亚马逊AWS官方博客
在 Amazon EMR 上运行带有多种 GPU 实例类型的深度学习框架
今天,AWS 很高兴地宣布 Amazon EMR 将支持 Apache MXNet 和新一代 GPU 实例类型,让您可以在进行机器学习工作流程和大数据处理的同时运行分布式深度神经网络。此外,您还可以在采用 GPU 硬件的 EMR 群集上安装并运行自定义深度学习库。通过使用深度学习框架,您可以使用新工具包来处理多种使用案例,包括无人驾驶车辆、人工智能、个性化医疗和计算机视觉。
Amazon EMR 提供一个 Hadoop 托管框架,可以让您轻松、快速且经济高效地使用 Apache Spark、Apache Hive、Presto、Apache HBase 和 Apache Flink 等框架处理 Amazon S3 中的大量数据。您可以低成本安全、高效地处理大量大数据使用案例,包括日志分析、Web 索引、数据转换 (ETL)、财务分析、科学模拟、实时处理和生物信息。
多年来,EMR 一直致力于帮助您运行可扩展的机器学习工作负载。2013 年,我们增加了对 Apache Mahout 的支持,以帮助您使用 Apache Hadoop MapReduce 来运行分布式机器学习工作负载。2014 年,客户开始利用 Apache Spark (我们在 2015 年增加了官方支持),以便利用 Spark ML 中提供的各种开源机器学习库来轻松构建可扩展的机器学习管道。
在过去 2 年内,我们还增加了对 Apache Zeppelin 笔记本、易于安装的 Jupyter 笔记本以及适用于交互式 Spark 工作负载的 Apache Livy 的支持,从而让数据科学家可以轻松快速地开发、培训以及将机器学习模型投入生产。EMR 的按秒计费方式以及使用 Amazon EC2 竞价型实例可实现的高达 80% 的成本节约,使您可以低成本轻松运行大规模的机器学习管道。
现在,您可以更轻松地在 Amazon EMR 上实施深度学习。我们增加了对 Apache MXNet (0.12.0) (一种可扩展的深度学习框架)、Amazon EC2 P3 和 P2 实例、EC2 计算优化型 GPU 实例的支持,并预先加载了所需的 GPU 驱动程序。现在借助最新的 GPU 硬件,您只需单击几下即可快速轻松地创建适用于分布式培训的可扩展式安全群集。此外,您还可以安装并使用 BigDL 或 CaffeOnSpark 等自定义深度学习库,方法是在自定义 Amazon Linux AMI 上预加载这些库或使用引导操作来自定义群集。此外,EMR 将很快增加对 TensorFlow (另一个热门的深度学习框架) 的支持。
借助 EMR,您可以在开发工作的数据探索和预处理阶段轻松开发和培训深度学习模型。首先,您可以轻松且经济高效地使用各种开源大数据框架 (包括 Apache Spark、Apache Hadoop 和 Apache Hive) 来探索和处理 S3 中的大量数据集。
其次,除了使用 S3 或群集上 HDFS 中存储的预处理数据来开发、培训和运行深度学习模型以外,您还可以使用 MXNet 和 Spark 预测或执行推理。您将按秒付费,并且可以设置自已愿意为 EC2 竞价型实例支付的最高价,还可以使用 Auto Scaling。然后,您可以在完成工作负载后关闭群集并停止付费,从而进一步降低实验和生产的成本。
在 EMR 控制台中,您只需单击几下即可使用 Spark、MXNet、Ganglia 监控和 Zeppelin 笔记本快速创建一个拥有一到数千个节点的 EMR 群集。
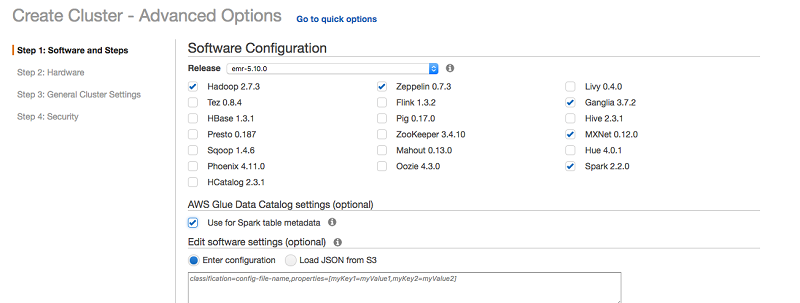
启动群集后,即可打开 Zeppelin 笔记本并开始使用 Spark 和 MXNet 探索数据和构建模型。

借助 EMR,您可以通过以下任一操作轻松监控和调试应用程序:
- 直接在 EMR 控制台中查看详细的 Spark 应用程序历史记录
- 使用 Amazon CloudWatch 指标
- 查看群集上的 Hadoop UI
- 将应用程序日志直接推送到 S3
- 将 Ganglia 用作资源使用指标
我们计划在不久的将来发布更多文章,并提供基于 EMR 利用 MXNet 和其他框架进行大规模深度学习的示例和最佳实践。有关如何入门的更多信息,请参阅 Amazon EMR 文档。
作者简介
 Jonathan Fritz 是 Amazon EMR 的首席产品经理。他领导团队的产品管理,并致力于使针对海量数据的分析和机器学习更加轻松。他在闲暇时喜欢去陌生城市旅行、参加现场音乐会和进行户外探索。
Jonathan Fritz 是 Amazon EMR 的首席产品经理。他领导团队的产品管理,并致力于使针对海量数据的分析和机器学习更加轻松。他在闲暇时喜欢去陌生城市旅行、参加现场音乐会和进行户外探索。