亚马逊AWS官方博客
构建现代化数据架构-使用 Amazon AppFlow、AmazonLake Formation 和 Amazon Redshift
最近,Roche Data Insights (RDI) 计划启动,旨在使用新的工作和协作方式来实现我们的愿景,从而通过联合治理构建共享、可互操作的数据和见解。此外,应建立简化和集成的数据格局,以增强洞察社区。参与该计划的首批领域之一是 Go-to-Market (GTM) 领域,该领域包括 Roche 的销售、营销、医疗准入和市场事务。GTM 领域使 Roche 能够了解客户,并最终创建和提供满足客户需求的高价值服务。GTM 作为一个领域,不仅限于医疗保健专业人士 (HCP),还扩展到由患者、社区、卫生当局、付款人、提供商、学术界、竞争对手等组成的更大医疗保健生态系统。因此,数据与分析是通过切实可行的洞察支持内部和外部利益攸关方的决策流程的关键。
Roche GTM 在利用 DevOps 最佳实践的同时,在 AWS 上构建了一个现代数据和机器学习 (ML) 平台。一切即代码 (EaC) 的口号是在 AWS 上构建完全自动化、可扩展的数据湖和数据仓库的关键。
在这篇博文中,您将了解 Roche 如何使用 AWS 产品和服务(例如 Amazon AppFlow、AWS Lake Formation 和 Amazon Redshift)来预置和填充其数据湖;他们如何获取、转换数据并将其加载到数据仓库中;以及他们如何实现安全和访问控制方面的最佳实践。
在以下各节中,您将深入了解 Roche 构建的可扩展、安全且自动化的现代数据平台。我们将演示如何自动化数据摄入、安全标准,以及如何利用 DevOps 最佳实践来简化对 AWS 上现代数据平台的管理。
数据平台架构
下图展示了数据平台架构。
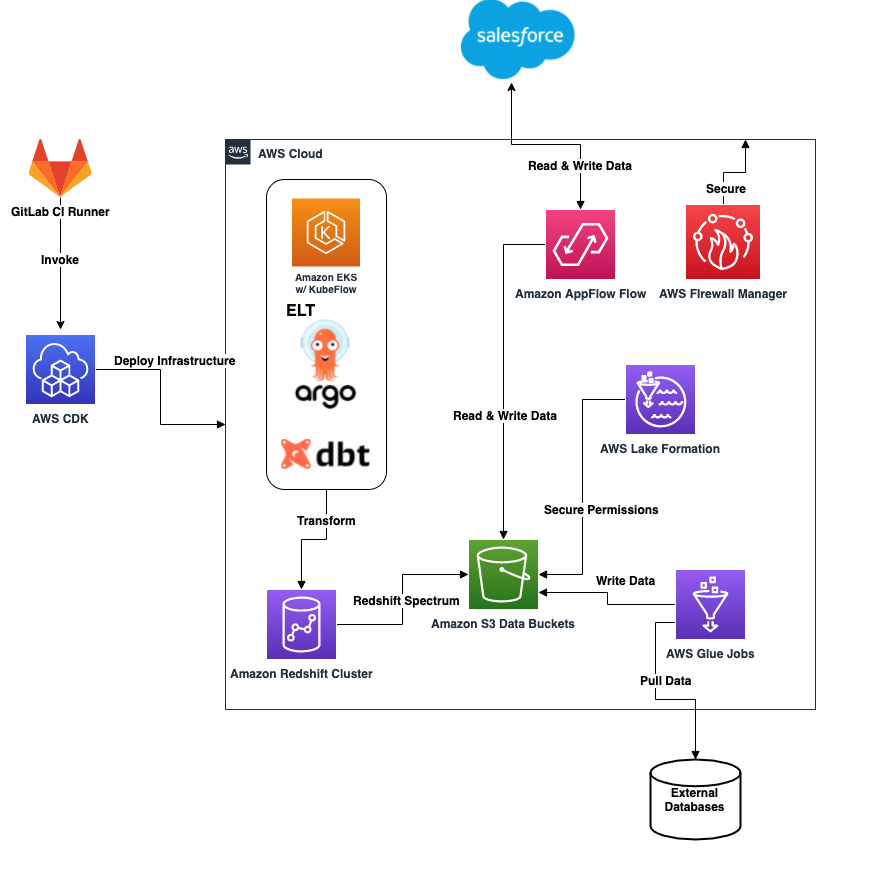
该架构包含以下组件:
- 核心基础设施是使用 AWS Cloud Development Kit (AWS CDK) 从 GitLab Runner 容器部署的
- Amazon AppFlow 从 Salesforce 收集对象并将其放入 Amazon Simple Storage Service (Amazon S3) 存储桶中
- 来自 S3 存储桶的已处理数据也会使用 Amazon AppFlow 重新加载到 Salesforce
- AWS Glue 作业会将外部数据库(例如 Oracle)和 API 中的数据加载到 S3 存储桶
- 启动在 Amazon Elastic Kubernetes Service (Amazon EKS) 上使用 Argo(一个开源项目)调用 DBT ELT 作业,以转换和清理外部 Amazon Redshift 表中的数据
- 运行 Kubeflow 的 Amazon EKS 集群与适用于数据科学机器学习实验和使用案例的 Amazon Redshift 集群进行交互
- Lake Formation 会保护分配给特定 AWS Identity and Access Management (IAM) 角色的 S3 存储桶、AWS Glue 数据库和表
