Blog AWS Indonesia
Mengekstrak dan Menggabungkan Data dari Beberapa Sumber Data Dengan Athena Federated Query
Dengan arsitektur modern, adalah hal yang sangat umum untuk mempunyai data yang tersimpan di berbagai sumber data. Kita membutuhkan alat dan teknologi yang tepat di seluruh sumber data tersebut untuk menciptakan wawasan yang berarti dari data yang disimpan. Amazon Athena terutama digunakan sebagai layanan kueri interaktif yang mempermudah analisis data tidak terstruktur, semi-terstruktur, dan terstruktur yang disimpan di Amazon Simple Storage Service (Amazon S3) menggunakan SQL standar. Dengan fungsionalitas kueri federasi di Athena, Anda sekarang dapat menjalankan kueri SQL di seluruh data yang disimpan di sumber data relasional, non-relasional, objek, dan kustom serta menyimpan hasilnya kembali di Amazon S3 untuk analisis lebih lanjut.
Tujuan tulisan ini adalah untuk membahas bagaimana kita dapat mengonfigurasi konektor yang berbeda untuk menjalankan kueri federasi dengan gabungan kompleks di berbagai sumber data, cara mengonfigurasi fungsi yang ditentukan pengguna untuk menyunting informasi sensitif saat menjalankan kueri Athena, dan bagaimana kita dapat menggunakan inferensi pembelajaran mesin (ML) untuk mendeteksi deteksi anomali dalam kumpulan data untuk membantu developer, arsitek big data, teknisi data, dan analis bisnis dalam rutinitas operasional harian mereka.
Athena Federated Query
Athena menggunakan konektor sumber data yang berjalan di AWS Lambda untuk menjalankan kueri federasi. Konektor sumber data adalah bagian kode yang diterjemahkan antara sumber data target Anda dan Athena. Anda dapat menganggap konektor sebagai ekstensi dari mesin kueri Athena. Konektor sumber data Athena yang dibuat sebelumnya tersedia untuk sumber data seperti Amazon CloudWatch Logs, Amazon DynamoDB, Amazon DocumentDB, Amazon Elasticsearch Service (Amazon ES), Amazon ElastiCache for Redis, dan sumber data relasional yang sesuai dengan JDBC seperti MySQL, PostgreSQL, dan Amazon Redshift di bawah lisensi Apache 2.0. Anda juga dapat menggunakan Athena Query Federation SDK untuk menulis konektor khusus. Setelah Anda menerapkan konektor sumber data, konektor tersebut dikaitkan dengan nama katalog yang dapat Anda tentukan di kueri SQL Anda. Anda bisa menggabungkan pernyataan SQL dari beberapa katalog dan menjangkau beberapa sumber data dengan satu kueri.
Saat kueri dikirimkan ke sumber data, Athena memanggil konektor yang sesuai untuk mengidentifikasi bagian tabel yang perlu dibaca, mengelola paralelisme, dan menurunkan predikat filter. Berdasarkan pengguna yang mengirimkan kueri, konektor dapat memberikan atau membatasi akses ke elemen data tertentu. Konektor menggunakan Apache Arrow sebagai format untuk mengembalikan data yang diminta dalam kueri, yang memungkinkan konektor diimplementasikan dalam bahasa seperti C, C ++, Java, Python, dan Rust. Karena konektor berjalan di Lambda, Anda dapat menggunakannya untuk mengakses data dari sumber data apa pun di cloud atau di lokasi yang dapat diakses dari Lambda.
Tulisan ini membahas cara mengonfigurasi konektor Athena Federated Query dan menggunakannya untuk menjalankan kueri federasi untuk data yang berada di HBase di Amazon EMR, Amazon Aurora MySQL, DynamoDB, dan database ElastiCache for Redis.
