亚马逊AWS官方博客
Amazon Redshift Spectrum 将数据仓库扩展到 EB 级别且无需加载
很多年前,我们首先研究了构建基于云的数据仓库的可能性,但现实却不容乐观:我们的客户所存储的数据量在持续不断的增加,但只有小部分数据进入了数据仓库或 Hadoop 系统以供分析。我们发现这一问题并不仅限于云领域。这一问题在业界广泛存在,体现为企业存储细分市场的增长速率远远超过数据仓库细分市场的增长速率。
我们将此称为“暗数据”问题。我们的客户很清楚他们收集的数据中存在未被发掘的价值,否则他们为什么要耗费资金去存储数据呢? 但可供他们用来分析此类数据的系统太慢、太复杂并且成本太高昂,因此他们无法将此类系统应用于所有数据,而只能应用于精选出的部分数据。他们在存储数据时抱有积极的希望:总有一天有人会找到解决方案。
Amazon Redshift 已成为发展最快的 AWS 服务之一,因为它帮助解决了暗数据问题。它在成本和速度方面至少优于市面大多数替代产品一个数量级。此外,Amazon Redshift 从一开始就是完全托管的,您无需担心容量、预配置、修补、监控、备份和许多其他 DBA 难题。许多客户(包括 Vevo、Yelp、Redfin 和 Edmunds)都已迁移到 Amazon Redshift,旨在改善查询性能、减少 DBA 开销以及降低分析成本。
我们客户的数据一直在以非常快的速度增加。从 GB 级到 PB 级,整体上 Amazon Redshift 客户每年分析的数据量普遍可翻一倍。正因如此,我们实现了帮助客户处理其不断增长的数据的功能,以实现使查询吞吐量翻倍或将压缩比从 3 倍提升到 4 倍等目的。这让客户有时间思考是舍弃数据还是将数据从分析环境中移除。但是,越来越多的 AWS 客户每天可产生 1PB 数据,这样仅仅三年便可达到 1EB。以前没有适用于此类客户的解决方案。如果您的数据每年增加一倍,不久后您就必须寻找全新的颠覆性方法来转换成本、性能和简单性曲线以管理数据。
我们来了解一下现在可用的选项。您可以将基于 Hadoop 的技术(如 Apache Hive)与 Amazon EMR 配合使用。这实际上是一种非常有效的解决方案,因为它让在 Amazon S3 中直接操作数据变得简单且具成本效益,并且不需要提取或转换。您可以随时根据需要启动集群,并根据运行的特定作业将其调整为合适的大小。这些系统非常适用于需要高度横线扩展的处理工作,例如扫描、筛选和聚合。但它们不适合处理复杂的查询处理。例如,连接处理需要跨节点对数据进行乱序处理,对于数据量大和节点数多的情况,处理速度则会非常慢。任何有意义的分析问题本质上都涉及连接。
您还可以使用列式 MPP 数据仓库,如 Amazon Redshift。这些系统可简单运行复杂的分析查询,同时将对大型数据集执行连接和聚合的速度提升几个数量级。Amazon Redshift 尤其具备此功能,它可利用高性能的本地磁盘、高级的查询执行和经过连接优化的数据格式。由于它只是标准的 SQL,因此您可以继续使用现有的 ETL 和 BI 工具。但您需要加载数据,并且需要根据您所需的存储和 CPU 要求预配置集群。
两种解决方案都具有强大的属性,但它们会强制您选择要使用的属性。我们将此视为“‘或’暴政”。 您可以拥有本地磁盘的吞吐量“或”Amazon S3 的规模。您可以拥有高级的查询优化“或”大规模的数据处理。您可以拥有具有优化格式的快速连接性能“或”处理常见数据格式的一系列数据处理引擎。但您不应该必须进行选择。在此规模下,您实际上无法进行选择。您需要的是“以上所有”选项。
Redshift Spectrum
我们构建了 Redshift Spectrum 以终结这种“‘或’暴政”。 利用 Redshift Spectrum,Amazon Redshift 客户可在 Amazon S3 中轻松查询数据。与 Amazon EMR 一样,您可以获得开放数据格式和成本低廉的存储,还可以扩展数千个节点以拉取数据并对数据进行筛选、投影、聚合、分组和排序。与 Amazon Athena 一样,Redshift Spectrum 采用无服务器技术,因此无需预配置或管理任何内容。您只需为执行 Redshift Spectrum 查询期间使用的资源付费。与 Amazon Redshift 本身一样,您可以使用高级的查询优化器、快速访问本地磁盘上的数据以及使用标准的 SQL。但独一无二的是,Redshift Spectrum 可在几分钟内对 EB 级或更多数据执行非常高级的查询。
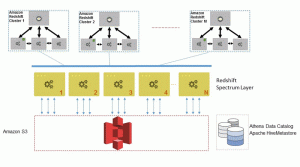
Redshift Spectrum 是 Amazon Redshift 的内置功能,您的现有查询和 BI 工具将可继续无缝工作。背后,我们管理着成千上万个分布于多个可用区的 Redshift Spectrum 节点。这些节点根据您需要处理的数据以透明方式进行扩展并分配到您的查询,无需预配置或预先承诺。Redshift Spectrum 还具有较高的并发性,您可以从任意数量的 Amazon Redshift 集群访问您的 Amazon S3 数据。
Redshift Spectrum 查询的运行流程
将 Redshift Spectrum 查询提交到 Amazon Redshift 集群的领导节点时,查询便开始。领导节点将优化和编译查询执行并将其推送到 Amazon Redshift 集群中的计算节点。接下来,计算节点将从数据目录获取描述外部表的信息,同时根据查询中的筛选和连接来动态修剪不相关的分区。计算节点还将检查本地可用的数据,并将谓词下推,以便仅高效地扫描 Amazon S3 中的相关对象。
然后,Amazon Redshift 计算节点将根据需要处理的对象数量生成多个请求,并将它们并发提交到 Redshift Spectrum,这会使每个 AWS 区域中聚集数千个 Amazon EC2 实例。Redshift Spectrum 工作线程节点将扫描、筛选并聚合 Amazon S3 中的数据,同时流式处理所需的数据以便将数据处理回 Amazon Redshift 集群。接下来,将在集群中本地执行最终的连接和合并操作,结果将返回客户端。

Redshift Spectrum 的架构可提供几项优势。首先,它可以独立于 Amazon S3 中的存储层来弹性缩放计算资源。第二,它可以提供非常高的并发性,因为您可以运行多个 Amazon Redshift 集群和在 Amazon S3 中查询相同的数据。第三,Redshift Spectrum 可以利用 Amazon Redshift 查询优化器生成高效的查询计划,对于使用多表连接和窗口函数的复杂查询同样适用。第四,它可以按源数据的原生格式(Parquet、RCFile、CSV、TSV、Sequence、Avro、RegexSerDe,即将增加更多格式)直接对源数据执行操作。这意味着无需进行数据加载或转换。这还可省去数据复制和相关成本。第五,通过以开放数据格式执行操作,您可以灵活地利用其他 AWS 服务和执行引擎来与各个团队协作处理 Amazon S3 中的相同数据。除了获得所有这些优势外,由于 Redshift Spectrum 是 Amazon Redshift 的一项功能,您还可获得与 Amazon Redshift 相同级别的端到端安全性、合规性和认证。
专为提高性能和节约成本而设计
利用 Amazon Redshift Spectrum,您只需为对您实际扫描的数据所运行的查询付费。我们建议您利用文件分区、列数据格式和数据压缩来最大程度降低在 Amazon S3 中扫描的数据量。这对于数据仓库非常重要,因为它可以显著提高查询性能和降低成本。通过按日期、时间或任何其他自定义键对 Amazon S3 中的数据进行分区,Redshift Spectrum 可以动态修剪不相关的分区以最大程度降低要处理的数据量。如果您以列格式(例如 Parquet)存储数据,Redshift Spectrum 将仅扫描查询所需的列,而不会处理整个行。同样,如果使用 Redshift Spectrum 支持的一种压缩算法来压缩数据,则可以减少扫描的数据量。
Amazon Redshift 和 Redshift Spectrum 提供各自同类产品中更好的功能。如果需要对相同的数据频繁运行查询,您可以将其标准化并存储到 Amazon Redshift 中,然后利用功能完备的数据仓库的所有优势来以固定费率存储和查询结构化数据。同时,您可以将其他数据(无论是历史数据还是最新数据)继续以多种开放格式保留在 Amazon S3 中,并将 Amazon Redshift 查询扩展到 Amazon S3 数据湖中。
这就是 Amazon Redshift Spectrum 将数据仓库扩展到 EB 级别且无需加载的方法。Redshift 将终结“‘或’暴政”,使您可随时在所需位置、按所需格式存储数据,并在需要时使这些数据可供使用标准 SQL 进行快速处理。
其他阅读资源
10 Best Practices for Amazon Redshift Spectrum
Amazon QuickSight Adds Support for Amazon Redshift Spectrum
Amazon Redshift Spectrum – Exabyte-Scale In-Place Queries of S3 Data
关于作者
 Maor Kleider 是快速、简单、经济高效的数据仓库 Amazon Redshift 的高级产品经理。Maor 热衷于与客户和合作伙伴之间的合作,了解他们独特的大数据用例并进一步改善其体验。在空闲时间,Maor 喜欢与家人一起旅行和探索新美食。
Maor Kleider 是快速、简单、经济高效的数据仓库 Amazon Redshift 的高级产品经理。Maor 热衷于与客户和合作伙伴之间的合作,了解他们独特的大数据用例并进一步改善其体验。在空闲时间,Maor 喜欢与家人一起旅行和探索新美食。