- AWS Firewall Manager 会保护整个 AWS 云外围
Lake Formation 安全性
我们使用 Lake Formation 保护所有到达数据湖的数据。将每个数据湖层划分为不同的 S3 存储桶和前缀可实现 Lake Formation 实施的细粒度访问控制策略。此概念还扩展到锁定对特定行和列的访问权限以及将策略应用于特定 IAM 角色和用户。管理和对数据湖资源的治理和访问很难,但 Lake Formation 为管理员简化了这一流程。
为使用 Lake Formation 保护对数据湖的访问,使用带有自定义构造的 AWS CDK 自动执行以下步骤:
- 向 Lake Formation 注册 S3 数据存储桶和前缀以及相应的 AWS Glue 数据库。
- 添加数据湖管理员(GitLab Runner IAM 部署角色和管理员 IAM 角色)。
- 授予 AWS Glue 作业 IAM 角色访问特定 AWS Glue 数据库的权限。
- 向 AWS Lambda IAM 角色授予对 Amazon AppFlow 数据库的访问权限。
- 向列出的 IAM 角色授予对 AWS Glue 数据库中相应表的访问权限。
AWS Glue 数据目录
AWS Glue 数据目录是在数据湖和 Amazon Redshift 中创建的所有数据库和表的集中注册和访问点。这为所有资源及其引用的所有数据架构和位置提供了集中的透明度。对于在智能湖仓平台内执行的任何数据操作来说,这都是一个至关重要的方面。
数据来源和摄入
通过使用 AWS Glue 作业和 Amazon AppFlow 获取数据并将其加载到数据湖中。摄入的数据将使用外部架构和表通过 Amazon Redshift Spectrum 在 Amazon Redshift 数据仓库中提供。本文稍后将概述创建外部架构并将其链接到数据目录的过程。
Amazon AppFlow Salesforce 摄入
Amazon AppFlow 是一项完全托管式集成服务,允许您从 Salesforce、SAP 和 Zendesk 等来源提取数据。Roche 与 Salesforce 集成,无需编写任何自定义代码即可将 Salesforce 对象安全地加载到其数据湖中。此外,Roche 还使用 Amazon AppFlow 将机器学习结果推送回 Salesforce,以推动这一过程。
Salesforce 对象首先完全加载到 Amazon S3 中,然后转为每日增量加载以捕获增量。数据以 Parquet 格式进入原始区域存储桶中,使用日期作为分区。Amazon AppFlow 流程是通过使用 YAML 配置文件创建的(请参阅以下代码)。AWS CDK 部署使用此配置来创建相应的流程。
YAML 配置使您可以轻松选择是将数据从 S3 存储桶重新加载到 Salesforce 还是从 Salesforce 加载到 S3 存储桶。随后,AWS CDK 应用程序和相应的堆栈会读取此配置,以转换到 Amazon AppFlow 流程。
在前面的 YAML 配置文件中指定了以下选项:
- source – 从中提取数据的位置(Amazon S3、Salesforce)
- destination – 要将数据存入的目的地(Amazon S3、Salesforce)
