資料科學與人工智慧有何差異?
資料科學和人工智能之間的相似之處
AI 和資料科學都包括分析和使用大量資料的工具、技術和演算法。以下是一些相似之處。
預測應用程式
人工智能和資料科學技術都是根據新資料進行預測,這是在應用在分析以前資料時學習到模型和方法的結果。例如,根據過去年資料預測未來的每月雨傘銷售是資料科學中的時間序列資料分析即是一個範例。
同樣地,自動駕駛汽車也是預測性人工智能系統的一個範例。當自動駕駛汽車上路時,它會計算與前方汽車的距離以及兩輛車的速度。根據預測前面車輛突然踩剎車的情況,它會維持行駛速度在避免碰撞的速度。
資料品質要求
如果訓練資料不一致、有偏見或不完整,AI 和資料科學技術都會給出不準確的結果。例如,資料科學和 AI 演算法可以:
- 如果新資料為全新,且不在原始資料集中,則過濾掉。
- 如果輸入資料缺少變化,則將資料集中的特定屬性優先於所有其他屬性。
- 建立不存在或虛構的資訊,因為輸入資料是假的。
機器學習
機器學習 (ML) 被認為是資料科學和 AI 的亞型。也就是說所有 ML 模型都被視為資料科學模型,所有 ML 演算法也被認為是 AI 演算法。有一個常見的誤解是所有 AI 都使用 ML,但事實並非如此。複雜的 AI 解決方案中並不總是需要 ML。同樣地,並非所有資料科學解決方案中都有使用 ML。
主要差異:資料科學與人工智能比較
資料科學包括分析資料以確定基礎模式和進行預測的興趣點。應用資料科學採用資料分析中使用的模型和方法,並將它們應用於現實情況中的新數據,以提供可能性輸出。相比之下,AI 使用應用資料科學技術和其他演算法來構建和進行近似人工智能的複雜機器為主的系統。
資料科學也可應用於 AI 和計算機科學以外的領域。
目標
資料科學的目標是應用現有的統計和計算模型與方法來了解所收集資料中的興趣點或模式。結果為預先決定的,且一開始就輕鬆定義。例如,您可以使用資料來預測未來的銷售,或辨別機器何時準備好進行維修。
AI 的目標是使用電腦從複雜的新資料產生與智能人類推理無法區分的結果。結果通用且難以定義。舉例來說,生成創意文字或從文字生成影像。問題集的細節過於龐大而無法準確定義,AI 系統會自行解釋問題。
範圍
由於結果是預先決定的,資料科學的範圍較小。該過程從辨識可以從資料回答的問題開始。範圍包括:
- 資料收集和預先處理。
- 將適當的模型和演算法應用於資料來回答這些問題。
- 解釋結果。
相比之下,AI 的範圍更廣,且步驟會依據解決的問題而有所不同。這個過程從辨識人類成功執行的勞力密集工作或複雜的推理任務開始進行,且我們希望機器能夠複製此過程。範圍可能包括:
- 探索資料分析。
- 將任務分為演算法元件以形成一個系統。
- 收集測試資料,藉此檢閱和精細化邏輯流程的合適性和系統的複雜性。
- 測試系統。

Methods
資料科學具有廣泛的資料建模技術。依據數據和提出的問題能夠選擇正確的技術。上述技術包括線性迴歸、邏輯迴歸、異常檢測、二進制分類、k-means 分群、主成分分析等更多。套用不正確的統計分析會產生意外的結果。
AI 應用程式通常仰賴複雜、預先建立的產品化元件。這些可能包括臉部辨識,自然語言處理,強化學習,知識圖譜,生成式人工智慧(生成式 AI)等更多。
應用:資料科學與人工智能比較
資料科學可以應用在有一定品質資料和模型來協助回答特定問題的任何地方。應用領域包括:
- 銷售需求預測。
- 詐騙偵測。
- 體育賠率。
- 風險評估。
- 能源消耗預測。
- 收入最佳化。
- 候選人篩選流程。
AI 的應用領域幾乎無止盡。熱門應用領域包括:
- 機器人生產線。
- 聊天機器人。
- 生物特徵辨識系統。
- 醫學成像分析。
- 預測性維護。
- 城市規劃。
- 行銷個人化。
職業:資料科學與人工智能比較
資料科學家的主要焦點是技術,讓他們能夠深入研究資料。資料科學家可以致力於收集和處理資料,為資料選擇合適的模型,以及解釋結果以提出建議。工作場域可能為特定軟體或系統,甚至自己建立系統。
角色類型
資料科學職位包括資料科學家、資料分析師、資料工程師、機器學習工程師、研究科學家、資料視覺化專家、領域特定分析師角色等。AI 也包括上述所有角色。然而,由於該領域的範圍如此廣泛,還有許多其他相關角色和工作重點領域,例如軟體開發人員、產品經理、行銷專家、AI 測試人員、AI 工程師等。
技能集
資料科學家具備統計實際應用和演算方法的技能,判斷符合資格的資料和分析資料以找到相關的見解。資料科學家需具備統計數學和計算機科學的背景,並精熟應用工具。
根據 AI 中的角色而定,所需的技能可能更以技術或軟技能為主。某些角色可能不需要技術經驗。例如,AI 軟體開發人員需要有關編程語言、庫和工具的實用知識。但是,生成式 AI 工具的 AI 測試人員則需要語言學技能、創造性思維,同時了解用戶與系統互動的方式。
職業進展
隨著資料科學工具和工作流程變得更加自動化和產品化,純資料科學角色的數量因此減少。尋求純資料科學角色的資料科學專業人員傾向於學術和最新應用。進行工具操作的資料科學家與分析師角色之間仍保有關聯性。從初階職位而言,資料科學家會取得更資深的職位,往人員或專案管理,甚至首席資料長的高階職位升遷。
根據 AI 角色本身的焦點,也可以預期類似的職業進展。您可能晉升為首席技術長、首席行銷長、首席產品長等。利用批判性思考判斷未來十年哪些職位將被自動化取代,可以幫助確保未來的職涯方向。
差異總結:資料科學與人工智能比較
|
資料科學 |
人工智慧 |
|
|
可以為我們說明嗎? |
使用統計及演算模型以便從資料中取得洞察。 |
廣義上用於描述模仿人類智慧的機器型應用程式的術語。 |
|
最適合 |
從一組資料中回答問題。 |
高效地完成複雜的人工任務。 |
|
Methods |
線性迴歸、邏輯迴歸、異常檢測、二進制分類、k-means 分群、主成分分析等。 |
臉部辨識,自然語言處理,強化學習,知識圖譜,生成式 AI 等。 |
|
範圍 |
可以從資料回答的預定義問題。 |
以任務為基礎,廣泛且難以定義。 |
|
實作 |
針對資料使用一系列不同的工具來擷取、清理、建模、分析和報告。 |
取決於任務。通常仰賴複雜、預先建立的產品化元件。 |
AWS 如何協助滿足資料科學和人工智慧需求?
AWS 提供全系列的資料科學以及 AI 產品和服務,旨在協助強化和發展組織和個人資料分析,以及智慧。
這包括用於結構性和非結構性資料的 API 資料科學和 AI 模型,以及可提供資料科學和 AI 解決方案端對端創建和部署的完全受管環境。
- Amazon SageMaker Studio 是一個整合式開發環境 (IDE),其中包括用於開發資料科學和 ML 解決方案的專用工具堆疊。
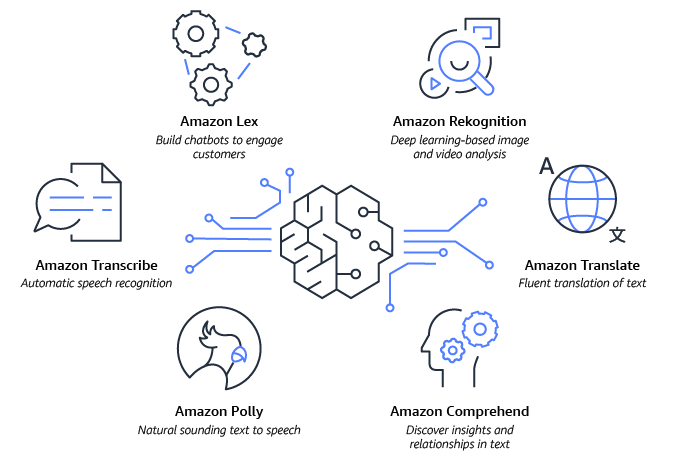
- Amazon Lex 可協助使用對話式 AI 建立自己的聊天機器人。
- Amazon Rekognition 提供預先訓練和可自訂的電腦視覺 (CV) 功能,可從您的影像和影片中擷取資訊和洞察。
- Amazon Comprehend 有助於從文件中的文字衍生並了解有價值的見解。
- Amazon Personalize 運用 ML 協助個人化客戶體驗。
- Amazon Forecast 有助於執行時間序列預測。
- Amazon Fraud Detector 可協助建立、部署和管理詐騙偵測模型。
AWS 還提供不斷增長的世界級生成式 AI 解決方案清單,這可建立新的內容和想法,包括對話、故事、影像、影片和音樂。生成式 AI 解決方案包括:
- Amazon Bedrock 協助組織建立和擴展生成式 AI 解決方案。
- AWS Trainium 有助於加快訓練生成式 AI 模型。
- Amazon Q Developer 是適用於軟體開發的生成式 AI 支援助理。
立即建立帳戶,開始使用 AWS 上的資料科學和人工智慧。
與 AWS 搭配使用的後續步驟
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages