亚马逊AWS官方博客

从X86到AWS Graviton4:合合信息图像识别应用的性能突破之旅
本文分享了合合信息将其图像识别应用从x86架构迁移到AWS Graviton ARM架构完整实践过程。通过精心的规划和实施,该项目不仅实现了3倍的性能提升,还在业务量翻倍的情况下将实例数量减少了61%,每台实例处理能力提升491%,显著优化了总拥有成本(TCO)。
基于视频理解的智能视频剪辑指南
利用生成式AI多模态模型用于视频理解从而进行视频编辑的指南,通过多模态大模型对视频内容进行深入理解,在此基础上提供了一套智能剪辑的功能集合,用于简化视频编辑工作流,提高视频创作效率,从而为观众提供更友好和丰富多样的视觉体验。
全新 Amazon Route 53 Global Resolver:统一、安全的全球 DNS 解析服务(预览版)
亚马逊云科技推出的 Amazon Route 53 Global Resolver 填补了全球 DNS 统一入口的架构空白。它不仅是混合云场景下统一 DNS 策略的利器,更是移动应用规避 DNS 污染、实现全球一致性体验的理想方案。本文从“企业网络架构”与“终端应用开发”两个核心场景出发,深入解析其差异化定位;并结合实战经验,分享了关于 DoH/DoT 协议细节(如 EDNS0 Token 传递)、Access Source 限制以及私有 Hosted Zone 覆盖逻辑的独家“避坑”指南。
使用 Kiro 规范驱动开发加速数据质量建设
本文将围绕规范驱动开发理念,在典型数仓场景下,利用Kiro AI IDE使用Redshift MCP 进行数据采样及血缘探索,自动生成Amazon Glue Data Quality规则及脚本,并且通过 Glue MCP 部署质量任务,生成质量报告,旨在帮助数据工程团队快速落地质量管理。
从 Intel 到 AWS Graviton 4:一次降本增效的技术迁移实践
从 Intel 到 AWS Graviton 的迁移是一次成功的降本增效实践。通过充分的性能验证、完善的 DevOps 支持、规范化的迁移流程,我们不仅实现了显著的成本节省,还获得了更好的性能表现。
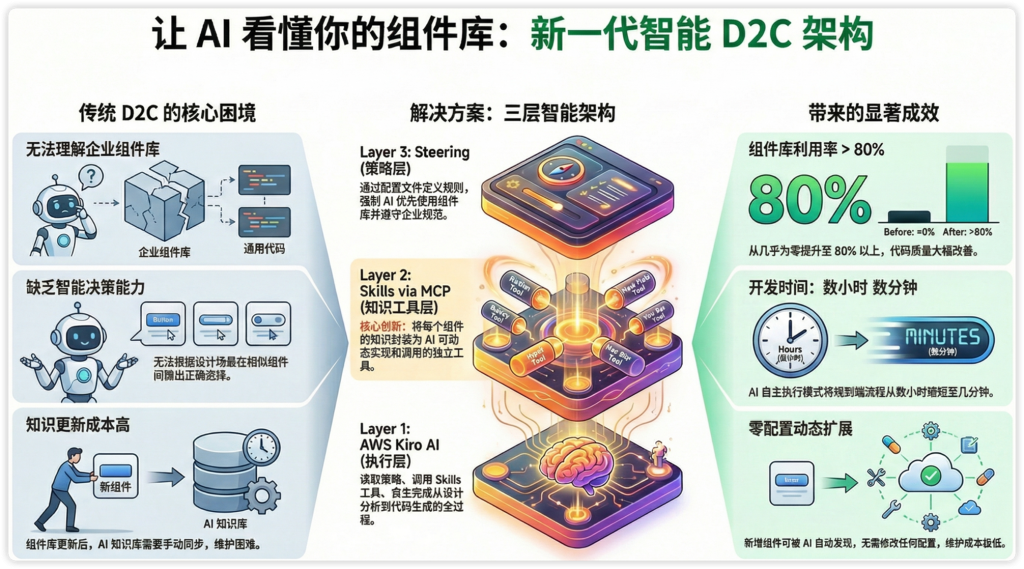
让 AI 理解你的组件库:新一代智能 D2C架构 — 基于 AWS Kiro MCP Skills 的智能转换实践
本文探讨了如何利用 AWS Kiro IDE、Model Context Protocol (MCP) 和 Skills 构建智能 D2C 平台。核心创新在于通过 Skills 将组件知识封装为可调用工具,结合 Steering 策略引导,使 AI 能够自动发现、理解并正确使用企业组件库。
使用Amazon Quick Suite定制成本分析智能体
在云计算时代,成本管理已成为企业优化云资源使用的关键环节。Amazon Quick Suite凭借其内置的生成式AI能力,让成本分析变得更加智能和直观。本文将详细介绍如何使用Quick Suite构建一个智能化的AWS成本分析系统,让您能够通过自然语言提问的方式快速获取成本洞察。
智能体驱动测试变革:让智能体成为测试第一性 之三 用 Web Bot Auth 为 AgentCore Browser Tool 打造可信身份
Web Bot Auth 的出现,为测试智能体提供了一个稳定、可识别的访问身份,让自动化流程在现代网站防护体系中能够更顺滑地运行。测试不再频繁被 CAPTCHA 或安全策略打断,也不再依赖脆弱的绕过方案,而是以一种更清晰、可控的方式与网站端协同。对于测试团队来说,这意味着更少的干扰、更高的效率,以及更容易维护的自动化体系。让智能体以更合理的方式工作,让测试过程回归本身应有的连续性与可预期性。
CloudFront 部署小指南(二十三)- 全新网站分发与安全防护固定月费套餐(Flat-rate)介绍与配置指导
Amazon Web Services 现已推出全新的网站分发与安全防护固定月费套餐(Flat-rate)方案,提供零超额费用(no overages) 的简化计费模式。该方案由 Amazon CloudFront 提供,将全球内容分发(CDN)与多项 AWS 服务和功能整合为一个按月计费的价格,无论你的网站因爆红导致流量激增,还是遭遇 DDoS 攻击,都不会产生额外费用,该方案大大提升了用户部署对外业务的在成本预估的便捷性与确定性,为用户提供一站式的方案。
构建弹性身份基础设施:AWS IAM 和 STS 的多区域容灾最佳实践
在设计云架构时,身份层的多区域容灾设计与应用层同样重要——通过部署紧急破窗机制、使用区域STS端点和配置多区域身份联合,可确保在区域故障时仍能维持身份认证和访问控制的业务连续性。