AWS Türkçe Blog
Üretken yapay zeka uygulamalarında vektör veri depolarının rolü
Orijinal makale: Link (G2 Krishnamoorthy, Rahul Pathak ve Vlad Vlasceanu)
Üretken Yapay Zeka hayal gücümüzü ele geçirdi ve soruları yanıtlama, hikayeler yazma, sanat yaratma ve hatta kod üretme becerisiyle sektörleri dönüştürüyor. AWS müşterileri, kendi işletmelerinde üretken yapay zekadan en iyi şekilde nasıl yararlanabileceklerini bize giderek daha fazla soruyor. Çoğu, kendi işlerine ve daha geniş sektöre benzersiz ve değerli bir bakış açısı sağlayan, alana özgü zengin bir veri birikimine (finansal kayıtlar, sağlık kayıtları, genomik veriler, tedarik zinciri vb.) sahiptir. Bu özel veriler, üretken yapay zeka stratejiniz için bir avantaj ve farklılaştırıcı olabilir.
Aynı zamanda, birçok müşteri, üretken yapay zeka uygulamalarında kullanılan vektör veri depolarının veya vektör veritabanlarının popülaritesindeki artışı fark etti ve bu çözümlerin üretken yapay zeka uygulamaları etrafındaki genel veri stratejilerine nasıl uyduğunu merak ediyor. Bu yazıda, vektör veritabanlarının üretken yapay zeka uygulamalarındaki rolünü ve AWS çözümlerinin üretken yapay zekanın gücünden yararlanmanıza nasıl yardımcı olabileceğini açıklıyoruz.
Üretken yapay zeka uygulamaları
Her üretken yapay zeka uygulamasının merkezinde büyük bir dil modeli (LLM) yer alır. LLM, internet üzerinden erişilebilen tüm içerikler gibi geniş bir içerik bütünü üzerinde eğitilmiş bir makine öğrenimi (ML) modelidir. Büyük miktarda kamuya açık veri üzerinde eğitilen LLM’ler temel modeller (FM’ler) olarak kabul edilir. Çok çeşitli kullanım durumları için uyarlanabilir ve ince ayar yapılabilir. Amazon SageMaker JumpStart, bir metin istemi kullanarak fotogerçekçi görüntüler oluşturabilen Stability AI’nın Text2Image modeli veya metin üretimi için Hugging Face’in Text2Text Flan T-5 modeli gibi üzerine inşa edebileceğiniz çeşitli önceden eğitilmiş, açık kaynaklı ve tescilli temel modeller sunar. FM’lerle üretken yapay zeka uygulamaları oluşturmanın ve ölçeklendirmenin en kolay yolu olan Amazon Bedrock, AI21 Labs, Anthropic, Stability AI ve Amazon Titan‘ın modellerini bir API aracılığıyla erişilebilir hale getiriyor.
Tamamen bir FM’e dayanan üretken bir yapay zeka uygulaması geniş gerçek dünya bilgisine erişebilecek olsa da, alana özgü veya uzmanlaşmış konularda doğru sonuçlar üretmek için özelleştirilmesi gerekir. Ayrıca, etkileşim ne kadar özelleşirse halüsinasyonlar (doğruluktan yoksun ancak güvenle doğru görünen sonuçlar) daha sık görülür. Peki, üretken yapay zeka uygulamanızı etki alanına özgü hale getirmek için nasıl özelleştirebilirsiniz?
Vektör veri depolarını kullanarak etki alanı özgüllüğü ekleme
Sufle mühendisliği (bağlam içi öğrenme olarak da adlandırılır), üretken yapay zeka uygulamanızı alanınıza özgü bağlama oturtmanın ve doğruluğu artırmanın en kolay yolu olabilir. Halüsinasyonları tamamen ortadan kaldırmasa da, bu teknik semantik anlam spektrumunu kendi alanınıza indirgeyecektir.
FM, özünde, bir dizi girdi belirtecine dayalı olarak bir sonraki belirteci çıkarır. Bu durumda bir belirteç, metin oluşturmada bir kelime veya kelime öbeği gibi semantik anlamı olan herhangi bir ögeyi ifade eder. Bağlamla ilgili ne kadar çok girdi sağlarsanız, çıkarılan bir sonraki belirtecin de bağlamla ilgili olma olasılığı o kadar yüksek olur. FM’i sorguladığınız istem, girdi belirteçlerini ve mümkün olduğunca bağlamla ilgili verileri içerir.
Bağlamsal veriler genellikle etki alanına özgü verilerinizi barındıran sistemler olan dahili veritabanlarınızdan veya veri göllerinizden gelir. Bu veri depolarından basitçe alana özgü ek veriler ekleyerek istemleri zenginleştirebilseniz de vektör veri depoları, istemlerinizi anlamsal olarak ilgili girdilerle tasarlamanıza yardımcı olur. Bu yönteme Retrieval Augmented Generation (RAG) adı verilir. Pratikte, kullanıcı profili bilgileri gibi hem bağlamsal olarak kişiselleştirilmiş veriler hem de anlamsal olarak benzer veriler içeren bir istem tasarlamanız muhtemeldir.
Üretken yapay zeka kullanımı için, alana özgü verileriniz, her biri dahili olarak bir vektör olarak ifade edilen bir dizi öge olarak kodlanmalıdır. Vektör, bir dizi boyutta (sayı dizisi) bir dizi sayısal değer içerir. Aşağıdaki şekilde bağlam verilerinin anlamsal ögelere ve ardından vektörlere dönüştürülmesine ilişkin bir örnek gösterilmektedir.
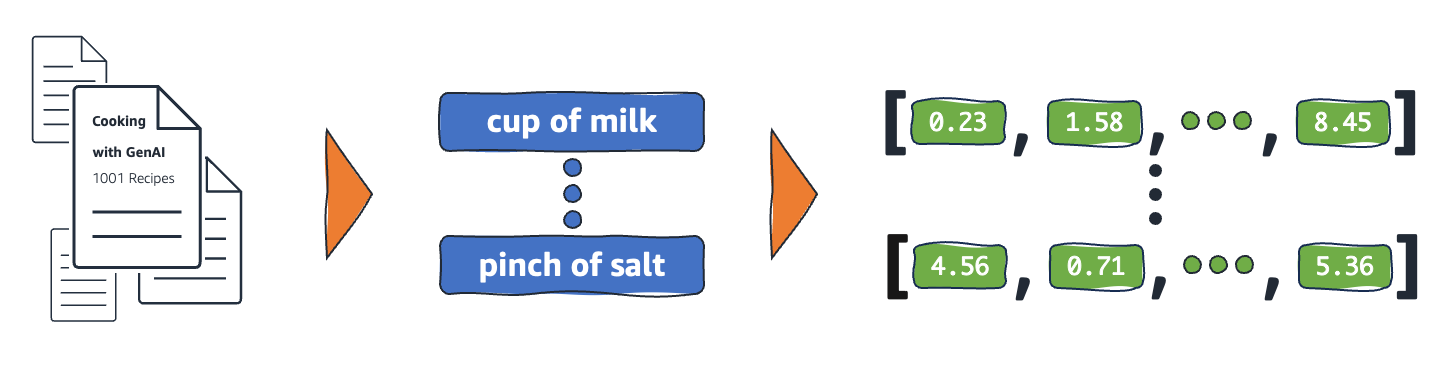
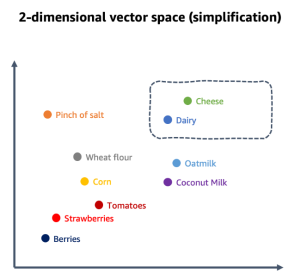
Bu sayısal değerler, çok boyutlu bir vektör uzayında ögeleri birbirleriyle ilişkili olarak haritalamak için kullanılır. Vektör ögeleri anlamsal olduğunda (bir anlam biçimini temsil ettiklerinde), yakınlık bağlamsal ilişki için bir gösterge haline gelir. Bu şekilde kullanıldığında, bu tür vektörler gömme (embeddings) olarak adlandırılır. Örneğin, “Peynir” için anlamsal öge, bakkaliye veya yemek pişirme veri alanı bağlamını temsil eden çok boyutlu bir uzayda “Süt Ürünleri” için anlamsal ögeye yakın yerleştirilebilir. Özel etki alanı bağlamınıza bağlı olarak, anlamsal bir öge bir kelime, ifade, cümle, paragraf, tüm belge, görüntü veya tamamen başka bir şey olabilir. Etki alanına özgü veri kümenizi birbiriyle ilişkilendirilebilen anlamlı ögelere ayırırsınız. Örneğin, aşağıdaki şekilde yemek pişirme bağlamı için basitleştirilmiş bir vektör uzayı gösterilmektedir.
Sonuç olarak, istem için ilgili bağlamı üretmek için bir veritabanını sorgulamanız ve vektör uzayında girdilerinizle yakından ilişkili ögeleri bulmanız gerekir. Vektör veri deposu, verimli en yakın komşu (nearest neighbor) sorgu algoritmaları ve veri alımını iyileştirmek için uygun dizinlerle vektörleri büyük ölçekte depolamanıza ve sorgulamanıza olanak tanıyan bir sistemdir. Vektörle ilgili bu yeteneklere sahip herhangi bir veritabanı yönetim sistemi bir vektör veri deposu olabilir. Yaygın olarak kullanılan birçok veritabanı sistemi, bu vektör yeteneklerini diğer işlevleriyle birlikte sunar. Alana özgü veri kümelerinizi vektör özelliklerine sahip bir veritabanında depolamanın bir avantajı, vektörlerinizin kaynak verilere yakın bir yerde bulunmasıdır. Harici veritabanlarını sorgulamak zorunda kalmadan vektör verilerini ek meta verilerle zenginleştirebilir ve veri işleme hatlarınızı basitleştirebilirsiniz.
Vektör veri depolarını hızlı bir şekilde kullanmaya başlamanıza yardımcı olmak için bugün, genel kullanıma sunulduğunda milyarlarca gömmeyi depolamak ve sorgulamak için basit bir API sağlayan Amazon OpenSearch Serverless için vektör motorunu duyurduk. Bununla birlikte, zaman içinde tüm AWS veritabanlarının vektör özelliklerine sahip olacağını düşünüyoruz, çünkü bu işlemlerinizi ve veri entegrasyonunuzu basitleştirir. Ayrıca, daha gelişmiş vektör veri deposu ihtiyaçları için aşağıdaki seçenekler mevcuttur:
- pgvector açık kaynak vektör benzerlik arama uzantısına sahip bir Amazon Aurora PostgreSQL Uyumlu Sürüm ilişkisel veritabanı
- Amazon OpenSearch Serverless için k-NN (k-en yakın komşu) eklentisi ve vektör motoru ile dağıtılmış bir arama ve analiz hizmeti olan Amazon OpenSearch Service
- pgvector uzantılı PostgreSQL için Amazon Relational Database Service (Amazon RDS) ilişkisel veritabanı
Gömmeler kaynak verilerinize yakın bir yerde saklanmalıdır. Sonuç olarak, verilerinizi bugün nerede depoladığınızın yanı sıra bu veritabanı teknolojilerine aşinalık, vektör boyutları açısından ölçek, gömme sayısı ve performans ihtiyaçları hangi seçeneğin sizin için doğru olduğunu belirleyecektir. Bu seçenekler için daha spesifik kılavuzlara geçmeden önce, RAG’nin nasıl çalıştığını ve RAG’de vektör veri depolarını nasıl uyguladığınızı anlayalım.
RAG için vektör veri depolarını kullanma
Üretken yapay zeka uygulamanızın doğruluğunu artırmak için gömmeleri (vektörleri) kullanabilirsiniz. Aşağıdaki diyagram bu veri akışını göstermektedir.
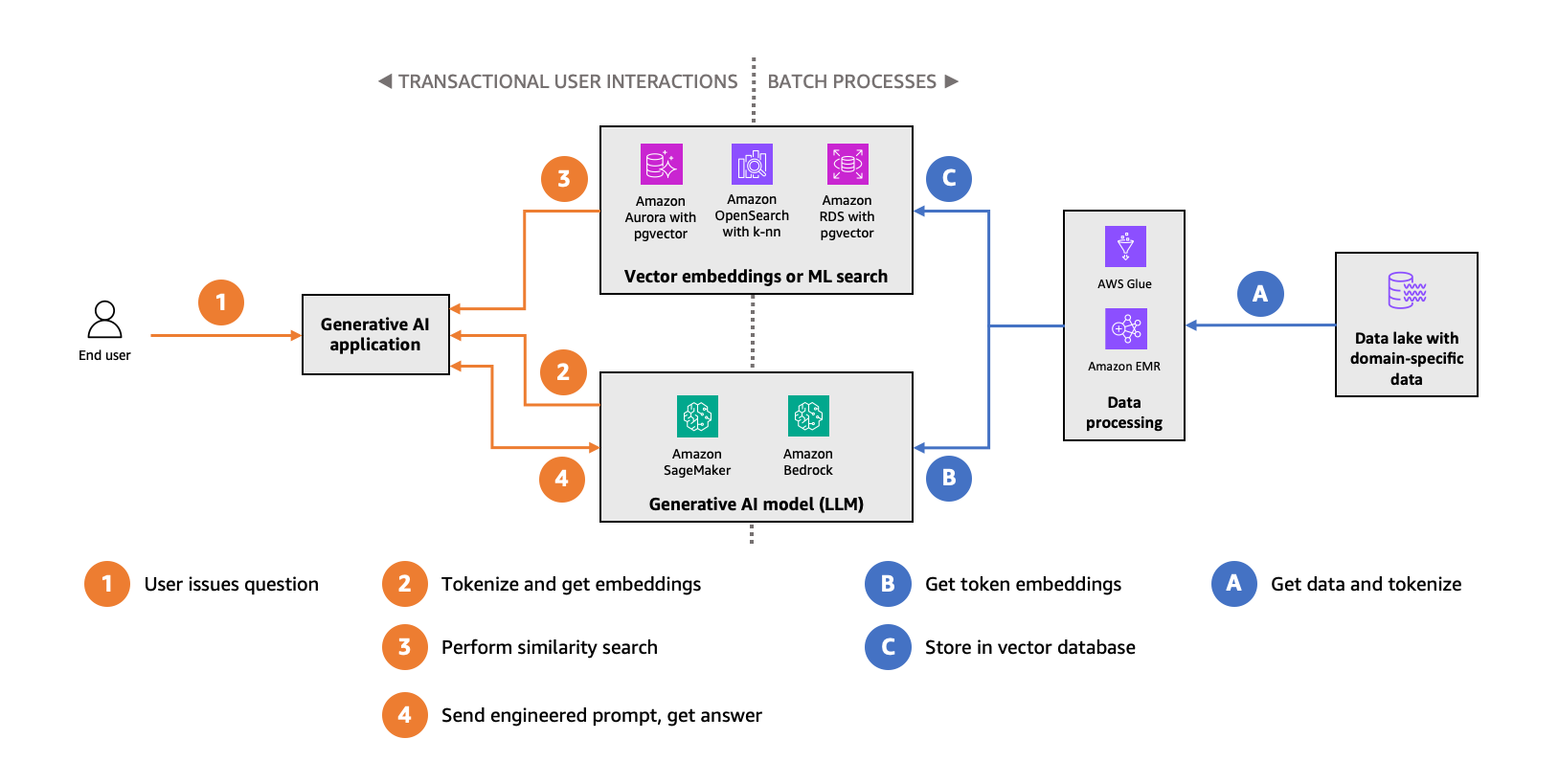
Alana özgü veri setinizi alırsınız (önceki şeklin sağ tarafı, mavi ile gösterilmiştir), onu anlamsal ögelere ayırırsınız ve bu anlamsal ögelerin vektörlerini hesaplamak için FM’i kullanırsınız. Daha sonra bu vektörleri, benzerlik araması yapmanızı sağlayacak bir vektör veri deposunda depolarsınız.
Üretken yapay zeka uygulamanızda (önceki şeklin sol tarafı, turuncu ile gösterilmiştir), son kullanıcı tarafından sağlanan soruyu alır, veri kümenizde kullanılan aynı algoritmayı kullanarak anlamsal ögelere ayırır (tokenization) ve giriş ögeleri için vektör uzayında en yakın komşular için vektör veri deposunu sorgularsınız. Depo size bağlamsal olarak benzer anlamsal ögeler sunacak ve siz de bunları tasarlanmış isteminize ekleyeceksiniz. Bu süreç, LLM’i etki alanınıza özgü bağlama daha da oturtarak LLM çıktısının doğru ve bu bağlamla ilgili olma olasılığını artıracaktır.
Vektör veri deponuzda, son kullanıcıların kritik yolunda benzerlik aramaları gerçekleştirmek için eş zamanlı okuma sorguları kullanılır. Vektör veri deposunu gömmelerle doldurmak ve veri değişikliklerini takip etmek için yapılan toplu işlemler çoğunlukla vektör veri deposuna veri yazar. Bu kullanım modelinin yönleri ile aşinalık ve ölçek gibi daha önce belirtilen hususlar, hangi hizmetin -Aurora PostgreSQL Uyumlu, OpenSearch Service, OpenSearch Serverless için vektör motoru veya PostgreSQL için Amazon RDS- sizin için doğru olduğunu belirler.
Vektör veri deposu ile ilgili önemli noktalar
Tanımladığımız kullanım şekli, vektör veri depoları için bazı benzersiz ve önemli hususlara da yol açmaktadır.
Kullanmak istediğiniz alana özgü verilerin hacmi ve bu verileri anlamsal ögelere ayırmak için kullandığınız işlem, vektör veri deponuzun desteklemesi gereken gömme sayısını belirleyecektir. Alana özgü verileriniz zaman içinde büyüdükçe ve değiştikçe, vektör veri deponuzun da bu büyümeye uyum sağlaması gerekir. Bu, indeksleme verimliliği ve ölçekte performans üzerinde etkiye sahiptir. Alana özgü veri kümelerinin yüz milyonlarca, hatta milyarlarca gömmeyle sonuçlanması alışılmadık bir durum değildir. Verileri bölmek için bir tokenizer kullanırsınız ve Natural Language Toolkit (NLTK) kullanabileceğiniz birkaç genel amaçlı tokenizer sağlar. Ancak alternatifleri de kullanabilirsiniz. Nihayetinde, doğru tokenizer, etki alanınıza özgü veri kümenizdeki anlamsal ögenin ne olduğuna bağlıdır – daha önce de belirtildiği gibi, bu bir kelime, kelime öbeği, metin paragrafı, tüm belge veya verilerinizin bağımsız anlam taşıyan herhangi bir alt bölümü olabilir.
Gömme vektörleri için boyut sayısı dikkate alınması gereken bir diğer önemli faktördür. Farklı FM’ler farklı sayıda boyuta sahip vektörler üretir. Örneğin, all-MiniLM-L6-v2 modeli 384 boyutlu vektörler üretirken Falcon-40B vektörleri 8.192 boyuta sahiptir. Bir vektör ne kadar çok boyuta sahipse, bir noktaya kadar temsil edebileceği bağlam o kadar zengin olur. Sonunda azalan getiriler ve artan sorgu gecikmesi göreceksiniz. Bu da sonunda boyutsallık lanetine yol açar (nesneler seyrek ve birbirine benzemez görünür). Anlamsal benzerlik aramaları gerçekleştirmek için genellikle yoğun boyutluluğa sahip vektörlere ihtiyacınız vardır, ancak veritabanınızın bu tür aramaları verimli bir şekilde gerçekleştirmesi için gömmelerinizin boyutlarını azaltmanız gerekebilir.
Bir diğer husus da tam benzerlik arama sonuçlarına ihtiyacınız olup olmadığıdır. Vektör veri depolarındaki indeksleme özellikleri benzerlik aramasını önemli ölçüde hızlandıracaktır, ancak sonuç üretmek için yaklaşık en yakın komşu (ANN) algoritması da kullanacaklardır. ANN algoritmaları doğruluk karşılığında performans ve bellek verimliliği sağlar. Her seferinde tam en yakın komşuları döndürdüklerini garanti edemezler.
Son olarak, veri yönetişimini göz önünde bulundurun. Alana özgü veri kümeleriniz muhtemelen kişisel veriler veya fikri mülkiyet gibi son derece hassas veriler içerir. Vektör veri deponuzun mevcut etki alanına özel veri kümelerinize yakın olması sayesinde erişim, kalite ve güvenlik kontrollerinizi vektör veri deponuza genişletebilir ve işlemleri basitleştirebilirsiniz. Çoğu durumda, verilerin semantik anlamını etkilemeden bu tür hassas verileri ayıklamak mümkün olmayacaktır, bu da doğruluğu azaltır. Bu nedenle, gömmeleri oluşturan, depolayan ve sorgulayan sistemler aracılığıyla verilerinizin akışını anlamak ve kontrol etmek önemlidir.
PostgreSQL için Aurora PostgreSQL veya Amazon RDS’i pgvector ile kullanma
Açık kaynaklı, topluluk destekli bir PostgreSQL uzantısı olan Pgvector, hem Aurora PostgreSQL’de hem de PostgreSQL için Amazon RDS’te mevcuttur. Uzantı, PostgreSQL’i vector adı verilen bir vektör veri türü, benzerlik araması için üç sorgu operatörü (Öklidyen, negatif iç çarpım ve kosinüs mesafesi) ve daha hızlı yaklaşık mesafe aramaları gerçekleştirmek için vektörler için ivfflat (saklanan vektörlerle ters çevrilmiş dosya) indeksleme mekanizması ile genişletir. Vektörleri 16.000 boyuta kadar saklayabilmenize rağmen, benzerlik arama performansını artırmak için yalnızca 2.000 boyut indekslenebilir. Uygulamada, müşteriler daha az boyuta sahip gömmeleri kullanma eğilimindedir. Amazon SageMaker ve pgvector kullanarak PostgreSQL’de yapay zeka destekli arama oluşturma yazısı, bu uzantıyı daha derinlemesine incelemek için harika bir kaynaktır.
İlişkisel veritabanlarına, özellikle de PostgreSQL’e zaten yoğun bir şekilde yatırım yaptıysanız ve bu alanda çok fazla uzmanlığınız varsa, vektör veri deponuz için pgvector uzantılı Aurora PostgreSQL’i kullanmayı kesinlikle düşünmelisiniz. Ayrıca, yüksek düzeyde yapılandırılmış alana özgü veri kümeleri ilişkisel veritabanları için daha doğal bir uyumdur. PostgreSQL’in belirli topluluk sürümlerini kullanmanız gerekiyorsa PostgreSQL için Amazon RDS de harika bir seçim olabilir. Benzerlik arama sorguları (okumalar), Aurora tarafından tek bir DB kümesinde (15) ve Amazon RDS tarafından bir replikasyon zincirinde (15) desteklenen maksimum okuma replikası sayısına bağlı olarak yatay olarak da ölçeklenebilir.
Aurora PostgreSQL, DB sunucularınızın işlem ve bellek kapasitesini yüke göre otomatik olarak ayarlayabilen isteğe bağlı, otomatik ölçeklendirme yapılandırması olan Amazon Aurora Serverless v2‘yu da destekler. Bu yapılandırma işlemleri basitleştirir, çünkü artık çoğu kullanım durumunda en üst düzey için hazırlık yapmanız veya karmaşık kapasite planlaması yapmanız gerekmez.
Amazon Aurora Machine Learning (Aurora ML), SQL işlevleri aracılığıyla Amazon SageMaker‘da barındırılan ML modellerine çağrı yapmak için kullanabileceğiniz bir özelliktir. Doğrudan veritabanınızdan gömmler oluşturmak üzere FM’lerinize çağrı yapmak için kullanabilirsiniz. Bu çağrıları saklı yordamlar halinde paketleyebilir veya diğer PostgreSQL özellikleriyle entegre edebilirsiniz, böylece vektörleştirme işlemi uygulamadan tamamen soyutlanmış olur. Aurora ML’de yerleşik olarak bulunan gruplama özellikleri sayesinde, ilk vektör kümesini oluşturmak üzere dönüştürmek için ilk veri kümesini Aurora’dan dışa aktarmanız bile gerekmeyebilir.
OpenSearch Serverless için OpenSearch Service’i k-NN eklentisi ve vektör motoru ile kullanma
k-NN eklentisi, açık kaynaklı, dağıtılmış bir arama ve analiz paketi olan OpenSearch’ü özel knn_vector veri türü ile genişleterek, OpenSearch dizinlerinde gömmeleri saklamanıza olanak tanır. Eklenti ayrıca k-nearest neighbor benzerlik aramaları gerçekleştirmek için üç yöntem sağlar: Approximate k-NN, Script Score k-NN (kesin) ve Painless extensions (kesin). OpenSearch, Metrik Olmayan Uzay Kütüphanesi (NMSLIB) ve Facebook AI Research’ün FAISS kütüphanesini içerir. İhtiyaçlarınızı karşılayan en iyisini bulmak için mesafe için farklı arama algoritmaları kullanabilirsiniz. Bu eklenti OpenSearch Service’te de mevcuttur ve Amazon OpenSearch Service’in vektör veritabanı özelliklerinin açıklandığı yazı, bu özellikleri daha derinlemesine incelemek için harika bir kaynaktır.
OpenSearch’ün dağıtılmış yapısı nedeniyle, çok sayıda gömme içeren vektör veri depoları için mükemmel bir seçimdir. Dizinleriniz yatay olarak ölçeklendirilerek gömmeleri depolamak ve benzerlik aramaları yapmak için daha fazla verim elde etmenizi sağlar. Ayrıca, arama yapmak için kullanılan yöntem ve algoritmalar üzerinde daha derin kontrol sahibi olmak isteyen müşteriler için de mükemmel bir seçimdir. Arama motorları düşük gecikmeli, yüksek verimli sorgulama için tasarlanmıştır ve bunu başarmak için işlemsel davranıştan ödün verir.
OpenSearch Serverless, OpenSearch etki alanlarının sağlanması, yapılandırılması ve ayarlanmasına ilişkin operasyonel karmaşıklıkları ortadan kaldıran isteğe bağlı sunucusuz bir yapılandırmadır. Tek yapmanız gereken bir dizin koleksiyonu oluşturmak ve dizin verilerinizi doldurmaya başlamaktır. OpenSearch Serverless için yeni duyurulan vektör motoru, arama ve zaman serisi koleksiyonlarının yanı sıra yeni bir vektör koleksiyon türü olarak sunuluyor. Vektör benzerlik araması ile çalışmaya başlamanız için size kolay bir yol sunar. Makine öğrenimi veya vektör teknolojisinde gelişmiş uzmanlığa ihtiyaç duymadan, Amazon Bedrock’un hızlı mühendisliği üretken yapay zeka uygulamalarınıza entegre etmesi için kullanımı kolay bir eşleştirme sağlar. Vektör motoruyla, vektör katıştırmalarını, meta verileri ve açıklayıcı metni tek bir API çağrısı içinde kolayca sorgulayabilir, böylece uygulama yığınınızdaki karmaşıklığı azaltırken daha doğru arama sonuçları elde edebilirsiniz.
OpenSearch’teki k-NN eklentili vektörler, nmslib ve faiss motorlarını kullanırken 16.000 boyuta kadar ve Lucene motoruyla 1.024 boyutu destekler. Lucene, vektör aramasının yanı sıra OpenSearch’ün temel arama ve analiz yeteneklerini de sağlar. OpenSearch, benzerlik aramaları da dahil olmak üzere çoğu işlem için özel bir REST API kullanır. OpenSearch dizinleriyle etkileşim kurarken daha fazla esneklik sağlarken, dağıtılmış web tabanlı uygulamalar oluşturmak için becerileri yeniden kullanmanıza olanak tanır.
OpenSearch, anlamsal benzerlik aramasını anahtar kelime arama kullanım durumlarıyla birleştirmeniz gerekiyorsa da harika bir seçenektir. Üretken yapay zeka uygulamaları için sufle mühendisliği, hem bağlamsal verilerin alınmasını hem de RAG’yi içerir. Örneğin, bir müşteri destek temsilcisi uygulaması, aynı anahtar kelimelere sahip önceki destek vakalarının yanı sıra anlamsal olarak benzer olan destek vakalarını da dahil ederek bir istem oluşturabilir, böylece önerilen çözüm uygun bağlama dayandırılır.
Neural Search eklentisi (deneysel), makine öğrenimi dil modellerinin doğrudan OpenSearch iş akışlarınıza entegre edilmesini sağlar. Bu eklenti ile OpenSearch, alım ve arama sırasında sağlanan metin için otomatik olarak vektörler oluşturur. Daha sonra arama sorguları için vektörleri sorunsuz bir şekilde kullanır. Bu, RAG’de kullanılan benzerlik arama görevlerini basitleştirebilir.
Ayrıca, alana özgü veriler üzerinde tam olarak yönetilen bir anlamsal arama deneyimi tercih ediyorsanız, Amazon Kendra‘yı düşünmelisiniz. Amazon Kendra, metin çıkarma, pasaj bölme, gömme alma ve vektör veri depolarını yönetme gibi ek yükleri ortadan kaldırarak belge ve pasajların son teknoloji sıralaması için kullanıma hazır anlamsal arama özellikleri sunar. Anlamsal arama ihtiyaçlarınız için Amazon Kendra’yı kullanabilir ve sonuçları tasarlanmış isteminize paketleyebilir, böylece en az miktarda operasyonel ek yük ile RAG’nin faydalarını en üst düzeye çıkarabilirsiniz. Amazon Kendra, LangChain ve büyük dil modellerini kullanarak kurumsal veriler üzerinde hızlı bir şekilde yüksek doğrulukta Üretken Yapay Zeka uygulamaları oluşturun yazısı, bu kullanım durumu için daha derin bir rehberlik sağlar.
Son olarak, Aurora PostgreSQL ve pgvector ile PostgreSQL için Amazon RDS, OpenSearch Serverless için vektör motoru ve k-NN ile OpenSearch Service LangChain‘de desteklenmektedir. LangChain, LLM’lere dayalı veri farkındalıklı, temsilci tarzı uygulamalar geliştirmek için popüler bir Python çerçevesidir.
Özet
Gömmeler, alana özgü veri kümelerinize yakın bir yerde saklanmalı ve yönetilmelidir. Bunu yapmak, ek, harici veri kaynakları kullanmadan bunları ek meta verilerle birleştirmenize olanak tanır. Ayrıca verileriniz statik değildir, zaman içinde değişir ve gömmeleri kaynak verilerinizin yakınında saklamak, gömmeleri güncel tutmak için veri işlem hatlarınızı basitleştirir.
Aurora PostgreSQL ve pgvector ile PostgreSQL için Amazon RDS, ayrıca OpenSearch Serverless ve OpenSearch Service için k-NN eklentisine sahip vektör motoru, vektör veri deposu ihtiyaçlarınız için harika seçeneklerdir, ancak hangi çözümün sizin için doğru olduğu nihayetinde kullanım durumunuza ve önceliklerinize bağlı olacaktır. Tercih ettiğiniz veritabanının vektör yetenekleri yoksa, bu yazıda tartışılan seçenekler SQL ve NoSQL ile aşinalık spektrumunu kapsar ve çok fazla operasyonel ek yük olmadan kolayca alınabilir. Hangi seçeneği seçerseniz seçin, vektör veri deposu çözümünüzün uygulama tarafından gönderilen eş zamanlı verimi sürdürmesi gerekir. Benzerlik arama yanıt gecikmelerinin beklentilerinizi karşılaması için çözümünüzü tam bir yerleştirme setiyle ölçekli olarak doğrulayın.
Aynı zamanda, SageMaker JumpStart ve Amazon Bedrock tarafından sağlanan temel modellerle birlikte kullanılan hızlı mühendislik, önemli makine öğrenimi becerilerine yatırım yapmak zorunda kalmadan müşterilerinizi memnun edecek yenilikçi üretken yapay zeka çözümleri oluşturmanızı sağlayacaktır.
Son olarak, teknolojinin bu alanda hızla geliştiğini ve her şey değiştikçe rehberliğimizi güncellemek için her türlü çabayı göstereceğimizi unutmayın, ancak bu yazıdaki öneriler evrensel olarak geçerli olmayabilir.
AWS’te üretken yapay zeka uygulamaları oluşturmaya bugün başlayın! AWS’in daha hızlı inovasyon yapmanıza ve müşteri deneyimlerini yeniden keşfetmenize yardımcı olmak için sunduğu araçları ve özellikleri keşfedin.