O blog da AWS
Monitorando o Amazon EMR no EKS com o Amazon Managed Prometheus e o Amazon Managed Grafana
O Amazon Managed Service for Prometheus é um serviço de monitoramento sem servidor para métricas compatível com o Prometheus de código aberto. O Amazon Prometheus facilita o monitoramento e o alerta de ambientes de contêineres com segurança, e ele se expande automaticamente à medida que suas necessidades de monitoramento aumentam. Além disso, ele oferece replicação de várias zonas de disponibilidade altamente disponíveis e integra os recursos de segurança e conformidade da AWS. O Amazon Managed Grafana é um serviço totalmente gerenciado com visualizações de dados ricas e interativas que ajudam os clientes a analisar, monitorar e alertar sobre métricas, logs e traces em várias fontes de dados.
O Amazon EMR no EKS permite que os clientes executem aplicações Spark junto com outros tipos de aplicações no mesmo cluster do Amazon EKS para melhorar a utilização de recursos e simplificar o gerenciamento da infraestrutura. O EMR no EKS configura dinamicamente a infraestrutura com base nas dependências de computação, memória e aplicação do job Spark. Um Spark Job pode gerar centenas de workers pods (também conhecidos como executores) em um cluster EKS para processar os jobs de dados. Portanto, é crucial observar as métricas de execução do job do Spark em andamento e obter informações sobre o uso de recursos do driver e dos executores do Spark. Além disso, as métricas essenciais devem ser armazenadas de forma centralizada para monitorar as tarefas e gerar alertas sobre degradação do desempenho, vazamentos de memória, etc.
Neste post, aprenderemos a criar observabilidade de ponta a ponta para jobs em Spark no EMR no EKS, aproveitando o Amazon Managed Service for Prometheus para coletar e armazenar as métricas geradas pelas aplicações Spark. Em seguida, usaremos o Amazon Managed Grafana para criar dashboards para monitorar casos de uso.
Visão geral da solução
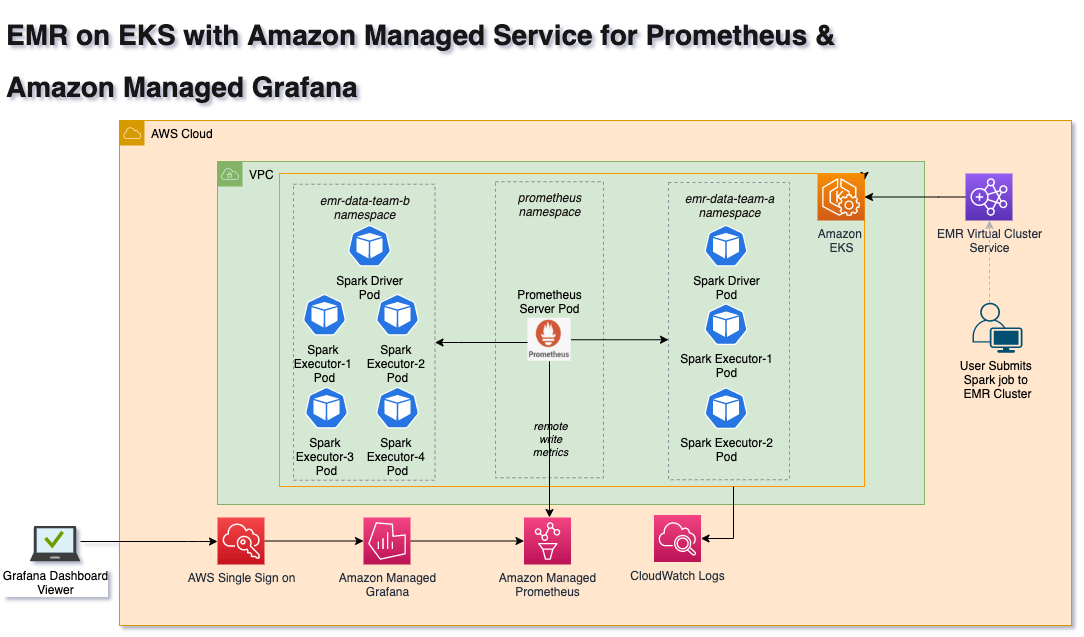
Nesta solução, usaremos o EMR no EKS Virtual Cluster para enviar Spark Jobs com a configuração do Prometheus Servlet. O Apache Spark Release 3.0 introduziu um novo recurso de coletor PrometheusServlet para expor as métricas do Spark Driver e Executor no formato Prometheus. A propriedade de configuração de métricas do Spark é definida na configuração do Spark, para que drivers e executores emitam métricas que podem ser coletadas pelo servidor Prometheus. Portanto, você deve configurar a configuração de escalonamento automático para que o servidor Prometheus aguente a carga.
