- การประมวลผลบนคลาวด์คืออะไร
- ฮับแนวคิดการประมวลผลบนคลาวด์
- ปัญญาประดิษฐ์
- แมชชีนเลิร์นนิง
การฝังในแมชชีนเลิร์นนิงคืออะไร
การฝังในแมชชีนเลิร์นนิงคืออะไร
การฝังเป็นการแสดงเชิงตัวเลขของวัตถุในโลกแห่งความเป็นจริงที่ระบบการ เรียนรู้ของเครื่อง (ML) และปัญญาประดิษ ฐ์ (AI) ใช้เพื่อทำความเข้าใจโดเมนความรู้ที่ซับซ้อนเช่นเดียวกับมนุษย์ทำ ตามตัวอย่าง อัลกอริทึมการประมวลผลจะเข้าใจว่าผลต่างระหว่าง 2 และ 3 คือ 1 ซึ่งบ่งบอกถึงความสัมพันธ์ที่ใกล้ชิดระหว่าง 2 และ 3 เมื่อเปรียบเทียบกับ 2 และ 100 อย่างไรก็ตาม ข้อมูลในโลกแห่งความเป็นจริงยังรวมถึงความสัมพันธ์ที่ซับซ้อนมากขึ้นด้วย ตัวอย่างเช่น Bird-Nest (รัง-นก) และ Lion-den (ถ้ำ-สิงโต) เป็นคำคู่ที่มีความสัมพันธ์กัน ในขณะที่ Day-Night (กลางวัน-กลางคืน) เป็นคำที่ตรงกันข้ามกัน การฝังจะแปลงวัตถุในโลกแห่งความเป็นจริงให้กลายเป็นการแทนค่าทางคณิตศาสตร์ที่ซับซ้อน ซึ่งจะมีทั้งคุณสมบัติและความสัมพันธ์โดยธรรมชาติระหว่างข้อมูลในโลกแห่งความเป็นจริงอยู่ด้วย กระบวนการทั้งหมดนี้นั้นดำเนินไปอย่างอัตโนมัติ โดยระบบ AI จะสร้างการฝังด้วยตนเองในระหว่างการฝึก และใช้สิ่งเหล่านั้นตามความจำเป็นเพื่อทำงานใหม่ให้สำเร็จ
เหตุใดการฝังจึงมีความสำคัญ
การฝังช่วยให้โมเดลการเรียนรู้เชิงลึกสามารถเข้าใจโดเมนข้อมูลในโลกแห่งความเป็นจริงได้อย่างมีประสิทธิภาพมากขึ้น โดยลดความซับซ้อนในการแสดงข้อมูลในโลกแห่งความเป็นจริงในขณะที่ยังคงรักษาความสัมพันธ์ทางความหมายและวากยสัมพันธ์ ช่วยให้อัลกอริธึมแมชชีนเลิร์นนิงสามารถแยกและประมวลผลประเภทข้อมูลที่ซับซ้อน และใช้งานแอปพลิเคชัน AI ที่เป็นนวัตกรรมใหม่ได้ ส่วนต่อไปนี้จะอธิบายปัจจัยที่สำคัญบางประการ
ลดมิติข้อมูล
นักวิทยาศาสตร์ข้อมูลใช้การฝังเพื่อแสดงข้อมูลมิติสูงในพื้นที่มิติต่ำ ในด้านวิทยาศาสตร์ข้อมูล คำว่า มิติ โดยทั่วไปหมายถึงคุณสมบัติหรือคุณลักษณะของข้อมูล ข้อมูลมิติที่สูงขึ้นใน AI หมายถึงชุดข้อมูลที่มีคุณสมบัติหรือคุณลักษณะมากมายที่กำหนดจุดข้อมูลแต่ละจุด ซึ่งอาจหมายถึงมิติหลายสิบ ร้อย หรือแม้แต่หลายพันมิติ ตัวอย่างเช่น รูปภาพสามารถถือเป็นข้อมูลที่มีมิติสูงได้ เนื่องจากค่าสีพิกเซลแต่ละค่าเป็นมิติที่แยกจากกัน
