AWS Türkçe Blog
Amazon Athena ile Amazon MSK’de gerçek zamanlı akış verilerini analiz edin
Orijinal makale: Link (Scott Rigney ve Kiran Matty)
Kullanım kolaylığı ve ölçeklenebilirlik konusundaki son gelişmeler, akış verilerinin oluşturulmasını ve gerçek zamanlı karar verme için kullanılmasını kolaylaştırdı. İşletmeleri sektördeki değişikliklere daha hızlı tepki vermeye zorlayan piyasa güçleriyle birleştiğinde, günümüzde giderek daha fazla kuruluş inovasyonu ve çevikliği artırmak için veri akışına yöneliyor.
Amazon Managed Streaming for Apache Kafka (MSK), yüksek performanslı veri hatları, akış analitiği, veri entegrasyonu ve görev açısından kritik uygulamalar için tasarlanmış açık kaynaklı bir dağıtılmış olay akış platformu olan Apache Kafka‘yı kullanan, uygulamaları oluşturmayı ve çalıştırmayı kolaylaştıran, tümüyle yönetilen bir hizmettir. Amazon MSK ile veritabanı değişiklik olayları veya web uygulaması kullanıcı tıklama akışları gibi çok çeşitli kaynaklardan gerçek zamanlı veriler yakalayabilirsiniz. Kafka, yeni verileri yazmak ve okumak için yüksek düzeyde optimize edildiğinden, operasyonel raporlama için çok uygundur. Bununla birlikte, bu verilerden içgörü elde etmek, akış kayıtlarını Amazon QuickSight gibi araçları kullanarak tarihsel analiz ve görselleştirme için analistler, veri bilimcileri ve veri mühendisleri tarafından erişilebilen Amazon S3 gibi bir depolama ortamına yazmak için genellikle özel bir akış işleme katmanı gerektirir.
Verileri bulundukları yerde ve ayrı işlem hatları ve işler geliştirmeden analiz etmek istediğinizde popüler bir seçim Amazon Athena‘dır. Athena ile, yeni bir dil öğrenmeden, verileri ayıklamak (ve çoğaltmak) için komut dosyaları geliştirmeden veya altyapıyı yönetmeden çok çeşitli veri kaynaklarından öngörüler elde etmek için mevcut SQL bilginizi kullanabilirsiniz. Athena, veri analistlerine, veri mühendislerine ve veri bilimcilere Amazon S3’de depolanan verilerin yanı sıra şirket içinde veya bulutta çalışan veritabanlarında depolanan veriler üzerinde SQL sorguları çalıştırma esnekliği sağlayan Amazon DynamoDB ve Amazon Redshift dahil olmak üzere popüler veri kaynaklarına yönelik 25’in üzerinde bağlayıcıyı destekler. Athena ile veri hareketi yoktur ve yalnızca çalıştırdığınız sorgular için ödeme yaparsınız.
Yenilikler
Bugünden itibaren, artık MSK ve kendi yönettiğiniz Apache Kafka’da akış verilerini sorgulamak için Athena’yı kullanabilirsiniz. Bu, Kafka konularında (topics) tutulan gerçek zamanlı veriler üzerinde analitik sorgular çalıştırmanıza ve bu verileri diğer Kafka konularının yanı sıra Amazon S3 veri gölünüzdeki diğer verilerle birleştirmenize olanak tanır. Bunların hepsini önce verileri Amazon S3’de depolamak için ayrı süreçlere ihtiyaç duymadan gerçekleştirebilirsiniz.
Çözüme genel bakış
Bu gönderide, size Athena’yı ve onun MSK bağlayıcısını (connector) kullanarak gerçek zamanlı SQL analitiğine nasıl başlayacağınızı gösteriyoruz. Süreç şunları içerir:
- AWS Glue Schema Registry ile akış verilerinizin şemasını kaydetme. Schema Registry, akış verilerini JSON şemalarına göre doğrulamanıza ve güvenilir bir şekilde geliştirmenize olanak tanıyan bir AWS Glue özelliğidir. Ayrıca verileri sıkıştırılmış bir biçimde seri hale getirebilir, bu da veri aktarımı ve depolama maliyetlerinden tasarruf etmenize yardımcı olur.
- Amazon Athena MSK Connector için yeni bir sunucu oluşturma. Athena bağlayıcıları, sunucusuz AWS Lambda uygulamaları olarak çalışan önceden oluşturulmuş uygulamalardır, dolayısıyla bağımsız veri dışa aktarma işlemlerine gerek yoktur.
- Kafka konularınızla ilgili etkileşimli SQL sorguları çalıştırmak için Athena konsolunu kullanma.
Athena’nın Amazon MSK için bağlayıcısını kullanmaya başlayın
Bu bölümde, MSK kümenizi Athena ile çalışacak ve Kafka konularınızda SQL sorguları çalıştıracak şekilde ayarlamak için gerekli adımları ele alacağız.
Önkoşullar
Bu gönderi, üreten bir uygulamadan akış iletileri almak üzere ayarlanmış, sunucusuz veya sunucuda çalışan bir MSK kümeniz olduğunu varsayar. Bilgi için Amazon Yönetilen Akış için Apache Kafka Geliştirici Kılavuzu’ndaki Setting up Amazon MSK ve Getting started using Amazon MSK bölümlerine bakın.
Ayrıca MSK için Athena bağlayıcısını kullanmadan önce bir VPC ve güvenlik grubu kurmanız gerekir. Daha fazla bilgi için bkz. Creating a VPC for a data source connector. MSK Serverless ile VPC’lerin ve güvenlik gruplarının otomatik olarak oluşturulduğunu, böylece hızlı bir şekilde başlayabileceğinizi unutmayın.
AWS Glue Schema Registry ile Kafka konularınızın şemasını tanımlayın
Kafka konularınızda SQL sorguları çalıştırmak için öncelikle konularınızın şemasını tanımlamanız gerekir. Çünkü Athena, sorgu planlaması için bu meta verileri kullanır. AWS Glue, akışlı veri kaynakları için Schema Registry özelliğiyle bunu yapmayı kolaylaştırır.
Schema Registry, Athena gibi analitik uygulamalarında kullanım için akış veri şemalarını merkezi olarak keşfetmenize, kontrol etmenize ve geliştirmenize olanak tanır. AWS Glue Schema Registry ile, Apache Kafka ile uygun entegrasyonları kullanarak veri akışı uygulamalarınızda şemaları yönetebilir ve uygulayabilirsiniz. Daha fazla bilgi edinmek için AWS Glue Schema Registry ve Getting started with Schema Registry bölümlerine bakın.
Bunu yapacak şekilde yapılandırılırsa, veri üreticisi şemasını otomatik olarak kaydedebilir ve AWS Glue ile şemada değişiklik yapabilir. Bu, özellikle veri içeriğinin zaman içinde değişebileceği kullanım durumlarında kullanışlıdır. Ancak şemayı aşağıdaki JSON yapısına benzer şekilde manuel olarak da belirleyebilirsiniz.
Schema Registry kurarken, customer_schema gibi hatırlaması kolay bir ad verdiğinizden emin olun çünkü daha sonra göreceğiniz gibi SQL sorguları içinde ona başvuracaksınız. Son olarak, Schema Registry’nin Description alanına şu metni eklediğinizden emin olun: {AthenaFederationMSK}.
Şema kurulumu hakkında ek bilgi için AWS Glue Schema Registry için şema örneklerine bakın.
MSK için Athena bağlayıcısını yapılandırma
Şemanız Glue’da kayıtlıyken bir sonraki adım, MSK için Athena bağlayıcısını ayarlamaktır. Bu adım için Athena konsolunu kullanmanızı öneririz. İlgili adımlarla ilgili daha fazla bilgi için bkz. Deploying a connector and connecting to a data source.
Athena’da birleştirilmiş veri kaynağı bağlayıcıları, AWS Lambda üzerinde çalışan ve hedef veri kaynağınız ile Athena arasındaki iletişimi yöneten uygulamalardır. Birleştirilmiş bir kaynakta bir sorgu çalıştığında, Athena Lambda işlevini çağırır ve sorgunuzun o kaynağa özgü kısımlarını çalıştırma görevini ona verir. Sorgu yürütme iş akışı hakkında daha fazla bilgi edinmek için Amazon Athena Kullanıcı Kılavuzu’ndaki Using Amazon Athena Federated Query bölümüne bakın.
Athena konsoluna erişerek ve sol gezinme panelinde Data sources (Veri kaynakları) seçerek başlayın, ardından Create data source (Veri kaynağı oluşturun) seçin:

Ardından, mevcut bağlayıcılar arasından Amazon MSK’i arayıp seçin ve Next seçin.

Data source details (Veri kaynağı ayrıntıları) kısmında, bağlayıcınıza msk gibi, hatırlaması ve gelecekteki SQL sorgularınızda başvurması kolay bir ad verin. Connection details (Bağlantı ayrıntıları) bölümünde Create Lambda function (Lambda işlevi oluştur) seçin. Bu sizi ek yapılandırma özellikleri sağlayacağınız AWS Lambda konsoluna götürecektir.
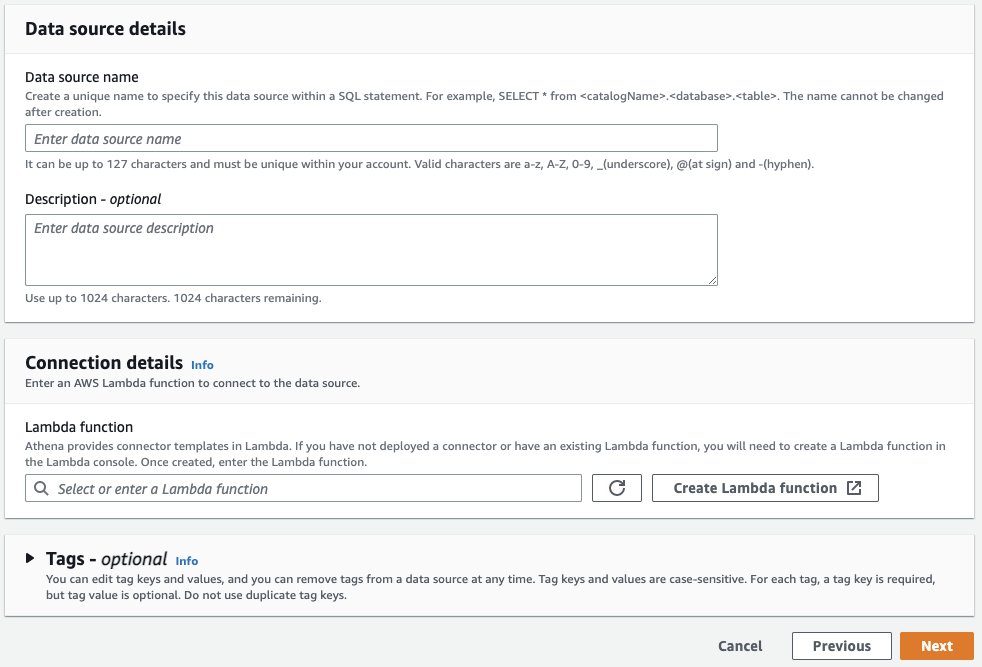
Lambda uygulama yapılandırma ekranında (burada gösterilmemiştir), bağlayıcınız için Application settings (Uygulama ayarlarını) sağlarsınız. Bunu yapmak için MSK kümenizden birkaç özelliğe ve Glue’da kayıtlı şemaya ihtiyacınız olacak.
Başka bir tarayıcı sekmesinde, MSK kümenize gitmek için MSK konsolunu kullanın ve ardından Properties (Özellikler) sekmesini seçin. Burada, Athena bağlayıcısının Application settings formundaki SubnetIds ve SecurityGroupIds alanlarında sağlayacağınız MSK kümenizdeki VPC alt ağlarını ve güvenlik grubu kimliklerini göreceksiniz. View client information (Müşteri bilgilerini görüntüle) tıklayarak KafkaEndpoint değerini bulabilirsiniz.
Bunları ve diğer gerekli değerleri sağladıktan sonra Deploy‘a tıklayın. Athena konsoluna dönün ve az önce oluşturduğunuz Lambda işlevinin adını Connection details (Bağlantı ayrıntıları) kutusuna girin, ardından Create data source (Veri kaynağı oluştur) tıklayın.
Athena’yı kullanarak akış verileri üzerinde sorgular çalıştırın
MSK veri bağlayıcı kurulumunuzla, artık veriler üzerinde SQL sorguları çalıştırabilirsiniz. Birkaç kullanım durumunu daha ayrıntılı olarak inceleyelim.
Kullanım örneği: etkileşimli analiz
MSK verilerinizi toplayan, gruplandıran veya filtreleyen sorgular çalıştırmak istiyorsanız, Athena’yı kullanarak etkileşimli sorgular çalıştırabilirsiniz. Bu sorgular, sorgunun gönderildiği andaki Kafka konularınızın mevcut durumuna göre çalışacaktır.
Before running any queries, it may be helpful to validate the schema and data types available within your Kafka topics. To do this, run the DESCRIBE command on your Kafka topic, which appears in Athena as a table, as shown below. In this query, the orders table corresponds to the topic you specified in the Schema Registry.
Herhangi bir sorgu çalıştırmadan önce, Kafka konularınızdaki şema ve veri türlerini doğrulamanız yararlı olabilir. Bunun için Athena’da tablo halinde görünen Kafka konunuz üzerinde aşağıda gösterildiği gibi DESCRIBE komutunu çalıştırın. Bu sorguda, orders tablosu, Schema Registry’de belirttiğiniz konuya karşılık gelir.
Artık konunuzun içeriğini bildiğinize göre, analitik sorgular geliştirmeye başlayabilirsiniz. E-ticaret sipariş verilerini içeren varsayımsal bir Kafka konusu için örnek bir sorgu aşağıda gösterilmiştir:
orders tablosu (ve temel alınan Kafka konusu) sınırsız bir veri akışı içerebileceğinden, yukarıdaki sorgu, sorgunun her yürütülmesinde büyük olasılıkla SUM(order_total) için farklı bir değer döndürür.
Bir konuda başka bir konuyla birleştirmeniz gereken verileriniz varsa, bunu da yapabilirsiniz:
Kullanım örneği: akış verilerini Amazon S3’deki bir tabloya alma
Birleşik sorgular, yukarıdakiler gibi etkileşimli sorguların verilerinizin mevcut durumuna göre değerlendirilmesini sağlayan temel veri kaynağına karşı çalışır. Göz önünde bulundurulması gereken noktalardan biri, art arda çalıştırılan birleşik sorguların, temel alınan kaynağa ek yük getirebileceğidir. Aynı kaynak veriler üzerinde birden çok sorgu gerçekleştirmeyi planlıyorsanız, bir SELECT sorgusunun sonuçlarını Amazon S3’deki bir tabloda depolamak için Athena’nın CTAS olarak da bilinen CREATE TABLE AS SELECT özelliğini kullanabilirsiniz. Ardından, her seferinde temel kaynağa geri dönmeden yeni oluşturduğunuz tablonuzda sorgular çalıştırabilirsiniz.
Bu veriler üzerinde, örneğin Amazon QuickSight’taki panolarda ek aşağı akış analizi yapmayı planlıyorsanız tablonuza düzenli olarak yeni veriler ekleyerek yukarıdaki çözümü geliştirebilirsiniz. Daha fazla bilgi edinmek için ETL ve veri analizi için CTAS ve INSERT INTO kullanma bölümüne bakın. Bu yaklaşımın diğer bir avantajı da, tablonuza yalnızca yetkili kullanıcıların erişebilmesini sağlamak için AWS Lake Formation tarafından desteklenen satır, sütun ve tablo düzeyinde veri yönetimi politikalarıyla bu tabloları güvenceye alabilmenizdir.
Başka ne yapabilirsiniz?
Athena ile, yeni bir dil öğrenmeden, verileri ayıklamak (ve çoğaltmak) için komut dosyaları geliştirmeden veya altyapıyı yönetmeden çok çeşitli veri kaynaklarından içgörüler oluşturan birleştirilmiş sorgular çalıştırmak için mevcut SQL bilginizi kullanabilirsiniz. Athena, verilerinizle çok daha fazlasını yapmanıza olanak tanıyan diğer AWS hizmetleri ve popüler analiz araçları ve SQL IDE’leri ile ek entegrasyonlar sağlar. Örneğin şunları yapabilirsiniz:
- Amazon QuickSight gibi iş zekası uygulamalarındaki verileri görselleştirme
- Athena’nın AWS Step Functions entegrasyonuyla olay odaklı veri işleme iş akışları tasarlama
- Amazon SageMaker‘da makine öğrenimine yönelik zengin girdi özellikleri oluşturmak için birden çok veri kaynağını birleştirme
Sonuç
Bu gönderide, Amazon MSK için yeni çıkan Athena bağlayıcısını öğrendik. Bununla birlikte, MSK veya kendi yönettiğiniz Apache Kafka’da çalışan Kafka konularında tutulan veriler üzerinde etkileşimli sorgular çalıştırabilirsiniz. Bu, panolara gerçek zamanlı içgörüler getirmenize veya zamana duyarlı işle ilgili soruları yanıtlamak için akış verilerinin belirli bir zamanda analizini etkinleştirmenize yardımcı olur. Ayrı bir havuz işlemine ihtiyaç duymadan yeni akış verilerinin Amazon S3’ye düzenli aralıklarla nasıl alınacağını da ele aldık. Bu, temel Kafka kümelerinize gidiş-dönüş sorgularına gerek kalmadan verilerinizin yinelenen analizini basitleştirir ve Lake Formation tarafından desteklenen erişim kurallarıyla verilerin güvenliğini sağlamayı mümkün kılar.
Bir sonraki analitik projenizde Athena ve birleştirilmiş sorguları değerlendirmenizi öneririz. Başlarken yardım için aşağıdaki kaynakları tavsiye ederiz:
- Athena’da yeniyseniz ve özellikleri ile yetenekleri hakkında daha fazla bilgi edinmek istiyorsanız Amazon Athena özelliklerine bakın.
- Athena’nın MSK için bağlayıcısı hakkında daha fazla bilgi edinmek için Amazon Athena MSK Bağlayıcısı‘na bakın.
- Desteklenen veri kaynaklarının tam listesi için bkz. Athena Veri Kaynağı Bağlayıcıları.