O Prometheus Node Exporter é usado para expor várias métricas relacionadas ao hardware e ao kernel dos nós do Cluster EKS. O servidor Prometheus coleta essas métricas e grava em endpoints do Amazon Managed Service for Prometheus por meio da propriedade de configuração remote_write. Por sua vez, o Amazon Managed Grafana usa o Amazon Managed Service for Prometheus workspace como fonte de dados para seus dashboards. O Amazon Managed Grafana é usado para visualizar dados por meio de dashboards.
Arquitetura
O diagrama a seguir ilustra a arquitetura da solução para extrair as métricas do Driver e executores do Spark, bem como escrever no Amazon Managed Service for Prometheus.
Implantando a solução
Nesta postagem, você provisionará os seguintes recursos necessários para executar Spark Jobs usando modelos Terraform do Data on EKS, bem como monitorar métricas de job usando o Amazon Managed Prometheus e o Amazon Managed Grafana. A configuração do Amazon Managed Grafana é um processo manual neste blog, mas isso pode ser automatizado se você tiver o AWS SSO ativado em sua conta da AWS.
- Virtual Private Cloud(VPC), três sub-redes privadas, três sub-redes públicas, gateway NAT único e gateway de Internet
- Amazon EKS Cluster com um grupo de nós gerenciados
- EMR on EKS, namespace, contas de serviço e funções do IAM para contas de serviço (IRSA)
- Instalação do servidor Prometheus
- Amazon Managed Prometheus com remote write
- Amazon Managed Grafana
Pré-requisitos
Antes de criar toda a infraestrutura, você deve atender aos seguintes pré-requisitos.
- Uma conta da AWS com credenciais válidas da AWS
- Interface de linha de comando (CLI) da AWS
- Terraform 1.0.1
- kubectl — CLI do Kubernetes
Implantação
Vamos implantar a solução.
Etapa 1: clonar o repositório
Abra a janela do Terminal, mude para o diretório inicial e clone o repositório.
Em seguida, navegue até
Etapa 2: inicializar o Terraform
Inicialize o projeto, que baixa plug-ins que permitem que o Terraform interaja com os serviços da AWS.
Etapa 3: Terraform Plan
Execute o Terraform plan para verificar os recursos criados por essa implantação. A saída do Terraform plan mostrará os recursos que serão criados por este template.
Etapa 4: Aplicar o Terraform
Finalmente, execute terraform apply para implantar os recursos. Essa execução pode levar até 30 minutos para criar todos os recursos.
Etapa 5: Verificar os recursos
Vamos verificar os recursos criados pela Etapa 4.
Verifique o cluster Amazon EKS e o serviço Amazon Managed para Prometheus
Verifique o EMR nos namespaces EKS emr-data-team-a e emr-data-team-b e o status do pod para Prometheus, Vertical Pod Autoscaler, Metrics Server e Cluster Autoscaler.
A imagem a seguir mostra o espaço de job Amazon Managed Service for Prometheus.

Etapa 6: Verificar o cluster virtual do EMR
Faça login no console da AWS, abra o serviço EMR e selecione o link EMR on EKS Virtual Clusters. Você deve ver o cluster virtual do EMR (emr-eks-karpenter-emr-data-team-a) em estado de Running conforme mostrado na imagem a seguir.

Etapa 7: Executar o job do Spark no cluster virtual do EMR
Antes do Spark 3.0, as métricas do Spark eram expostas por meio do Spark JMX Sink + Prometheus JMX Converter com uma combinação do exportador Prometheus JMX. Infelizmente, essa abordagem requer uma configuração adicional com um arquivo jar externo. No entanto, esse processo agora é simplificado com a introdução do suporte nativo para o Prometheus Monitoring com a classe PrometheusServlet como o recurso mais recente do Apache Spark3.0. Nesta postagem do blog, usaremos o Spark3.0 com a configuração do prometheusServlet para expor métricas ao Prometheus. O PrometheusServlet adiciona um servlet na interface de usuário existente do Spark para fornecer dados de métricas no formato Prometheus.
Os usuários do Spark devem adicionar a seguinte configuração ao sparkSubmitParameters tpara extrair as métricas do driver e dos executores do Spark. Essa configuração de parâmetro já foi adicionada ao exemplo de script do Spark usado nesta solução. O Prometheus Server em execução no EKS extrai as métricas periodicamente. A Prometheus confia na descoberta de serviços do Kubernetes para encontrar um job em execução e extrair e armazenar as métricas do endpoint do aplicação. Aqui está o link para as métricas disponíveis do Spark.
Etapa 8: Monitore o envio do Spark
Faça login no console do AWS EMR, selecione o cluster virtual do EMR e verifique o status do job. Isso deve mostrar o status como Completed em alguns minutos, e o conjunto de dados de resultados da execução do Spark Job será gravado no bucket do S3 na pasta OUTPUT.

Execute o comando a seguir para verificar o status do pod de execução do job do Spark
Etapa 9: Verificar as métricas coletadas pelo Prometheus Server
Nesta etapa, verifique as métricas do Spark coletadas pelo Prometheus Server em execução no Cluster EKS. Vamos executar o comando. Esse comando constrói um arquivo de configuração com valores de dados do servidor e da autoridade de certificação para um cluster EKS especificado.
Vamos transferir para o serviço Prometheus para verificar as métricas usando o Prometheus WebUI.
Agora, abra o navegador e acesse a interface do usuário do Prometheus usando http://localhost:9090/. As métricas do Spark Executor são as seguintes:

Além disso, essa solução grava automaticamente as métricas no Amazon Managed Service for Prometheus workspace. Vamos analisar como consultar essas métricas do Amazon Grafana nas próximas etapas.
Etapa 10: Configurar o Grafana Workspace
Nesta etapa, usaremos o AWS Console para criar o Amazon Grafana Workspace.
- Faça login no console da AWS e abra o Amazon Grafana.
- Selecione
Create Workspacee insira os detalhes conforme mostrado a seguir.
Observe que, se você não configurou usuários por meio do AWS SSO, poderá usar a experiência integrada oferecida pelo Amazon Managed Grafana e selecionar Criar usuário nesta etapa. Como alternativa, você pode abrir o serviço AWS Single Sign-On e criar usuários (por exemplo, grafana-user). Consulte esta postagem para obter mais detalhes sobre como configurar o Amazon Managed Grafana com SSO.

A próxima etapa é adicionar o usuário recém-criado do AWS SSO ao workspace do Grafana. Selecione o botão Assign new user or group e selecione o usuário grafana-user criado anteriormente ao espaço de job. Torne esse usuário um administrador selecionando o botão Make Admin. Essa opção permite que os usuários adicionem fontes de dados ao painel do Grafana em nossas próximas etapas.
Etapa 11: Adicionar o Amazon Managed Prometheus Workspace como fonte de dados ao Amazon Managed Grafana
É fácil conectar-se ao Amazon Managed Prometheus usando os datasources da AWS e depois explorar as métricas. Abra o URL do Grafana Workspace em um navegador. Você deve fornecer ao usuário recém-criado grafana-user e a senha para fazer login no Workspace. Depois de fazer login, você pode ver a página do Amazon Grafana Dashboard. Primeiro, selecione o logotipo da AWS na faixa esquerda logo acima do link de configurações e selecione Amazon Managed Service for Prometheus como fonte de dados.
Ele deve buscar automaticamente o Workspace do Amazon Managed Service for Prometheus criado pelo Terraform Apply na Etapa 4. Em seguida, selecione a região correta usada para implantar o Cluster EKS na Etapa 3 e selecione o botão Add data source. Você deverá ver uma página, conforme mostrado na imagem a seguir, com uma fonte de dados conectada com êxito.

Etapa 12: criar o painel de métricas do Spark
Finalmente, chegamos à etapa final de criação do painel Grafana e monitoramento dos Spark Jobs. Já criamos um arquivo JSON do painel do Spark Grafana para esta demonstração. Copiaremos o conteúdo do arquivo JSON deste local:
~/data-on-eks/analytics/terraform/emr-eks-karpenter/emr-grafana-dashboard/emr-eks-grafana-dashboard.json
Agora, importe o conteúdo do arquivo JSON para o Amazon Managed Grafana. Faça login no console Amazon Managed Grafana e selecione os botões “+” e “import” no painel esquerdo da faixa de opções. Cole o conteúdo do arquivo JSON copiado na caixa de texto “import via panel json” e selecione o botão Load para ver o painel do Spark.
Como alternativa, você também pode usar o painel de controle Grafana de código aberto com ID 18387.
Você deve ver um painel como o da imagem a seguir. Além disso, você pode filtrar e monitorar os jobs do Spark usando Virtual Cluster ID, EMR Job ID, DriverID, ExecutorID e NodeID.

O GIF animado a seguir mostra o EMR no painel de métricas do EKS Spark Job para vários recursos.

Limpar
Para evitar cobranças indesejadas em sua conta da AWS, exclua todos os recursos da AWS criados durante este passo a passo. Você pode executar o comando cleanup.sh para excluir todos os recursos criados por esta postagem:
Além disso, faça login no AWS Console e exclua o cluster virtual do EMR e o Amazon Managed Grafana Workspace criados manualmente.
Conclusão
Neste post, aprendemos a configurar e executar jobs do Spark usando o EMR no serviço gerenciado EKS, bem como exportar métricas para o Prometheus Server usando o coletor PrometheusServlet. A Prometheus grava essas métricas remotamente no Amazon Managed Service for Prometheus. O Amazon Managed Grafana é usado para visualizar as métricas no painel ao vivo. Esta postagem também apresentou um Data on EKS de código aberto que ajuda você a criar plataformas de dados escaláveis em clusters EKS com todos os complementos necessários, incluindo Prometheus e EMR nos recursos do EKS Kubernetes.
Lidar com grandes volumes de cargas de job do contêiner Spark com um grande número de métricas exige um banco de dados de métricas altamente escalável e altamente disponível. O Amazon Managed Service for Prometheus fornece uma experiência totalmente gerenciada que oferece segurança, escalabilidade e disponibilidade aprimoradas. Além disso, o AWS Managed Grafana para visualização interativa de dados é usado para monitoramento e alertas. Ambos os serviços compartilham serviços de segurança da AWS, como controle de acesso refinado e trilhas de auditoria de atividades. Isso permite que engenheiros de dados, cientistas de dados e engenheiros de DevOps monitorem e gerenciem proativamente as cargas de job do Spark em execução no EKS.
Este artigo foi traduzido do Blog da AWS em Inglês.