- object_name – 要与之交互的 Salesforce 对象的名称
- incremental_load – 一个布尔值,用于指定加载应该是增量加载还是完全加载(0 表示完整,1 表示增量)
- schedule_expression – 用于运行流程的 cron 或 rate 表达式(
na表示按需) - s3_prefix – 用于在 S3 存储桶中推送或提取数据的前缀
- connector_profile – 连接到 Salesforce 时要使用的 Amazon AppFlow 连接器配置文件名称(可以是 CSV 列表)
- environment – 将此 Amazon AppFlow 流程部署到的环境(
all表示部署到开发和生产环境,dev表示开发环境,prod表示生产环境) - upsert_field_list – 向 Salesforce 执行更新插入操作时要使用的一组 Salesforce 对象字段(可以是 CSV 列表)(仅在将数据从 S3 存储桶重新加载到 Salesforce 时适用)
- bookmark_col – 数据目录中用于注册每日加载日期字符串分区的列的名称
将 Salesforce 对象注册到数据目录
完成以下步骤,将加载到数据湖中的数据注册到数据目录中,并将其链接到 Amazon Redshift:
- 收集 Salesforce 对象字段和相应的数据类型。
- 在数据目录中创建相应的 AWS Glue 数据库。
- 对 Amazon Redshift 运行查询,以创建链接到 AWS Glue 数据库的外部架构。
- 在 AWS Glue 数据库和表中创建表和分区。
可通过数据目录和 Amazon Redshift 集群访问数据。
Amazon AppFlow 动态字段收集
要在数据湖中构造已加载的 Salesforce 对象的架构,请调用以下 Python 函数。该代码利用来自 Boto3 的 Amazon AppFlow 客户端动态收集 Salesforce 对象字段来构建 Salesforce 对象的架构。
我们将函数用于通过 AWS CDK 部署创建 Amazon AppFlow 流程,以及在相应 AWS Glue 数据库的数据目录中创建相应的表。
创建 Amazon CloudWatch Events 规则、AWS Glue 表和分区
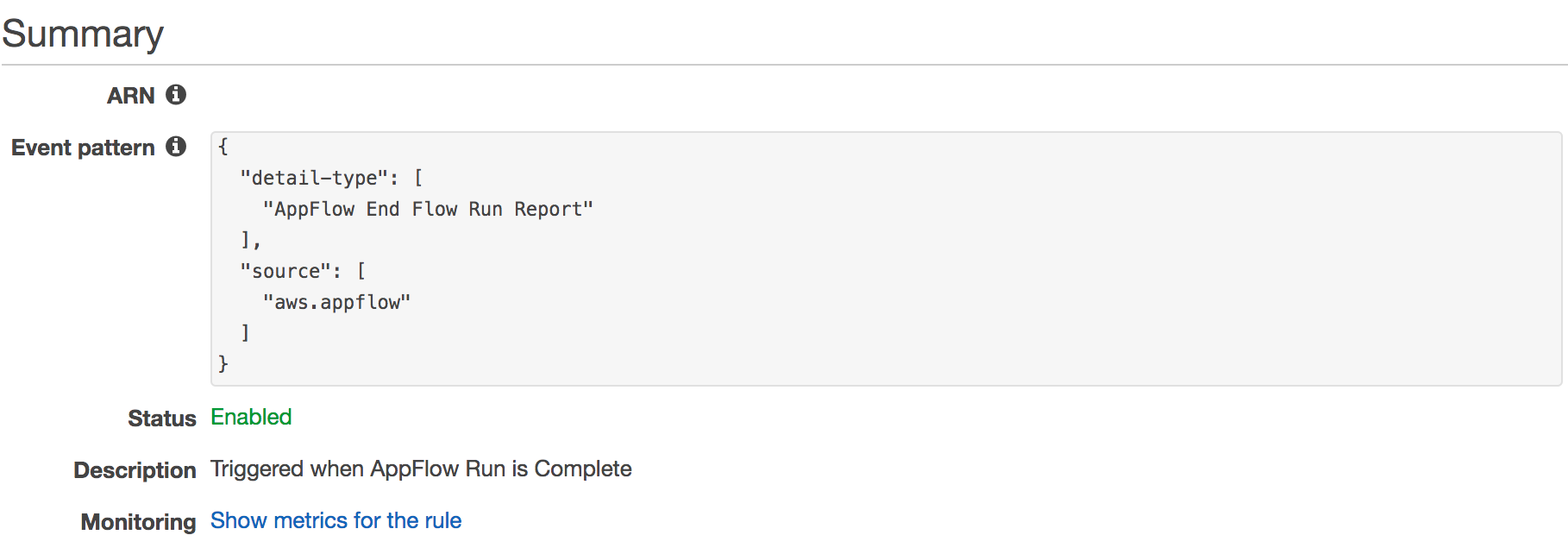
要自动将新表(每个加载到 Amazon S3 中的 Salesforce 对象一个)和分区添加到数据目录中,您需要创建 Amazon CloudWatch Events 规则。此函数使您能够查询 AWS Glue 和 Amazon Redshift 中的数据。
Amazon AppFlow 流程完成后,它会调用 CloudWatch Events 规则和相应的 Lambda 函数,以便在 AWS Glue 中创建一个新表,或者使用当天的相应日期字符串添加新分区。CloudWatch Events 规则与以下屏幕截图类似。
调用的 Lambda 函数使用 Amazon SageMaker Data Wrangler Python package 与数据目录进行交互。使用前面的函数定义,可以访问对象字段及其数据类型以传递给以下函数调用:
如果表已存在,则 Lambda 函数会创建一个新分区来表示流程完成的日期(如果该分区尚不存在):
Amazon Redshift 外部架构查询
系统会为上述配置中存在的每个 Amazon AppFlow 连接器配置文件创建一个 AWS Glue 数据库。从 Salesforce 加载到 Amazon S3 中的对象将作为表注册到相应数据库下的数据目录中。要将数据目录中的数据库与外部 Amazon Redshift 架构关联起来,请运行以下查询:
指定的 iam_role 值必须是提前创建的 IAM 角色,并且必须指定适当的访问策略才能查询 Amazon S3 的位置。
现在,数据目录中的所有可用表都可以在 Amazon Redshift Spectrum 中使用 SQL 在本地进行查询。
Amazon AppFlow Salesforce 目的地
Roche 使用 Amazon Redshift 数据仓库中的数据训练和调用机器学习模型。机器学习模型完成后,结果将推送回 Salesforce。通过使用 Amazon AppFlow,我们无需编写任何自定义代码即可实现数据传输。结果的架构必须与相应 Salesforce 对象的架构相匹配,并且结果的格式必须以 JSON 行或 CSV 格式写入,才能写回 Salesforce。
AWS Glue 作业
为了将本地数据馈送到数据湖中,Roche 在 Python 中构建了一组 AWS Glue 作业。有各种外部源,包括直接加载到原始区域 S3 存储桶中的数据库和 API。AWS Glue 作业每天运行一次,以加载新数据。加载的数据遵循 YYYYMMDD 格式的分区方案,以便更高效地存储和查询数据集。然后,将加载的数据转换为 Parquet 格式,以实现更高效的查询和存储。
Amazon EKS 和 KubeFlow
为了在 Amazon EKS 上部署机器学习模型,Roche 在 Amazon EKS 上使用 Kubeflow。使用 Amazon EKS 作为骨干网络基础设施,可以轻松构建、训练、测试和部署机器学习模型,并与作为数据源的 Amazon Redshift 进行交互。
Firewall Manager
作为额外的安全层,Roche 通过使用 Firewall Manager 采取了额外的预防措施。这允许 Roche 通过使用有状态和无状态规则集明确拒绝或允许入站和出站流量。这也使 Roche 能够允许对外部网站进行某些出站访问,并拒绝他们不希望其 Amazon VPC 中的资源访问的网站。这一点至关重要,尤其是在处理任何敏感数据集时,以确保数据受到保护且不会被转移到外部。
CI/CD
架构图中概述的所有基础设施都是自动化的,并使用持续集成和持续交付 (CI/CD) 管道部署到多个 AWS 区域,将 GitLab Runner 作为编排器。使用 GitFlow 模型进行分支和调用自动部署以部署到 Roche AWS 账户。
基础设施即代码和 AWS CDK
基础设施即代码 (IaC) 最佳实践被用来帮助创建所有基础设施。Roche 团队使用 Python AWS CDK 对其 AWS 账户中基础设施发生的任何更改进行部署、版本控制和维护。
AWS CDK 项目结构
GitLab 中项目结构的顶层包括以下文件夹(但不限于这些文件夹),以便将基础设施和代码全部保存在同一个位置。

为了便于使用 Roche 账户中创建的各种资源,部署分为以下 AWS CDK 应用程序,其中包含多个堆栈:
coredata_lakedata_warehouse
core 应用程序包含与账户设置和账户引导启动相关的所有堆栈,例如:
- VPC 创建
- 初始 IAM 角色和策略
- 安全防护机制
data_lake 应用程序包含与创建 AWS 数据湖相关的所有堆栈,例如:
- Lake Formation 设置和注册
- AWS Glue 数据库创建
- S3 存储桶创建
- Amazon AppFlow 创建流程
- AWS Glue 作业设置
data_warehouse 应用程序包含与设置数据仓库基础设施相关的所有堆栈,例如:
- Amazon Redshift 集群
- 负载均衡器到 Amazon Redshift 集群
- 日志记录
选择所描述的 AWS CDK 项目结构是为了保持部署的灵活性,并从逻辑上将相互依赖的堆栈组合在一起。这种灵活性允许按功能划分部署,并且仅在真正需要和要求时才进行部署。这种调配的不同部分的分离保持了部署时的灵活性。
AWS CDK 项目配置
项目配置非常灵活,始终可以作为 YAML 配置文件进行外推。例如,Roche 简化了创建新 Amazon AppFlow 流程的过程,只需在其 YAML 配置中添加新条目即可根据需要添加或删除流程。下次进行 GitLab Runner 部署时,它会接收综合 AWS CDK 中的更改,以使用新资源集生成新的更改集。这种配置和设置使内容保持动态和灵活,同时将配置与代码分离。
网络架构
下图展示了网络架构。
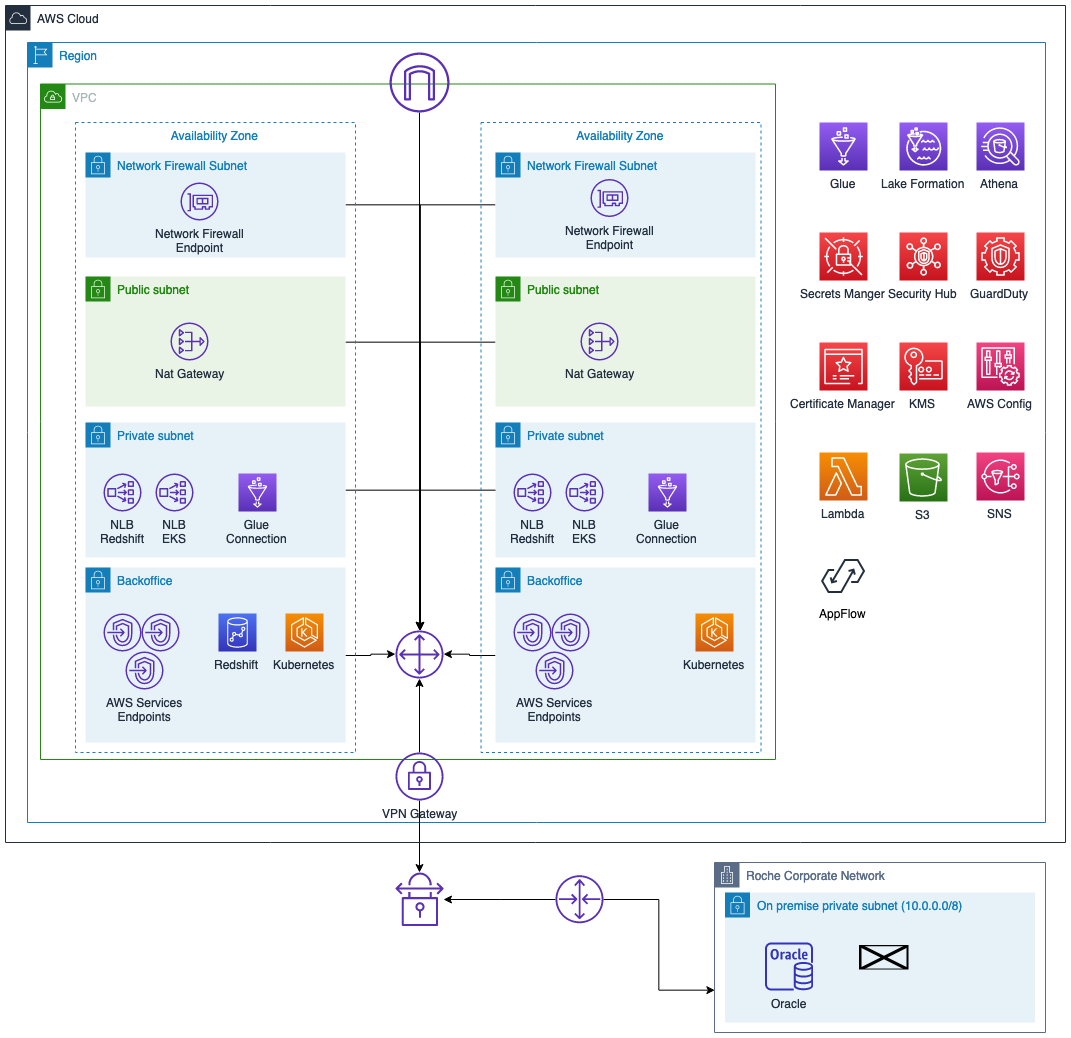
我们可以将架构分解如下:
- 所有 AWS 服务都部署在两个可用区中(Amazon Redshift 除外)
- 只有私有子网才能访问本地 Roche 环境
- 服务部署在后端子网中
- 使用 AWS Network Firewall 进行外围保护
- 网络负载均衡器将服务发布到本地环境
网络安全配置
基础设施、配置和安全性在 AWS CDK 中定义为代码,Roche 使用 CI/CD 管道来管理和部署它们。Roche 有一个 AWS CDK 应用程序来部署项目的核心服务:VPC、VPN 连接和 AWS 安全服务(AWS Config、Amazon GuardDuty 和 AWS Security Hub)。该 VPC 包含部署在两个可用区域中的四个网络层,它们具有用于访问 Amazon S3、Amazon DynamoDB 和 Amazon Simple Queue Service (Amazon SQS) 等 AWS 服务的 VPC 终端节点。它们会限制使用 AWS Network Firewall 访问互联网。
基础设施被定义为代码,配置是隔离的。Roche 通过运行 CI/CD 管道来部署其基础设施,从而执行 VPC 设置。配置位于特定的外部文件中;如果 Roche 想要更改 VPC 的任何值,他们只需修改此文件并再次运行管道(无需键入任何新代码行)。如果 Roche 想要更改任何配置,他们不必更改任何代码。它使 Roche 可以轻松地进行更改,然后将其部署到其环境中,从而使更改更加透明且更易于配置。配置的可追溯性更加透明,并且可以更轻松地批准更改。
以下代码是 VPC 配置的示例:
这种方法的优点如下:
- 无需修改 AWS CDK 构造函数和构建新代码即可更改 VPC 配置
- 从一个中心位置管理 VPC 配置
- 通过 Git 追踪变更和配置历史记录
- 在几分钟内将所有基础设施重新部署到其他地区或账户
操作和警报
Roche 开发了一种自动警报系统,在端到端架构的任何部分遇到任何问题时,重点关注从 AWS Glue 或 Amazon AppFlow 加载数据时出现的任何问题。默认情况下,出于调试目的,所有日志记录都会发布到 CloudWatch。
已针对以下工作流程构建了操作警报:
- AWS Glue 作业和 Amazon AppFlow 流程会摄取数据。
- 如果任务失败,它会向 CloudWatch Events 规则发出一个事件。
- 触发规则并调用 Lambda 函数以将失败详情发送到 Amazon Simple Notification Service (Amazon SNS) 主题。
- SNS 主题的一个 Lambda 订阅者随后被调用:
- Lambda 函数从 AWS Secrets Manager 中读取特定的 webhook 网址。
- 该函数会向特定的外部系统发出警报。
- 外部系统会收到该消息,向有关各方通报问题并提供详细信息。
以下架构概述了为智能湖仓平台构建的警报机制。

结论
GTM (Go-To-Market) 领域成功地帮助其业务利益攸关方、数据工程师和数据科学家提供了一个可扩展到 Roche 面临的许多使用场景的平台。它是 Roche 中的 GTM 组织的关键推动者和加速器。通过现代数据平台,Roche 现在能够更好地了解客户,并最终创建和提供满足客户需求的高价值服务。它不仅限于医疗保健专业人士 (HCP),还扩展到更大的医疗保健生态系统。本博客中的平台和基础设施通过切实可行的见解,帮助支持和加快内部和外部利益攸关方的决策过程。
这篇博文中的步骤可帮助您计划使用 AWS 托管服务构建类似的现代数据策略,以便从 Salesforce 等来源提取数据,自动创建元数据目录并在数据湖和数据仓库之间无缝共享数据,以及在出现编排数据工作流程失败时创建警报。在本文的第 2 部分中,您将了解如何使用敏捷数据建模模式构建数据仓库,以及如何快速开发、编排和配置 ELT 作业以执行自动化数据质量测试。
特别感谢 Roche 团队:Joao Antunes、Krzysztof Slowinski、Krzysztof Romanowski、Bartlomiej Zalewski、Wojciech Kostka、Patryk Szczesnowicz、Igor Tkaczyk、Kamil Piotrowski、Michalina Mastalerz、Jakub Lanski、Chun Wei Chan、Andrzej Dziabowski 在项目交付方面和为此文章提供的支持。
关于作者
 Roche 的 Yannick Misteli 博士 – Yannick Misteli 博士领导 Roche 全球产品战略 (GPS) 的云平台和机器学习工程团队。他对基础设施和数据驱动型解决方案的运营充满热情,并且在通过数据分析推动商业价值创造方面拥有丰富的经验。
Roche 的 Yannick Misteli 博士 – Yannick Misteli 博士领导 Roche 全球产品战略 (GPS) 的云平台和机器学习工程团队。他对基础设施和数据驱动型解决方案的运营充满热情,并且在通过数据分析推动商业价值创造方面拥有丰富的经验。
 AWS 的 Simon Dimaline – Simon Dimaline 专门从事数据仓库和数据建模领域已有 20 多年。他目前在 AWS 专业服务的数据和分析团队工作,以加快客户对 AWS 分析服务的采用。
AWS 的 Simon Dimaline – Simon Dimaline 专门从事数据仓库和数据建模领域已有 20 多年。他目前在 AWS 专业服务的数据和分析团队工作,以加快客户对 AWS 分析服务的采用。
 AWS 的 Matt Noyce — Matt Noyce 是 Amazon Web Services 专业服务的高级云应用程序构架师。他与客户合作,在 AWS 上构建、设计、自动化和构建可满足其业务需求的解决方案。
AWS 的 Matt Noyce — Matt Noyce 是 Amazon Web Services 专业服务的高级云应用程序构架师。他与客户合作,在 AWS 上构建、设计、自动化和构建可满足其业务需求的解决方案。
 AWS 的 Chema Artal Banon – Chema Artal Banon 是 AWS 专业服务的安全顾问,与 AWS 的客户合作设计、构建和优化他们的安全性,以推动业务发展。他擅长帮助客户建立信心和培养技术能力,从而帮助公司以尽可能安全的方式加快使用 AWS 云的步伐。
AWS 的 Chema Artal Banon – Chema Artal Banon 是 AWS 专业服务的安全顾问,与 AWS 的客户合作设计、构建和优化他们的安全性,以推动业务发展。他擅长帮助客户建立信心和培养技术能力,从而帮助公司以尽可能安全的方式加快使用 AWS 云的步伐。
向以下人员致以特别的谢意,他们的专业知识使这篇文章得以在 AWS 上发布:
- Thiyagarajan Arumugam – 首席分析专家解决方案构架师
- Taz Sayed – 分析技术负责人
- Glenith Paletta – 企业服务经理
- Mike Murphy – 全球客户经理
- Natacha Maheshe – 高级产品营销经理
- Derek Young – 高级产品经理
- Jamie Campbell – Amazon AppFlow 产品经理
- Kamen Sharlandjiev – 高级解决方案构架师 – Amazon AppFlow
- Sunil Jethwani – 首席客户交付构架师
- Vinay Shukla – Amazon Redshift 首席产品经理
- Nausheen Sayed – 项目经理