亚马逊AWS官方博客
使用 Amazon DynamoDB 构建可扩展的梦幻足球数据库模型
Original URL: https://aws.amazon.com/blogs/database/modeling-a-scalable-fantasy-football-database-with-amazon-dynamodb/
- 可扩展性:DynamoDB 提供几乎无限的吞吐量和存储空间,采用灵活的定价模式,可随您的工作负载扩展。
- 完全托管:DynamoDB 可以处理大多数管理任务,例如补丁和备份,这样您便可以专注于游戏的开发。DynamoDB 的无服务器架构意味着您不必预置或管理实例或存储。它可以自动扩展容量以满足工作负载需求,提供按使用量付费的定价,您只需创建表即可开始操作。
- 全局表:DynamoDB 全局表提供完全托管、多区域的双活数据库,可为大规模扩展的全球应用程序提供高速的本地读写性能。
- Amazon Web Services(AWS)集成:DynamoDB 与多种其他服务集成,例如用于流式传输项目更改的 Amazon Kinesis Data Streams、用于日志记录的 AWS CloudTrail、用于调用操作的 AWS Lambda以及其他需要使用的服务。要了解更多信息,请参阅 DynamoDB 功能页面。
以下架构图描绘了一款生产就绪性游戏,该游戏运行在 AWS 上并由 DynamoDB 支持。在这篇文章中,我们将在热门梦幻足球游戏类型的背景下,重点介绍 DynamoDB 表的设计概念。

图 1:以 AWS 为后端的生产就绪型游戏示例架构
在这篇文章中,我们将讨论虚拟的梦幻足球游戏的访问模式,然后演示我们为满足这些模式而设计的 DynamoDB 表架构。我们重点介绍梦幻足球联赛游戏,在这种游戏中,好友们可以开展竞赛,用现实世界中的足球运动员创建最佳球队名单,并进行排名赛。DynamoDB 是游戏玩家使用的应用程序的后端数据库,随着足球赛季进展,玩家用它来管理球队和跟踪得分。我们讨论在对 DynamoDB 表建模时的注意事项,用以支持对游戏中功能(例如球队选择、分数和排行榜)的访问模式。
如何在 DynamoDB 中进行数据建模
如果您不熟悉 DynamoDB 数据建模,请务必注意,您不应使用关系数据库的建模技术在 DynamoDB 中对数据建模。使用 DynamoDB 时,您必须在创建数据模型之前定义访问模式。对于大多数工作负载,其目标是创建一个可以在任意规模下都表现出高性能且经济高效的数据模型。为此,您必须知道应用程序的访问模式属性,例如数据大小、数据配置和数据速度。
一般而言,打造 DynamoDB 数据库架构需要四个步骤:
- 了解使用案例。
- 构造实体关系图(ERD,Entity-Relationship Diagram)。
- 列出您的查询或伪查询(定义访问模式)。
- 将伪查询映射到对应的 DynamoDB 操作。
为包括 Amazon Keyspaces(Apache Cassandra 兼容)在内的大多数非关系数据库设计架构时,这些技术同样适用。作出这种权衡的好处包括规模大、性能高。要了解使用案例,通常需要记录工作负载的要求(事务速率、延迟和持久性)。如果您不知道访问模式是什么,那么应该研究类似的应用程序。对于梦幻足球使用案例,您应该知道联赛、球队和足球运动员(球员)代表什么,以及游戏中如何访问每个实体。接下来,您应该创建一个 ERD,用于帮助您发现实体之间的关系。创建 ERD 后,您可以创建排序的查询列表,根据查询在游戏中的使用频率确定先后顺序。此时,您还可以创建一些示例数据来模拟查询和响应。最后,使用适用于 DynamoDB 的 NoSQL Workbench 或电子表格,将您的查询映射到 DynamoDB 架构。映射是定义分区架构、二级索引和写入分片(如果您的设计需要分片)的过程。
梦幻足球游戏数据库(ERD 和访问模式)
无论您是使用 DynamoDB 构建新应用程序还是从其他数据存储迁移,数据建模流程中的第一步通常都是创建 ERD。在确定应用程序中的实体及其关系后,您可以使用任何常用的 ERD 表示格式来构建 ERD。
在我们游戏的 ERD 中有五个不同的实体。Gamer(玩家)实体存储有关玩游戏的玩家的信息(玩家是通过手机或 Web 浏览器玩游戏的用户)。玩家创建球员的 TeamSheets(球员名单),可以参加任意数量的 Leagues(联赛)。为简单起见,在本例中,指定的一支球队只能参加一个联赛。TeamSheet(球员名单)实体(也称为比赛周球员名单)是由玩家每周创建的 Footballers(球员)集合,其大小固定。Footballers(球员)可以加入一个联赛中的多只球队。Footballers(球员)属于一个 Position(位置),例如中场或守门员。请注意,我们没有为足球俱乐部创建实体;它们可以建模为 Footballer(球员)中的一个属性,因为该应用程序没有需要按照足球俱乐部进行排序或查询的读取模式。
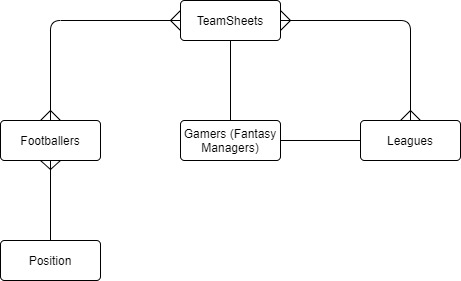
图 2:梦幻足球数据库的 ERD
访问模式:
- 按玩家 ID 查找 Gamer 详细信息。
- 获取某个 Gamer 的 TeamSheet。
- 按球员 ID 查找 Footballer 的详细信息。
- 获取给定 Position 的 Footballer。
- 获取一个 League 中的所有 Gamer,按照 totalPoints(总积分)排序。
注意:在实际游戏中,梦幻足球游戏会有其他访问模式。我们选择这些常见模式用于演示的目的。
建模实体项目
在为 DynamoDB 建模架构时,您应尝试以合理的成本和可接受的性能,构造项目和项目集合来满足访问模式的要求。项目集合的定义是具有相同分区键值但排序键值不同的一组项目。如果主键定义合适,DynamoDB 的灵活架构允许您在同一个表中存储不同类型的实体,例如 Footballer 或 League。这样可以进行更高效的跨实体查询。对于此示例应用程序数据库,我们首先对顶级实体进行建模。
在下表中,请注意我们为分区键(PK)和排序键(SK)使用通用名称。这是因为我们计划利用 DynamoDB 的架构灵活性,在表中存储多个实体类型。我们使用的另一种建模技术是为 PK 值加上实体名称前缀。Gamer 实体的模式为 Gamer#<GamerName>,Footballer 实体则使用模式 Footballer#<FootballerName>。我们这样做的原因有二。首先,为了满足基表中的主键唯一性约束,并在使用通用标识符的情况下,避免表中不同项目类型之间的重叠。其次,如果我们选择使用此属性作为二级索引的排序键,则这样可以在排序键表达式中使用选择性的 begins with(开头为)模式。这些基本实体满足第一种(按照玩家 ID 获取 Gamer)和第三种(按照球员 ID 获取 Footballer)访问模式。
| 主键 | 属性 | |||||||
| 分区键(PK) | 排序键(SK) | |||||||
| Gamer#Tito12121 | Gameer#Tito12121 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | . |
| gamer | 1995 | South Africa | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||
| Gamer#Seyi89000 | Gamer#Seyi89000 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |
| gamer | 2005 | USA | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||
| – – – | – – – | – – – | – – – | – – – | – – – | – – – | – – – | |
| Footballer#KwesiManu#9 | Footballer#KwesiManu#9 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – |
| footballer | 12 | 51 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Striker | – – | ||
| Footballer#PauloSantos#10 | Footballer#PauloSantos#10 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – |
| Footballer | 9.5 | 22 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Midfielder | – – | ||
在 DynamoDB 中,顾名思义,分区键定义了数据如何分布在底层存储层中。选择高基数的分区键属性值非常重要,因为在一段时间以后,随着应用程序中请求率的增加,这可以实现数据的均匀分布。要了解更多信息,请参阅Choosing the Right DynamoDB Partition Key(选择合适的 DynamoDB 分区键)。如下表所示,您可以使用分区键快速标识实体。分区键值作为根(实体)项目的排序键重复,因此可以将它们与其他项目类型区分开来。
排序键通常用来与其他实体建立一对多关系的模型。但是,对于顶级实体项目,我们将重复使用分区键,将其作为表示实体数据的项目的排序键。例如,Gamer Tito12121 的 PK 值为 Gamer#Tito12121,而主项目的 SK 值 Gamer#Tito12121 表示 Tito12121。您也可以使用其他命名惯例,例如 <metadata> 或 <root>,但是如果您需要创建二级索引,并使用基本排序键作为全局二级索引的分区键,则这可能会成为扩展限制。
一对多关系建模
在 DynamoDB 中有多种方法可以对一对多关系进行建模。我们将在以下部分中探讨项目集合 – 如何在 DynamoDB 中对一对多关系建模中介绍的一些技术。
| 主键 | 属性 | |||||||
| 分区键(PK) | 排序键(SK) | |||||||
| Gameer#Tito12121 | Gamer#Tito12121 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | . |
| gamer | 1995 | South Africa | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||
| Gamer#Seyi89000 | Gamer#Seyi89000 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |
| gamer | 2005 | USA | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||
| – – – | – – – | – – – | – – – | – – – | – – – | – – – | – – – | |
| Footballer#KwesiManu#9 | Footballer#KwesiManu#9 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – |
| footballer | 12 | 51 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Striker | – – | ||
| Footballer#PauloSantos#10 | Footballer#PauloSantos#10 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – |
| Footballer | 9.5 | 22 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Midfielder | – – | ||
对全局二级索引使用分区键过载
我们可以使用 Position 作为全局二级索引(GSI)的分区键值,用于获取踢指定位置的所有球员。通过 GSI,您可以使用替代键查询表中的数据。如果没有 GSI,我们只能查询基表的主键。在示例中,我们创建了一个名为 GSI1 的 GSI,具有两个名为 GSI1_PK 的属性,用于保存 GSI 分区键值。与基表架构类似,我们在 GSI 键中使用分区键过载,以允许不同的实体驻留在同一个索引中。在应用这种设计模式时,我们必须使用实体作为 GSI1_PK 的前缀,这就得到了 GSI1_PK 值 Position#Midfielder。此 GSI 符合第四种访问模式:按 Position 获取 Footballers。
| 主键 | 属性 | |||||||||
| 分区键(PK) | 排序键(SK) | |||||||||
| Gamer#Tito12121 | Gamer#Tito12121 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 1995 | South Africa | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| GW#01#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| GW#02#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| – – – | – – – | – – – | – – – | – – – | – – – | |||||
| – – – | – – – | – – – | – – – | – – – | – – – | – – – | ||||
| Gamer#Seyi89000 | Gamer#Seyi89000 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 2005 | USA | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| Footballer#KwesiManu#9 | Footballer#KwesiManu#9 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| footballer | 12 | 51 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Striker | – – | ||||
| Footballer#PauloSantos#10 | Footballer#PauloSantos#10 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| Footballer | 9.5 | 22 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Midfielder | – – | ||||
我们在这里的做法是过载 GSI,这使得我们能够获取给定 Position 上的所有 Footballers,同时允许以后将 GSI 用于其他查询。使用 GSI,您可以选择只投射自己感兴趣的属性,这比投射所有属性的性能更好,成本效益更高。例如,我们通过查询 GSI1:GSI1_PK = “Position#Midfielder”,可以获得 Position 为中场的所有 Footballers(实体)。我们选择不为 Position 使用 GSI 写入分片,因为对于给定 Position 的球员的基数很低。有关这种设计技术的更多信息,请参阅对选择性表查询使用全局二级索引写入分片。
使用项目集合
DynamoDB 设计的一个原则是将相关数据保存在一起。这意味着您在 Gamer 下,将关于玩家的 TeamSheets(比赛周球员名单)的信息,与有关 Gamer 实体的重要详细信息存储在一起。这种使用项目集合预联接数据的技术减少了为提取项目往返查询表的次数,从而缩短了检索时间,但代价是表中的某些数据会重复。这种技术可用于优化计算,这与关系数据库正好相反,在关系数据库中,您可以联接来自不同表的单独项目以节省存储成本。在下图中,我们在 GW#(N) 的 SK 值下为 Gamer#Tito12121 添加了 TeamSheets,此处的 GW 表示比赛周(Game Week),N 表示比赛周编号。请注意比赛周 01 的 TeamSheet 属性值映射到多个 Footballers。我们决定不使用称为邻接列表的更高级的技术,原因如后文所述,因为我们想在 TeamSheet 中一次性添加或删除所有球员,以保持其固定大小限制。这种设计满足了第二种访问模式:获取某个 Gamer 的 TeamSheet。如下图所示,为 Gamer#Tito12121 显示了三个项目:一个根项目记录和两个球队名单记录,因此我们可以确定,所有具有 PK = Gamer#Tito12121 的项目位于同一个项目集合中。这种建模技术在一个 PK 下构造项目集合。当您有这样的表示相关数据的项目集合时,您可以使用查询 API 操作同时检索一个分区键下的多个项目。
| 主键 | 属性 | |||||||||
| 分区键(PK) | 排序键(SK) | |||||||||
| Gamer#Tito12121 | Gamer#Tito12121 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 1995 | South Africa | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| GW#01#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| GW#02#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| – – – | – – – | – – – | – – – | – – – | – – – | |||||
| – – – | – – – | – – – | – – – | – – – | – – – | – – – | ||||
| Gamer#Seyi89000 | Gamer#Seyi89000 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 2005 | USA | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| Footballer#KwesiManu#9 | Footballer#KwesiManu#9 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| footballer | 12 | 51 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Striker | – – | ||||
| Footballer#PauloSantos#10 | Footballer#PauloSantos#10 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| Footballer | 9.5 | 22 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Midfielder | – – | ||||
管理多对多关系建模
您可以使用几种策略来对多对多关系建模。在我们的梦幻足球应用程序数据库示例中,多对多关系的例子包括 Footballer-TeamSheet 以及 Gamer-League 关系。
使用数据复制
在 DynamoDB 中,对多对多关系建模的最常用策略之一是复制数据。在我们的梦幻足球游戏中,适合这种策略的关系的一个很好的例子是 Gamer 与 Footballer 的关系。这里的一种典型的访问模式是获取玩家的球员名单中的球员。如下表所示,Gamer 创建的球员名单中包含为每个比赛周选择的 Footballers。在关系数据库中,您通常会通过创建单独的 TeamSheet 表来建模,该表使用外键将 Footballers 链接到球员名单。在 DynamoDB 中,您可以在 Gamer 实体下复制 TeamSheet 数据,这使您可以通过单个 GetItem 请求提取某个玩家的球员名单中的所有球员。使用此策略时,请务必记住,当重复关系中的相关实体数量有限,并且重复的信息不会经常更改或不可变时,此策略最有效。
| 主键 | 属性 | |||||||||
| 分区键(PK) | 排序键(SK) | |||||||||
| Gamer#Tito12121 | Gamer#Tito12121 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 1995 | South Africa | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| GW#01#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| GW#02#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| – – – | – – – | – – – | – – – | – – – | – – – | |||||
| – – – | – – – | – – – | – – – | – – – | – – – | – – – | ||||
| Gamer#Seyi89000 | Gamer#Seyi89000 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 2005 | USA | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| Footballer#KwesiManu#9 | Footballer#KwesiManu#9 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| footballer | 12 | 51 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Striker | – – | ||||
| Footballer#PauloSantos#10 | Footballer#PauloSantos#10 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| Footballer | 9.5 | 22 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Midfielder | – – | ||||
使用邻接列表
在图论中,使用邻接列表来表示多对多关系是用于有限图的常见表示形式。用 DynamoDB 术语来说,您可以将实体之间的关系建模为表中的一个项目。在我们的梦幻足球游戏中,Gamer 和 League 关系可以使用此策略建模。为此,我们在顶级实体 Gamer 下,为玩家参加的每个联赛创建一个项目。
| 主键 | 属性 | |||||||||
| 分区键(PK) | 排序键(SK) | |||||||||
| Gamer#Tito12121 | Gamer#Tito12121 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 1995 | South Africa | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| GW#01#TeamSheet | Type | TeamSheet | ||||||||
| gamer | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| GW#02#TeamSheet | Type | TeamSheet | ||||||||
| gamer | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| – – – | – – – | – – – | – – – | – – – | – – – | |||||
| League#1234 | Type | GameweekPoints | TotalPoints | |||||||
| league | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||||
| League#3456 | Type | GameweekPoints | TotalPoints | |||||||
| league | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||||
| League#5678 | Type | GameweekPoints | TotalPoints | |||||||
| league | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||||
| – – – | – – – | – – – | – – – | – – – | ||||||
| – – – | – – – | – – – | – – – | – – – | – – – | – – – | – – – | |||
| Gamer#Seyi89000 | Gamer#Seyi89000 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 2005 | USA | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||
| GW#01TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| – – – | – – – | – – – | – – – | – – – | – – – – | |||||
| League#1234 | Type | GameweekPoints | TotalPoints | |||||||
| league | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||||
| Footballer#KwesiManu#9 | Footballer#KwesiManu#9 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| footballer | 12 | 51 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Striker | – – | ||||
| Footballer#PauloSantos#10 | Footballer#PauloSantos#10 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| Footballer | 9.5 | 22 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Midfielder | – – | ||||
通过这个模型,我们可以提取任何给定玩家参加的所有联赛,如以下架构所示。
| 主键 | 属性 | |||||||||
| 分区键(PK) | 排序键(SK) | |||||||||
| Gamer#Tito12121 | Gamer#Tito12121 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 1995 | South Africa | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| GW#01#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| GW#02#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| – – – | – – – | – – – | – – – | – – – | – – – | |||||
| League#1234 | Type | GameweekPoints | TotalPoints | |||||||
| league | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||||
| League#3456 | Type | GameweekPoints | TotalPoints | |||||||
| league | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||||
| League#5678 | Type | GameweekPoints | TotalPoints | |||||||
| league | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||||
| – – – | – – – | – – – | – – – | – – – | ||||||
| – – – | – – – | – – – | – – – | – – – | – – – | – – – | – – – | |||
| Gamer#Seyi89000 | Gamer#Seyi89000 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 2005 | USA | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||
| Footballer#KwesiManu#9 | Footballer#KwesiManu#9 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| footballer | 12 | 51 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Striker | – – | ||||
| Footballer#PauloSantos#10 | Footballer#PauloSantos#10 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| Footballer | 9.5 | 22 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Midfielder | – – | ||||
为了使用 PK = League#<LeagueID> 通过单个请求让玩家在某个联赛中玩游戏,我们可以添加一个名为 GSI2 的 GSI,其中 League# 是分区键(上表中未显示)。在 GSI 中,我们的分区键 GSI2_PK 的值是 League#<LeagueID>,排序键 GSI2_SK 的值是 TotalPoints。在应用程序中,我们必须确保 League 和 Gamer 的键与 GSI2 主键保持同步。为了满足第五种访问模式(获取给定 League 的所有 Gamer,按照 TotalPoints 排序),我们可以使用分区键查询给定联赛,获取联赛中按照 TotalPoints 排序的所有玩家,无需在客户端排序。
访问模式和查询映射
在建模练习结束时,使用示例查询条件以及用于满足访问模式的表或二级索引键更新访问模式表。
| . | 访问模式 | 查询条件 |
| 1 | 按玩家 ID 查找 Gamer 详细信息 | 表上的主键,PK = ”Gamer#Tito12121” |
| 2 | 获取某个 Gamer 的 TeamSheet。 | 表上的主键,PK = ”Gamer#Tito12121”,
SK = ”GW#01#TeamSheet” |
| 3 | 按球员 ID 查找 Footballer 的详细信息 | 表上的主键,PK = ”Footballer#PauloSantos#10” |
| 4 | 获取给定 Position 的 Footballer | 使用 GSI1,GSI1_PK = ”Position#Midfielder” |
| 5 | 获取一个 League 中的所有 Gamer,按照 totalPoints(总积分)排序 | 使用 GSI2, GSI2_PK = ”League#1234” |
结论
在本文中,您学习了设计可扩展数据模型的方法,该模型用于在 DynamoDB 中存储梦幻足球的游戏比赛数据。您还了观看了我们如何应用技术的演练,例如非规范化、每个索引多个实体类型以及邻接列表,以便根据要求将数据访问模式映射到表和索引,从而为应用程序提供服务。有关 AWS 上游戏设计模式的更多深入信息,请参阅 Introduction to Scalable Gaming Patterns on AWS(AWS 上的可扩展游戏模式简介)。此外,有关在 AWS 上开发游戏的其他资源,请参阅 AWS for Games。
关于作者
 Stanley Chukwuemeke 是一名数据库解决方案架构师。他帮助客户设计数据库解决方案并将其数据库解决方案迁移到 AWS。
Stanley Chukwuemeke 是一名数据库解决方案架构师。他帮助客户设计数据库解决方案并将其数据库解决方案迁移到 AWS。
 Sean Shriver 是一位高级NoSQL 解决方案架构师。Sean 帮助高端和战略客户进行 Amazon DynamoDB 的迁移、设计审查、AWS SDK 优化和概念验证测试。
Sean Shriver 是一位高级NoSQL 解决方案架构师。Sean 帮助高端和战略客户进行 Amazon DynamoDB 的迁移、设计审查、AWS SDK 优化和概念验证测试。
 Kehinde Otubamowo 是一位高级NoSQL 解决方案架构师。他热衷于数据库现代化,喜欢分享构建经济高效且大规模运行的数据库解决方案的最佳实践。
Kehinde Otubamowo 是一位高级NoSQL 解决方案架构师。他热衷于数据库现代化,喜欢分享构建经济高效且大规模运行的数据库解决方案的最佳实践。