亚马逊AWS官方博客

给 Openclaw瘦身-利用Nova MME 和 S3 Vector实现Skill按需召回
本文介绍一种针对 OpenClaw 的智能Skills召回方案,基于 Amazon Bedrock Nova Multimodal Embeddings 和 Amazon S3 Vector,通过向量语义检索实现skill按需召回,将每次对话注入的技能描述 Token 降低约 90%,并提升响应速度。
2026 年度首批 AWS 大侠揭晓!
我们非常高兴地宣布,三位杰出的开发者社区领导者成为 AWS 大侠。他们代表了让 AWS 社区充满活力的核心力量。除了分享专业技术知识,他们还积极搭建连接、建立真诚的人际联结,并为他人开辟成长之路。从在山区村落开创云文化,到跨大洲推动网络安全教育,这些大侠用行动诠释了真正的领导力不仅体现在技术专业知识上,更体现在我们构建的社区和所影响的人生上。
AWS 一周综述:Amazon S3 推出 20 周年、Amazon Route 53 Global Resolver 正式推出等(2026 年 3 月 16 日)
二十年前的上周,Amazon S3 于 2006 年 3 月 14 日公开发布。虽然 Amazon Simple Storage Service 通常被认为是定义云基础设施的基础存储服务,但最初的简单对象存储服务已发展成为范围和规模要大得多的服务。
让 Kiro 和 Claude Code 响应 IM 消息:用 ACP Bridge 打造异步 AI 编程工作流
AI 编程助手如 Kiro CLI、Claude Code 能力日益强大,但使用场景局限于本地终端,难以满足移动办公和团队协作需求。本文介绍 ACP Bridge——一个将本地 CLI 编程助手通过 ACP 协议暴露为 HTTP 服务的桥接工具,结合 OpenClaw Gateway 和 AWS 基础设施,实现从 Discord 消息触发异步 AI 编程任务的完整闭环。
使用 AWS Route 53 构建高可用 DNS 解析服务:从多主多备到智能健康检测的最佳实践
介绍DNS服务在健康监测/多主多备/zone备份的最佳实践
大规模视频合并与转码
本文将分享我们如何利用AWS服务构建一套高效、经济的视频处理系统,在有限时间内完成2500部短剧(每部80-120集)的合并与转码任务。这个项目不仅展示了云计算在媒体处理领域的强大能力,更重要的是展现了如何在成本、性能和开发复杂度之间找到最佳平衡点。
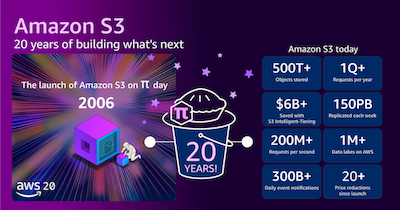
Amazon S3 二十周年:回望初心,共筑未来
二十年前的今天,即 2006 年 3 月 14 日,Amazon Simple Storage Service(Amazon S3)悄然上线。
在Amazon EKS上部署OpenClaw AI Agent:基于Kata Containers的企业级沙箱实践
在Amazon EKS上部署OpenClaw AI Agent:基于Kata Containers的企业级沙箱实践
为 Amazon S3 通用存储桶引入账户区域命名空间
今天,我们宣布推出 Amazon Simple Storage Service(Amazon S3)的一项新功能,您可以使用该功能在自己的账户区域命名空间中创建通用存储桶,从而在数据存储需求规模和范围增长时简化存储桶的创建和管理。您可以跨多个 AWS 区域创建通用存储桶名称,确保所需的存储桶名称始终可供您使用。
OpenClaw 安全和功能增强实践
本文记录了我在 AWS EC2 上部署 OpenClaw后,围绕安全防护和功能增强两条主线所做的一系列配置。不是官方教程,而是实际踩坑后的工程实践。