O blog da AWS
Migração do Azure Blob Storage para o Amazon S3 usando o AWS DataSync
Conversamos com os clientes todos os dias sobre seus requisitos de migração de dados, que abrangem desde transferências de dados entre serviços da AWS, movimentação de dados on premises para a AWS, até migrações de dados entre outros provedores públicos e meios de armazenamento. O único ponto em comum a essas solicitações é o desejo de ter um método nativo da AWS, simples e econômico para realizar essas transferências de dados. Os clientes não querem escrever e manter seus próprios scripts, ferramentas de agendamento e soluções de monitoramento para simplesmente mover dados de um local para outro.
Visando endereçar esta demanda, a AWS possui serviços como a família AWS Snow, a família AWS Transfer e o AWS DataSync. Estamos trabalhando constantemente para oferecer recursos novos e aprimorados aos nossos clientes, incluindo um anúncio de 2022 – suporte ao AWS DataSync para mover dados entre a AWS e outros locais públicos. Isso inclui suporte para compartilhamentos SMB do Azure Files. O AWS DataSync acaba de lançar uma prévia do suporte ao Azure Blob Storage, permitindo que mais clientes, de maneira simples, migrem seus dados para os serviços de armazenamento da AWS, incluindo o Amazon Simple Storage Service (Amazon S3), o Amazon Elastic File System (Amazon EFS) e o Amazon FSx.
Neste blog, abordamos o uso do AWS DataSync para migrar objetos do Azure Blob Storage para o Amazon S3. Atualmente, não há nenhum DataSync agent nativo disponível para o Azure. Mostramos como você pode aproveitar o Hyper-V DataSync agent existente para acelerar a transferência de seus dados do Azure Blob para o Amazon S3. O DataSync agent também pode ser implantado no EC2, mas ao implantá-lo próximo ao local de armazenamento de origem, você pode aproveitar as otimizações de rede, como a compressão in-line para reduzir as taxas de saída de dados do Azure ao transferir dados para o Amazon S3.
O AWS DataSync suporta a cópia de dados do Azure Blob Storage
O AWS DataSync é um serviço de transferência de dados on-line totalmente gerenciado que facilita a automatização da transferência de dados em grande escala. Com o AWS DataSync, você pode implantar seu agent e, com alguns cliques ou utilizando a linha de comando, você terá uma tarefa de transferência de dados segura e confiável em execução sem a necessidade de implantar seus próprios utilitários de software ou gerenciar scripts programados personalizados.
Quando você seleciona containers do Azure Blob Storage como seu local de origem, o AWS DataSync transfere objetos do Azure Blob Storage de até 5 TB de tamanho com metadados de objetos que não excedam 2 KB. Os metadados do Azure Blob Storage são informações adicionais, como propriedades do sistema e name-value pairs adicionais que você pode definir, como nome do autor, tipo de documento, classe do documento, etc.
O Armazenamento do Azure fornece três tiers de acesso, incluindo: Hot tier, Cool tier e Archive tier. Os níveis Hot and Cool são considerados níveis de acesso on-line, o que significa que os clientes podem acessar os dados imediatamente quando solicitados. O Archive tier é destinado a dados que raramente são acessados. Se você tiver dados arquivados que precisam ser transferidos para o armazenamento da AWS, precisará reidratar os objetos do Archive tier para um tier de acesso on-line antes que esses objetos possam ser transferidos para o armazenamento da AWS. O DataSync simplesmente ignorará os objetos do Azure Blob Storage que estão armazenados no Archive tier ao invés de gerar uma mensagem de erro.
Visão geral da solução e terminologia do AWS DataSync
O DataSync tem quatro componentes para movimentação de dados: task, location, agent e task execution. A Figura 1 mostra a relação entre os componentes e as configurações que usaremos para o tutorial.

Figura 1: Componentes primários do AWS DataSync
- Agent: uma máquina virtual (VM) que lê ou grava dados para um determinado local. Neste tutorial, implantamos o DataSync agent como uma VM do Azure em uma rede virtual do Azure.
- Location: o local de origem e destino da migração de dados. Neste tutorial, o local de origem é um container do Azure Blob Storage. O local de destino é um bucket Amazon S3.
- Task: Uma tarefa compreende um local de origem e um local de destino com uma configuração que define como os dados são transferidos. Uma tarefa sempre sincroniza dados da origem para o destino. As configurações incluem opções como incluir/excluir padrões, agendamento de tarefas, limites de largura de banda e muito mais.
- Task Execution: é uma execução individual de uma tarefa, que inclui informações como hora de início, hora de término, bytes gravados e status.
A imagem a seguir mostra como os dados são migrados do Azure Blob Storage para o Amazon S3 com o AWS DataSync.
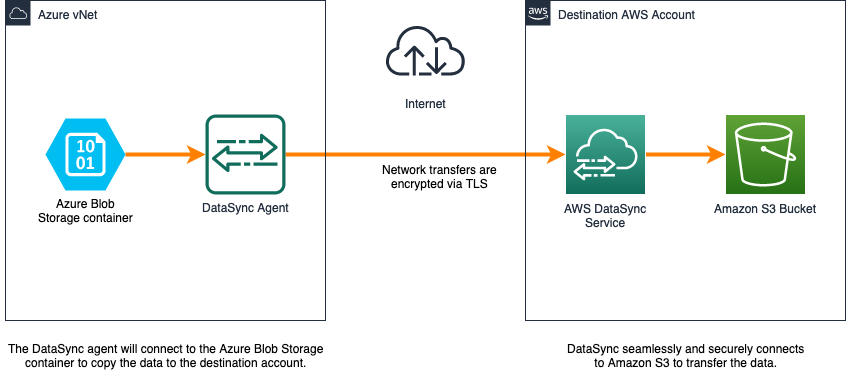
Figura 2: Arquitetura DataSync com container de armazenamento Azure Blob
Informações de dimensionamento do AWS DataSync agent
Ao implantar o AWS DataSync no Azure, selecione o tamanho da instância adequado ao número de arquivos a serem transferidos.
Recomendamos dedicar os seguintes recursos mínimos:
- Processadores virtuais — Quatro processadores virtuais atribuídos à VM.
- Espaço em disco — 80 GB de espaço em disco para instalação da imagem da VM e dos dados do sistema.
- RAM — Dependendo da configuração do seu armazenamento de dados:
- 32 GB de RAM atribuídos à VM, para tarefas que transferem até 20 milhões de arquivos.
- 64 GB de RAM atribuídos à VM, para tarefas que transferem mais de 20 milhões de arquivos.
Embora você possa implantar um DataSync agent em uma instância do Amazon EC2 para acessar seu armazenamento do Azure, talvez seja benéfico implantar o agent o mais próximo do sistema de armazenamento que o DataSync precisa acessar. A implantação do DataSync agent na mesma rede do sistema de armazenamento de origem diminuirá a latência da rede, aproveitará a compressão in-line dos dados fornecida pelo protocolo de transferência projetado pela AWS e eliminará a necessidade de ter um endpoint público para sua conta de armazenamento do Azure.
O Transport Layer Security (TLS) 1.2 criptografa todos os dados transferidos entre a origem e o destino. Além disso, os dados nunca são mantidos no próprio AWS DataSync. O serviço oferece suporte ao uso de criptografia padrão para buckets S3.
Pré-requisitos
Você precisará do seguinte para concluir as etapas desta postagem:
- Conta da AWS
- Assinatura de conta Azure
- Bucket Amazon S3
- Container do Azure Blob Storage
- PowerShell
- CLI do Azure
- AzCopy
- Os seguintes recursos do Windows precisarão estar habilitados em sua máquina local:
- Módulo Hyper-V para Windows PowerShell
- Serviços Hyper-V
Você pode encontrar detalhes sobre como configurar um container do Azure Blob Storage aqui. Um bucket S3 também precisará ser provisionado. Você pode encontrar detalhes sobre como criar esse recurso aqui. Chamamos o bucket do S3 de “datasynctest1234” e a conta de armazenamento do Azure de “awsblobdatasync”, que mencionaremos posteriormente neste blog.
Implantando o DataSync agent
Nesta seção, vamos nos concentrar nas etapas necessárias para implantar e configurar o DataSync agent.
Etapa 1: Preparar a imagem do DataSync agent para implantação
- Abra o console do AWS DataSync em https://console.aws.amazon.com/datasync/
- Na página Create Agent no console, selecione “Microsoft Hyper-V” no drop-down menu Hypervisor.
- Escolha “Download the image” na seção Deploy Agent. Isso baixa o agent em um arquivo.zip que contém um arquivo de imagem VHDX.
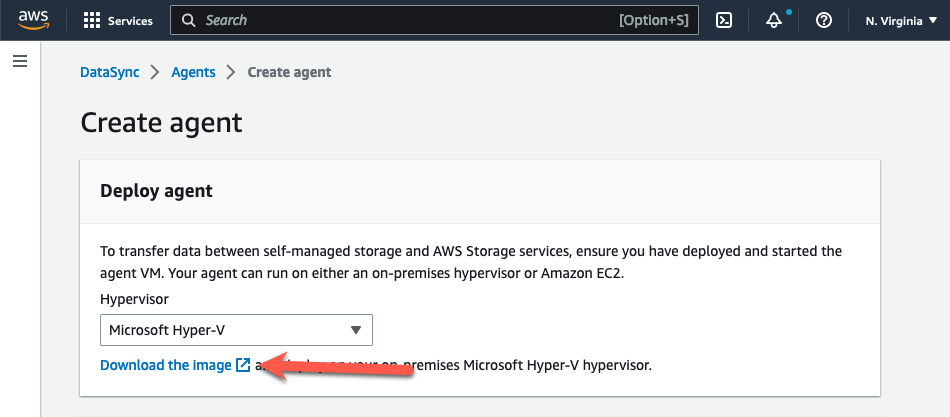
Figura 3: Faça o download do DataSync agent
- Extraia o arquivo de imagem VHDX para sua estação de trabalho.
- O arquivo VHDX precisará ser convertido em um arquivo VHD de tamanho fixo para compatibilidade com o Azure. Você pode encontrar mais informações sobre como preparar um VHDX para upload no Azure aqui. Execute o comando a seguir, atualizando o caminho e o nome do arquivo para corresponder à sua localização:
Convert-VHD -Path .\<path to vhdx>\aws-datasync-2.0.1678813931.1-x86_64.xfs.gpt.vhdx -DestinationPath .\<path to vhdx>\ aws-datasync-2016788139311-x86_64.vhd -VHDType Fixed
Etapa 2: Carregar o VHD em um disco gerenciado
- Determine o tamanho do VHD para que você possa criar um disco gerenciado vazio compatível. Use o comando “ls -l .” no diretório que contém a imagem do arquivo VHD. Isso fornecerá o número de bytes do arquivo VHD. Você precisará disso para o parâmetro –upload-size-bytes posteriormente.

Figura 4: Identifique o tamanho do byte do arquivo DataSync VHD
- Crie o disco gerenciado vazio executando o comando a seguir. Atualize os parâmetros com suas informações.
az disk create -n <yourdiskname> -g <yourresourcegroupname> -l <yourregion> --upload-type Upload --upload-size-bytes 85899346432--sku standard_lrs
- Gere uma assinatura de acesso compartilhado (SAS)
az disk grant-access -n <yourdiskname> -g <yourresourcegroupname> --access-level Write --duration-in-seconds 86400
- Carregue o DataSync VHD para o disco gerenciado vazio
AzCopy.exe copy "c:\somewhere\mydisk.vhd" "sas-URI"--blob-type PageBlob
- Quando o upload estiver concluído, revogue o SAS para preparar o disco para montagem na nova VM.
az disk revoke-access -n <yourdiskname> -g <yourresourcegroupname>
Etapa 3: Criar a VM do DataSync agent
- Crie a VM do DataSync usando o disco gerenciado que você criou.
az vm create --resource-group myResourceGroup --location eastus --name myNewVM --size Standard_E4as_v4 --os-type linux --attach-os-disk myManagedDisk
- Ativar o boot diagnostics
- Conecte-se via conexão serial e faça login no console local do seu agent
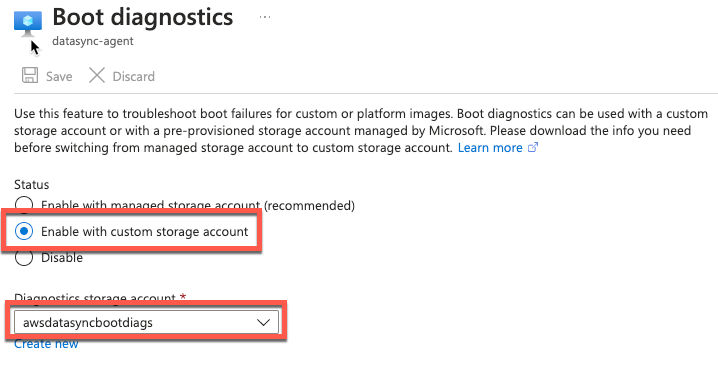
Figura 5: Habilitar o diagnóstico de inicialização
- No menu principal do AWS DataSync Activation — Configuration, digite 0 para obter uma chave de ativação.
- Insira a região da AWS na qual você ativará o agent.
- Insira o tipo de endpoint de serviço que seu agent usará. As opções incluem público, FIPS e VPC com o AWS PrivateLink. Usaremos a opção pública neste exemplo.
- A chave de ativação será gerada automaticamente e exibida na tela. Selecione e copie esse valor.
Etapa 4: ativar a VM do DataSync agent
- Abra o console do AWS DataSync em https://console.aws.amazon.com/datasync/
- Na página Create agent na console, selecione “Microsoft Hyper-V” no menu drop-down Hypervisor.
- Na seção Service Endpoint, selecione a opção Public service endpoints na região em que você ativará seu agent.
- Em Key activation, selecione Manually enter your agent’s activation key e cole o valor que você copiou da console local do agent.
- Forneça um nome exclusivo para o agent, se desejar, e clique no botão Create agent.
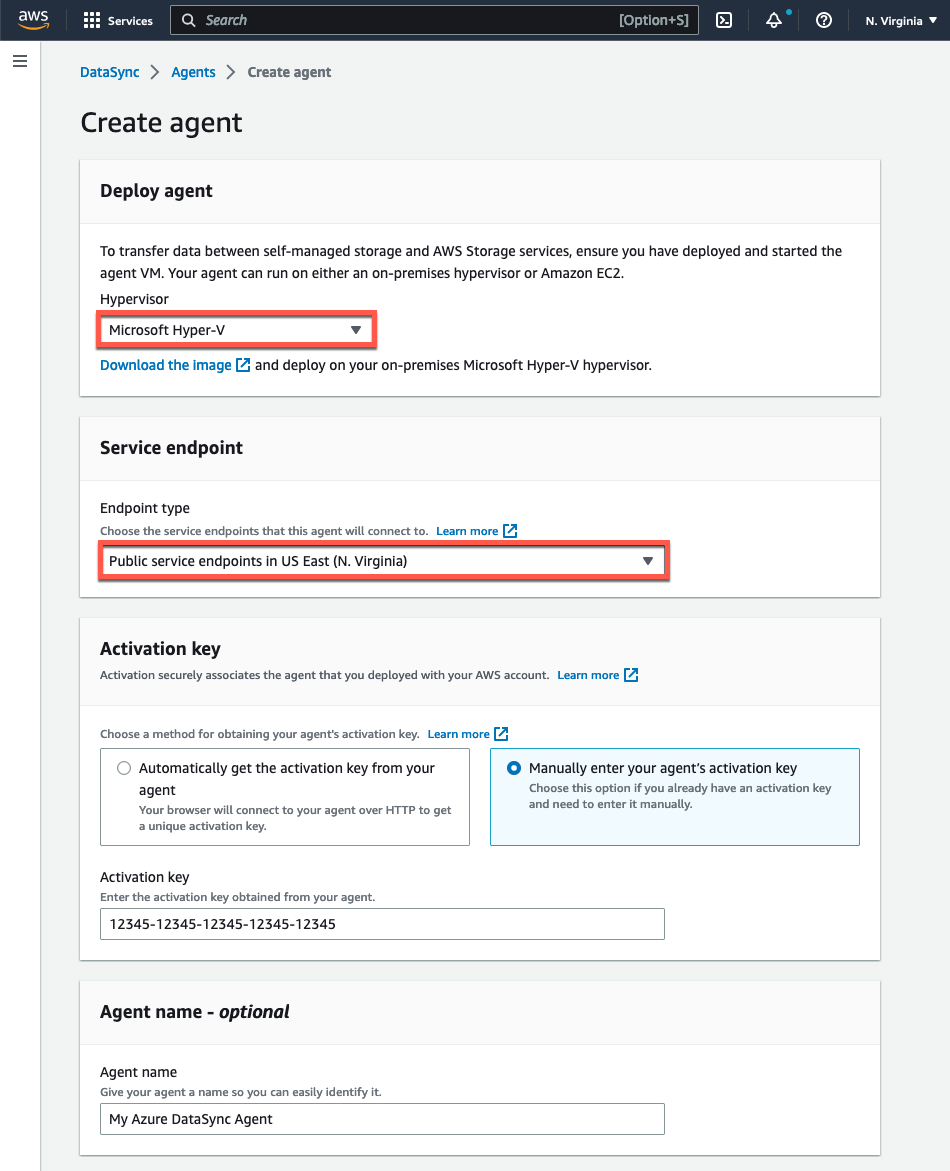
Figura 6: Crie o DataSync agent
Configurando a replicação de dados
Nesta seção, vamos nos concentrar nas etapas necessárias para criar os locais de armazenamento e configurar a replicação de dados.
Etapa 1: Configurar o local de origem do Azure Blob Storage
Configure o container de origem do Azure Blob Storage como um location do DataSync Azure Blob. Escolha a opção Locations no painel de navegação esquerdo e selecione Create Location. Em seguida, selecione Microsoft Azure Blob Storage como seu Location type. Certifique-se de selecionar o agent que você criou nas etapas anteriores.

Figura 7. Criando o local do Azure Blob Storage
Em seguida, você precisará especificar uma Container URL e um SAS token. Opcionalmente, você pode especificar o caminho de uma pasta no container para recuperar um subconjunto dos dados. Siga estas etapas para recuperar o URL do container e gerar um token SAS do Azure.
O token SAS do Azure fornece acesso delegado aos recursos na conta de armazenamento. Você pode fornecer acesso granular aos seus dados definindo os recursos que podem ser acessados, as permissões para esses recursos e a duração da validade do token SAS. Você pode gerar um token SAS do Azure no nível da conta de armazenamento ou no nível do container blob. Gerar o token no nível do container blob pode ser útil quando você deseja limitar o acesso a um único container.
Você pode gerar um token SAS do Azure a partir do portal do Azure, do Azure Storage Explorer ou da CLI do Azure. Usaremos o método do Portal do Azure para criar um token no nível da conta.
1.No portal do Azure, navegue até a conta de armazenamento e selecione Shared access signature no lado esquerdo da página. Limpe todos os Allowed services, exceto o Blob.
2. Selecione Container e Object no Allowed resource types. Atribua Read e List a partir das Allowed permissions. Atribua a permissão de Read/Write na seção Allowed blob index permissions para copiar tags. Você pode encontrar detalhes adicionais relacionados às permissões do token SAS na documentação.
3. Especifique as datas/horas de início e expiração da chave assinada. Certifique-se de que o período de validade do token seja suficiente para migrar os dados.
4. Revise a configuração e selecione Generate SAS and connection string.
5. Os valores do SAS token e do Blob Service SAS URL serão exibidos na parte inferior da tela. Copie o campo do SAS token para o campo SAS token na console da AWS.
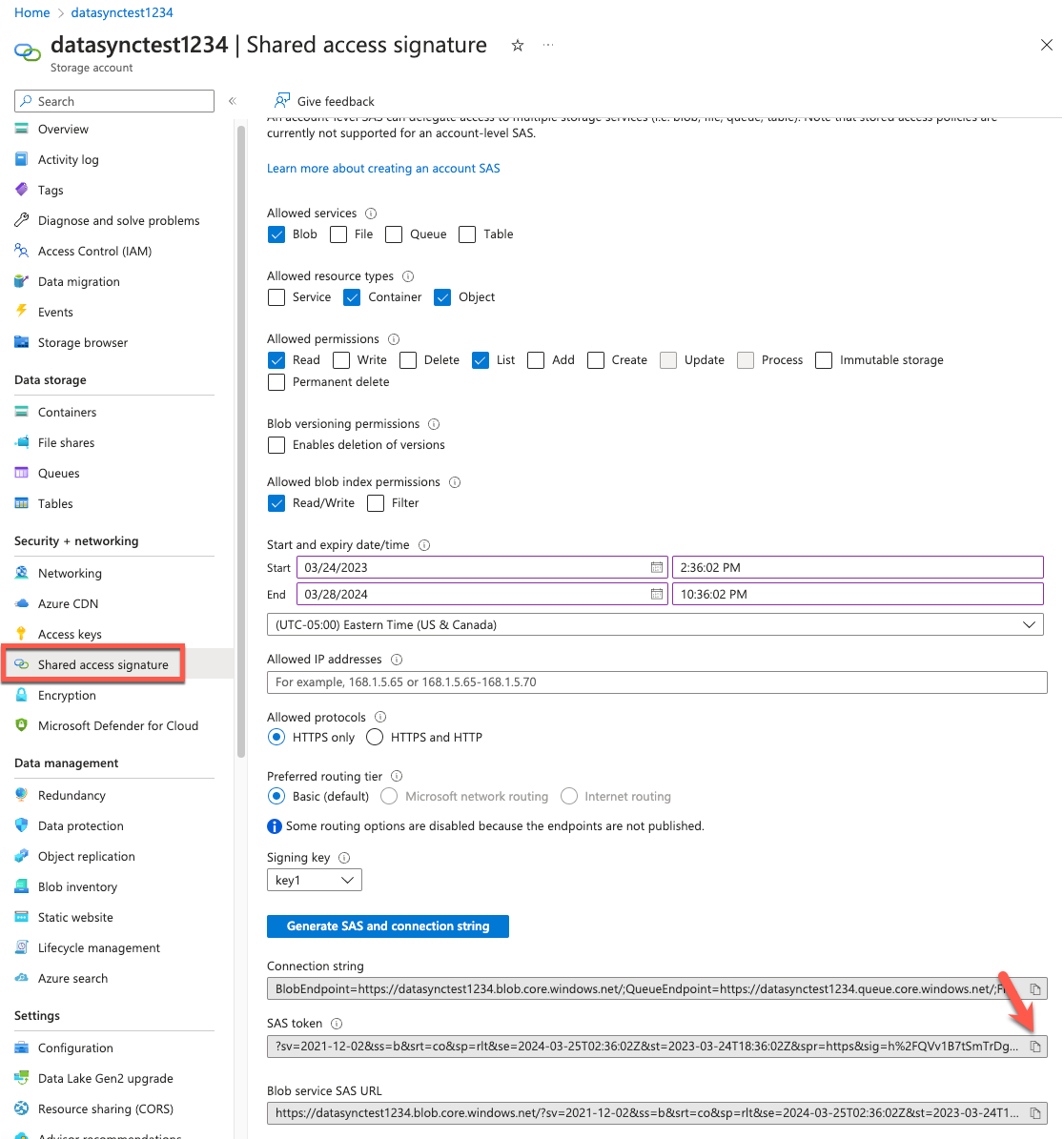
Figure 8: Identify the SAS token
6. Copie o Container URL das propriedades do Azure Blob container.
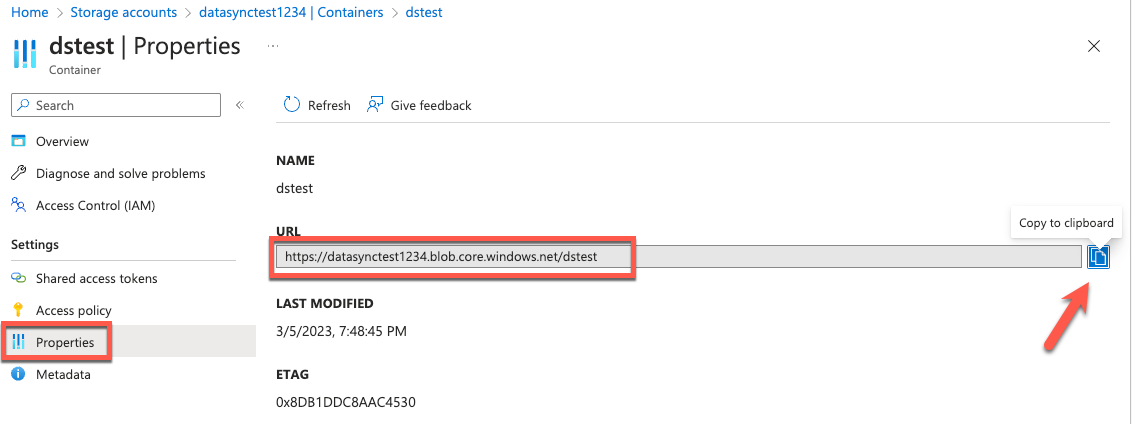
Figura 9: Identifique o URL do container
Etapa 2: configurar o local de destino
Configure o local de destino como Amazon S3. Selecione Locations no menu de navegação à esquerda e clique em Create location. Escolha seu bucket Amazon S3 de destino, classe de armazenamento S3, pasta e a função do IAM com as permissões para acessar o bucket do Amazon S3. O DataSync pode transferir dados diretamente para todas as classes de armazenamento S3 sem precisar gerenciar políticas de ciclo de vida de zero dia. Para cada transferência, você pode selecionar a classe de armazenamento S3 mais econômica para suas necessidades. O DataSync detecta arquivos ou objetos existentes no sistema de arquivos ou bucket de destino. Os dados que foram alterados entre o local de origem e o local de destino serão transferidos em execuções sequenciais da task do AWS DataSync.

Figura 10: Crie a localização do S3
Etapa 3: criar a tarefa de replicação
Defina as configurações da tarefa mapeando o local de origem existente do Azure Blob Storage na etapa 3 e o bucket Amazon S3 de destino na etapa 4. Consulte a documentação de configurações de tarefas para saber mais sobre as configurações e opções da tarefa.

Figura 11: Configurar o local de origem
Depois de configurar o local de origem, clique em Next e selecione o bucket Amazon S3 de destino:

Figura 12: Configurar o local de destino
A seguir está um exemplo das configurações que configuramos acima.
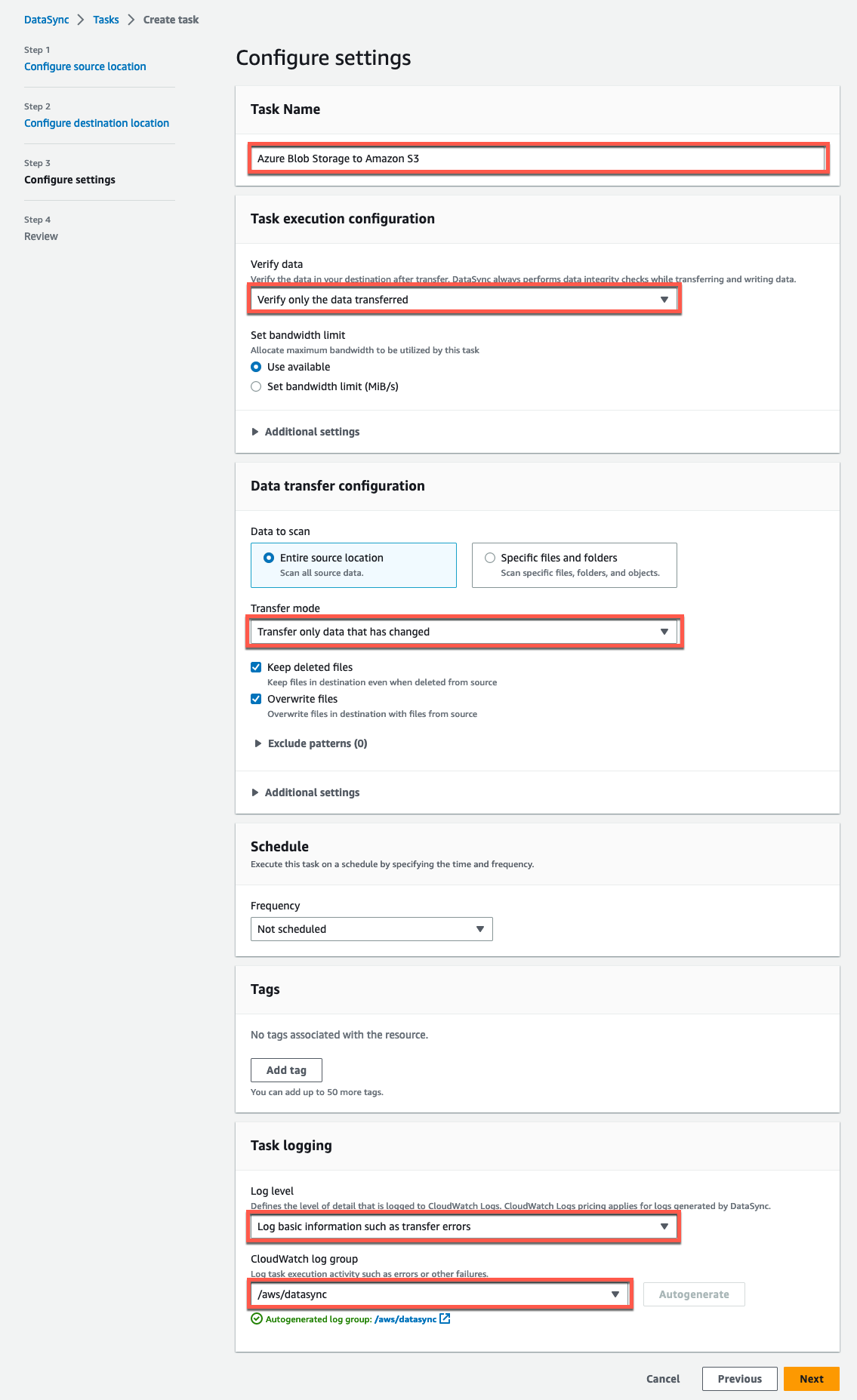
Figura 13: Configurações de tarefas do DataSync
Etapa 4: iniciar a task do DataSync
Inicie sua task para que o DataSync possa transferir os dados clicando em Start na lista de tasks ou dentro da própria visão geral da task. Saiba mais sobre a task execution e o monitoramento de sua tarefa do DataSync com o Amazon CloudWatch clicando nos links.
Depois de concluir as etapas deste tutorial, você tem um pipeline de dados seguro para mover seus dados do Azure Blob Storage de forma eficiente para o Amazon S3. Sempre que sua task do DataSync é executada, ela verifica os locais de origem e destino em busca de alterações e executa uma cópia de quaisquer diferenças de dados e metadados. Há várias fases pelas quais uma task do DataSync passa: lançamento, preparação, transferência e verificação. O tempo gasto na fase de preparação varia de acordo com o número de arquivos nos locais de origem e destino. Geralmente, leva de alguns minutos a várias horas. Consulte o Guia do usuário do DataSync para obter mais informações sobre as fases da tarefa do DataSync.
Limpando
Para obter mais informações sobre os preços da AWS, consulte a documentação do AWS DataSync. Embora não haja cobrança adicional pela transferência de dados de entrada, pode haver cobranças de saída de dados na conta de origem no Azure. Consulte o site de preços do fornecedor para obter informações atualizadas relacionadas às taxas de saída. Para evitar cobranças contínuas pelos recursos que você criou, siga estas etapas:
- Exclua a task do DataSync criada na Etapa 3 da configuração da replicação de dados.
- Exclua os locais de origem e destino criados nas etapas 1 e 2 da configuração da replicação de dados.
- Exclua o DataSync agent criado na etapa 3 da implantação do DataSync
- Exclua a VM do Azure e os recursos anexados criados ao implantar o DataSync agent.
- Exclua todos os objetos no bucket do S3 da etapa 1 da configuração da replicação de dados. O bucket deve estar vazio antes que você possa excluí-lo seguindo as etapas encontradas aqui.
- following the steps found here.
Conclusão
Nesta postagem do blog, exploramos uma implantação passo a passo do AWS DataSync agent no Azure. Criamos e configuramos uma task que copia dados de objetos de um container do Azure Blob Storage para um bucket S3 na AWS sem gerenciar scripts ou utilitários personalizados.
Os clientes podem se beneficiar da migração fácil de dados do Azure Blob Storage para serviços de armazenamento da AWS, como Amazon S3, Amazon Elastic File System e qualquer sistema de arquivos Amazon FSx compatível. O suporte para copiar dados dos serviços de armazenamento da AWS para o Azure Blob Storage será adicionado como parte da disponibilidade geral (GA). Aproveitar um serviço gerenciado como o DataSync elimina a carga de gerenciar infraestrutura adicional, economiza tempo operacional e reduz a complexidade da movimentação de dados em grande escala.
Aqui estão outros recursos para ajudar você a começar a usar o AWS DataSync:
- O que há de novo no AWS DataSync
- Guia do usuário do AWS DataSync
- AWS re:POST
- AWS DataSync Primer — curso on-line gratuito de uma hora e individualizado
- Como mover dados dos compartilhamentos SMB do Azure Files para a AWS usando o AWS DataSync
Obrigado por ler esta postagem sobre a migração do Azure Blob Storage para o Amazon S3 usando o AWS DataSync. Eu encorajo você a tentar essa solução hoje. Se você tiver algum comentário ou pergunta, deixe-os na seção de comentários
Este artigo foi traduzido do Blog da AWS em Inglês.
Sobre os autores
Revisores e Tradutores
 Gustavo Lima é Arquiteto de Soluções na AWS no segmento de Partner First SP High Biller. Ele possui mais de 13 anos de experiência na área de soluções de armazenamento e proteção de dados. Juntou-se ao time da AWS em 2022.
Gustavo Lima é Arquiteto de Soluções na AWS no segmento de Partner First SP High Biller. Ele possui mais de 13 anos de experiência na área de soluções de armazenamento e proteção de dados. Juntou-se ao time da AWS em 2022.
 André Botura é Arquiteto de Soluções Senior na AWS.
André Botura é Arquiteto de Soluções Senior na AWS.
 Samuel Sousa é Arquiteto de Soluções especialista em Storage na AWS para a América Latina. Ele possui mais de 10 anos de experiência na área de arquitetura de soluções focado especificamente no armazenamento, gerenciamento, proteção e recuperação de dados. Juntou-se ao time da AWS em 2020 e, desde então, vem ajudando os clientes a migrar e a otimizar suas cargas de trabalho na nuvem.
Samuel Sousa é Arquiteto de Soluções especialista em Storage na AWS para a América Latina. Ele possui mais de 10 anos de experiência na área de arquitetura de soluções focado especificamente no armazenamento, gerenciamento, proteção e recuperação de dados. Juntou-se ao time da AWS em 2020 e, desde então, vem ajudando os clientes a migrar e a otimizar suas cargas de trabalho na nuvem.