亚马逊AWS官方博客
Amazon Aurora 新功能 – 直接通过数据库使用机器学习
机器学习使您能够更好地了解您的数据。但是,大部分结构化的数据存储于何处呢? 在数据库中! 今天,若要将机器学习与关系数据库中的数据结合使用,您需要开发一个自定义应用程序来读取数据库中的数据,然后再应用机器学习模型。开发此应用程序需要多种技能才能与数据库进行交互和使用机器学习。这是一个新的应用程序,现在,您必须管理其性能、可用性和安全性。
我们能否更轻松地对关系数据库中数据应用机器学习呢? 甚至是利用现有的应用程序?
从现在开始,Amazon Aurora 已本地集成了两种 AWS 机器学习服务:
- Amazon SageMaker,一项让您能够快速构建、训练和部署自定义机器学习模型的服务。
- Amazon Comprehend,一项使用机器学习来查找文字中的见解的自然语言处理 (NLP) 服务。
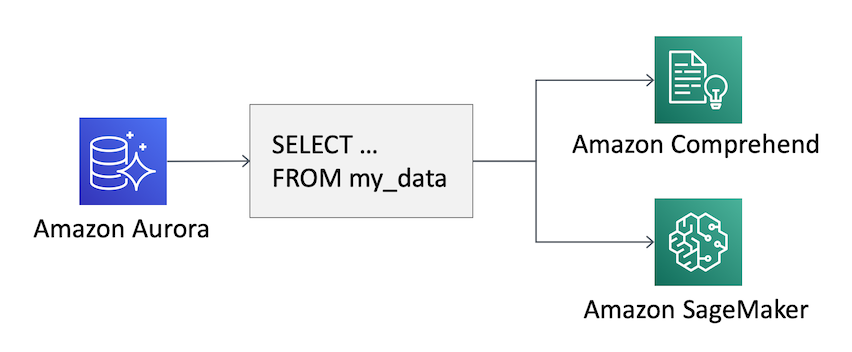
通过使用这项新的功能,您可以在查询中使用 SQL 函数来对关系数据库中的数据应用机器学习模型。例如,您可以使用 Comprehend 检测用户评论的情绪,或者应用通过 SageMaker 构建的自定义机器学习模型来估计客户“流失”风险。 客户流失是一个掺杂着“变化”和“转变”的词语,用于描述客户停止使用您的服务。
您可以大型查询的输出(包括机器学习模型中的其他信息)存储到一个新的表格中,或者通过仅更改客户端运行的 SQL 代码来在应用程序中交互式使用此功能,无需任何机器学习经验。
让我们来看两个(第一个是通过使用 Comprehend,第二个是通过使用 SageMaker) Aurora 数据库可以为您带来哪些帮助的示例。
配置数据库权限
第一步是授予数据库访问您想要使用的服务的权限:Comprehend、SageMaker 或两者。 在 RDS 控制台中,创建一个新的 Aurora MySQL 5.7 数据库。在该数据库可用后,在区域终端节点的连接和安全选项卡中,找到管理 IAM 角色部分。
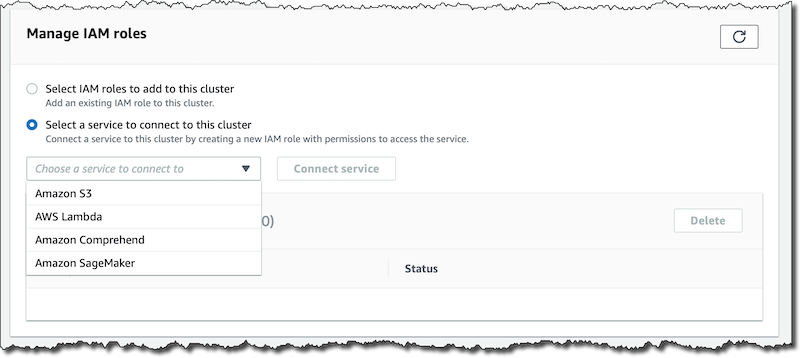
此时,将 Comprehend 和 SageMaker 连接到此数据库集群。对于 SageMaker,我需要提供已部署机器学习模型的终端节点的 Amazon 资源名称 (ARN)。如果您想要使用多个终端节点,则需要重复执行此步骤。控制台负责创建服务角色,让 Aurora 数据库访问这些服务,以便新的机器学习模型集成工作。

通过 Amazon Aurora 使用 Comprehend
通过使用 MySQL 客户端连接到数据库。为了运行测试,我创建了一个用于存储博客平台评论的表格,并插入了一些示例记录:
CREATE TABLE IF NOT EXISTS comments (
comment_id INT AUTO_INCREMENT PRIMARY KEY,
comment_text VARCHAR(255) NOT NULL
);
INSERT INTO comments (comment_text)
VALUES ("This is very useful, thank you for writing it!");
INSERT INTO comments (comment_text)
VALUES ("Awesome, I was waiting for this feature.");
INSERT INTO comments (comment_text)
VALUES ("An interesting write up, please add more details.");
INSERT INTO comments (comment_text)
VALUES ("I don’t like how this was implemented.");若要检测表格中的评论情绪,我可以使用 aws_comprehend_detect_sentiment 和 aws_comprehend_detect_sentiment_confidence SQL 函数:
SELECT comment_text,
aws_comprehend_detect_sentiment(comment_text, 'en') AS sentiment,
aws_comprehend_detect_sentiment_confidence(comment_text, 'en') AS confidence
FROM comments;
aws_comprehend_detect_sentiment 函数将返回最合适的输入文本情绪:积极、消极或中性。aws_comprehend_detect_sentiment_confidence 函数将返回情绪检测的置信度,0(完全不可信)- 1(完全可信)。
通过 Amazon Aurora 使用 SageMaker 终端节点
与使用 Comprehend 所做的类似,我可以访问 SageMaker 终端节点来丰富存储在数据库中的信息。为了查看实际的使用案例,让我们以此文开头处提到的客户流失为例。
手机运营商拥有的历史记录上存在两种最终结果:一种是客户流失;另一种是继续使用服务。我们可以使用此历史记录信息来构建机器学习模型。作为模型的输入,我们瞄准的是当前的订阅套餐、一天中不同时段通过手机通话的客户数量以及呼叫客户服务的频率。
以下是我的客户表的结构:
SHOW COLUMNS FROM customers;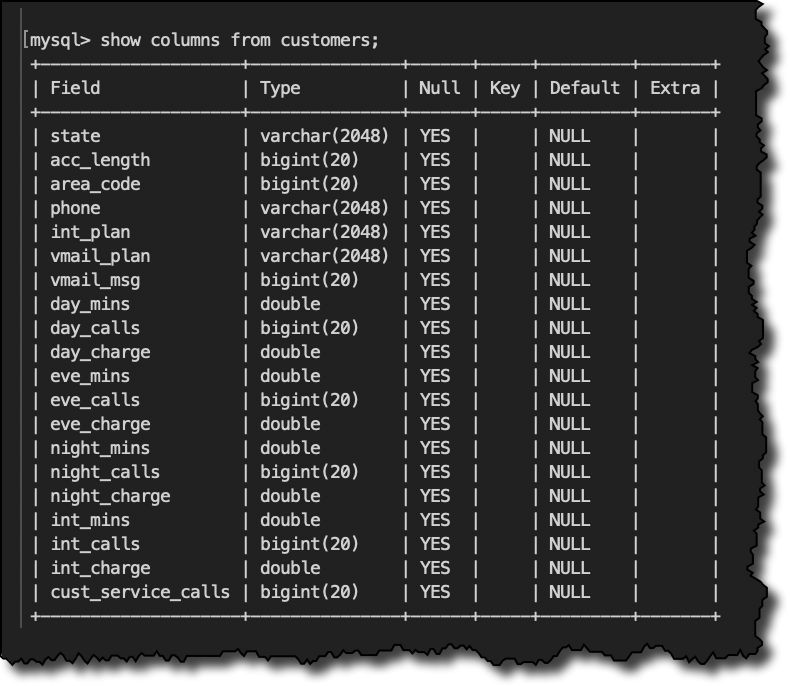
为了能够确定客户流失风险,我使用XGBoost 算法在此示例 SageMaker 笔记本之后训练了一个模型。当该模型创建完毕之后,我将它部署到一个托管的终端节点。
当 SageMaker 终端节点处于服务状态时,我返回到控制台的管理 IAM 角色部分,以授予 Aurora 数据库访问终端节点 ARN 的权限。
现在,我将创建一个新的 will_churn SQL 函数,为终端节点输入提供模型所需的参数:
CREATE FUNCTION will_churn (
state varchar(2048), acc_length bigint(20),
area_code bigint(20), int_plan varchar(2048),
vmail_plan varchar(2048), vmail_msg bigint(20),
day_mins double, day_calls bigint(20),
eve_mins double, eve_calls bigint(20),
night_mins double, night_calls bigint(20),
int_mins double, int_calls bigint(20),
cust_service_calls bigint(20))
RETURNS varchar(2048) CHARSET latin1
alias aws_sagemaker_invoke_endpoint
endpoint name 'estimate_customer_churn_endpoint_version_123';您可以看到,该模型通过使用客户的手机订阅详细信息和服务使用模式来识别客户流失风险。使用 will_churn SQL 函数,我对我的 customers 表格运行了一次查询,根据我的机器学习模型对客户进行标记。为了存储查询结果,我创建了一个新的 customers_churn 表格:
CREATE TABLE customers_churn AS
SELECT *, will_churn(state, acc_length, area_code, int_plan,
vmail_plan, vmail_msg, day_mins, day_calls,
eve_mins, eve_calls, night_mins, night_calls,
int_mins, int_calls, cust_service_calls) will_churn
FROM customers;让我们看一看 customers_churn 表格中的一些记录:
SELECT * FROM customers_churn LIMIT 7;
很幸运,前面 7 位客户显然不会流失。但总体情况如何呢? 存储 will_churn 函数的结果后,我可以对 customers_churn 表格运行 SELECT GROUP BY 语句。
SELECT will_churn, COUNT(*) FROM customers_churn GROUP BY will_churn;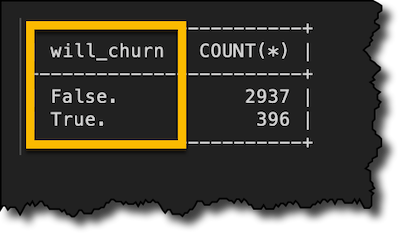
从这里开始,我就可以深入了解哪些因素导致我的客户流失。
当我创建新版本的机器学习模型以及新的终端节点 ARN 时,我可以重新创建 will_churn 函数,而无需更改我的 SQL 语句。
现已推出
新的机器学习集成已于今天在 Aurora MySQL 5.7 中推出,其中 SageMaker 集成已正式推出,Comprehend 集成提供预览版。您可以在文档中了解更多信息。我们即将推出其他引擎和版本:Aurora MySQL 5.6 并且 Aurora PostgreSQL 10 和 11 也即将推出。
Aurora 机器学习集成已在基础服务可用的所有区域推出。例如,如果 Aurora MySQL 5.7 和 SageMaker 在某一区域均可用,则您可以使用 SageMaker 集成。如需完整的服务可用性列表,请参阅 AWS 区域表。
使用集成不会额外收费,您只需以正常费率支付基础服务费用。使用 Comprehend 时,请注意查询的大小。 例如,如果对客户服务网页中的用户反馈进行情绪分析,若要联系做出特别积极或消极评论的客户以及每天做出 10,000 条评论的客户,您需要支付 3美元/天。 为了降低成本,请记住要存储结果。
对关系数据库中存储的数据应用机器学习模型从未如此简单。快来告诉我您打算用它来构建什么样的应用程序吧!
– Danilo