each writing their outputs to DynamoDB on completion.
The orchestrator monitors DynamoDB for completion of both parallel tasks. When both finish, it validates consistency: the infrastructure package and the pipeline configuration must reference the same service names and deployment targets. If they’re consistent, it invokes the Deploy and Observe agent with a consolidated task object containing the InfraPackage, PipelineConfig, and deployment target parameters.
The Deploy and Observe agent executes the deployment, monitors progress, and returns a DeploymentStatus and ObservabilityReport. The orchestrator synthesizes all four agents’ outputs into a user-facing summary.
Shared state design
DynamoDB stores the task manifest, agent completion status, and inter-agent payloads. Each workflow execution gets a unique task ID; all records for that execution key under that ID. This makes it straightforward to query the complete history of any execution and to resume after a failure at any step.
ElastiCache stores the active session context — conversation history, the current task ID, and recently accessed payloads — with a TTL aligned to the expected session duration. Bedrock Knowledge Bases provides the shared retrieval layer: all four agents query the same knowledge base for AWS service documentation, CDK construct references, and organizational deployment policies.
Evaluation and observability
Each agent has its own evaluation dataset and runs on-demand evaluation during development. The Repo Analysis agent is evaluated against a corpus of sample repositories with known service manifests. The Infra Generation agent is evaluated against service manifests with known correct IaC outputs. Full evaluation covers complete end-to-end workflow test cases — repository URL in, deployed observability report out — with AgentCore Evaluations running Builtin.GoalSuccessRate at the system level.
CloudWatch Traces provides distributed tracing across the full workflow. LangSmith provides per-agent trace visualization for development and debugging. CloudWatch dashboards track per-agent error rates, token costs, and latency percentiles, with alarms triggering when any agent’s quality metrics fall below threshold. Build these dashboards at the start — you’ll use them constantly.
Conclusion and looking ahead
Multi-agent architectures solve real problems that single agents can’t: parallelism across independent domains, per-domain specialization, fault isolation, and task complexity that exceeds what any single context window can hold. But they also add significant operational surface area. You’re now managing agent identity, prompt injection propagation across boundaries, compounding non-determinism, and distributed failure modes. Build the observability and schema validation infrastructure from day one — retrofitting it later is painful.
The four planes, the four orchestration patterns, MCP as the capability interface, A2A as the inter-agent communication standard, and shared state through DynamoDB and ElastiCache — these aren’t abstractions. They’re the specific engineering decisions that determine whether a multi-agent system is reliable, maintainable, and secure in production.
Module 5: Domain-Specific Agent Applications extends this foundation in a different direction — rather than asking how multiple agents coordinate, it asks how agents can be specialized for particular domains: customer engagement, geospatial reasoning, and voice-enabled interaction. The multi-agent architecture built in this module serves as the platform on which those domain specialists will be deployed.
Featured AI tools in AWS Marketplace
Build with foundation models, deployment platforms, and AI infrastructure — all available through your AWS account.
Why AWS Marketplace for on-demand cloud tools
Free to try. Deploy in minutes. Pay only for what you use.
Featured tools are designed to plug in to your AWS workflows and integrate with your favorite AWS services.
Subscribe through your AWS account with no upfront commitments, contracts, or approvals.
Try before you commit. Most tools include free trials or developer-tier pricing to support fast prototyping.
Only pay for what you use. Costs are consolidated with AWS billing for simplified payments, cost monitoring, and governance.
A broad selection of tools across observability, security, AI, data, and more can enhance how you build with AWS.
Continue your journey
Module 4 builds on evaluation and introduces multi-agent coordination. Next, see how agents solve real-world problems across sales, location, and voice domains.