- AWS Marketplace›
- Developer tools & tutorials›
- Data, analytics, & machine learning
Deploy enterprise-grade vector search with Amazon Bedrock and Zilliz Cloud
Enhance LLM responses with real-time data and vector search capabilities using Amazon Bedrock, LangChain, and Zilliz Cloud.
Introduction
The explosion of AI and large language model (LLM) applications has created an unprecedented demand for efficient vector storage solutions in enterprise environments. As a data architect, I want to deploy a solution that can effectively manage the exponential growth of unstructured data, such as text, images, and audio. In this article, I'll explore how Zilliz, an enterprise-ready vector database, provides the foundation for building an AI-powered application that can understand and process information with contextual awareness.
Beyond traditional databases – Vector intelligence
The rapid adoption of AI applications has created new challenges in how enterprises handle data. Traditional relational databases, while excellent for managing structured data like customer records or inventory systems, fall short when dealing with unstructured data that needs to be translated into high-dimensional vector embeddings. Think of vector embeddings as a way to translate real-world things into numbers that computers can understand. Whether it's words, pictures, music, or any digital content, these mathematical representations help AI make sense of them. This is where vector databases come in - they're specifically designed to store and efficiently query these numerical representations while preserving their semantic meaning.
As organizations increasingly adopt AI technologies, data architects like myself face the challenge of choosing the right vector database solution for storing and processing these high-dimensional vectors. Unlike traditional databases that rely on exact matches, vector databases excel at finding similarities between these complex data representations.
Enhancing LLM capabilities through vector storage
One of the most critical applications of vector databases has emerged in addressing a fundamental limitation of Large Language Models (LLMs): their data sources and cutoff date. LLMs, while powerful, are only trained on historical and public data up to a certain point in time. This creates a significant challenge for organizations needing to leverage current information or proprietary data in their AI applications. Vector databases bridge this gap by providing a dynamic and updateable knowledge store that can be seamlessly integrated with LLMs.
By converting current documents, articles, and organizational knowledge into vector embeddings, vector databases enable LLMs to access and reason about information beyond the knowledge gained from the data that was used to originally train them. This capability is particularly valuable for applications requiring real-time information access, such as customer support systems needing access to the latest product documentation or financial analysis tools requiring current market data.
The real-world implications are significant. Consider a semantic search application where users expect instant, contextually relevant results that include both historical and current information. Traditional databases might take seconds or even minutes to process these similarity queries, creating an unacceptable user experience. Similarly, recommendation systems handling millions of product embeddings need specialized vector database solutions to maintain performance at scale.
Moreover, vector databases play a crucial role in reducing LLM hallucinations - instances where models generate plausible but incorrect information. By providing access to accurate, up-to-date information stored as vector embeddings, these databases help ground LLM responses in factual, verifiable data. This is particularly important in enterprise settings where accuracy and reliability are paramount.
These challenges are why I'm exploring vector database solutions that can not only handle these workloads efficiently but also integrate seamlessly with our existing AWS infrastructure and AI frameworks like LangChain. The ability to maintain current, accurate information while providing fast, scalable access to vector embeddings has become a cornerstone of modern AI architecture.
Zilliz Cloud: Empowering enterprise-grade vector search
Zilliz Cloud is a fully managed vector database service built on top of the open-source Milvus database, offering a comprehensive solution for your vector search needs.
Zilliz Cloud integrates with the popular LangChain framework, enabling you to build Retrieval Augmented Generation (RAG) applications. By combining the power of vector search with large language models, you can develop AI-powered solutions that deliver contextually relevant and accurate responses, addressing the growing demand for more intelligent conversational interfaces.
Creating a RAG application with Zilliz, LangChain and Amazon Bedrock
Zilliz Cloud is available in AWS Marketplace including a free trial and as a pay-as-you-go solution, making it easy to prototype, build, deploy and integrate into your existing AWS infrastructure. Here's a step-by-step guide on how to get started:
Create a Zilliz Cloud Cluster
- Start by subscribing to Zilliz Cloud Vector Database in AWS Marketplace. Select the offering and follow the prompts to create a new Zilliz Cloud cluster.
- Create a Zilliz account, and create an Enterprise cluster with AWS as your cloud provider.
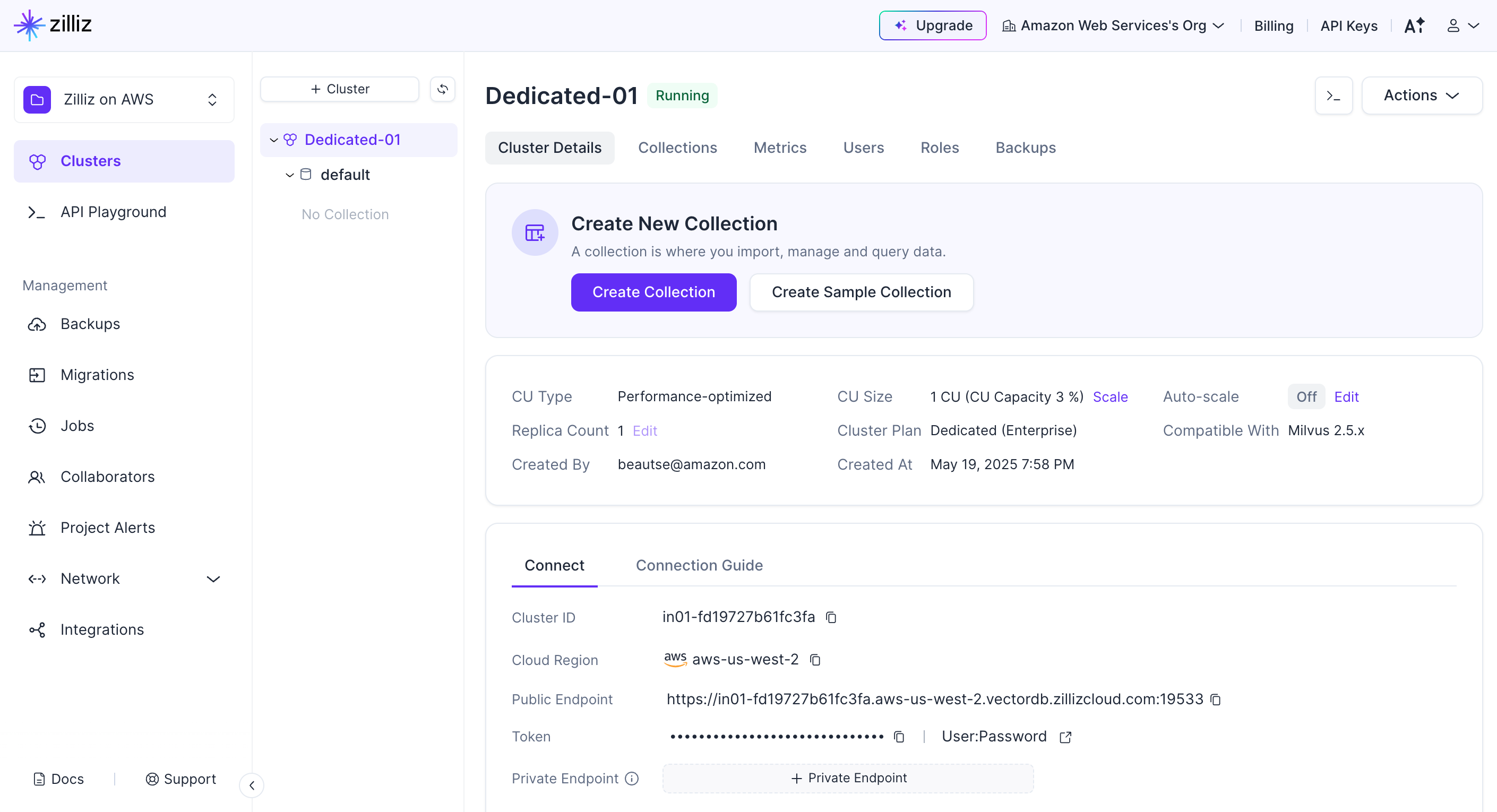
Your cluster will begin creating and initialize a public endpoint. To set up a private endpoint, follow these instructions on setting up an AWS PrivateLink. Using AWS PrivateLink enables improved security and optimized performance to reach the managed Zilliz Cloud cluster.
Navigate to Amazon Sagemaker AI and create a notebook instance.
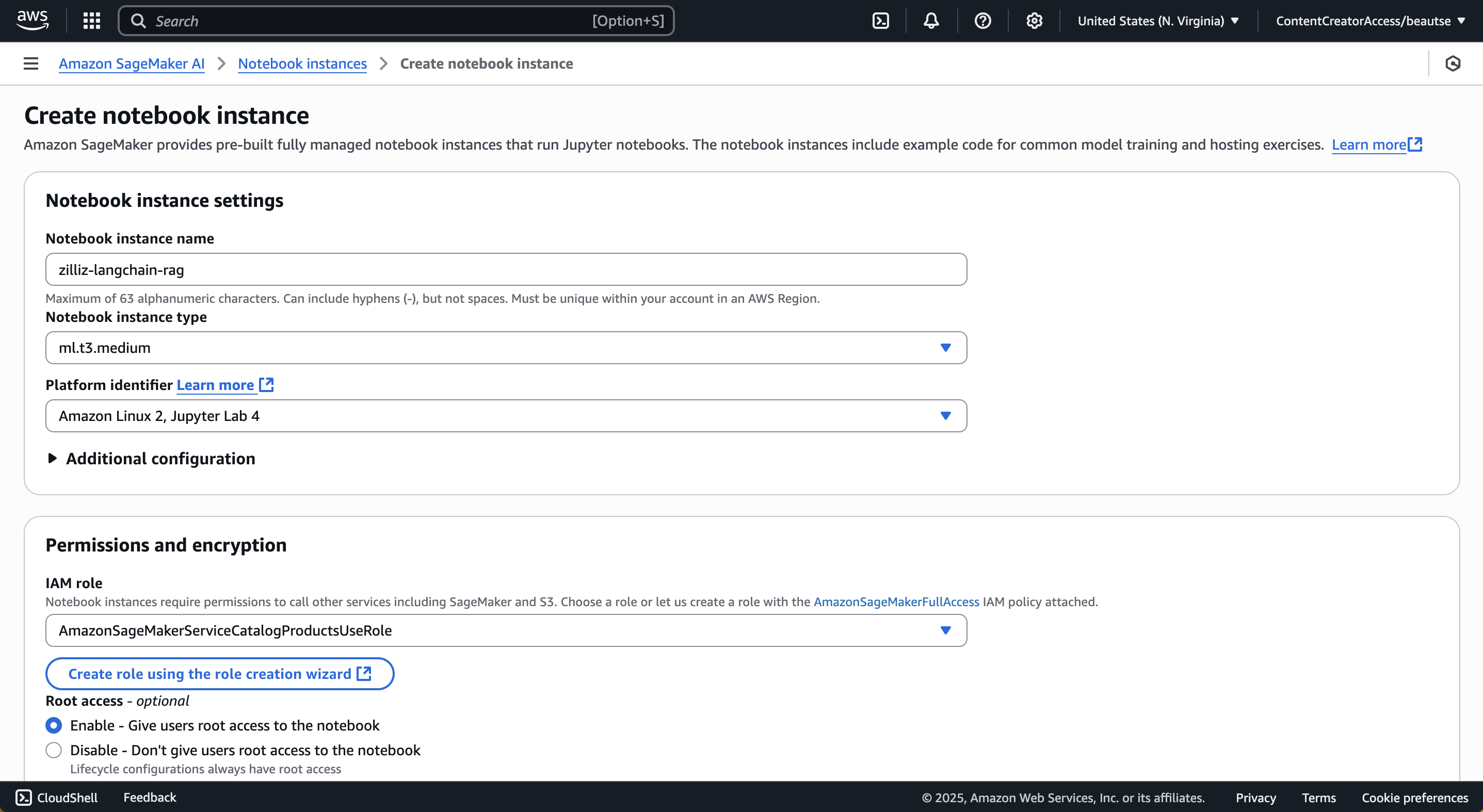
Now that we have set up the infrastructure for to create our RAG application using Zilliz, LangChain and Amazon Bedrock, we want to install and import the necessary packages in our jupyter notebook.
!pip install —upgrade —quiet langchain langchain-core langchain-text-splitters langchain-community langchain-aws bs4 boto3 awscli
import bs4
import boto3
import os
from langchain_aws import ChatBedrock, BedrockEmbeddings
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.prompts import PromptTemplate
from langchain_community.vectorstores import Zilliz
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
Next, we will configure the connection to Amazon Bedrock and Zilliz Cloud by setting the necessary environment variables.
ZILLIZ_CLOUD_URI = "ZILLIZ_CLOUD_URI"
ZILLIZ_CLOUD_API_KEY = "ZILLIZ_CLOUD_API_KEY"
Then create a boto3 client to connect to the Amazon Bedrock Runtime service and initialize instances for language model operations and text embeddings.
# Create a boto3 client with the specified credentials
client = boto3.client(
"bedrock-runtime",
region_name='us-east-1'
)
# Initialize the ChatBedrock instance for language model operations
llm = ChatBedrock(
client=client,
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
region_name='us-east-1',
model_kwargs={"temperature": 0.1},
)
# Initialize the BedrockEmbeddings instance for handling text embeddings
embeddings = BedrockEmbeddings(client=client, region_name='us-east-1')
Now that we have the Amazon Bedrock Runtime and embeddings enabled, we want to collect the information that the AI system will use to generate its responses (passed in as context). We can use the WebBaseLoader from LangChain to retrieve data from various sources, such as web pages, databases, or other external repositories. Once the data is collected, you'll want to split the documents into smaller chunks using a text splitter like the RecursiveCharacterTextSplitter from LangChain.
Then, you need to provide a clear structure or template of what the responses should look like for your language model. The PromptTemplate in LangChain allows you to define this template, specifying things like the tone, style, and overall format of the responses, as well as any specific information or formatting that should be included.
Next, we Initialize a Zilliz vector store from the loaded documents and embeddings and create a retriever for document retrieval and generation.
# Initialize Zilliz vector store from the loaded documents and embeddings
vectorstore = Zilliz.from_documents(
documents=docs,
embedding=embeddings,
connection_args={
"uri": ZILLIZ_CLOUD_URI,
"token": ZILLIZ_CLOUD_API_KEY,
"secure": True,
},
auto_id=True,
drop_old=True,
)
# Create a retriever for document retrieval and generation
retriever = vectorstore.as_retriever()
# Define a function to format the retrieved documents
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
Lastly, we will define a retrieval-augmented generation (RAG) chain to retrieve relevant documents, process them, and generate coherent responses using the language model.
# Define the RAG (Retrieval-Augmented Generation) chain for AI response generation
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# Invoke the RAG chain with a specific question and retrieve the response
res = rag_chain.invoke("What is Shaq's opinion of his kids playing professional basketball?")
print(res)
A sample output from this application and the article passed in will look like this:
According to the context provided, Shaquille O'Neal discourages his children from pursuing professional basketball careers. He explicitly states, "We don't need another basketball player. At all." Instead, O'Neal encourages his seven children to pursue other careers, such as law, medicine, engineering, or AI invention. He emphasizes education, jokingly saying that to "touch daddy's cheese," his kids need to show him "two or three degrees." O'Neal's stance appears to be influenced by his own experience, where he missed many important family moments due to his basketball career, including birthdays, school plays, and holidays.
Key takeaways
Traditional databases struggle to handle unstructured data and vector embeddings needed for modern AI applications, creating a significant challenge for enterprises. Zilliz Cloud, built on the open-source Milvus database, offers a comprehensive solution by providing efficient vector storage and similarity search capabilities, enabling organizations to manage high-dimensional data effectively while maintaining performance at scale. The integration of Zilliz Cloud with Amazon Bedrock and LangChain creates a powerful ecosystem for building RAG applications, allowing organizations to enhance their LLM capabilities with up-to-date information, making it particularly valuable for enterprise environments requiring accurate and reliable AI-powered solutions.
Why AWS Marketplace for on-demand cloud tools
Free to try. Deploy in minutes. Pay only for what you use.
Featured tools are designed to plug in to your AWS workflows and integrate with your favorite AWS services.
Subscribe through your AWS account with no upfront commitments, contracts, or approvals.
Try before you commit. Most tools include free trials or developer-tier pricing to support fast prototyping.
Only pay for what you use. Costs are consolidated with AWS billing for simplified payments, cost monitoring, and governance.
A broad selection of tools across observability, security, AI, data, and more can enhance how you build with AWS.