亚马逊AWS官方博客
构建、共享、部署:业务分析师和数据科学家如何使用无代码机器学习和 Amazon SageMaker Canvas 缩短面市时间
业务分析师构建模型,然后分享
为了了解 SageMaker Canvas 如何简化业务分析师与数据科学家(或机器学习工程师)之间的协作,我们首先以业务分析师的身份来进入这一流程。在开始之前,请参阅宣布推出 Amazon SageMaker Canvas — 面向业务分析师的可视化、无代码机器学习功能,了解有关使用 SageMaker Canvas 构建和测试模型的说明。
在本文中,我们使用 Kaggle 的信用卡欺诈侦测数据集的修改版本,这是一个众所周知的二元分类问题数据集。该数据集最初高度不平衡,很少有条目被归类为负类(异常事务)。无论目标功能分布如何,我们仍然可以使用此数据集,因为 SageMaker Canvas 会在自动训练和调整模型时处理这种不平衡。该数据集由大约 900 万个元胞组成。您还可以下载此数据集的缩减版本。这种数据集要小得多,约为 50 万个元胞,因为数据集随机抽样不足,然后使用 SMOTE 技术进行过度抽样,以确保在此过程中丢失尽可能少的信息。在 SageMaker Canvas 免费套餐下,使用此缩减版数据集运行整个实验的费用为 0 美元。
构建模型后,分析师可以使用它直接在 Canvas 中针对单个请求或整个输入数据集批量进行预测。

使用 Canvas Standard Build 构建的模型也可以轻松地与使用 SageMaker Studio 的数据科学家和机器学习工程师共享,只需单击一下按钮即可。这样,数据科学家就可以验证您构建的模型性能并提供反馈。机器学习工程师可以选择您的模型,并将其与您的公司和客户可用的现有工作流及产品集成。请注意,在撰写本文时,无法共享通过 Canvas Quick Build 构建的模型或时间序列预测模型。
通过 Canvas UI 共享模型非常简单:
- 在显示您创建的模型的页面上,选择一个模型。
- 选择 Share(共享)。

- 选择要共享的模型的一个或多个版本。
- (可选)添加注释,以提供有关模型或您要查找的帮助的更多背景信息。
- 选择 Create SageMaker Studio Link(创建 SageMaker Studio 链接)。

- 复制生成的链接。

就是这么简单! 现在,您可以通过 Slack、电子邮件或您喜欢的任何其他方式与同事共享链接。数据科学家需要位于同一 SageMaker Studio 域中才能访问您的模型,因此,请确保您的企业管理员也是如此。

数据科学家访问来自 SageMaker Studio 的模型信息
现在,让我们扮演数据科学家或机器学习工程师的角色,使用 SageMaker Studio 从他们的角度来看问题。
分析师分享的链接将我们带到了 SageMaker Studio,这是第一个用于端到端机器学习工作流的基于云的 IDE。

该选项卡将自动打开,并显示分析师在 SageMaker Canvas 中创建的模型概览。您可以快速查看模型的名称、机器学习问题类型、模型版本以及创建模型的用户(位于“Canvas user ID”(Canvas 用户 ID)字段下)。您还可以访问有关输入数据集的详细信息以及 SageMaker 能够生成的最佳模型。我们稍后将在本文中深入探讨这一点。
在 Input Dataset(输入数据集)选项卡上,您还可以查看从源数据集到输入数据集的数据流。在这种情况下,只使用一个数据源且未应用任何联接操作,因此只显示一个源。您可以选择 Open data exploration notebook(打开数据探索笔记本),分析有关数据集的统计数据和详细信息。借助此笔记本,您可以浏览训练模型之前可用的数据,其中包含目标变量的分析、输入数据的样本、统计数据及列和行的说明,以及其他有用信息,以便数据科学家进一步了解数据集。要详细了解此报告,请参阅数据探索报告。

分析完输入数据集后,我们转到模型概览的第二个选项卡 AutoML Job(AutoML 作业)。当您在 SageMaker Canvas 中选择“Standard Build”(标准构建)选项时,此选项卡包含对 AutoML 作业的描述。
SageMaker Canvas 下的 AutoML 技术消除了构建机器学习模型的繁重工作。它使用自动化方法根据您的数据自动构建、训练和调整最佳机器学习模型,同时允许您保持完全控制力和可见性。生成的候选模型以及在 AutoML 过程中使用的超参数的可见性包含在候选生成笔记本中,该笔记本位于此选项卡上。
AutoML Job(自动机器学习作业)选项卡还列出了在 AutoML 流程中构建的每个模型(按 F1 目标指标排序)。为了从启动的训练作业中突出显示最佳模型,Best Model(最佳模型)列中使用了带有绿色圆圈的标签。您还可以轻松可视化训练和评估阶段使用的其他指标,例如,准确度得分和曲线下面积 (AUC)。要详细了解在 AutoML 作业期间可以训练的模型以及用于评估训练模型性能的指标,请参阅模型支持、指标和验证。
要详细了解模型,现在可以右键单击最佳模型,然后选择 Open in model details(在模型详细信息中打开)。或者,也可以选择 Best model(最佳模型)链接(位于首次访问的 Model overview(模型概览)部分顶部)。

模型详细信息页面包含大量有关使用此输入数据表现最佳的模型的有用信息。我们首先看看页面顶部的摘要。上面的示例屏幕截图显示,在数百次模型训练运行中,XGBoost 模型在输入数据集上的表现最佳。在撰写本文时,SageMaker Canvas 可以训练三类机器学习算法:线性学员算法、XGBoost 和多层感知器 (MLP),每种算法都有各种各样的预处理管道和超参数。要详细了解每种算法,请参阅支持的算法页面。
SageMaker 还包含解释功能,这要归功于 KernelShap 可扩展且高效的实施,基于合作博弈论领域的 Shapley 值的概念,该概念为每个功能分配特定预测的重要性值。这样可以透明地了解模型如何得出预测,且定义功能重要性非常有用。包含功能重要性的完整可解释性报告可以 PDF、笔记本或原始数据格式下载。该报告显示了更广泛的指标集以及在 AutoML 作业期间使用的超参数完整列表。要详细了解 SageMaker 如何为 AutoML 解决方案和标准机器学习算法提供集成的可解释性工具,请参阅使用集成的可解释性工具和通过 Amazon SageMaker Autopilot 提高模型质量。
最后,此视图中的其他选项卡显示有关性能详细信息(混淆矩阵、精度召回曲线、ROC 曲线)、AutoML 作业期间用于输入和生成的构件及网络详情的信息。
此时,数据科学家有两种选择:直接部署模型,或创建可手动/自动调度或触发的训练管道。以下各部分提供了对这两个选项的一些见解。
直接部署模型
如果数据科学家对 AutoML 作业获得的结果感到满意,可以直接从 Model Details(模型详细信息)页面部署模型。只需选择模型名称旁边的 Deploy model(部署模型)即可。

SageMaker 向您展示了两个部署选项:由 Amazon SageMaker 端点提供支持的实时端点和由 Amazon SageMaker 批量转换提供支持的批量推断。
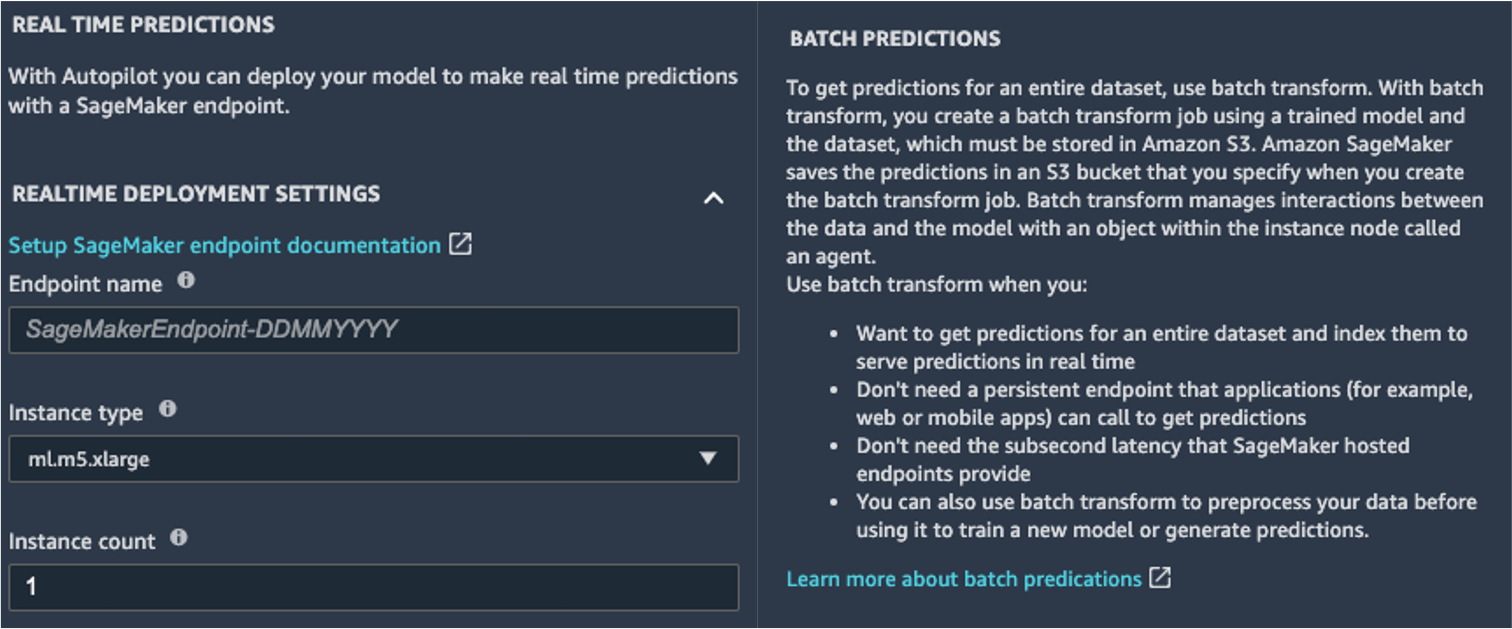
SageMaker 还提供了其他推理模式。要了解详情,请参阅部署推理模型。
要启用实时预测模式,您只需为端点提供名称、实例类型和实例计数即可。由于此模型不需要大量计算资源,因此,您可以使用初始计数为 1 且基于 CPU 的实例。您可以在 Amazon SageMaker 定价页面(在 On-Demand Pricing(按需定价)部分,选择 Real-Time Inference(实时推理)选项卡)详细了解不同类型的可用实例及其规格。如果您不知道应该为部署选择哪个实例,也可以让 SageMaker 使用 SageMaker Inference Recommender 根据您的 KPI 找到最适合您的实例。您还可以提供其他可选参数,说明是否要捕获到端点或来自端点的请求和响应数据。如果您打算监控模型,这可能很有用。您还可以选择要在响应中提供哪些内容,无论是预测还是预测概率、所有类别的概率以及目标标签都可以。
要运行批量评分作业,一次获取整组输入的预测,您可以从 AWS 管理控制台或通过 SageMaker Python 软件开发工具包启动批量转换作业。要详细了解批量转换,请参阅使用批量变换和示例笔记本。
定义训练管道
机器学习模型很少(如果有的话)被认为是静态且不变的模型,因为它们偏离了训练所依据的基准。现实世界中的数据会随着时间的推移而变化,并从中产生更多的模式和见解,根据历史数据训练的原始模型可能会(也可能不会)捕获这些模式和见解。要解决此问题,您可以设置训练管道,使用最新的可用数据自动对模型进行再训练。
在定义此管道时,数据科学家的选择之一是再次将 AutoML 用于训练管道。您可以从 AWS Boto3 SDK 调用 create_auto_ml_job() API,以编程方式启动 AutoML 作业。您可以通过 AWS Step Functions 工作流中的 AWS Lambda 函数调用此操作,也可以通过 Amazon SageMaker Pipelines 中的 LambdaStep 调用。
或者,数据科学家可以使用从 AutoML 作业中获得的知识、构件和超参数来定义完整的训练管道。您需要以下资源:
- 最适合使用案例的算法 — 您已经从 Canvas 生成的模型摘要中获得了这些信息。对于这个使用案例,涉及的是 XGBoost 内置算法。有关如何使用 SageMaker Python 软件开发工具包通过 SageMaker 训练 XGBoost 算法的说明,请参阅将 XGBoost 与 SageMaker Python 软件开发工具包结合使用。

- 由 AutoML 作业派生的超参数 — 可在可解释性部分中找到。使用 SageMaker Python 软件开发工具包定义训练作业时,您可以将其用作输入。

- 构件部分中提供的特征工程代码 — 您可以使用此代码在训练前预处理数据(例如,通过 Amazon SageMaker 处理),也可以在推理之前(例如,作为 SageMaker 推理管道的一部分)对数据进行预处理。

您可以将这些资源作为 SageMaker 管道的一部分进行组合。我们忽略了这篇文章中的实施细节,敬请关注有关此主题的更多内容。
结论
借助 SageMaker Canvas,您无需编写任何代码即可使用机器学习生成预测。业务分析师可以自主地将其用于本地数据集以及已存储在 Amazon Simple Storage Service (Amazon S3)、Amazon Redshift 或 Snowflake 中的数据。他们只需单击几下,即可准备和联接数据集、分析估计的准确性、验证哪些列具有影响力、训练性能最佳的模型以及生成新的单个或批量预测,所有这些都无需聘请专家数据科学家。然后,他们可以根据需要与数据科学家或 MLOPs 工程师团队共享模型,该团队将模型导入到 SageMaker Studio 中,并与分析师一起提供生产解决方案。
业务分析师可以独立地从其数据中获得见解,而无需获得机器学习专业的学位,也无需编写任何代码。数据科学家现在可以有更多时间从事更具挑战性的项目,从而更好地利用他们在 AI 和机器学习方面广泛的知识。
我们相信,这次新的合作将为您的企业构建更强大机器学习解决方案打开大门。现在,您的分析师可以提供有价值的业务见解,同时让数据科学家和机器学习工程师根据需要帮助优化、调整和扩展。
其他资源
- 要详细了解 SageMaker 如何进一步帮助业务分析师,请参阅面向业务分析师的 Amazon SageMaker。
- 要详细了解 SageMaker 如何允许数据科学家开发、训练和部署机器学习模型,请参阅面向数据科学家的 Amazon SageMaker。
- 有关 SageMaker 如何帮助 MLOPs 工程师使用 MLOPs 简化机器学习生命周期的更多信息,请参阅面向 MLOPs 工程师的 Amazon SageMaker。