亚马逊AWS官方博客
Amazon Redshift 更新 – 下一代计算实例和托管式分析优化存储
早在 2012 年,我们就已推出 Amazon Redshift(Amazon Redshift – 新的 AWS 数据仓库)。它拥有成千上万个客户,目前是世界上最常用的数据仓库。该数据仓库为客户一贯提供快速的性能、对复杂查询的支持和事务性功能,全部都具有行业领先的性价比。
Redshift 原始模型在计算能力与存储容量之间建立起相对严格的耦合。您创建一个具有特定数量实例的集群,并提交给(有时受限于)每个实例所提供的本地存储量。您可以使用按需并发扩展来访问其他计算能力,并且可以使用 Elastic Resize 在几分钟内扩展和缩减您的集群,以便能够适应不断变化的计算和存储需求。
我们认为我们可以做得更好! 今天,我们推出适用于 Redshift 的下一代 Nitro 驱动计算实例,该实例由新的托管型存储模型提供支持,可让您单独优化您的计算能力和存储。此次发布利用一些架构上的改进,包括高带宽网络、使用 Amazon Simple Storage Service (S3) 支持的本地 SSD 存储的托管存储及多种高级数据管理方法来优化数据在 S3 间的来回移动。
在这些功能的共同作用下,Redshift 可以提供任何其他云数据仓库服务的 3 倍性能,而且使用密集存储 (DS2) 实例的大多数现有 Amazon Redshift 客户将以相同的成本获得高达 2 倍的性能和 2 倍的存储。
在很多其他使用案例中,这种新组合非常适合操作分析,在此类分析中,大部分工作负载集中于数据仓库中一个较小的数据子集(通常为最近的子集)。过去,客户要将旧的数据卸载到其他类型的存储中,以使其保持在存储限制内,这样会造成额外的复杂性,并且会使历史数据查询变得非常复杂。
下一代计算实例
新的 RA3 实例旨在与新的托管存储模型密切合作。ra3.16xlarge 实例有 48 个 vCPU,384 GiB 内存和高达 64 TB 的存储。我可以创建具有 2 到 128 个实例的集群,为我提供超过 8 PB 的压缩存储:
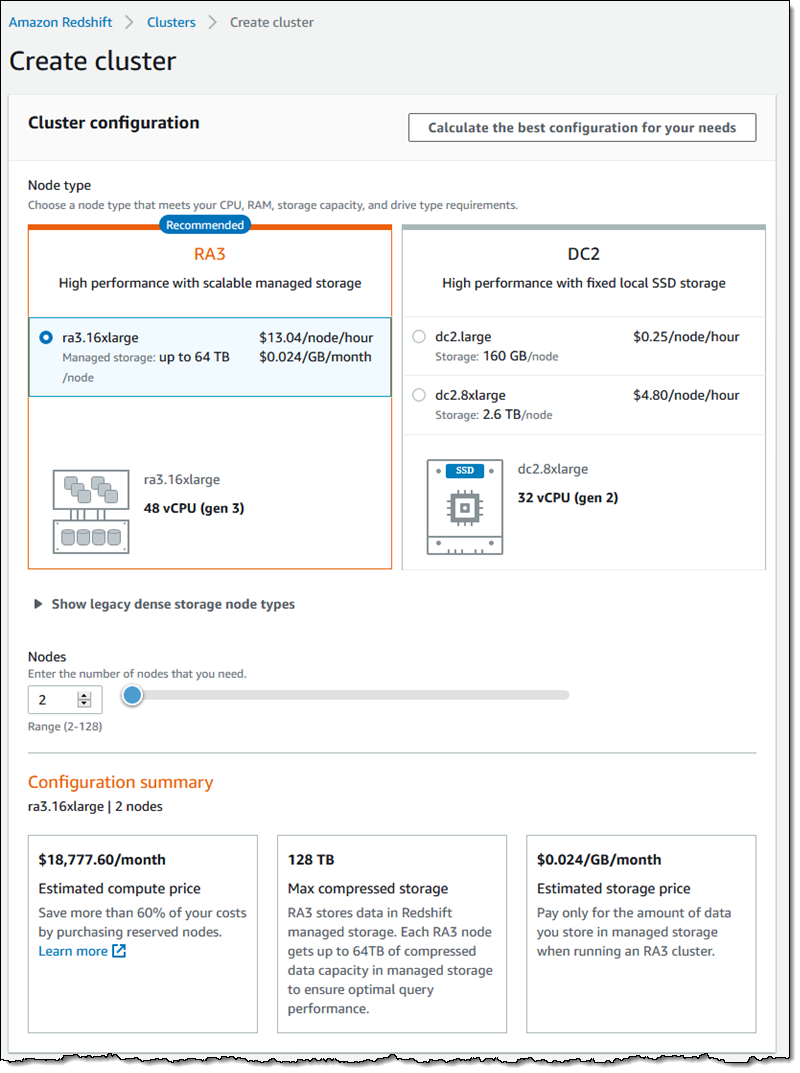
我还可以从现有集群的快照创建一个新的 RA3 驱动集群,或者可以使用 Classic resize 升级我的集群以使用新的实例类型。
如果您拥有现有快照或集群,您可以使用 Amazon Redshift 控制台在您还原或调整大小时获得推荐的 RA3 配置。您还可以从 DescribeNodeConfigurationOptions 函数或 describe-node-configuration-options 命令中获得建议。
经分析优化的托管存储
新的托管存储同样很精彩。每一个实例上基于 SSD 的大容量、高性能存储都有一个缓存,由 S3 提供支持,用于扩展、性能和持久性。存储系统使用多条提示,包括数据块温度、数据阻塞和工作负载模式来管理缓存,以获得高性能。数据自动放置在适当的层级中,您无需进行任何特殊操作便能从缓存或其他优化中获益。您支付同样的低价便能获得 SSD 和 S3 存储,而且您可以扩展您的数据仓库的存储容量,无需添加和为其他实例付费。
价格和可用性
您可以在提供 Redshift 的所有 AWS 区域开始将 RA3 实例托管存储一起使用。
— Jeff;