Data Uji
Untuk mendemonstrasikan kemampuan federasi Athena, kita menggunakan kumpulan data sampel TPCH. TPCH adalah tolok ukur pendukung keputusan dan memiliki relevansi industri yang luas. Tolok ukur ini menggambarkan sistem pendukung keputusan yang memeriksa volume data yang besar, menjalankan kueri dengan tingkat kerumitan yang tinggi, dan memberikan jawaban atas pertanyaan bisnis penting. Untuk kasus penggunaan kami, bayangkan perusahaan e-commerce dengan arsitektur berikut:
- Data
Lineitemsdisimpan di HBase di Amazon EMR untuk memenuhi persyaratan penyimpanan data yang dioptimalkan untuk penulisan dengan tingkat transaksi tinggi dan daya tahan jangka panjang, - ElastiCache for Redis menyimpan tabel
NationsdanActiveOrderssehingga mesin pemroses dapat mengaksesnya dengan cepat. - Aurora dengan mesin MySQL digunakan untuk data akun
Orders,Customer, danSuppliersseperti alamat email dan alamat pengiriman. - DynamoDB menyimpan data
PartdanPartsupp, karena DynamoDB menawarkan fleksibilitas tinggi dan kinerja tinggi.
Diagram berikut menunjukkan tampilan skema dari tabel TPCH dan penyimpanan data terkait.

Membangun lingkungan pengujian menggunakan AWS CloudFormation
Sebelum mengikuti tulisan ini, Anda perlu membuat sumber daya AWS yang diperlukan di akun Anda. Untuk melakukan ini, kami telah memberi Anda templat AWS CloudFormation untuk membuat stack yang berisi sumber daya yang diperlukan: sampel database TPCH di Amazon Relational Database Service (Amazon RDS), HBase di Amazon EMR, Amazon ElastiCache for Redis, dan DynamoDB.
Templat ini juga membuat database dan tabel AWS Glue, bucket S3, VPC endpoint Amazon S3, VPC endpoint AWS Glue, named-query Athena, AWS Cloud9 IDE, instans notebook Amazon SageMaker, dan sumber daya AWS Identity and Access Management (IAM) lainnya yang kami gunakan untuk mengimplementasikan kueri federasi, fungsi yang ditentukan pengguna (UDF), dan fungsi inferensi ML.
Templat ini dirancang hanya untuk memperlihatkan bagaimana Anda bisa menggunakan Athena Federated Query, UDFs, dan inferensi ML. Penyiapan ini tidak dimaksudkan untuk penggunaan produksi tanpa modifikasi. Selain itu, template dibuat untuk digunakan di Region us-east-1, dan tidak berfungsi di Region lain.
Sebelum meluncurkan stack, Anda harus memiliki prasyarat berikut:
- Akun AWS yang menyediakan akses ke layanan AWS
- Pengguna IAM dengan kunci akses dan kunci rahasia untuk mengonfigurasi AWS Command Line Interface (AWS CLI), dan izin untuk membuat peran IAM, kebijakan IAM, dan tumpukan di AWS CloudFormation.
Untuk membuat sumber daya Anda, selesaikan langkah-langkah berikut:
- Pilih Launch Stack:

- Pilih I acknowledge that this template may create IAM resources.
Template ini menciptakan sumber daya yang menimbulkan biaya saat mereka tetap digunakan. Ikuti langkah-langkah pembersihan di akhir posting ini untuk menghapus dan membersihkan sumber daya untuk menghindari biaya yang tidak perlu. - Saat templat CloudFormation selesai, catat keluaran yang terdaftar di tab Outputs di konsol AWS CloudFormation.

- Pembuatan stack CloudFormation membutuhkan waktu sekitar 20–30 menit untuk menyelesaikannya. Periksa konsol AWS CloudFormation dan tunggu status
CREATE_COMPLETE.
Saat pembuatan tumpukan selesai, akun AWS Anda memiliki semua sumber daya yang diperlukan untuk menerapkan solusi ini. - Pada tab Output dari stack Athena-Federation-Workshop, catat hal berikut:
S3Bucket
Subnets
WorkshopSecurityGroup
EMRSecurityGroup
HbaseConnectionString
RDSConnectionString
Anda memerlukan semua informasi ini saat menyiapkan konektor. - Saat pembuatan stack selesai, periksa status langkah Amazon EMR di konsol Amazon EMR.
Diperlukan waktu hingga 15 menit untuk menyelesaikan langkah ini.
Menerapkan konektor dan menghubungkan ke sumber data
Mempersiapkan untuk membuat kueri federasi adalah proses dengan dua bagian: menerapkan fungsi Lambda untuk konektor sumber data dan kemudian menghubungkan fungsi Lambda ke sumber data. Di bagian pertama, Anda memberi nama fungsi Lambda yang nantinya dapat Anda pilih di konsol Athena. Di bagian kedua, Anda memberi nama konektor yang bisa Anda referensikan dalam kueri SQL Anda.
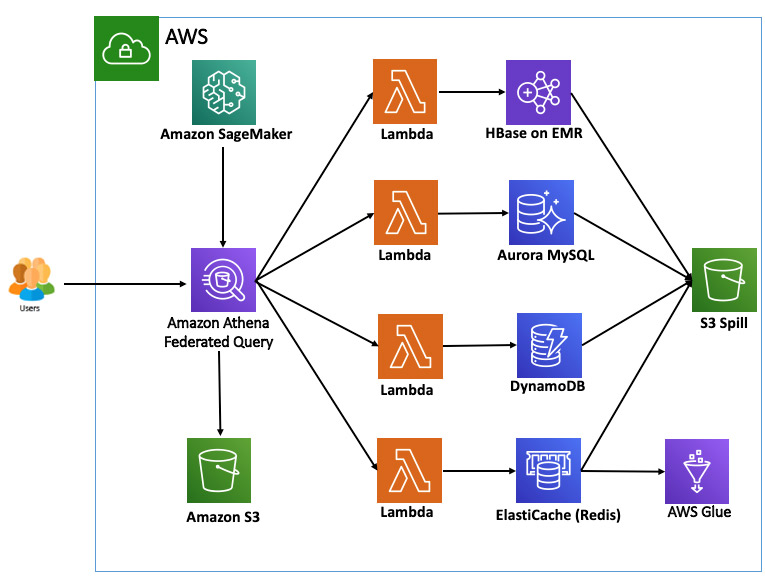
Kami ingin melakukan kueri sumber data yang berbeda, jadi di bagian berikut kami menyiapkan konektor Lambda untuk HBase di Amazon EMR, Aurora MySQL, DynamoDB, dan Redis sebelum kami mulai membuat join kompleks di seluruh sumber data menggunakan kueri federasi Athena. Diagram berikut menunjukkan arsitektur lingkungan kita.
Menginstal Athena JDBC Connector untuk Aurora MySQL
Konektor Athena JDBC mendukung basisdata berikut:
- MySQL
- PostGreSQL
- Amazon Redshift
Untuk menginstal konektor Athena JDBC untuk Aurora MySQL, selesaikan langkah-langkah berikut:
- Di akun AWS anda, cari
serverless application repository. - Pilih Available applications.
- Pastikan Show apps that create custom IAM roles or resource policies dipilih.
- Cari
athena federation. - Cari dan pilih AthenaJdbcConnector.
- Berikan nilai-nilai berikut:
- Application name – Biarkan nama
AthenaJdbcConnector. - SecretNamePrefix – Masukkan
AthenaJdbcFederation. - SpillBucket – Masukkan nilai
S3Bucketdari keluaran AWS CloudFormation. - DefaultConnectionString – Masukkan nilai
RDSConnectionStringdari keluaran AWS CloudFormation. - DisableSpillEncryption – Biarkan nilai
false. - LambdaFunctionName – Masukkan
mysql. - LambdaMemory – Biarkan nilai
3008. - LambdaTimeout – Biarkan nilai
900. - SecurityGroupIds – Masukkan nilai
WorkshopSecurityGroupdari keluaran AWS CloudFormation. - SpillPrefix – Ubah nilai menjadi
athena-spill/jdbc. - SubnetIds – Masukkan nilai
Subnetsdari keluaran AWS CloudFormation.
- Application name – Biarkan nama
- Pilih I acknowledge that this app creates custom IAM roles.
- Pilih Deploy.
Ini menerapkan konektor Athena JDBC untuk Aurora MySQL; Anda dapat merujuk ke fungsi Lambda ini dalam kueri Anda sebagai lambda:mysql.
Untuk informasi selengkapnya tentang konektor Athena JDBC, lihat repo GitHub.
Memasang konektor Athena DynamoDB
Untuk menginstal Konektor Athena DynamoDB, selesaikan langkah-langkah berikut:
- Di akun AWS anda, cari
serverless application repository. - Pilih Available applications.
- Pastikan Show apps that create custom IAM roles or resource policies dipilih.
- Cari athena federation.
- Cari dan pilih AthenaJdbcConnector.
- Berikan nilai-nilai berikut:
- Application name – Biarkan nama
AthenaDynamoDBConnector. - SpillBucket – Masukkan nilai
S3Bucketdari keluaran AWS CloudFormation. - AthenaCatalogName – Masukkan
dynamo. - DisableSpillEncryption – Biarkan nilai false.
- LambdaMemory – Biarkan nilai 3008.
- LambdaTimeout – Biarkan nilai 900.
- SpillPrefix – Ubah nilai menjadi
athena-spill-dynamo.
- Application name – Biarkan nama
- Pilih I acknowledge that this app creates custom IAM roles.
- Pilih Deploy.
Ini menerapkan konektor Amazon DynamoDB; Anda dapat merujuk ke fungsi Lambda ini dalam kueri Anda sebagai lambda:dynamo.
Untuk informasi selengkapnya tentang konektor Amazon DynamoDB, lihat repo GitHub.
Memasang konektor Athena HBase
Untuk menginstal konektor Athena HBase, selesaikan langkah-langkah berikut:
- Di akun AWS anda, cari
serverless application repository. - Pilih Available applications.
- Pastikan Show apps that create custom IAM roles or resource policies dipilih.
- Cari
athena federation. - Cari dan pilih AthenaHBaseConnector.
- Berikan nilai-nilai berikut:
- Application name – Biarkan nama
AthenaHBaseConnector. - SecretNamePrefix – Masukkan
hbase-*. - SpillBucket – Masukkan nilai
S3Bucketdari keluaran AWS CloudFormation. - AthenaCatalogName – Masukkan
hbase. - DefaultConnectionString – Masukkan nilai
HbaseConnectionStringdari keluaran AWS CloudFormation. - DisableSpillEncryption – Biarkan nilai false.
- LambdaMemory – Biarkan nilai
3008. - LambdaTimeout – Biarkan nilai
900. - SecurityGroupIds – Masukkan nilai
EMRSecurityGroupdari keluaran AWS CloudFormation. - SpillPrefix – Ubah nilai menjadi
athena-spill-hbase. - SubnetIds – Masukkan nilai Subnets dari keluaran AWS CloudFormation.
- Application name – Biarkan nama
- Pilih I acknowledge that this app creates custom IAM roles.
- Pilih Deploy.
Ini menerapkan konektor Athena HBase; Anda dapat merujuk ke fungsi Lambda ini dalam kueri Anda sebagai lambda:hbase.
Untuk informasi selengkapnya tentang konektor Athena HBase, lihat repo GitHub.
Memasang konektor Athena Redis
Untuk menginstal Athena Redis Connector, selesaikan langkah-langkah berikut:
- Di akun AWS anda, cari
serverless application repository. - Pilih Available applications.
- Pastikan Show apps that create custom IAM roles or resource policies dipilih.
- Cari
athena federation. - Cari dan pilih AthenaRedisConnector.
- Berikan nilai-nilai berikut:
- Application name – Biarkan nama
AthenaRedisConnector. - SecretNamePrefix – Masukkan
redis-*. - SpillBucket – Masukkan nilai
S3Bucketdari keluaran AWS CloudFormation. - AthenaCatalogName – Masukkan
redis. - DisableSpillEncryption – Biarkan nilai
false. - LambdaMemory – Biarkan nilai
3008. - LambdaTimeout – Biarkan nilai
900. - SecurityGroupIds – Masukkan nilai
EMRSecurityGroupdari keluaran AWS CloudFormation. - SpillPrefix – Ubah nilai menjadi
athena-spill-redis. - SubnetIds – Masukkan nilai
Subnetsdari keluaran AWS CloudFormation.
- Application name – Biarkan nama
- Pilih I acknowledge that this app creates custom IAM roles.
- Pilih Deploy.
Ini menerapkan konektor Athena Redis; Anda dapat merujuk ke fungsi Lambda ini dalam kueri Anda sebagai lambda:redis.
Untuk informasi selengkapnya tentang konektor Athena Redis, lihat repo GitHub.
Menjalankan kueri federasi
Sekarang setelah konektor diterapkan, kita bisa menjalankan kueri Athena yang menggunakan konektor tersebut.
- Di konsol Athena, pilih Get Started.
- Pastikan Anda berada di grup kerja
AmazonAthenaPreviewFunctionality. Jika tidak, pilih Workgroups, pilih AmazonAthenaPreviewFunctionality, dan pilih Switch Workgroup.
Pada tab Saved Query, Anda dapat melihat daftar kueri yang telah diisi sebelumnya untuk diuji.

Kueri yang disimpanSourcemenguji fungsionalitas konektor Athena Anda untuk setiap sumber data, dan Anda dapat memastikan bahwa Anda dapat mengekstrak data dari setiap sumber data sebelum menjalankan kueri yang lebih kompleks yang melibatkan sumber data yang berbeda. - Sorot kueri pertama hingga titik koma dan pilih Run Query.
Setelah berhasil menguji koneksi ke setiap sumber data, Anda dapat melanjutkan dengan menjalankan kueri yang lebih kompleks, seperti:
FetchActiveOrderInfoProfitBySupplierNationByYrOrdersRevenueDateAndShipPrioShippedLineitemsPricingReportSuppliersWhoKeptOrdersWaiting
Jika Anda melihat kesalahan pada kueri HBase seperti berikut, coba jalankan kembali dan itu akan menyelesaikan masalah.
GENERIC_USER_ERROR: Encountered an exception[java.lang.RuntimeException] from your LambdaFunction[hbase] executed in context[retrieving meta-data] with message[org.apache.hadoop.hbase.client.RetriesExhaustedException: Can't get the location for replica 0]Sebagai contoh dari kueri tingkat lanjut, kueri SuppliersWhoKeptOrdersWaiting mengidentifikasi pemasok yang produknya merupakan bagian dari pesanan multi-pemasok (dengan status F saat ini) dan mereka tidak mengirimkan suku cadang yang diperlukan tepat waktu. Kueri ini menggunakan beberapa sumber data: Aurora MySQL dan HBase di Amazon EMR. Seperti yang ditunjukkan pada tangkapan layar berikut, kueri mengekstrak data dari tabel suppliers di Aurora MySQL, tabel lineitem di HBase, dan tabel orders di Aurora MySQL. Hasilnya dikembalikan dalam 7,13 detik.

Pembersihan
Untuk membersihkan sumber daya yang dibuat sebagai bagian dari templat CloudFormation kita, selesaikan langkah-langkah berikut:
- Di konsol Amazon S3, kosongkan bucket
athena-federation-workshop-<account-id>. - Jika Anda menggunakan AWS CLI, hapus objek di bucket
athena-federation-workshop- <account-id>dengan kode berikut (pastikan Anda menjalankan perintah ini pada bucket yang benar):aws s3 rm s3://athena-federation-workshop-<account-id> --recursive - Di konsol AWS CloudFormation, hapus semua konektor sehingga tidak lagi terpasang ke antarmuka jaringan elastis (ENI) VPC. Atau, buka setiap konektor dan batalkan pilihan VPC sehingga tidak lagi terpasang ke VPC yang dibuat oleh AWS CloudFormation.

- Di konsol Amazon SageMaker, hapus semua endpoint yang Anda buat sebagai bagian dari inferensi ML.
- Di konsol Athena, hapus grup kerja
AmazonAthenaPreviewFunctionality. - Di konsol AWS CloudFormation atau AWS CLI, hapus stack
Athena-Federation-Workshop.
Ringkasan
Dalam tulisan ini, kami mendemonstrasikan fungsionalitas Athena Federated Query dengan membuat beberapa konektor berbeda dan menjalankan kueri gabungan pada beberapa sumber data.
Tulisan ini disadur dari artikel Extracting and joining data from multiple data sources with Athena Federated Query yang ditulis oleh Saurabh Bhyutani (Senior Big Data Specialist Solutions Architect di Amazon Web Services) dan Amir Basirat (Big Data Specialist Solutions Architect at Amazon Web Services)