亚马逊AWS官方博客
基于亚马逊云科技构建电动汽车电池告警预测平台
简介
近年来,我国新能源汽车行业呈现蓬勃发展的态势。主机厂已经收集了大量的电动车的车联网数据,包括三大类(静态车辆数据、实时处理数据和实时车辆告警数据)160多项数据。主机厂希望从这些数据中得到报警的统计和分析,并且希望延伸到报警的预测,可以及时召回可能发生故障的车辆或者主动推送更新软件到车端进行修复,降低电池事故造成的损失,提升客户的满意度。
该博客介绍了如何利用Amazon Web Services的服务组件快速搭建电动车电池告警预测平台,包括存储海量测试数据,构建基于Xgboost分类算法的电池故障报警预测模型,推理预测数据以及可视化的数据展示。
代码仓库
https://github.com/aws-samples/aws-bev-bms-battery-consistency-bias-alarm-prediction
架构概述

该解决方案是基于数据驱动来对电池单体一致性偏差报警事件进行预测,借助于Amazon Sagemaker,您可以快速便捷的构建自己的机器学习模型(如Xgboost,递归神经网络等),并完成模型训练,模型推理。该解决方案中使用Amazon DynamoDB和Amazon S3来存储预测事件的输入和推理结果。当您部署完该解决方案后,在Sagemaker Notebook中会预置一个基于Xgboost二分类的机器学习模型脚本(xgboost_beginner.ipynb)以及样例数据(series_samples.csv),运行该机器学习脚本可以实现预测模型的快速构建和自动部署。本解决方案支持的推理事件有两种方式:其一为用户直接使用POST请求携带输入特征数据获取推理结果,该方式是基于Amazon API Gateway和 Lambda实现;其二为用户上传收集到的批量电池数据(可以来源于您on-premise数据库,或实时车辆网收集到的电池数据)至Amazon S3桶,数据上传事件会自动触发Lambda进行推理。所有的POST请求推理和S3上传事件触发的推理均可以通过Apache Superset进行可视化,它是由 Fargate进行承载,方便您实时查看具体的电池单体一致性偏差报警事件。架构图中各个组件之间的关系用连接箭头表示,其具体含义分别为:
- 主机厂或电池厂商将采集的电池数据上传至 S3桶中,用于模型建模和训练;
- Sagemaker Notebook Instance获取电池数据;
- 在Sagemaker Notebook Instance中完成模型建模,训练和部署,部署后的Inference Model是一个Runtime Endpoint,它用来提供预测推理服务;
- 应用场景一:车辆网上传的数据推送到的S3桶,S3桶中新增加的Batch数据即为需要推理的数据;
- 应用场景一:新增加的Batch数据自动调用Lambda进行转发请求;
- 应用场景一:Lambda调用Sagemaker Runtime Endpoint进行前向推理;
- 应用场景一:前向推理的结果写入到Dynamo DB进行存储;
- 应用场景一:前向推理的结果写入到S3进行存储(供Superset可视化);
- 应用场景二:用户调用API进行前向预测推理,用户采用POST调用;
- 应用场景二:API Gateway将请求路由到Lambda函数;
- 应用场景二:Lambda调用Sagemaker Runtime Endpoint进行前向推理;
- 应用场景二:前向推理的结果写入到Dynamo DB进行存储;
- 应用场景二:前向推理的结果写入到S3进行存储(供Superset可视化);
- Superset后台部署在Fargate Service, 基于SQL数据查询访问实时推理结果的数据;
- Amazon Athena从Glue Data Catalog中的数据库和表中查询数据;
- Glue Data Catalog的表格Schema是对预测结果S3桶中记录的定义。
解决方案部署
部署可以在北京区,宁夏区,美东一区进行,若在国内部署需要开通ICP Exception。可以直接基于Cloudformation部署,cloudformation的模板下载链接进行,创建堆栈时参数保持默认值即可。
美东一区:
中国区(宁夏/北京):
数据分析/模型训练/模型部署
在解决方案部署完成之后,在Sagemaker控制台中会创建一个笔记本实例。内置了xgboost的脚本和电池样例数据集,用户在真实使用场景中可以基于自身的电池数据集来进行模型构建,训练和部署。
打开Sagemaker控制台,可以看到部署之后预置的笔记本实例:

点击 [打开Jupyter],进入界面如下:

打开 xgboost_beginner.ipynb,依次执行每一个代码块,便可以逐步进行数据加载,各维度数据分析与可视化,数据集划分,xgboost分类模型构建与训练,模型自动部署,模型性能测试等一系列操作。
样例数据集中包含了“车架号VIN”,“采集时间Date”,“总电压(V)”,“总电流(A)”,“电池单体电压最高值(V)”,“电池单体电压最低值(V)”, “最高温度值(℃)”, “最低温度值(℃)” 信息。最后一列的Label表征数据在该天是否发生了电池单体一致性差报警,0表示没有报警,1表示发生报警。在xgboost_beginner.ipynb脚本中,选取历史14天的样本并聚合在一起形成一个 14*6 维度的特征向量,基于该向量预测未来14天内是否出现电池一致性差报警,此问题被抽象成一个二分类问题。
在构建模型输入数据集时,首先将历史特征聚合成一个大的向量,并将未来14天内的电池一致性报警标签进行聚合,举例说明:对于第x天而言,第x-14天(含)到第x-1天(含)这共计14天的特征(维度为6)聚合成一个84维度的特征向量;若第x天(含)到第x+13天(含)这未来14天出现电池单体一致性报警,则该特征向量对应的分类标签为1;反之为0。通过滑窗操作对所有数据执行上述操作,提取所有的样本,再按照4:1划分为训练集和验证集。
完成模型训练后可以看到训练迭代过程中的error (loss)逐步收敛,如下图所示:

模型部署需要5分钟左右,保持脚本中的 sm_endpoint_name参数不变即可,在解决方案中lambda函数会以此名调用Sagemaker endpoint:

在xgboost模型部署完成之后在Sagemaker终端节点中会出现如下处于“InService”状态的推理节点。

继续执行xgboost_beginner.ipynb的代码块,可以对电池故障报警分类算法的性能作出评估,采用的性能指标包括:
- 真阳(True Positive): 实际上是正例的数据被分类为正例
- 假阳(False Positive): 实际上是反例的数据被分类为正例
- 真阴(True Negative): 实际上是反例的数据被分类为反例
- 假阴(False Negative): 实际上是正例的数据被分类为反例
- 召回率(Recall): Recall = TPR = TP / (TP + FN), 衡量的数据集中所有的正样本被模型区分出来的比例
- 精确率(Persion): Persion = TP / (TP + FP), 衡量的模型区分出来的正样本中真正为正样本的比例
- 假阳率(False Positive Rate, FPR): FPR = FP / (FP + TN), 衡量的是 被错分的反例 在所有反例样本中的占比
基于不同分类阈值绘制出ROC曲线(FPR-TPR),当选择的阈值越小,其TPR越大,FPR越大;ROC曲线下的面积约接近1.0说明模型越优。下图为示例数据训练后在验证集上的性能呈现。

基于POST请求调用触发推理
在Sagemaker推理节点部署成功后,你可以通过HTTP POST请求来调用电池预测推理服务,POST数据中携带特征数据,在该解决方案中以14天数据为特征,每一天包含“总电压(V)”,“总电流(A)”,“电池单体电压最高值(V)”,“电池单体电压最低值(V)”, “最高温度值(℃)”, “最低温度值(℃)”这六个维度的特征,共计84维数据,POST请求地址为cloudformation部署诚征的API Gateway地址后加上“inference”路由。基于curl调用示意如下所示:
基于S3桶批量数据上传触发推理
此解决方案还支持批量数据预测,测试数据可以从https://github.com/aws-samples/aws-bev-bms-battery-consistency-bias-alarm-prediction/blob/main/source/sagemaker/sample-data/test_batch_samples.csv下载,将此数据上传至部署账户中名为bev-bms-infer-<region_name>-<account_id>的S3桶中(该桶在部署时已经自动创建),数据上传事件会自动触发推理。
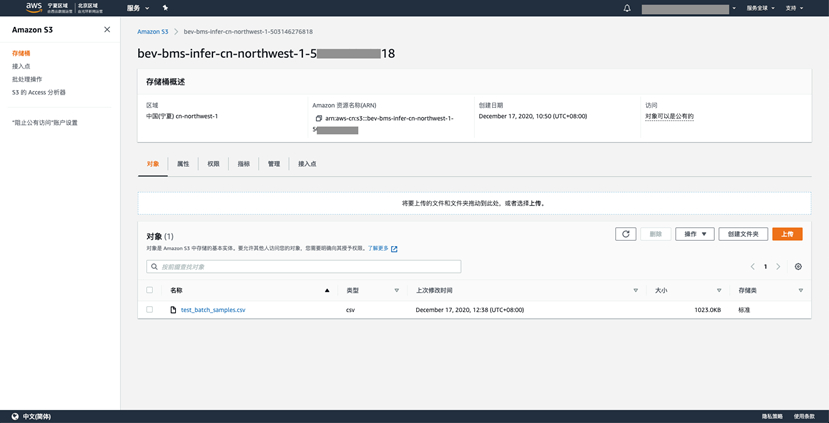
推理结果会实时写入到DynamoDB数据表中,如下所示:

Apache Superset配置
此解决方案基于Apache Superset来对预测的电池单体一致性偏差报警事件进行可视化,首先打开Cloudformation部署成功后的输出链接,如下所示:
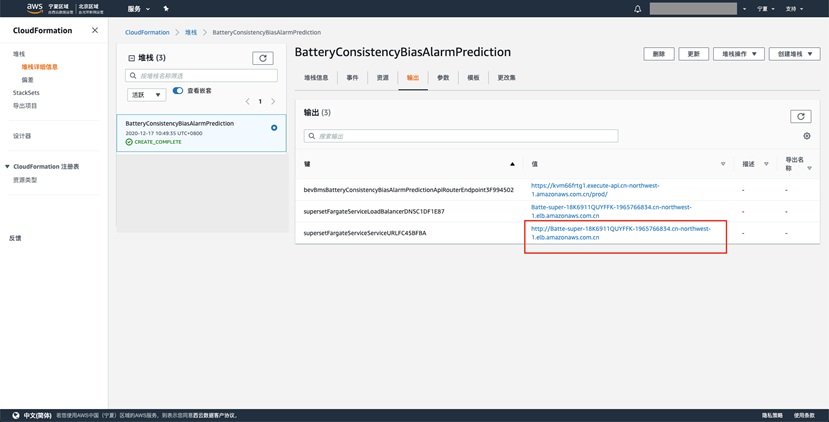
登录用户名和密码均为admin.
点击[Source]à[Databases],如下图所示:

点击右上角+号,创建Database,如下图所示:

添加Database,Database处输入“demo”, SQLAlchemy URI处输入“awsathena+rest://@athena.< region_name>.amazonaws.com.cn/default?s3_staging_dir=s3://bev-bms-events-<region_name> -<account_id >/query”,输入完成后可以点击[TEST CONNECTION]测试连通性,确认可以与Amazon Athena相连通。

滚动到最下面,点击[Save],出现如下界面:

推理事件可视化
点击Superset页面顶端导航栏[SQL Lab]à[SQL Editor],左侧依次选择Database, Schema, Table, 在SQL查询输入栏中输入查询语句,如:
查询结果如下图所示:

点击上图中的 [EXPLORE],选择排序方式为根据预测报警概率从高到低排序,如下图所示,可以清晰地看到推理结果中电池单体一致性偏差报警概率高的车辆VIN码,日期等信息。
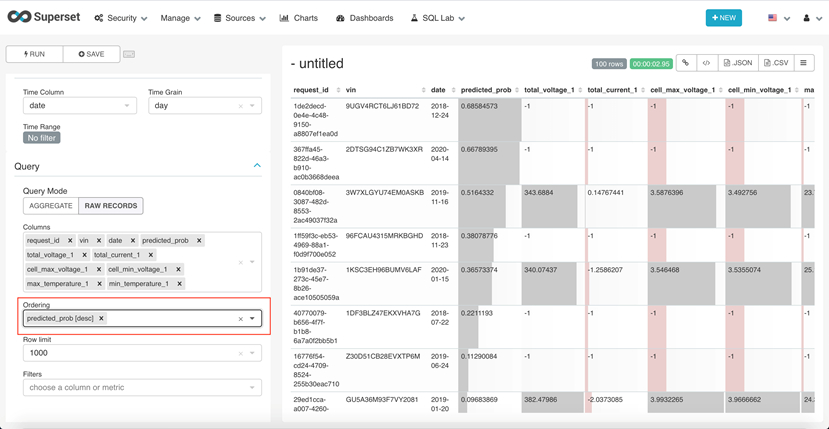
用户可以编写其他SQL语句来查询数据库表中的推理事件,如针对某一辆车,某个日期进行查询,等等。
总结
此解决方案提供了在亚马逊云上构建电动汽车电池单体一致性偏差预测解决方案,并提供REST API调用推理和批量数据推理功能,最后还支持使用Apache Superset进行推理结果可视化呈现。该解决方案适用于主机厂(OEM)或电池供应商来对电动汽车的电池健康情况进行监测和预测,同时适用于具有自主开发需求的OEM或电池供应商,可以基于该解决方案来自行开发算法模型,实现快速生产部署。