Amazon Web Services ブログ
Category: Analytics

Fivetran の Managed Data Lake Service の CDC で実現する業務システムから Apache Iceberg へのリアルタイムデータ連携
本記事は アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクト 疋田、畠 と、Fivetr […]
Vanguard が Amazon Redshift マルチウェアハウスアーキテクチャで分析基盤を刷新
Vanguard の Financial Advisor Services 部門が、Amazon Redshift のマルチウェアハウスアーキテクチャを活用して分析基盤を変革した事例を紹介します。単一クラスターから、プロビジョンドクラスターと Serverless を組み合わせたワークロード分離アーキテクチャへの移行により、ETL の SLA 遵守率 100%、月間 50 万以上のクエリ対応、BI ダッシュボード 25 倍増を実現しました。さらに、データメッシュアーキテクチャへの進化についても解説します。

Amazon Redshift と AWS IAM Identity Center できめ細かなアクセス許可を複数のウェアハウスに展開する
本記事では、Amazon Redshift フェデレーテッドアクセス許可と AWS IAM Identity Center を使用して、複数のデータウェアハウスのきめ細かなアクセス許可をスケーラブルに管理する方法を紹介します。Enterprise Data Warehouse (EDW) でセキュリティポリシーを一度定義すれば、Sales や Marketing のコンシューマーウェアハウスに自動適用されるアーキテクチャを解説します。

Amazon OpenSearch Serverless の集中型・分散型ネットワーク接続パターンの設計 – パート 2
本記事は、Amazon OpenSearch Serverless のハイブリッドマルチアカウントアクセスパターンに関するシリーズのパート 2 です。複数の事業部門が独立して OpenSearch Serverless コレクションを管理するシナリオに対応する分散型アーキテクチャを紹介します。中央ネットワーキングアカウントのカスタムプライベートホストゾーンと Route 53 Profile を活用し、オンプレミスおよびスポークアカウントからのプライベートアクセスを実現します。

Amazon OpenSearch Serverless の集中型・分散型ネットワーク接続パターンの設計 – パート 1
本記事では、Amazon OpenSearch Serverless の集中型・分散型ネットワーク接続パターンを紹介します。集中型インターフェイス VPC エンドポイントと Route 53 Profiles を使用して、オンプレミス環境や複数の AWS アカウントから OpenSearch Serverless コレクションにセキュアにプライベートアクセスする方法を解説します。

Amazon MSK Express ブローカーで Kafka 運用をシンプルにする
本記事では、Amazon MSK Express ブローカーが Kafka クラスターの運用をどのようにシンプルにするかを紹介します。サイジング、ストレージ管理、コンピューティングのスケーリング、モニタリング、アクセス制御、高可用性について、Express ブローカーがもたらす改善を解説します。
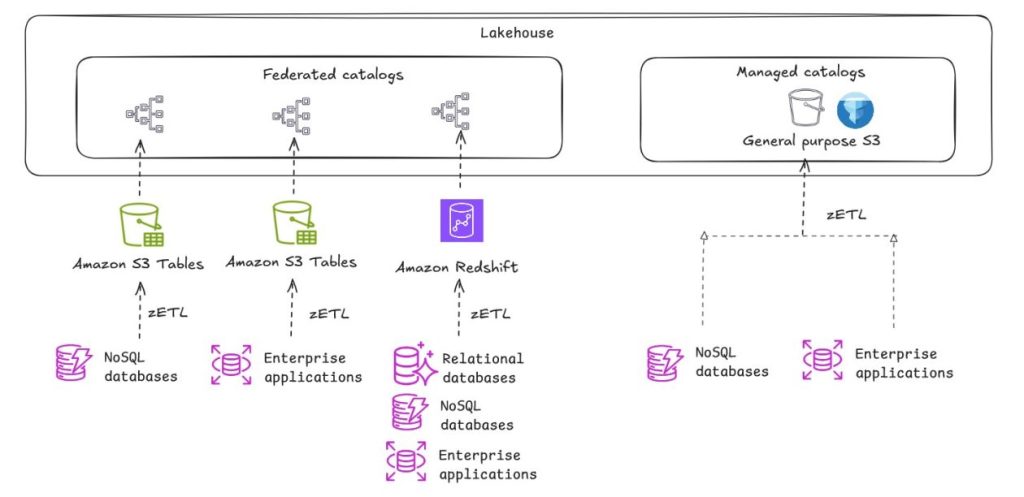
Amazon SageMaker を使用したレイクハウスのアーキテクチャ選択ガイド
Amazon SageMaker のレイクハウスアーキテクチャにおけるストレージパターンの選択ガイドです。データレイク (汎用 S3、S3 Tables) とデータウェアハウス (Redshift Managed Storage) の特性を比較し、ETL、Zero-ETL、データフェデレーションなどのデータ取り込みパターンとともに、ユースケースに応じた最適なアーキテクチャの選択方法を解説します。
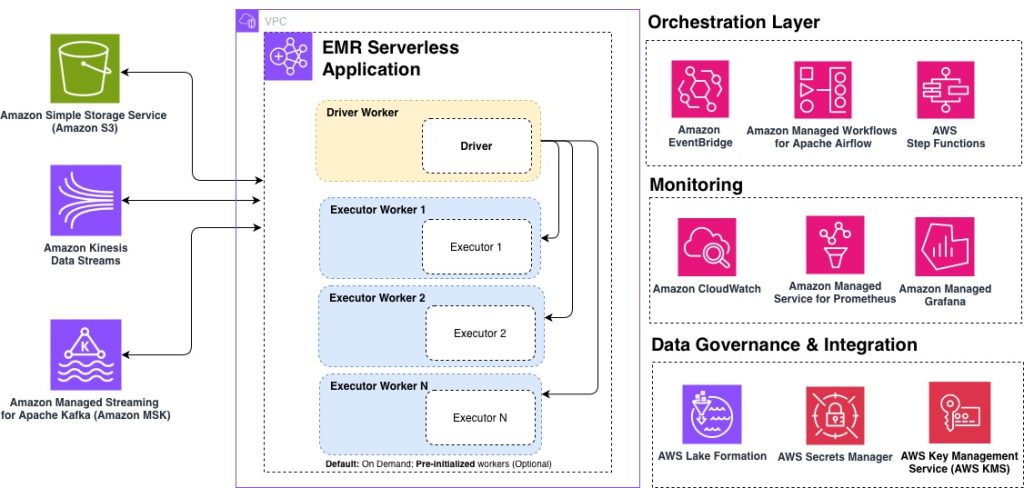
Amazon EMR Serverless のベストプラクティス 10 選
Amazon EMR Serverless のパフォーマンス、コスト、スケーラビリティを最適化するためのベストプラクティス 10 選を紹介します。アプリケーション設計、ワーカーの適正化、Graviton プロセッサの活用、ストレージ選択、マルチ AZ 構成など、効率的なデータ処理パイプラインの構築に役立つ実践的な推奨事項をまとめています。

AWS Weekly Roundup: 20 周年を迎えた Amazon S3、Amazon Route 53 Global Resolver の一般提供など (2026 年 3 月 16 日)
Amazon S3 の一般提供が開始されたのは、20 年前の先週にあたる 2006 年 3 月 14 日でした […]

Amazon Redshift Templates で運用を標準化する
本記事では、Amazon Redshift の新機能 Redshift Templates を紹介します。COPY コマンドのパラメータを再利用可能なデータベースオブジェクトとして保存し、データロード操作の標準化、一貫性の向上、保守の簡素化を実現する方法を、業界別のユースケースとともに解説します。