เมื่อถูกนำเสนอด้วยข้อมูลมิติสูง โมเดลการเรียนรู้เชิงลึกต้องใช้พลังและเวลาในการคำนวณมากขึ้นในการเรียนรู้ วิเคราะห์ และอนุมานได้อย่างแม่นยำ การฝังจะลดจำนวนมิติโดยการระบุความเหมือนกันและรูปแบบระหว่างคุณสมบัติต่างๆ ส่งผลให้ทรัพยากรการประมวลผลและเวลาที่ต้องใช้ในการประมวลผลข้อมูลดิบลดลง
ฝึกโมเดลภาษาขนาดใหญ่
การฝังปรับปรุงคุณภาพข้อมูลเมื่อฝึกโมเดล ภาษาขนาดใหญ่ (LLM) ตัวอย่างเช่น นักวิทยาศาสตร์ข้อมูลใช้การฝังเพื่อล้างข้อมูลการฝึกจากความผิดปกติที่ส่งผลต่อการเรียนรู้โมเดล วิศวกร ML ยังสามารถปรับใช้โมเดลที่ได้รับการฝึกอบรมล่วงหน้าด้วยการเพิ่มการฝังใหม่สำหรับการเรียนรู้แบบถ่ายโอน ซึ่งต้องมีการปรับปรุงโมเดลพื้นฐานด้วยชุดข้อมูลใหม่ ด้วยการฝัง วิศวกรสามารถปรับแต่งโมเดลสำหรับชุดข้อมูลที่กำหนดเองจากโลกแห่งความเป็นจริงได้
สร้างการใช้งานที่เป็นนวัตกรรม
การฝังช่วยให้การเรียนรู้เชิงล ึกและแอปพลิเคชันปัญ ญาประดิษฐ์เชิงสร้างใหม่ (generative AI) เทคนิคการฝังต่างๆ ที่ใช้ในสถาปัตยกรรมนิวรัลเน็ตเวิร์กช่วยให้โมเดล AI ที่แม่นยำได้รับการพัฒนา ฝึกฝน และปรับใช้ในสาขาและการใช้งานด้านต่างๆ ตัวอย่างเช่น:
- ด้วยการฝังรูปภาพ วิศวกรสามารถสร้างแอปพลิเคชันคอมพิวเตอร์วิทัศน์ที่มีความแม่นยำสูงสำหรับการตรวจจับวัตถุ การจดจำรูปภาพ และงานอื่น ๆ ที่เกี่ยวข้องกับภาพ
- ด้วยการฝังคำ ซอฟต์แวร์ประมวลผลภาษาธรรมชาติสามารถเข้าใจบริบทและความสัมพันธ์ของคำได้แม่นยำยิ่งขึ้น
- การฝังกราฟจะแยกและจัดหมวดหมู่ข้อมูลที่เกี่ยวข้องจากโหนดที่เชื่อมต่อถึงกันเพื่อรองรับการวิเคราะห์เครือข่าย
แบบจำลองการมองเห็นคอมพิวเตอร์ แชท บอท AI และระบบแนะนำ AI ล้วนใช้การฝังเพื่อทำงานที่ซับซ้อนซึ่งเลียนแบบสติปัญญาของมนุษย์ให้เสร็จสมบูรณ์
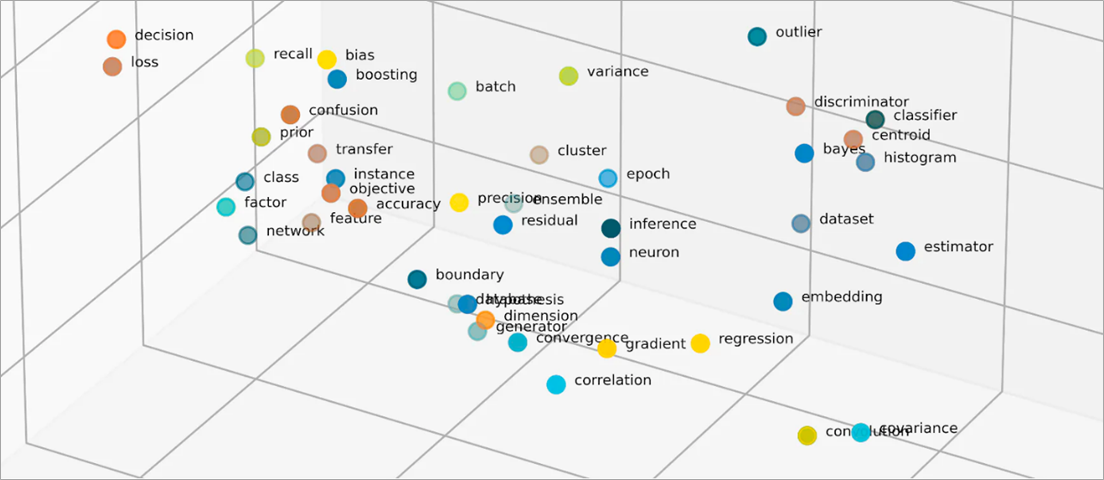
เวกเตอร์ในการฝังคืออะไร
โมเดล ML ไม่สามารถตีความข้อมูลได้อย่างชาญฉลาดในรูปแบบดิบ และต้องการข้อมูลตัวเลขเป็นอินพุต โมเดลเหล่านี้ใช้การฝังนิวรัลเน็ตเวิร์กเพื่อแปลงข้อมูลคำศัพท์จริงเป็นการแสดงตัวเลขที่เรียกว่าเวกเตอร์ เวกเตอร์คือค่าตัวเลขที่แสดงถึงข้อมูลในพื้นที่หลายมิติ ช่วยให้โมเดล ML ค้นหาความคล้ายคลึงกันระหว่างรายการที่กระจัดกระจาย
ทุกออบเจ็กต์ที่โมเดล ML เรียนรู้จากจะมีลักษณะหรือคุณสมบัติที่หลากหลาย ลองพิจารณาภาพยนตร์และรายการทีวีต่อไปนี้เป็นตัวอย่างง่ายๆ ภาพยนตร์และรายการทีวีแต่ละเรื่องจะมีลักษณะเฉพาะตามแนว ประเภท และปีที่เข้าฉาย
The Conference (สยองขวัญ, 2023, ภาพยนตร์)
Upload (ตลก, 2023, รายการทีวี, ซีซั่น 3)
Tales from the Crypt (สยองขวัญ 1989 รายการทีวี ซีซั่น 7)
Dream Scenario (สยองขวัญ-ตลก, 2023, ภาพยนตร์)
โมเดล ML สามารถตีความตัวแปรตัวเลข เช่น ปี แต่ไม่สามารถเปรียบเทียบตัวแปรที่ไม่ใช่ตัวเลข เช่น แนว ประเภท ตอน และซีซั่นทั้งหมดได้ การฝังเวกเตอร์จะเข้ารหัสข้อมูลที่ไม่ใช่ตัวเลขลงในชุดค่าที่โมเดล ML สามารถเข้าใจและเชื่อมโยงได้ ตัวอย่างเช่น ข้อมูลต่อไปนี้เป็นเพียงการแสดงสมมุติของรายการทีวีที่แสดงไว้ก่อนหน้านี้
The Conference (1.2, 2023, 20.0)
Upload (2.3, 2023, 35.5)
Tales from the Crypt (1.2, 1989, 36.7)
Dream Scenario (1.8, 2023, 20.0)
ตัวเลขแรกในเวกเตอร์จะสอดคล้องกับประเภทเฉพาะ โมเดล ML จะพบว่า The Conference และ Tales from the Crypt เป็นภาพยนตร์แนวเดียวกัน ในทำนองเดียวกัน โมเดลจะค้นหาความสัมพันธ์เพิ่มเติมระหว่าง Upload และ Tales from the Crypt ตามหมายเลขที่สาม ซึ่งแสดงถึงรูปแบบ ซีซั่น และตอนต่างๆ เมื่อมีการแนะนำตัวแปรมากขึ้น คุณสามารถปรับแต่งโมเดลเพื่อบีบอัดข้อมูลเพิ่มเติมในพื้นที่เวกเตอร์ที่เล็กลงได้
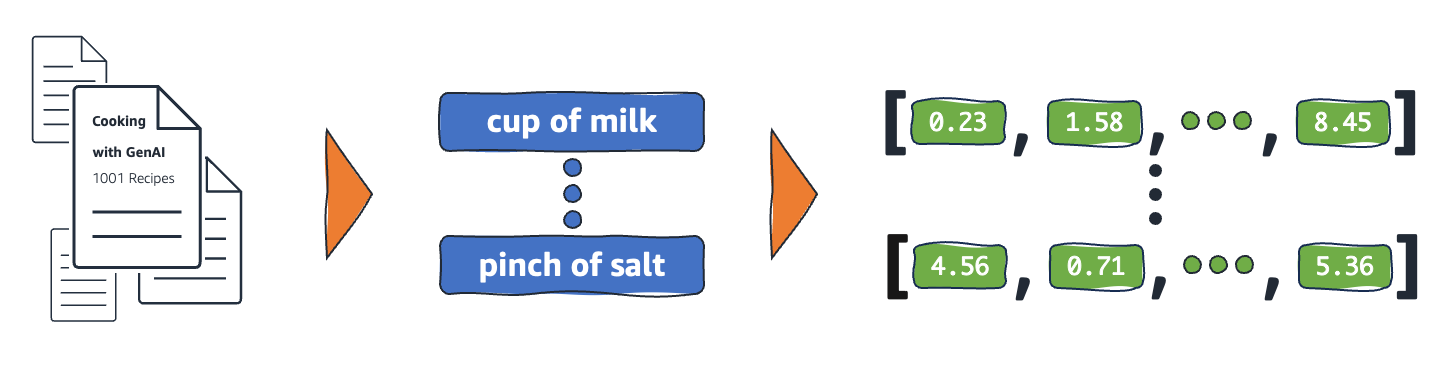
การฝังทำงานอย่างไร
การฝังจะแปลงข้อมูลดิบเป็นค่าต่อเนื่องที่โมเดล ML สามารถตีความได้ โดยทั่วไปแล้ว โมเดล ML จะใช้การเข้ารหัสแบบ One-Hot เพื่อแมปตัวแปรเชิงหมวดหมู่ให้อยู่ในรูปแบบที่สามารถเรียนรู้ได้ วิธีการเข้ารหัสจะแบ่งแต่ละหมวดหมู่ออกเป็นแถวและคอลัมน์ และกำหนดค่าไบนารีให้กับแถวและคอลัมน์เหล่านั้น พิจารณาประเภทของผลผลิตและราคาต่อไปนี้
|
ผลไม้ |
ราคา |
|
Apple |
5.00 |
|
ส้ม |
7.00 |
|
แครอท |
10.00 |
การแสดงค่าด้วยผลลัพธ์การเข้ารหัสแบบ One-Hot ในตารางต่อไปนี้
|
Apple |
ส้ม |
ลูกแพร์ |
ราคา |
|
1 |
0 |
0 |
5.00 |
|
0 |
1 |
0 |
7.00 |
|
0 |
0 |
1 |
10.00 |
ตารางแสดงทางคณิตศาสตร์เป็นเวกเตอร์ [1,0,0,5.00], [0,1,0,7.00] และ [0,0,1,10.00]
การเข้ารหัสแบบ One-Hot จะขยายค่ามิติเป็น 0 และ 1 โดยไม่ต้องให้ข้อมูลที่ช่วยให้โมเดลเชื่อมโยงวัตถุต่างๆ ตัวอย่างเช่น โมเดลไม่พบความคล้ายคลึงระหว่างแอปเปิ้ลกับส้มแม้จะเป็นผลไม้เหมืนกัน และไม่สามารถแยกความแตกต่างระหว่างส้มกับแครอทว่าเป็นผักและผลไม้ได้ เมื่อมีการเพิ่มหมวดหมู่เข้าไปในรายการมากขึ้น การเข้ารหัสจะส่งผลให้ตัวแปรกระจายอย่างกระจัดกระจายโดยมีค่าว่างจำนวนมากซึ่งใช้พื้นที่หน่วยความจำมหาศาล
การฝังวัตถุเวกเตอร์ลงในช่องว่างมิติต่ำโดยแสดงความคล้ายคลึงกันระหว่างวัตถุที่มีค่าตัวเลข การฝังนิวรัลเน็ตเวิร์กเทียมช่วยให้แน่ใจว่าจำนวนมิติข้อมูลยังคงสามารถจัดการได้ด้วยคุณสมบัติอินพุตที่ขยายเพิ่มขึ้น คุณสมบัติอินพุตเป็นลักษณะของออบเจ็กต์เฉพาะที่อัลกอริทึม ML ได้รับมอบหมายให้วิเคราะห์ การลดขนาดช่วยให้การฝังสามารถเก็บข้อมูลที่โมเดล ML ใช้เพื่อค้นหาความเหมือนและความแตกต่างจากข้อมูลอินพุต นักวิทยาศาสตร์ข้อมูลยังสามารถแสดงภาพการฝังในพื้นที่สองมิติเพื่อทำความเข้าใจความสัมพันธ์ของวัตถุที่กระจายได้ดียิ่งขึ้น
โมเดลแบบฝังคืออะไร
โมเดลแบบฝังเป็นอัลกอริธึมที่ได้รับการฝึกเพื่อรวมข้อมูลให้เป็นการนำเสนอที่หนาแน่นในพื้นที่หลายมิติ นักวิทยาศาสตร์ข้อมูลใช้โมเดลแบบฝังเพื่อให้โมเดล ML สามารถเข้าใจและให้เหตุผลกับข้อมูลที่มีมิติสูง สิ่งเหล่านี้เป็นโมเดลแบบฝังทั่วไปที่ใช้ในการใช้งาน ML
การวิเคราะห์องค์ประกอบหลัก
การวิเคราะห์องค์ประกอบหลัก (PCA) เป็นเทคนิคการลดขนาดที่ลดประเภทข้อมูลที่ซับซ้อนให้เป็นเวกเตอร์ขนาดต่ำ โดยจะมีการค้นหาจุดข้อมูลที่มีความคล้ายคลึงกันและบีบอัดให้เป็นเวกเตอร์ที่ฝัง ซึ่งสะท้อนถึงข้อมูลต้นฉบับ แม้ว่า PCA จะอนุญาตให้โมเดลประมวลผลข้อมูลดิบได้อย่างมีประสิทธิภาพมากขึ้น แต่ข้อมูลอาจสูญหายระหว่างการประมวลผล
การแยกค่าเอกฐาน
การแยกค่าเอกฐาน (SVD) เป็นโมเดลแบบฝังที่แปลงเมทริกซ์เป็นเมทริกซ์เอกฐาน เมทริกซ์ผลลัพธ์จะคงข้อมูลดั้งเดิมไว้ในขณะที่ช่วยให้โมเดลเข้าใจความสัมพันธ์เชิงความหมายของข้อมูลที่เป็นตัวแทนได้ดีขึ้น นักวิทยาศาสตร์ข้อมูลใช้ SVD เพื่อใช้งาน ML ต่างๆ รวมถึงการบีบอัดรูปภาพ การจัดหมวดหมู่ข้อความ และคำแนะนำ
Word2Vec
Word2Vec เป็นอัลกอริทึม ML ที่ได้รับการฝึกให้เชื่อมโยงคำ และนำเสนอคำเหล่านั้นในพื้นที่ฝัง นักวิทยาศาสตร์ด้านข้อมูลจะป้อนโมเดล Word2Vec ด้วยชุดข้อมูลข้อความขนาดใหญ่เพื่อให้สามารถเข้าใจภาษาธรรมชาติได้ โมเดลจะค้นหาความคล้ายคลึงกันในคำโดยพิจารณาบริบทและความสัมพันธ์ทางความหมาย
Word2Vec มีสองรูปแบบ ได้แก่ Continuous Bag of Words (CBOW) และ Skip-gram CBOW จะช่วยให้โมเดลทำนายคำจากบริบทที่กำหนด ในขณะที่ Skip-gram จะได้บริบทจากคำที่กำหนด แม้ว่า Word2Vec จะเป็นเทคนิคการฝังคำที่มีประสิทธิภาพ แต่ก็ไม่สามารถแยกแยะความแตกต่างทางบริบทของคำเดียวกันที่ใช้เพื่อสื่อถึงความหมายที่แตกต่างกันได้อย่างถูกต้อง
BERT
BERT คือโมเดลภาษาที่ใช้รูปแบบ Transformer ซึ่งได้รับการฝึกฝนด้วยชุดข้อมูลขนาดใหญ่เพื่อทำความเข้าใจภาษาเหมือนกับมนุษย์ BERT สามารถสร้างคำที่ฝังจากข้อมูลอินพุตที่ได้รับการฝึก เช่นเดียวกับ Word2Vec นอกจากนี้ BERT ยังสามารถแยกความแตกต่างความหมายตามบริบทของคำเมื่อนำไปใช้กับวลีที่ต่างกัน ตัวอย่างเช่น BERT สร้างการฝังที่แตกต่างกันสำหรับ 'เล่น' เช่นเดียวกับใน "ฉันไปดูละคร" และ "ฉันชอบเล่น"
การฝังถูกสร้างขึ้นอย่างไร?
วิศวกรใช้ เครือข่ายประสา ทเพื่อสร้างการฝังตัว นิวรัลเน็ตเวิร์กประกอบไปด้วยชั้นนิวรอนที่ซ่อนอยู่ ซึ่งทำให้การตัดสินใจที่ซ้ำซ้อน เมื่อสร้างการฝัง เลเยอร์ใดชั้นหนึ่งที่ซ่อนอยู่จะเรียนรู้วิธีแยกคุณสมบัติอินพุตเป็นเวกเตอร์ สิ่งนี้เกิดขึ้นก่อนเลเยอร์การประมวลผลคุณสมบัติ กระบวนการนี้ได้รับการดูแลและแนะนำโดยวิศวกรด้วยขั้นตอนต่อไปนี้:
- วิศวกรป้อนนิวรัลเน็ตเวิร์กด้วยตัวอย่างเวกเตอร์บางตัวที่เตรียมเอง
- นิวรัลเน็ตเวิร์กเรียนรู้จากรูปแบบที่ค้นพบในตัวอย่าง และใช้ความรู้ในการคาดการณ์ที่ถูกต้องจากข้อมูลที่มองไม่เห็น
- บางครั้งวิศวกรอาจต้องปรับแต่งโมเดลอย่างละเอียด เพื่อให้แน่ใจว่าจะกระจายคุณสมบัติอินพุตลงในพื้นที่มิติที่เหมาะสม
- เมื่อเวลาผ่านไป การฝังจะทำงานได้อย่างอิสระ ทำให้โมเดล ML สามารถสร้างคำแนะนำจากตัวแทนเวกเตอร์ได้
- วิศวกรยังคงตรวจสอบประสิทธิภาพของการฝังและปรับแต่งข้อมูลใหม่ ๆ
AWS สามารถช่วยรองรับเกี่ยวกับข้อกำหนดการฝังของคุณได้อย่างไร
Amazon Bedrock เป็นบริการที่มีการจัดการอย่างเต็มที่ซึ่งเสนอโมเดลพื้นฐานที่มีประสิทธิภาพสูง (FM) จากบริษัทชั้นนำของ AI พร้อมกับคุณสมบัติที่หลากหลายเพื่อสร้างแอปพลิเคชันปัญญาประดิษฐ์แบบสร้าง (generative AI) Amazon Nova เป็น โมเดลพื้นฐานที่ทันสมัย (SOTA) รุ่นใหม่ (FM) ที่นำเสนอข้อมูลข่าวกรองชายแดนและประสิทธิภาพด้านราคาชั้นนำในอุตสาหกรรม ซึ่งเป็นโมเดลอเนกประสงค์ที่ทรงพลังซึ่งสร้างขึ้นเพื่อรองรับกรณีการใช้งานที่หลากหลาย ใช้ตามที่สร้างมา หรือปรับแต่งด้วยข้อมูลของคุณเอง
Titan Embeddings คือ LLM ที่แปลข้อความเป็นตัวแทนตัวเลข โมเดล Titan Embeddings รองรับการดึงข้อความ ความคล้ายคลึงกันเชิงความหมาย และการทำคลัสเตอร์ ข้อความอินพุตสูงสุดคือโทเค็น 8,000 รายการและความยาวเวกเตอร์เอาต์พุตสูงสุดคือ 1536
ทีมแมชชีนเลิร์นนิงยังสามารถใช้ Amazon SageMaker เพื่อ สร้างการฝังตัว Amazon SageMaker เป็นฮับที่คุณสามารถสร้าง ฝึกฝน และปรับใช้โมเดล ML ในสภาพแวดล้อมที่ปลอดภัยและปรับขนาดได้ มีเทคนิคการฝังที่เรียกว่า Object2Vec ซึ่งวิศวกรสามารถกำหนดเวกเตอร์ข้อมูลมิติสูงในพื้นที่มิติต่ำได้ คุณสามารถใช้การฝังที่ผ่านการเรียนรู้เพื่อคำนวณความสัมพันธ์ระหว่างอ็อบเจกต์สำหรับงานดาวน์สตรีม เช่น การจัดหมวดหมู่และรีเกรสชัน
เริ่มต้นด้วยการฝังใน AWS โดยการ สร้างบัญชีวันนี้
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages