What’s the Difference Between Cassandra and HBase?
Page topics
- What’s the difference between Cassandra and HBase?
- Similarities: Cassandra and HBase
- Architectural differences: Cassandra vs. HBase
- Performance: Cassandra vs. HBase
- Other key differences: Cassandra vs. HBase
- When to use: Cassandra vs. HBase
- Summary of differences: Cassandra vs. HBase
- How can AWS help with your Cassandra and HBase requirements?
What’s the difference between Cassandra and HBase?
Apache Cassandra and Apache HBase are NoSQL databases that store data in a non-tabular format. Both store data as key-value stores on big data infrastructure to manage massive data volumes accurately and efficiently. However, they do have architectural differences that suit different use cases better. For example, Cassandra provides fast read and write performance, and HBase provides greater data consistency. HBase is also more effective for handling large, sparse datasets. Organizations use Cassandra and HBase for different big data use cases.
Similarities: Cassandra and HBase
Cassandra and HBase are two NoSQL databases that can store, process, and retrieve billions of datasets. They have overlapping similarities in the following areas.
Big data application
You can store massive volumes of unstructured, non-relational data with both Cassandra and HBase. They differ from a traditional database system, which stores data in simple rows of columns. You can use Cassandra and HBase to store images, audio, videos, and other unstructured data types for large-scale processing.
Open source
The Apache Software Foundation publishes and manages Cassandra and HBase as open source projects. HBase was developed from the concept introduced by Google BigTable and publicly released by Apache in 2008. Cassandra is an initiative that was created to solve Facebook's inbox search issues. It uses certain features of BigTable and others from Amazon Dynamo.
Scalability
You can scale HBase to meet growing data demands by adding more region servers to the HBase cluster. The NoSQL database system can then distribute data nodes to new regions when they exceed a certain capacity. A Cassandra cluster can also support multiple nodes to scale its data management capabilities. By adding more nodes, you can effectively distribute data evenly and prevent traffic bottlenecks.
Data recovery
Data nodes in both Cassandra and HBase are fault-tolerant. In Cassandra, each node supports data replication. A write operation is automatically issued to all of the nodes that are assigned to the particular data. HBase has a similar data duplication approach, which is automated by the Hadoop Distributed File System (HDFS) that it runs on. The HDFS creates and maintains data duplicates on different servers. Both NoSQL databases duplicate data nodes in different physical networks based on the replication factor to reduce the risks of network-wide failure.
Write path
Both Cassandra and HBase organize data into columns. When storing data, each database looks for the appropriate column family, which holds related information together. Both databases also write the data to the log files when the database is appending or storing them to the column.
Architectural differences: Cassandra vs. HBase
Cassandra and HBase operate with different characteristics of the CAP theorem. The CAP theorem specifies that distributed systems can possess two of the following traits at any given time:
- Consistency
- Availability
- Partition tolerance
Because partition tolerance is mandatory for databases storing massive datasets, Cassandra and HBase differ in availability and consistency. Cassandra has high availability and partition tolerance because of its peer-to-peer node arrangement. HBase provides consistency with partition tolerance because a single HBase primary replicates data to all nodes.
Next, we explain further architectural differences in how both databases manage data requests.
Data model
Both Cassandra and HBase organize data into groups, rows, and columns, but each database does so with different layouts. In Cassandra, columns of related data are stored in rows under a broader category called a keyspace. For example, a Cassandra database might contain the following keyspace, column families, and cell arrangement:
- Keyspace : CustomerOrders
- Column family: Client
- ID, FirstName, LastName
- Column family: Orders
- ID, Item, Price
- Column family: Client
The Client column family sits in a partition above the Orders column family. In practical applications, a keyspace stacks multiple family columns together.
The HBase architecture has a layout that resembles that of traditional relational databases. Instead of having an ID for each column family, HBase uses sequential row keys in a table. Then it arranges columns that belong to the same column family next to each other for dataeasy retrieval. Here's an example:
- Table; CustomerOrders
- Row Key, Column Family: Client {First Name, LastName}, Column Family: Order {Item, Price}
Read about relational databases
Key components
Cassandra uses a technique called consistent hashing to enable each node to find specific data quickly in its peer-to-peer network. Its key components include the memtable, commit log, and SS tables. Together, they form the writing path for the nodes, data centers, and clusters in the Cassandra architecture.
HBase sits on top of the HDFS. It uses the HBase primary, region server, and Zookeeper to provide data management.
Cassandra provides data management and data storage independently, and HBase requires external systems for data storage capabilities.
Core design
Cassandra runs on the active-active architecture, where each node responds to writes and requests. Even if a particular node doesn’t store the requested data, it retrieves them from other nodes with a peer-to-peer communication method called the gossip protocol.
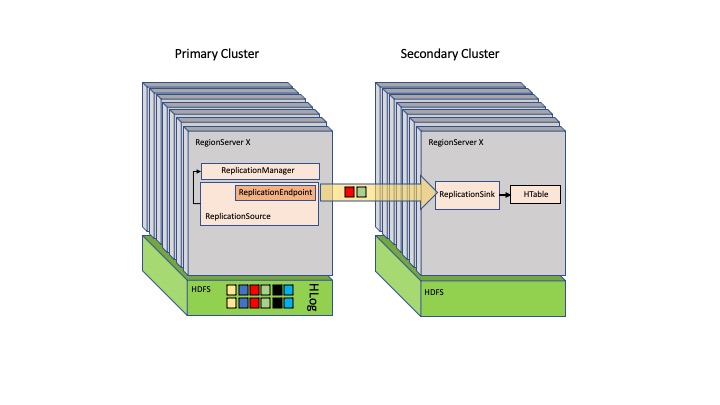
HBase uses a primary-secondary setup, where the HBase primary has control over other node's region servers. The HBase architecture presents a single point of failure if there are no replicas of the HBase primary. You can duplicate multiple HBase primary nodes, but only one takes charge of all region servers.
The following image shows the primary-secondary setup in HBase.
Query language
Cassandra enables data manipulation in the database with Cassandra Query Language (CQL). You use CQL to add, remove, or update records in descriptive instructions that are similar to SQL. The HBase query language consists of basic shell commands that take more effort to learn.
Performance: Cassandra vs. HBase
Both Cassandra and HBase provide high-speed access to large datasets for big data analytics. The databases show performance differences in the following aspects.
Latency
Latency is the time gap between sending an instruction to the database system and storing or retrieving data. Generally, HBase shows lower latency as the number of data reads and writes increases. The opposite is true for Cassandra, which shows larger delays as it fetches more data.
Throughput
Throughput measures the number of reads or writes operations that a database handles every second. HBase maintains a consistent throughput of 100,000–200,000 operations but demonstrates an increase after hitting 250,000 operations. Cassandra's throughput increases as it writes or reads more data.
Read performance
A read operation in Cassandra involves finding the exact location of the stored data on the partition table. If the search involves a secondary key or non-partition table, Cassandra takes longer to search every node in the cluster. Also, data inconsistencies happen when several nodes contain different versions of the same data.
HBase has a better read performance than Cassandra because it writes all data to a single server. Unlike in Cassandra, reading data in HBase doesn’t require the database system to search through a partition table. The HDFS that HBase uses to store data provides bloom filters and block caches, which speeds up data retrieval.
Write performance
Cassandra completes a write operation faster than HBase. With Cassandra, you can write data to the log and cache simultaneously. HBase doesn’t support concurrent writing. Instead, the HBase client application goes through the Zookeeper to start a write operation, with the HBase primary providing the address for storing data. The additional steps in HBase slow down the data-writing process.
Other key differences: Cassandra vs. HBase
You can use both Cassandra and HBase to build data science applications, but slight differences influence the decision to choose one over the other.
Security
With Cassandra, you can regulate access to the records' row level. It also provides SSL encryption to protect data exchange between nodes. Unlike Cassandra, HBase provides additional cell-level encryption and encryption and authentication features.
Data partitioning
Cassandra supports ordered partitioning, and it can scan the sequentially ordered records by using a column as a partition key. Although this might be helpful, ordered partitioning complicates load balancing, with multiple writes taking place on a single node. An HBase table doesn't support ordered partitioning.
Nodes communication
In Cassandra architecture, seed nodes are the key points for inter-cluster communications. These nodes use the gossip protocol to move data between different clusters. HBase uses an active HBase primary node to coordinate communication between several region servers. In this architecture, data movement is negotiated by the Zookeeper protocol.
When to use: Cassandra vs. HBase
Both Cassandra and HBase databases can help different types of big data applications. Next, we share which distributed database would work better than the other in different circumstances.
Availability vs. consistency
Cassandra is suitable for use cases that require frequent data writing, but it’s not optimized for frequently updating or deleting data. For example, organizations use Cassandra to build messaging systems, interactive data processing solutions, and real-time sensor data storage. HBase is better for applications that require data consistency and frequent processing. For example, banking, healthcare, and telecom solutions use HBase to analyze large volumes of data.
Database setup
Cassandra is easier to set up because it's a standalone product with all the necessary database components. Unlike Cassandra, HBase relies on several Hadoop components—such as Zookeeper, HDFS primary, and HDFS DataNode—to run. Setting it up might be simple, but maintaining multiple interdependencies could prove challenging in real-life applications. If you’re already using Hadoop infrastructure, you might find migrating to HBase to be easier than migrating to Cassandra.
Summary of differences: Cassandra vs. HBase
|
Cassandra |
HBase |
|
|
Core design |
Uses active-active architecture. All nodes process read/write requests. |
Uses primary-secondary architecture. HBase primary controls several region servers. |
|
Key components |
Memtable, commit log, and SS tables. |
HBase primary, region server, and Zookeeper. |
|
Data model |
Store rows of related column families in keyspace. |
Column families arranged horizontally with a sequential row key. |
|
Query language |
Uses Cassandra Query Language. |
Uses shell command. |
|
Latency |
Higher latency with more data fetches. |
Lower latency with more data operations. |
|
Throughput |
Throughput increases with more data operations. |
Throughput increases after a certain number of operations. |
|
Read performance |
Slow read. Refers to partition table for read location. Data inconsistencies can occur. |
Better read performance and data consistency. |
|
Write performance |
Better write performance. Writes to log and cache concurrently. |
Additional steps. Goes through Zookeeper and HBase primary. |
|
Security |
Regulate access up to role level. |
Regulate access up to cell level. |
|
Data partitioning |
Supports ordered partitioning. |
Doesn’t support ordered partitioning. |
|
Nodes communication |
Uses gossip protocol. |
Uses Zookeeper protocol. |
How can AWS help with your Cassandra and HBase requirements?
Amazon Web Services (AWS) provides scalable cloud database services that you can use to implement data science technologies efficiently and affordably. Instead of manually provisioning the underlying infrastructure, you can use the following AWS services to support your Cassandra and HBase databases:
- Amazon Keyspaces (for Apache Cassandra) is an online database service for running high-throughput Cassandra workloads. With Amazon Keyspaces, you can scale applications while maintaining response times in single-digit millisecond response time.
- With Amazon EMR, you can deploy HBase clusters for large-scale data processing applications. Running HBase on EMR improves data recoverability by backing up stored data on Amazon Simple Storage Service (Amazon S3).
Get started with big data analytics on AWS by creating an account today.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages