
Sold by: Elastic
Deployed on AWS
Free Trial
Vendor Insights
Address your search, observability, and security challenges with Elastic's leading vector database, built for generative AI, semantic search, and hundreds of open, pre-built integrations. Start a 7-day free trial and harness the power of your data, securely and at scale.
4.3
Overview
Video
Video 1

Video
Product video
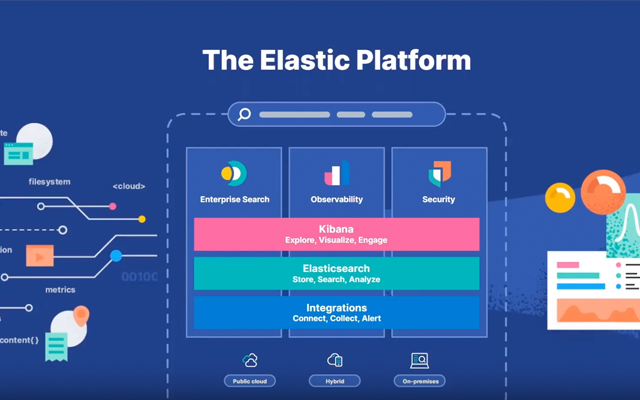
The Elasticsearch Platform combines world-class search with agentic AI to address your search, observability, and security challenges.
Elasticsearch's vector database enables developers to deliver high precision semantic search and scalable AI experiences faster at lower costs. Elastic ensures peak performance even as customers scale across thousands of customers and petabytes of data, while consumption-based pricing and resource optimization tools help keep overall costs low.
Elasticsearch is the most complete data platform for context engineering and AI - the most deeply integrated open stack combining a scalable distributed data store, vector database, hybrid search, Jina AI models, and an agent builder. It simplifies building best-in-class search, AI, and agentic applications that deliver trusted answers at scale, regardless of where data resides. Built for production, Elasticsearch scales predictably with near real-time performance and cost efficiency on-prem or in the cloud, powering even the most demanding workloads.
Elastic Observability - SRE teams shouldn't have to choose between metrics coverage and cost control. Elasticsearch, the best-in-class for logs, is now best-in-class for metrics, too - with a single backend and a single query language. Native Prometheus and PromQL support means existing queries, dashboards, and alert rules work without modification. Elastic delivers more metrics, longer retention, lower cost - no retraining budget, no surprise bill at the end of the month.
Elastic is the agentic security operations platform built to secure, not to tax. A platform where autonomous agents handle the full lifecycle from ingestion through response, and your analysts handle judgment, verification and approval. When your adversary moves at machine speed, every vendor-imposed barrier is a gap the adversary exploits. Elastic removes them all. No taxes on your time, wallet, trust, or attention.
Take advantage of Elastic Cloud Serverless - the fastest way to start and scale security, observability, and search solutions without managing infrastructure. Built on the industry-first Search AI Lake architecture, it combines vast storage, compute, low-latency querying, and advanced AI capabilities to deliver uncompromising speed and scale. Users can choose from Elastic Cloud Hosted and Elastic Cloud Serverless during deployment. Try the new Serverless calculator for price estimates.
Ready to see for yourself? Sign into your AWS account, click on the "View Purchase Options" button at the top of this page, and start using a single deployment and three projects of Elastic Cloud for the first 7 days, free!
Highlights
- Search: Build innovative agentic AI, GenAI, and semantic search experiences with Elasticsearch, the leading vector database.
- Security: Modernize SecOps (SIEM, endpoint security, cyber security) with AI-driven security analytics powered by the Elasticsearch Platform.
- Observability: Use open, extensible, full-stack observability with natively integrated OpenTelemetry for Application Performance Monitoring (APM) of logs, traces, and metrics.
Details
Sold by
Delivery method
Deployed on AWS
New
Introducing multi-product solutions
You can now purchase comprehensive solutions tailored to use cases and industries.

Features and programs
Skip the manual risk assessment. Get verified and regularly updated security info on this product with Vendor Insights.
Security credentials achieved
(2)

ISO27001

AWS Security Specialization
Buyer guide
Gain valuable insights from real users who purchased this product, powered by PeerSpot.

Financing for AWS Marketplace purchases
AWS Marketplace now accepts line of credit payments through the PNC Vendor Finance program. This program is available to select AWS customers in the US, excluding NV, NC, ND, TN, & VT.

AWS PrivateLink
Get next level security. Connect VPCs and AWS services without exposing data to the internet.
Pricing
Free trial
Try this product free according to the free trial terms set by the vendor.
Pricing is based on actual usage, with charges varying according to how much you consume. Subscriptions have no end date and may be canceled any time.
Additional AWS infrastructure costs may apply. Use the AWS Pricing Calculator to estimate your infrastructure costs.
Dimension | Cost/unit |
|---|---|
Elastic Consumption Unit | $0.001 |
Dimensions summary
Elastic Consumption Units (ECUs) represent Elastic's unified pricing metric across both their Cloud Hosted and Serverless offerings on AWS Marketplace. For Cloud Hosted solutions, ECUs measure infrastructure resource consumption, while for Serverless offerings, ECUs quantify usage based on service-specific dimensions such as data ingestion, search operations, and security events. This flexible pricing model ensures customers pay only for their actual usage, whether they're using Elasticsearch, Observability, Security, or other Elastic services.
Top-of-mind questions for buyers like you
What is an Elastic Consumption Unit (ECU) and how is it calculated?
An ECU is Elastic's standardized billing metric that measures usage across their services. For Cloud Hosted deployments, ECUs are calculated based on infrastructure resources consumed, while for Serverless offerings, ECUs are determined by service-specific usage metrics like data ingestion volume, search operations, or security events processed.
How can I estimate my monthly costs for Elastic Cloud on AWS Marketplace?
Elastic provides a pricing calculator on their website where you can estimate costs based on your expected usage patterns. You can also monitor your actual ECU consumption through Elastic Cloud console's usage monitoring features, and the billing interface shows detailed breakdowns of usage by service and deployment.
Does Elastic Cloud on AWS Marketplace require any upfront commitment?
Elastic Cloud on AWS Marketplace follows a pay-as-you-go model with no upfront commitments required. However, customers can opt for annual commitments to receive volume discounts, and usage is billed monthly through your AWS account based on actual consumption of ECUs.
Vendor refund policy
See EULA above.
Custom pricing options
Request a private offer to receive a custom quote.

Legal
Vendor terms and conditions
Upon subscribing to this product, you must acknowledge and agree to the terms and conditions outlined in the vendor's End User License Agreement (EULA) .
Content disclaimer
Vendors are responsible for their product descriptions and other product content. AWS does not warrant that vendors' product descriptions or other product content are accurate, complete, reliable, current, or error-free.
Delivery details
Software as a Service (SaaS)
SaaS delivers cloud-based software applications directly to customers over the internet. You can access these applications through a subscription model. You will pay recurring monthly usage fees through your AWS bill, while AWS handles deployment and infrastructure management, ensuring scalability, reliability, and seamless integration with other AWS services.
Resources
Vendor resources
Support
Vendor support
Visit Elastic Support (https://www.elastic.co/support ) for more information. If you are a customer, go to the Elastic Support Hub (http://support.elastic.co ) to raise a case.
AWS infrastructure support
AWS Support is a one-on-one, fast-response support channel that is staffed 24x7x365 with experienced and technical support engineers. The service helps customers of all sizes and technical abilities to successfully utilize the products and features provided by Amazon Web Services.
Updated weekly
By Elastic


By ChaosSearch, Inc.
Top
10
In Databases & Analytics Platforms
Top
10
In Generative AI, Log Analysis
Top
100
In Log Analysis, Analytic Platforms
Sentiment is AI generated from actual customer reviews on AWS and G2
Functionality
Ease of use
Customer service
Cost effectiveness
Positive reviews
Mixed reviews
Negative reviews
AI generated from product descriptions
Vector Database Capabilities
Enables semantic search and AI experiences with vector database functionality optimized for generative AI applications and high-precision retrieval at scale.
Hybrid Search Architecture
Combines vector search with traditional search capabilities and integrates Jina AI models for comprehensive search and AI application development.
Observability Platform
Provides unified backend for logs, metrics, and traces with native Prometheus and PromQL support, allowing existing queries and dashboards to function without modification.
Distributed Data Store
Scalable distributed architecture supporting petabyte-scale data processing with near real-time performance and predictable scaling across on-premises and cloud deployments.
Security Operations Automation
Autonomous agent-based platform handling full lifecycle from data ingestion through response for SIEM, endpoint security, and cyber security analytics.
AI-Powered Root Cause Analysis
Automatically investigates alerts and pinpoints root causes with 5x faster analysis capabilities.
Natural Language Query Interface
Enables querying of observability data using conversational natural language to identify issues and receive actionable insights.
Real-Time Anomaly Detection
Detects system anomalies in real-time to prevent incidents before they impact users.
OpenTelemetry Integration
Supports standardized OpenTelemetry integration for unified data collection across logs, metrics, and traces in cloud-native environments including Kubernetes, serverless, and microservices.
Multi-Tiered Storage Architecture
Implements multi-tiered storage and data management capabilities to optimize telemetry costs and achieve 30% to 50% cost savings.
Direct S3 Data Indexing
Indexes Amazon S3 data without transformation or schema changes, enabling immediate access to all data as-is
SQL and Search Query Support
Enables SQL queries and search workloads on indexed S3 data through open APIs compatible with analytics tools
Machine Learning Workload Capability
Supports machine learning workloads on indexed data stored in Amazon S3 with infinite scalability
Unlimited Data Retention
Provides unlimited retention of indexed data, enabling historical analysis across any time horizon without data purging or archival requirements
Fully Managed Service Architecture
Operates as a fully managed service eliminating administrative overhead including re-indexing, sharding, load balancing, and compute/storage management
Validated by AWS Marketplace
FedRAMP
GDPR
HIPAA
ISO/IEC 27001
PCI DSS
SOC 2 Type 2
-
-
-
-
-
-
-
No security profile
Standard contract
No
No
No
Customer reviews
AkashKumar3
Centralized monitoring has improved our cloud traffic management but log accuracy still needs work
Reviewed on Jul 14, 2026
Review provided by PeerSpot
What is our primary use case?
I am the Elastic Search admin for my organization, and we are using Elastic Search to handle the traffic to GCP . The monitoring of all the clusters and all the deployments are quite good, and compared to other services such as OpenSearch that we used previously, Elastic Search is much better, and Kibana is also invaluable.
When we get the logs, it is mostly about how we edit the configurations and how we make changes according to the requirements of our organization. In these cases, the logs sometimes can be a bit inaccurate. We are a customer, and we use Elastic Search integrated into our organization's usage.
What is most valuable?
Elastic Search is much better, and Kibana is also invaluable. It is scalable, and from my usage, we had many cases where we had to scale it according to the client requirements or the project requirements, and that was very easy because they provide a feature of increasing our usage or the configurations very easily.
During the first year or year and a half that I was working, it required maintenance. However, with the upcoming migrations and Elastic Search version upgrades, we started automating the alerts and the auto-migrations. The auto-scalability feature of Elastic Search is quite good as well.
What needs improvement?
When we get the logs, it is mostly about how we edit the configurations and how we make changes according to the requirements of our organization. In these cases, the logs sometimes can be a bit inaccurate.
We do not have much use for hybrid search in my use case. We did have a session where we tried it out for projects that are possibly a part of our organization, but we do not use that feature much.
For how long have I used the solution?
I have been using Elastic Search for the past three years.
What do I think about the stability of the solution?
I have not experienced significant stability issues, and from my usage so far, there were no issues that I faced.
What do I think about the scalability of the solution?
It is scalable, and from my usage, we had many cases where we had to scale it according to the client requirements or the project requirements, and that was very easy because they provide a feature of increasing our usage or the configurations very easily.
How are customer service and support?
We are in constant contact with technical support because we have a large amount of projects in our wing. Mostly, in order to check what the backend situations are, we contact technical support, which is quite easy to reach. Once there is any case that requires a one-on-one interaction, it is easy to contact them and we have a session to resolve the issue. The technical support is great.
Which solution did I use previously and why did I switch?
We did try out OpenSearch , but I do not think that will count as much as how much I have used Elastic Search.
How was the initial setup?
The initial deployment was fine because the organization already had Elastic Search, and I was not the one who implemented it. I found it easy to get used to the whole usage, so it was fine for me. To fully understand the whole knowledge of all the deployments, it took me about six months, which was a fine timeline according to the requirements of my employer.
What's my experience with pricing, setup cost, and licensing?
The pricing for Elastic Search is mainly budgeted according to the organization budget, so we take it as a yearly subscription, and that is acceptable since we do get a fair discount when we are taking it in bulk.
What other advice do I have?
Elastic Search overall is good. Regarding relevancy and searching, the searching is fine because in my use case, we only use it to retrieve the data, and the text search is quite good. We do not find any issue with that. In Elastic Cloud, which comes with the premium enterprise version of Elastic Search, we just got that this year. We received it in January, and they have inbuilt tools for GenAI. They also have a RAG feature where we can get LLMs to find answers or generate data, and that was quite good. I would give Elastic Search a rating of seven overall.
Neel Choudhury
Search performance has transformed log analysis and complex data lookups in daily workflows
Reviewed on Jun 12, 2026
Review from a verified AWS customer
What is our primary use case?
I am familiar with Elastic Search to a certain extent as I have used it in my development life. I thought someone wanted feedback about it, specifically how I have used it in my career, so I agreed to share that information.
I started using Elastic Search after becoming acquainted with it when I accessed the AWS environment for the first time during the COVID period. We tried to establish a vertex and edge graph database schema, and I was hired to get that schema up and running while dealing with millions of records related to car spare parts. Due to a signed clause, I cannot go into too much detail. The challenge was with the indexes slowing down, which prompted a move to GraphDB because it provides faster access time. I had to deal with a lot of data cleansing and created many pipelines, first pushing records into Elastic Search through a bulk insert. I also looked up data using Kibana as the front end to leverage queries for pulling up that data.
Once GraphDB was in place, I was required to develop a service for asynchronous processing and order confirmation, where one copy would be stored in a database and the other would be pushed into Elastic Search for further lookup, eliminating the need for direct queries to the RDS
I have never reached out to Elastic Search's technical support team.
What is most valuable?
Elastic Search, being a vector database, quickly indexes data, allowing for searches based on text and data directly, which I found fascinating. My dev lead mentioned that it uses C++ to pick up these indexes and pulls up records incredibly fast, in nanoseconds, keeping me interested in how things are becoming faster over time and diversifying away from traditional relational database systems.
Regarding scalability, I consider both vertical and horizontal scalability in theory. I have not experienced sharding but find it interesting as a use case with Elastic Search. I see significant potential for vertical scalability, which can accommodate more data and offer substantial improvement.
What needs improvement?
Your question about what I dislike about Elastic Search is quite pointed, and I prefer to look at it as something for improvement, such as provisioning options other than Kibana. A standalone install that is operating system agnostic could run on Mac, Linux, or Windows by just providing a URL, username, and password to access the schema for queries. This would benefit many people who may not have access to Kibana, especially those who, the workplace evolution has shown, may not know what Kibana is if they lack tool access. It is crucial to have executable information to understand a product deeply. If Kibana is not a viable option for everyone due to hosting constraints, a standalone installer could connect directly to Elastic Search, with documentation readily available online to guide those needing desktop access.
For how long have I used the solution?
I have been using this solution for two years overall and have had good exposure to it with all CRUD operations I have been performing with it.
What do I think about the stability of the solution?
I have used Elastic Search for log lookups with ELK and never encountered any crashes or downtime while it was hosted in the cloud. While occasionally one or two queries may take longer due to network lags, these issues are more infrastructure-related since I have never faced any problems with Elastic Search's stability, which generally retrieves information instantly.
What do I think about the scalability of the solution?
Regarding scalability, I consider both vertical and horizontal scalability in theory. I have not experienced sharding but find it interesting as a use case with Elastic Search. I see significant potential for vertical scalability, which can accommodate more data and offer substantial improvement.
How was the initial setup?
When discussing initial deployment, the specific attribute of interest is the overall initial installation when starting to roll out the product. The deployment was a struggle as I faced challenges with bash commands and understanding how to run things on my system. Looking up tutorials on YouTube was tricky, and cross-referencing with documentation posed difficulties as some people customize setups to their needs. Setting up MySQL is straightforward, while with Elastic Search, I had to run bash commands for proper service execution. I faced some hurdles getting CRUD queries to work correctly. I resorted to Docker as an alternative, which diverged from standard practices of creating a local database service. An ideal setup would include a setup executable for Windows that would greatly facilitate immediate access and CRUD operation starts.
In my case, the system was already running by the time I started, as the custom DevOps team managed the deployment, and I was only tasked with connecting via Kibana and issuing bulk insert commands.
What's my experience with pricing, setup cost, and licensing?
I have not checked Elastic Search's pricing thoroughly, so I do not know how a company would perceive it. From what I see, small companies might consider the cost, with starting pricing for a single node instance at $16 a month for serverless and hosted options, though at least one or two connected clusters would be necessary for viable solutions. Companies might see this lower end pricing as suitable, but for startups, reaching up to $2,000 could appear steep, depending on their aggressive usage approach.
I faced a situation where our graph database work halted due to technical difficulties with the Neptune product, as some CRUD operations were not carried out. Product specialists suggested that the business case did not fit the graph database's requirements and recommended Elastic Search instead for a better use case. I was involved in a data structure related to car spare parts needing to facilitate purchases by linking parts to various car makes across catalogs, ultimately attempting to shift from relational databases due to overwhelming data generation that slowed down indexed lookups. Elastic Search significantly helped in confirming order data lookup, but costs for clusters in further development led to work being stalled.
A preliminary architect consultation or proof of concept on cluster purposes would aid in establishing understanding for further development on Elastic Search, which is becoming increasingly costly in the cloud due to demand. A structured understanding of costs tied to usage metrics would greatly assist in planning before commitments, as delays in our POC adversely affected our progress. Documentation should also encompass potential use cases and scenarios to better assist developers during implementations across programming languages to ensure seamless integration.
Which other solutions did I evaluate?
Regarding alternatives, I have worked with various database products, including Azure technologies where I worked with NoSQL storage tables similar to AWS DynamoDB, which are schema-less with varying attributes per record. These use partition key and row key for accessing information, fragmenting what we associate with traditional RDS . Additionally, I worked with Axelor CRM from a French company, alongside MySQL and Oracle. My first company used MS SQL , and I have discussed my use case involving AWS Neptune graph database and Elastic Search, which encompasses all I have worked with so far.
What other advice do I have?
For an overall rating of Elastic Search, I would score it at a solid 8 out of 10.
Its speed has facilitated my understanding of logical operators and streamlined query issuance. I would love to grasp the inner workings of sharding with distributed schema implications. Based on what I have experienced thus far, I find it a significant improvement, but once I better understand sharding and its performance effects, I would likely adjust my score.
My experience with the relevancy of search results using Elastic Search indicates that issuing a full query yields a finite number of results, while partial text searches can return irrelevant information. Mastering query issuance with Elastic Search is a valuable skill that develops over time. I prefer a structured JSON approach, utilizing properly sequenced clauses, which allow drilling down to a limited set of records that directly relate to the search context.
On hybrid search effectiveness, I think that AI is progressively offering more concise information. Providing more relevant keywords allows Elastic Search to generate results faster than other databases, such as RDS. The ability to engage with text directly simplifies understanding records and has a significant impact on AI functionality in rendering accurate results based on user needs.
Which deployment model are you using for this solution?
Public Cloud
If public cloud, private cloud, or hybrid cloud, which cloud provider do you use?
Amazon Web Services (AWS)
Shubham Yash Tomar
Search across multilingual user data has become smarter and handles fuzzy name matches well
Reviewed on Jun 05, 2026
Review from a verified AWS customer
What is our primary use case?
The major purpose was to solve the search part. We have data in multiple languages, majorly in Indian languages such as English, Hindi, Punjabi, and some Marathi and Bengali. There is a requirement where we need to support a kind of listing, and I can say there is a list of people or users to whom I want to search.
What is most valuable?
What I like the most about Elastic Search is that I can store my data and search throughout my document. It is not like I am doing a search on a particular field only. For example, in comparison with other databases like SQL or NoSQL, you can implement search, but you need to be restricted to a particular field. In Elastic Search , there is an opportunity to search the entire document, and if there are any matches, it gives a score based on which I can decide how much data I need to show.
For example, if I am searching a person's name, there is a chance that the person's name I will be looking for may have some partial match. If I search for Amit, there can be multiple spellings for the same thing. It works on a kind of phonics system, which is a major requirement for me because when people type, they usually make spelling mistakes.
What needs improvement?
Regarding what I dislike about Elastic Search, there is one issue that occurs because Elastic Search is not my primary database; it serves as a substitute database for the searching part. I need to sync my data, and if I am not using the enterprise edition or version, sometimes my entire servers get crashed or backups crash. If I need to recreate that same thing again, it will take a lot of time, as the restore and sync process is very slow.
For how long have I used the solution?
I have been using Elastic Search for the last three to four years.
What do I think about the stability of the solution?
Regarding stability, if I am deploying myself, I feel many issues during deployment due to maintenance that I have to take care of. Sometimes the CPU or memory spikes depending on the load. However, I have noticed that an enterprise solution seems to be carefully handled by Elastic Search itself.
What do I think about the scalability of the solution?
I have almost handled ten to twenty million data entries, and we have gotten results from that. I think I have seen that level of scalability in Elastic Search.
How are customer service and support?
I have contacted technical support or customer support several times, but not me personally; my DevOps team has connected with the technical support several times. They deal with the contact support because they handle all the infrastructure setup and issues related to DevOps.
Which solution did I use previously and why did I switch?
I have used other similar solutions to Elastic Search. I think Elastic Search was compared to lexical search or something similar. There is another solution provided by MongoDB which also does similar work; with them, we can restore the JSON format data quickly compared to Elastic Search. MongoDB provides a tool called Compass, and they have Atlas. In Atlas, they are offering a lot of solutions with many features that were missing in Elastic Search. While the searching part in Elastic Search works fine, it lacks a lot of things; for instance, if I need to scale or downgrade my system, the backup restoration works much faster.
How was the initial setup?
The initial deployment was something I was not part of for Elastic Search, and even for Mongo not much. However, I have some idea about it; you can create multiple shards and similar configurations. It is easy in both cases.
What other advice do I have?
A lot of maintenance is required on my end. A lot of data needs to be synced because we were using CDC, so a lot of data is transmitted from my primary database to this secondary database for searching purposes. That requires a lot of effort. However, using the cloud solution, I think it can be set up; but again, it costs me a lot.
My experience with the relevancy of the search results when using traditional keyword and full-text search capabilities shows that as we are moving towards AI, you can keep all your data and break it into an AI format. Whatever I want to search, it will give me a result. I think moving forward, plain text search will not be a long-term solution because as people are moving towards AI, they want machines to understand better what they are trying to search. For example, I may want to search for a person based on department and years of experience, and for that, I think Elastic Search will suffice. However, breaking data into tokens and embedding it for querying will be a better solution moving forward. Elastic Search is also providing some sort of AI solution, but I have not had much time to explore that yet.
I believe the effectiveness of hybrid search, which combines vector and text searches, is great because vector search deducts information from the text provided to a machine and effectively gives the related data. If I use vector search with plain text in a hybrid search, it will be a better solution moving forward. This is because people do not want to search for something such as Atul Kumar; they want to search for Atul Kumar from a specific department or company, region, or city. My overall rating for this product is eight point five out of ten.
Anderson Gil
Advanced search weighting has transformed research queries and supports fast, insightful discovery
Reviewed on May 22, 2026
Review from a verified AWS customer
What is our primary use case?
We use Elastic Search for a research application based on paper study, and the primary usage is for indexing the data and then functioning in a similar way to an e-commerce search bar.
What is most valuable?
For us, what I can notice is the ability of adding weights to each field of the data, which is very useful because sometimes the user searches the data not just by the title, but by specific keywords, and being able to add weight to the fields in order to show that information to the final user is very useful. Also, the panel for showing graphs about the data and how the users are interacting with it is pretty useful.
The difference in performance of Elastic Search is outstanding; if we compare a traditional database or service for search and index products or, in this case, papers, the difference is outstanding. That is the case when you want to filter the data; the primary advantage will be performance for sure.
Again, the primary improvement will be performance, and the interactivity we can have with the data is very flexible; it adapts to the needs of the user very easily.
I cannot see any issues at this point; the panel is great. The way to customize and configure the panel and the search is great; it is really visual. Documentation is great as well.
What needs improvement?
The initial configuration could be easier; at first, the learning curve is a little high, and over time, it becomes easier. For me, the initial configuration might be improved.
For how long have I used the solution?
I have around three years of experience.
What do I think about the stability of the solution?
Stability has not been an issue; it is working perfectly in that aspect.
What do I think about the scalability of the solution?
Scalability has not been an issue for now.
How are customer service and support?
In the case scenario when we need to face support, support was really useful, and they answered the questions in a good period of time.
Which solution did I use previously and why did I switch?
Cassandra was one we were evaluating, but we preferred Elastic Search because the documentation was way better and the community was bigger. It is easier to find answers when we face a problem, and that is why we chose Elastic Search.
How was the initial setup?
At first, we faced several issues related to some versioning and allowing indexing the database because part of our information is in a traditional SQL database, and we were using the IDs from the index for the records in Elastic Search. We created a little ETL for that, and handling that process was tricky and harder at first. That was the biggest challenge we faced when starting to set up Elastic Search.
I would say that first, contact support for the initial setup; I think it will make the process easier. Then start, for example, with how to send and retrieve the data in the documentation; I think that is the best thing they can do.
What about the implementation team?
For that one, my field, the PO and the technical leader is the one that handles the bills about Elastic Search.
I am on the side of implementing it, so in terms of cost-efficient or the price of using it in the cloud, that is not something I am really involved with; I am more on the dev-ops side.
What was our ROI?
It was great; the developer experience is great when integrating either the frontend or the backend side. Nothing so complex could not come.
What other advice do I have?
For implementing Elastic Search, I would say good documentation, and it is really easy to use. We have an example of almost every functionality that is inside of Elastic Search framework, so that is helpful. I would provide a rating of ten for this product, and I say a ten; it is really good.
Which deployment model are you using for this solution?
Public Cloud
If public cloud, private cloud, or hybrid cloud, which cloud provider do you use?
Antonia F.
Simple UI, Seamless Integrations, and Strong Elasticsearch Performance
Reviewed on May 19, 2026
Review provided by G2
What do you like best about the product?
I like the UI and UX, its design look simple so the new person also can operate the Elasticsearch. The integration feature built in is compatible with many products. I am using at least 4 years and I think the performance is more better than any product for data analysis.
What do you dislike about the product?
In my usage in elasticsearch, I don't have any issue about that
What problems is the product solving and how is that benefiting you?
With Elasticsearch, now we can centralize all the logs in one place and the search speed is insane even when we querying billion of documents, it still fast. We use it together with Kibana for visualization, so when there's anomaly or error spike, our team can detected it much more quicker than before.
Also the scalability is good. We can add node without much downtime, and the cluster manage the shard distribution by itself. For our usecase in log monitoring, this is very helping because log volume keep growing every month.
Also the scalability is good. We can add node without much downtime, and the cluster manage the shard distribution by itself. For our usecase in log monitoring, this is very helping because log volume keep growing every month.