¿Cuál es la diferencia entre las bases de datos relacionales y las no relacionales?
¿Cuál es la diferencia entre las bases de datos relacionales y no relacionales?
Las bases de datos relacionales y no relacionales son dos métodos de almacenamiento de datos para aplicaciones. Una base de datos relacional (o base de datos SQL) almacena los datos en formato tabular con filas y columnas. Las columnas contienen atributos de datos, mientras que en las filas hay valores de datos. Se pueden vincular las tablas de una base de datos relacional para obtener información más profunda sobre la interconexión entre diversos puntos de datos. Por otra parte, las bases de datos no relacionales (o bases de datos NoSQL) utilizan diversos modelos de datos para acceder a estos y administrarlos. Están optimizadas específicamente para aplicaciones que requieren grandes volúmenes de datos, baja latencia y modelos de datos flexibles, lo que se logra mediante la flexibilización de algunas de las restricciones de coherencia de datos en otras bases de datos.
¿Cómo almacenan los datos las bases de datos relacionales?
Las bases de datos relacionales almacenan los datos en tablas con columnas y filas. Cada columna representa un atributo de datos específico y cada fila representa una instancia de esos datos.
A cada tabla se le asigna una clave principal, una columna de identificador que identifica de forma exclusiva la tabla. La clave principal se utiliza para establecer relaciones entre las tablas. Se usa para relacionar filas entre tablas como la clave externa de otra tabla.
Una vez que se conectan dos tablas, se obtienen datos de ambas con una sola consulta. Las consultas SQL se escriben para interactuar con la base de datos relacional.
Ejemplo de datos almacenados
Por ejemplo, imagine que un minorista crea una tabla con todos sus productos. En esta tabla, podría tener columnas para los nombres, las descripciones y el precio de los productos. Otra tabla contiene datos sobre los clientes, sus nombres y lo que han comprado.
Las siguientes tablas muestran este enfoque.
|
ID_del_producto (clave principal) |
Nombre_del_producto |
Costo_del_producto |
|
P1 |
Producto_A |
100 USD |
|
P2 |
Producto_B |
50 USD |
|
P3 |
Producto_C |
80 USD |
|
ID_del_cliente |
Nombre_del_cliente |
artículo_comprado (clave externa) |
|
C1 |
Cliente_A |
P2 |
|
C2 |
Cliente_B |
P1 |
|
C3 |
Cliente_C |
P3 |
¿Cómo almacenan los datos las bases de datos no relacionales?
Existen varios sistemas de bases de datos no relacionales diferentes debido a las variaciones en la forma en que administran y almacenan los datos sin esquemas. Los datos sin esquema son datos que se almacenan sin las restricciones que requieren las bases de datos relacionales.
A continuación, explicamos algunos de los tipos comunes de bases de datos no relacionales.
Base de datos de clave-valor
Una base de datos de clave-valor almacena los datos como una colección de pares clave-valor. En un par, la clave sirve como identificador único. Tanto las claves como los valores pueden ser cualquier cosa, desde objetos simples hasta objetos compuestos complejos.
Más información sobre las bases de datos de clave-valor »
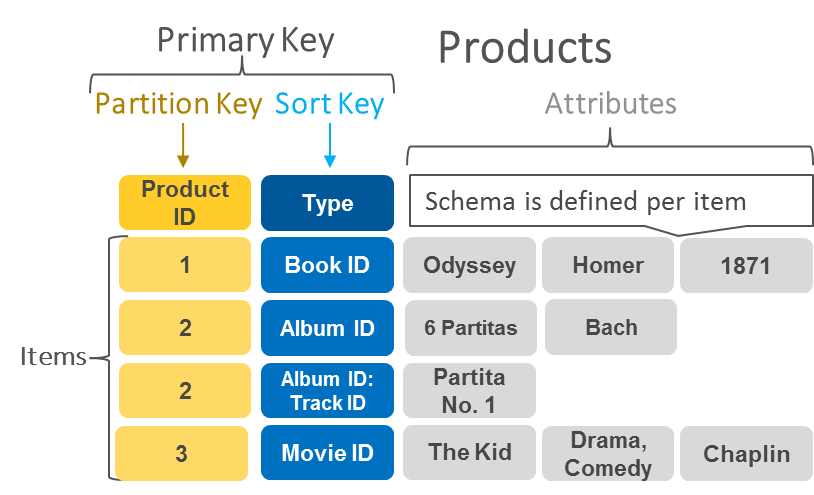
Bases de datos de documentos
Las bases de datos orientadas a documentos tienen el mismo formato de modelo de documento que los desarrolladores utilizan en el código de sus aplicaciones. Almacenan los datos como objetos JSON que son flexibles, semiestructurados y de naturaleza jerárquica.
El siguiente ejemplo muestra el aspecto que pueden tener los datos almacenados en una base de datos de documentos.
|
{ nombre_de_empresa: “CualquierEmpresa”, dirección: {calle: “Calle Principal 1212”, ciudad: “CualquierCiudad”}, número_de_teléfono: “1-800-555-0101”, sector: [“procesamiento de alimentos”, “electrodomésticos”] tipo: “privada”, número_de_empleados: 987 } |
Más información sobre las bases de datos de documentos »
Bases de datos de grafos
Las bases de datos de gráficos están diseñadas expresamente para almacenar relaciones y navegar por ellas. Usan nodos para almacenar entidades de datos y periferias para almacenar relaciones entre entidades.
Un borde siempre tiene un nodo inicial, un nodo final, un tipo y una dirección. Puede describir, por ejemplo, las relaciones entre elementos principales y secundarios, las acciones y la propiedad.
Más información sobre las bases de datos de grafos»

Diferencias clave: bases de datos relacionales en comparación con bases de datos no relacionales
Las bases de datos relacionales y no relacionales almacenan y administran los datos de forma muy diferente. En las siguientes secciones se describen las diferencias específicas.
Estructura
Las bases de datos relacionales almacenan datos en forma tabular y siguen reglas estrictas sobre las variaciones de datos y las relaciones entre tablas. Le permiten procesar consultas complejas sobre datos estructurados y, al mismo tiempo, mantener la integridad y la coherencia de los datos.
Las bases de datos no relacionales son más flexibles y útiles para datos con requisitos cambiantes. Puede utilizarlas para almacenar imágenes, videos, documentos y otro contenido semiestructurado y no estructurado.
Mecanismo de integridad de datos
ACID (atomicidad, consistencia, aislamiento y durabilidad) se refiere a la capacidad de la base de datos para mantener la integridad de los datos a pesar de los errores o las interrupciones en el procesamiento de los datos.
Un modelo de base de datos relacional sigue las propiedades estrictas de ACID. Esto significa que un conjunto de operaciones consiguientes siempre se completarán juntas. Si se produce un error en una sola operación, se produce un error en todo el conjunto de operaciones. Esto garantiza la precisión de los datos en todo momento.
Por el contrario, las bases de datos no relacionales ofrecen un modelo BASE (coherencia eventual flexible básicamente disponible) más flexible.
Las bases de datos no relacionales garantizan la disponibilidad, pero no la coherencia inmediata. El estado de la base de datos puede cambiar con el tiempo y, finalmente, se vuelve coherente. Algunas bases de datos no relacionales pueden cumplir con los requisitos de ACID en cuanto a rendimiento u otros aspectos.
Rendimiento
El rendimiento de las bases de datos relacionales depende de su subsistema de disco. Para mejorar el rendimiento de la base de datos, puede usar SSD y optimizar el disco configurándolo con una matriz redundante de discos independientes (RAID). Para obtener el máximo rendimiento, también debe optimizar los índices, las estructuras de tablas y las consultas.
Por el contrario, el rendimiento de las bases de datos NoSQL depende de la latencia de la red, el tamaño del clúster de hardware y la aplicación que realiza la llamada. Hay algunas maneras de mejorar el rendimiento de una base de datos no relacional:
- Aumentar el tamaño del clúster
- Minimizar la latencia de la red
- Índice y caché
Las bases de datos NoSQL ofrecen un mayor rendimiento y escalabilidad para casos de uso específicos en comparación con una base de datos relacional.
Escalado
El esquema rígido de un sistema de bases de datos relacionales puede presentar desafíos a gran escala. Por lo general, se escala de manera vertical al agregar más recursos de CPU o RAM al servidor. También puede escalar de manera horizontal si duplica los datos en todos los servidores para cargas de trabajo de solo lectura. Sin embargo, el escalado horizontal de las cargas de trabajo de lectura y escritura requiere estrategias especiales, como la fragmentación y la partición.
Más información sobre la partición de bases de datos »
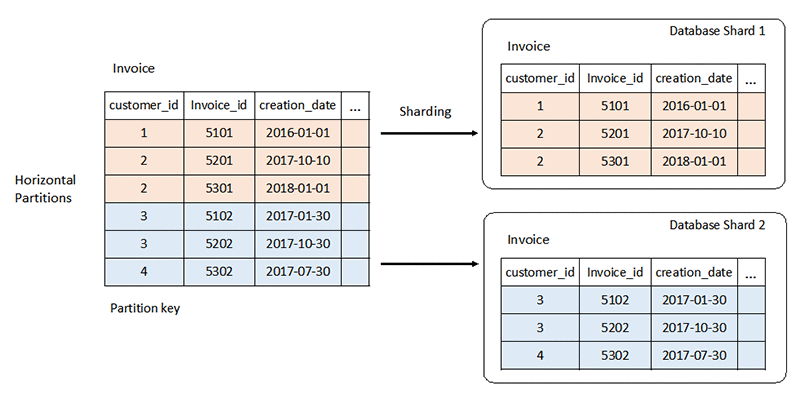
Por el contrario, las bases de datos NoSQL son altamente escalables. Puede distribuir su carga de trabajo entre muchos nodos con mayor facilidad. Estas bases de datos pueden procesar grandes volúmenes de datos mediante la partición en conjuntos más pequeños y la distribución de los conjuntos en varios nodos.

Cuándo utilizar bases de datos relacionales y cuándo bases de datos no relacionales
Las bases de datos relacionales son la mejor opción si los datos son predecibles en términos de tamaño, estructura y frecuencia de acceso. También puede preferir un sistema de administración de bases de datos relacionales si las relaciones entre las entidades son importantes. Por ejemplo, si tiene un conjunto de datos grande con una estructura y relaciones complejas, querrá que las relaciones destaquen por su análisis y facilidad de uso.
Por el contrario, un modelo no relacional funciona mejor para almacenar datos que sean flexibles en forma o tamaño, o que puedan cambiar en el futuro.
Además, en algunos casos, las relaciones de datos simplemente no encajan bien en el formato tabular de claves principales y externas. Por ejemplo, para modelar los amigos y las relaciones en una red social, necesitarías una tabla con cientos de filas en una base de datos relacional.
Por el contrario, esto se puede representar en una sola línea en una base de datos no relacional. El siguiente ejemplo muestra las entradas de datos de un miembro con cuatro amigos en una base de datos no relacional.
|
ID_de_miembro ID_de_amigo M1 M2 M1 M3 M1 M4 M1 M5 |
{nombre del miembro: “miembro 1” member friends: “miembro 2, miembro 3, miembro 4, miembro 5”} |
Resumen de diferencias: bases de datos relacionales en comparación con bases de datos no relacionales
|
Categoría |
Base de datos relacional |
Base de datos no relacional |
|
Modelo de datos |
Tabular. |
Clave-valor, documento o gráfico. |
|
Tipo de datos |
Estructurado. |
Estructurados, semiestructurados y sin estructurar. |
|
Integridad de los datos |
Alta, con total conformidad con ACID. |
Modelo de coherencia eventual. |
|
Rendimiento |
Se ha mejorado al agregar más recursos al servidor. |
Se ha mejorado al agregar más nodos de servidor. |
|
Escalado |
El escalado horizontal requiere estrategias de administración de datos adicionales. |
El escalado horizontal es sencillo. |
¿Cómo puede AWS cumplir con sus requisitos de bases de datos relacionales y no relacionales?
Amazon Web Services (AWS) ofrece muchos servicios que cumplen los requisitos de las bases de datos relacionales y no relacionales.
Servicios de AWS para bases de datos relacionales
Amazon Relational Database Service (Amazon RDS) es un conjunto de servicios administrados que facilita la configuración, el uso y el escalado de las bases de datos relacionales en la nube. Las bases de datos en la nube ofrecen muchos beneficios, como el rendimiento, la escalabilidad y la rentabilidad. Puede utilizar motores de bases de datos relacionales como los siguientes:
- Amazon RDS para SQL Server para implementar varias ediciones de SQL Server (2014, 2016, 2017 y 2019)
- Amazon RDS para MySQL admitirá las versiones 5.7 y 8.0 de MySQL Community Edition
- Amazon RDS para MariaDB admitirá las versiones 10.3, 10.4, 10.5 y 10.6 del servidor MariaDB
Además, Amazon RDS para Oracle tiene dos modelos de licencias diferentes, lo que significa que no necesita comprar licencias de Oracle por separado si no las tiene.
Servicios de AWS para bases de datos no relacionales
AWS también cuenta con varios servicios de bases de datos NoSQL para cumplir con todos sus requisitos de NoSQL. A continuación, se indican varios ejemplos:
- Amazon DynamoDB es un servicio de base de datos de valor clave que proporciona una latencia uniforme de milisegundos de un solo dígito para cargas de trabajo a cualquier escala.
- Amazon DocumentDB (compatible con MondoDB) es una popular base de datos orientada a documentos con API potentes e intuitivas para un desarrollo flexible e iterativo.
- Amazon MemoryDB es un servicio de base de datos en memoria duradero. Ofrece una latencia de lectura y escritura de microsegundos para un rendimiento ultrarrápido.
- Amazon Neptune es un servicio de base de datos de gráficos totalmente administrado para crear y ejecutar aplicaciones de gráficos de alto rendimiento.
- Amazon OpenSearch Service está diseñado específicamente para proporcionar visualizaciones y análisis casi en tiempo real de los datos generados por máquinas.
Cree una cuenta hoy mismo para comenzar con bases de datos relacionales y no relacionales en AWS.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages