亚马逊AWS官方博客
使用Amazon Redshift ML构建机器学习应用
Amazon Redshift ML 使数据分析师和数据库开发人员可以在 Amazon Redshift 数据仓库中使用熟悉的 SQL 命令轻松创建、训练和应用机器学习模型。 借助 Redshift ML,用户可以利用 Amazon SageMaker,这是一项完全托管的机器学习服务,而无需学习新工具或语言。 只需使用 SQL 语句,便可利用Redshift 数据创建和训练 Amazon SageMaker 机器学习模型,然后使用这些模型进行预测。
Amazon Redshift 支持有监督学习,包括回归、二分类和多分类。回归是指预测连续值的问题,例如客户的总支出。二分类是指预测两种结果之一的问题,例如预测客户是否流失。多分类是指预测许多结果之一的问题,例如预测客户可能感兴趣的项目。数据分析师和数据科学家可以使用它来执行有监督学习,以解决范围包括预测、个性化或客户流失的各种问题。
在本篇文章中,我们将介绍使用标准 SQL 在Redshift 集群上使用机器学习。我们继续使用银行营销数据集,有关数据集的介绍,请参考第一篇《使用 Amazon SageMaker 构建机器学习应用》。首先使用Amazon Redshift的COPY命令把数据集导入到table中,然后使用CREATE MODEL方法创建模型,如下图所示,在创建模型的过程中,会调用Amazon SageMaker Autopilot,SageMaker Autopilot 将自动探索不同的解决方案以找到最佳模型,并通过Amazon SageMaker Neo将模型编译,最终将编译后的模型部署到Amazon Redshift Cluster中,通过Redshift Function调用模型进行预测。

1.首先登陆到AWS控制台,然后导航到Amazon Redshift页面,点击右侧的”Create cluster”按钮。

- 在”Cluster identifier”中填入集群的名称,例如”redshift-cluster-1″
- 选择”Free trial”
- 在”Admin user name”中填入”awsuser”
- 在”Admin user password”中填入密码,密码长度至少8位,其中至少包含一个数字,一个大写字母以及一个小写字母。


等待几分钟后,Redshift集群会创建成功。
2.为Redshift集群创建Role
Redshift集群需要用到三种策略。
- AmazonS3FullAccess
- AmazonRedshiftFullAccess
- AmazonSageMakerFullAccess
登陆到控制台,导航到IAM,并进入到Roles页面,点击“Create role”。
在AWS service中选择“Redshift”,在“Select your use case”中选择“Redshift – Customizable”,点击“Next:Permission”,
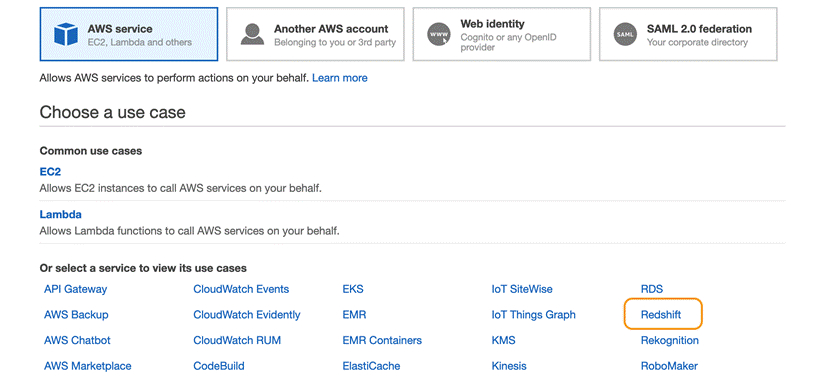
选择3个Policy Name:AmazonRedshiftFullAccess,AmazonS3FullAccess,AmazonSageMakerFullAccess
保持默认,点击”Next:Tags”,保持默认,点击”Next:Review”,在Role Name中输入”testredshiftrole”,点击”Create role”。
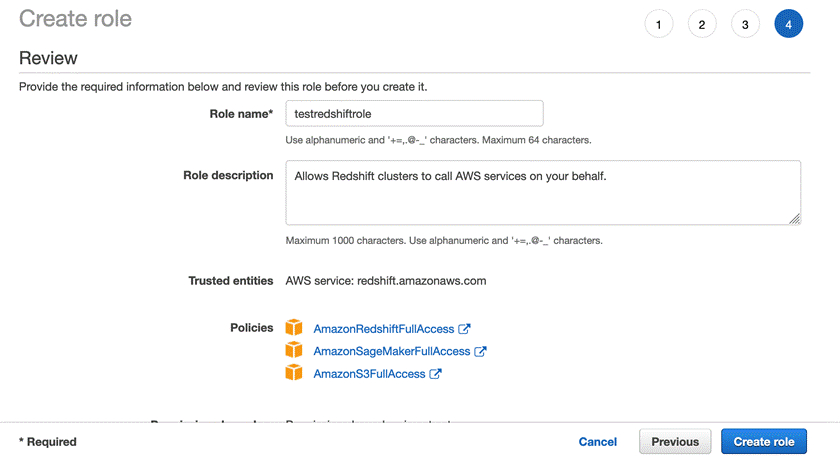
在Redshift ML训练过程中,会调用到SageMaker AutoML的功能,因此要增加对SageMaker服务的访问权限。
在”testredshiftrole”中点击”Trust relationships”,”Edit trust relationship”,追加以下的json代码。
点击”Update trust policy”,保存后效果如下图所示。

在”testredshiftrole”的详细信息页面,记录下ARN。



3.关联角色
在刚刚创建的集群页面,点击”Properties”

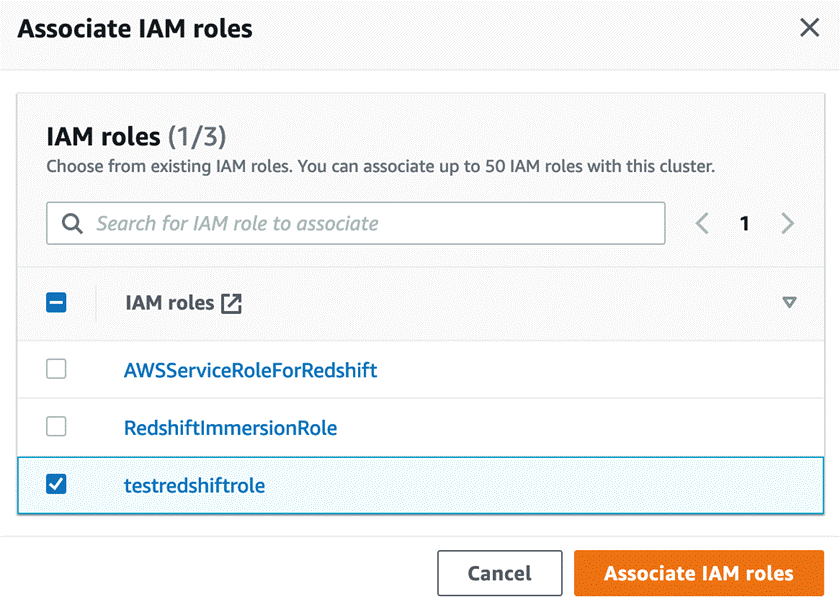
点击”Associate IAM role”按钮,选择刚刚创建的”testredshiftrole”,如下图所示。

4.导入数据集
首先从链接下载数据集(https://archive.ics.uci.edu/ml/machine-learning-databases/00222/),压缩包中有三个文件,我们把bank-additional-full.csv作为训练集,bank-additional.csv作为测试集。 为了方便识别训练文件和测试文件,我们把bank-additional-full.csv重命名为bank-train.csv,bank-additional.csv改名为bank-test.csv。把修改后的两个文件上传到S3存储桶中。 
返回到Redshift的页面,在左侧的导航栏中点击“Query editor”,点击“Connect to database”


在Query 1中输入以下内容,并点击”Run”按钮
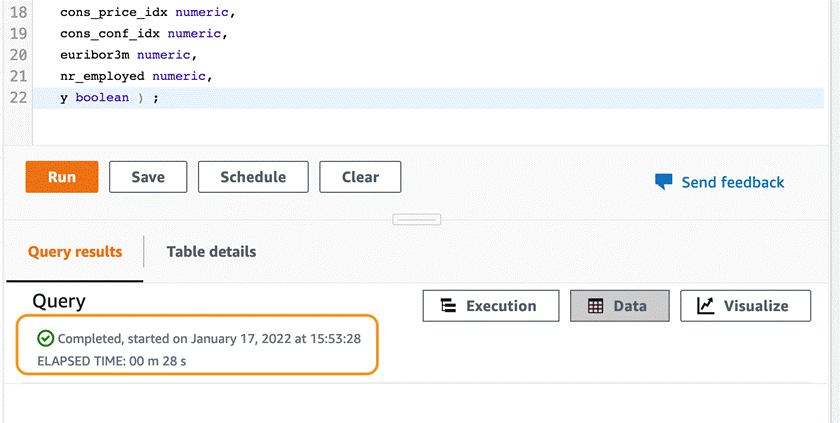
导入数据,新建editor Query 2
点击”Run”
<<YOUR_BUCKET_NAME>>:替换为数据所在存储桶的名称
<<YOUR_REGION_NAME>>:替换为Redshift集群所在的区域(例如us-east-1)
<<COPY_YOUR_ROLE_ARN>>:替换为在上文testredshiftrole详情页面的Role ARN

在editor中输入以下SQL语句,检查数据是否正确导入。

同样建立建立表并导入测试数据。
<<YOUR_BUCKET_NAME>>:替换为数据所在存储桶的名称 <<YOUR_REGION_NAME>>:替换为Redshift集群所在的区域(例如us-east-1) <<COPY_YOUR_ROLE_ARN>>:替换为在上文testredshiftrole详情页面的Role ARN5.创建模型
在editor中输入以下代码。 注意在替换<<S3_BUCKET_NAME_WITHOUT_S3_PREFIX >>的名字时,直接输入BUCKET的名称,不需要加s3前缀。 CREATE MODEL 命令以异步方式运行,在底层Redshift会使用到SageMaker AutoML的功能。我们设置最长的运行时间为1小时。 在这个SQL语句中,我们可以看到创建了一个SQL函数func_model_bank_marketing,在后面我们会用到这个函数进行预测。<< S3_BUCKET_NAME_WITHOUT_S3_PREFIX >>:替换为数据所在存储桶的名称,注意这里不带S3前缀。 <<COPY_YOUR_ROLE_ARN>>:替换为在上文testredshiftrole详情页面的Role ARN 新建一个editor,运行以下脚本,可以查看运行状态。 show model model_bank_marketing; 我们可以看到,模型正在训练。

切换到SageMaker页面中的”Training Jobs”,我们可以看到在redshift创建模型的过程中,启动了多个训练任务以自动寻找最佳的模型。

大约1个小时后,训练完成。我们反复运行上面的命令,查询”Model State”,当训练完成后,状态变为”Ready”。运行以下脚本,查看在测试集的准确率。其中num_correct表示在测试集上预测正确的数量,total表示总共测试集的数量,num_correct/total表示预测的准确率。

运行以下的SQL语句,显示预测结果。
WITH term_data AS ( SELECT func_model_bank_marketing( age,job,marital,education,"default",housing,loan,contact,month,day_of_week,duration,campaign,pdays,previous,poutcome,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed) AS predicted
FROM bank_details_inference )
SELECT
CASE WHEN predicted = 'Y' THEN 'Yes-will-do-a-term-deposit'
WHEN predicted = 'N' THEN 'No-term-deposit'
ELSE 'Neither' END as deposit_prediction,
COUNT(1) AS count
from term_data GROUP BY 1;
结论
本篇文章介绍了使用Amazon Redshift ML进行模型创建和预测的基本方法。对于数据仓库管理员,不需要掌握机器学习的理论,就可以轻松的使用SQL创建和管理机器学习模型。同时,Amazon Redshift ML的模型也支持部署到Amazon Sagemaker Endpoint中,实现全托管的模型在线服务,有兴趣的读者可以参考Amazon Redshift ML在线文档。