Amazon Web Services ブログ
AWSサーバーレスバッチ処理アーキテクチャの構築
この記事では、ファイル取り込み処理を実装するためのバッチ処理を、サーバーレスに実現するための方法を説明していきます。今回の例では、オーケストレーションにAWS Step Functions、オンデマンドのコンピューティングにAWS Lambda、データストアにAmazon S3、メールの送信にAmazon SESを使っていきます。
概要
この記事では、ビジネスニーズの高い一般的なユースケースである、「ファイルでデータがアップロードされてきた際の処理」を例として使用します。使用するテストファイルは、item ID, order date, order locationといった様々なデータフィールドを含んでいます。このデータはまず検証され、加工されたあと、単価などの追加情報が付与されます。そして最後にサードパーティのシステムへ送付する必要があります。
Step Functionsは、フルマネージドなワークフロー上で複数のAWSサービス同士を連携させる機能があり、その機能によってアプリケーションのビルドやアップデートを高速化することができます。また、ネスト機能を使って小さなワークフローからより大きなワークフローを構築することもできます。本記事のアーキテクチャーでは、小さく部品化したChunk Processorワークフローを作り、小さな単位でファイルを処理するようにしています。
ファイルのサイズが増えるとステートの間でやり取りされるペイロードのサイズも増えていきます。大きなペイロードをステート間でやりとりするような実行は、ペイロードの最大サイズである262,144バイトを超えると止まってしまう可能性があります。
今回は、大きなファイルを処理したり、ワークフローを部品化したりするために、処理を2つのワークフローに分割しました。一つ目のワークフローは大きなファイルをチャンク(ある程度の大きさにまとまったデータの一塊)に分割する責務を持つもので、二つ目のネストされたワークフローは個々のチャンクされたファイルに対してレコードごとの処理を行うものです。このように高粒度なワークフローステップと低粒度なワークフローステップを分割することによって、モニタリングやデバッグを行いやすくすることもできます。
ファイルを複数のチャンクに分割することはチャンクごとの並列処理を可能にするため、パフォーマンスの向上も見込むことができます。 Map stateを設定してチャンクごとの動的並列処理を有効にすると、さらにパフォーマンスを向上させることができます。
全体の動作
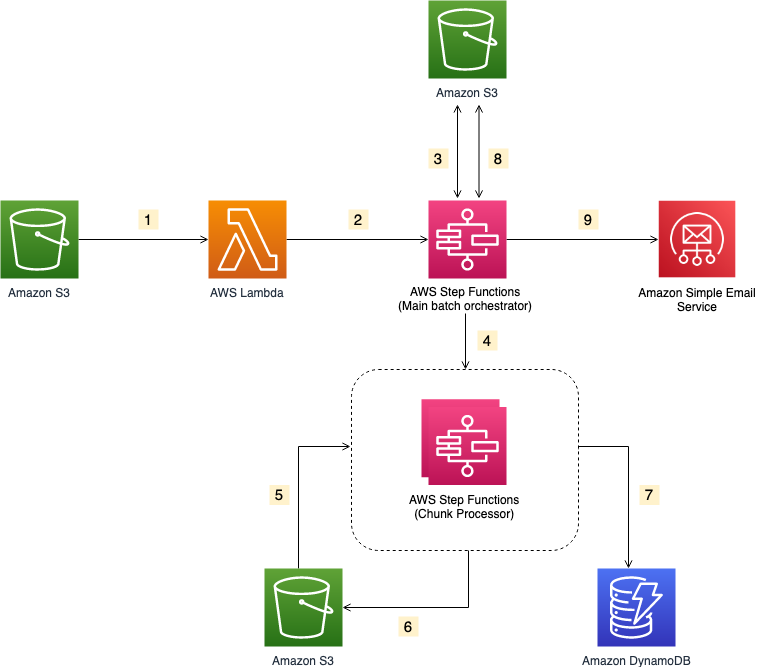
- S3バケットへのファイルアップロードがS3イベント通知をトリガーします。トリガーは、オブジェクトの詳細を含んだイベントをインプットとしてLambda関数の実行を非同期に 行います。
- Lambda関数はMain batch orchestratorワークフローを呼び、ファイル処理を開始します。
- Main batch orchestratorワークフローは入力ファイルを読み込み、ファイルを複数のチャンクに分割し、それぞれのチャンクしたファイルをS3バケットに格納します。
- Main batch orchestratorワークフローは、分割した各チャンクファイルに対してChunk Processorワークフローを呼び出します。
- 各Chunk Processorワークフローの実行は分割されたチャンクファイルの一つを読み込み処理を行います。
- Chunk Processorワークフローは処理済みのチャンクファイルをS3バケットに書き戻します。
- Chunk Processorワークフローは検証エラーの詳細を全てAmazon DynamoDBテーブルに記録します。
- Main batch orchestratorワークフローは処理済みのチャンクファイルをマージしてS3バケットへ保存します。
- Main batch orchestratorワークフローはAmazon Simple Email Serviceを使って結合されたファイルをあらかじめ定めていた受信者に対してEメール送信します。
各ワークフローの動作
-
- Main batch orchestratorワークフローはファイル処理のオーケストレーションを担います。
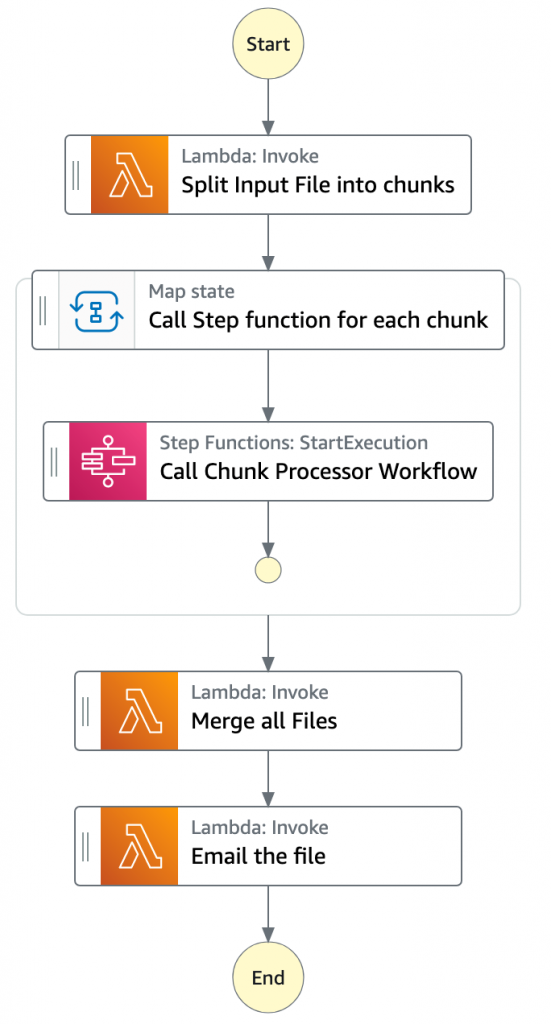
- 最初のTask stateであるSplit Input File into chunksはLambda関数を呼び出します。この関数では、入力ファイルをレコード数を元に複数のチャンクに分割し、各チャンクをS3バケットに格納します。
- 次のstateは、Call Step Functions for each chunkと名付けられた Map stateです。Step Functionsのサービス統合機能を使ってファイルの各チャンクに対してChunk Processorワークフローをトリガーします。この時、Chunk Processorワークフローに対してパラメーターとして分割されたファイルチャンクのS3バケットへのパスが渡されます。
- Main batch orchestratorは全ての子ワークフローが完了するのを待ちます。
- 全ての子ワークフローが成功で処理が完了したら次のTask stateはMerge all Filesです。ここでは、全ての処理済みのチャンクを一つのファイルに結合し、S3バケットに書き戻します。
- 次のTask stateであるEmail the fileは前のステップで出力されたファイル使います。このtaskでは出力ファイル用のS3 presigned URLを生成し、Eメールで送信します。
- Main batch orchestratorワークフローはファイル処理のオーケストレーションを担います。

- Chunk Processorワークフローは渡されたチャンクファイルに対して行ごとの処理を行う責務を持ちます。
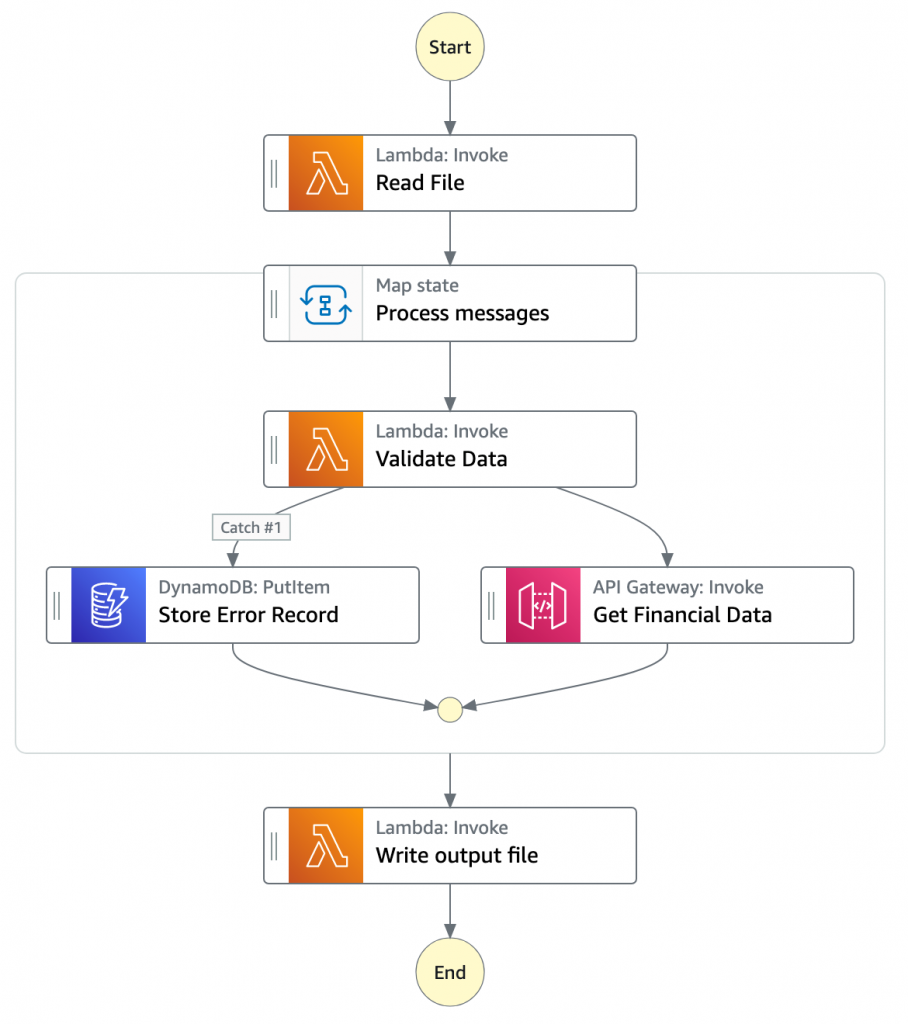
- 最初のTask stateであるRead FileはチャンクされたファイルをS3から読み込んでJSONオブジェクトの配列に変換を行います。1つのJSONオブジェクトがチャンクファイルの1行に相当します。
- 次のstateはProcess messagesと名付けられたMap stateです。ここでは一連のステップを入力配列の各要素に対して行います。
- Map stateの内部では、Validate Dataが最初のstateとなります。Lambda関数を呼び出して、自身で定義したルールによって各JSONオブジェクトを検査します。検査に失敗したレコードは、Amazon DynamoDBテーブルに格納されます。
- 次のstateはGet Financial Dataで、Amazon API Gatewayエンドポイントを呼び出し、DynamoDBテーブルから取得したデータを現在のデータに付加します。
- Map stateのイテレーションが完了したら、Write output fileがタスクをトリガーします。Lambda関数が呼び出され、関数内でJSONデータをCSVに変換し戻してからS3に出力されたオブジェクトを書き込みます。

前提条件
- AWS アカウント
- AWS SAM CLI
- Python 3
- 適切なアクセス権限を持ったAWS Identity and Access Management (IAM)ロール
アプリケーションのデプロイ
-
- こちらの リポジトリをクローンします。
- ディレクトリを変更し、アプリケーションコードをビルドします:
sam build
-
- アプリケーションをパッケージ化しAWSへデプロイします。入力を求められたら下記のように対応するパラメータを入力します:
sam deploy --guided
 テンプレートパラメータは以下の通りです:
テンプレートパラメータは以下の通りです:
- SESSender: 出力ファイルのEメール送信元アドレス
- SESRecipient: 出力ファイルのEメール受信先アドレス
- SESIdentityName: SESユーザがEメールを送信する際に使用するEメールアドレスもしくはドメイン
- InputArchiveFolder: 入力ファイルが処理後にアーカイブされるAmazon S3フォルダ
- FileChunkSize: 入力ファイルから分割される各チャンクのサイズ
- FileDelimiter: CSVファイルのデリミター(例:コンマ)
- アプリケーションをパッケージ化しAWSへデプロイします。入力を求められたら下記のように対応するパラメータを入力します:
-
- スタックの作成が完了したら、Outputs上にインプットファイル用のバケット(Source Bucket)が確認できます。
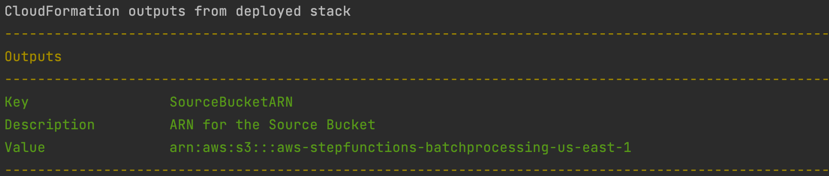
- スタックの作成が完了したら、Outputs上にインプットファイル用のバケット(Source Bucket)が確認できます。
- AWS CloudFormation Console上でデプロイされたコンポーネントを確認します。
ソリューションのテスト
-
- Amazon SESを使ったEメールの送信を試す前に“From”、“Source”、“Sender”、“Return-Path”で利用するアドレスが自分の所有するものであることを必ず確認してください。 詳しい情報については、Verifying identities in Amazon SESを参照してください。
- 作成したCloudFormationスタックのリソースセクションからS3バケット(SourceBucket)の情報を確認します。物理IDを選択するようにしてください。

-
- SourceBucketのS3コンソール上でフォルダの作成を選択します。フォルダ名をinputとし、フォルダの作成を選択します。
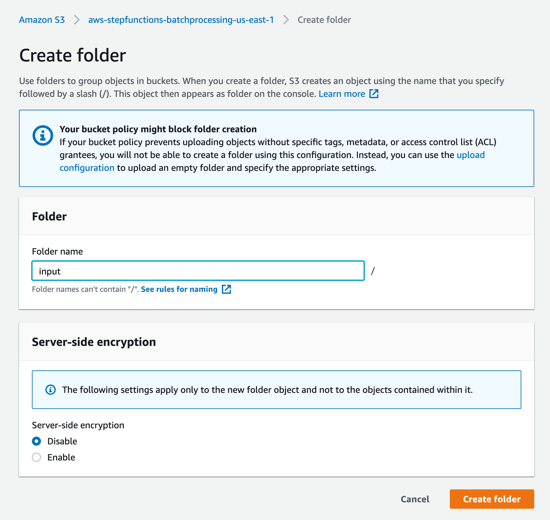
- SourceBucketのS3コンソール上でフォルダの作成を選択します。フォルダ名をinputとし、フォルダの作成を選択します。
-
- SourceBaucketに設定されているS3イベント通知はオブジェクトのプレフィックスにinputを、サフィックスにcsvを指定しています。このイベントはnotification Lambda functionをトリガーします。これはAWS SAM templateのカスタムリソースの部分で作られたものです。

- SourceBaucketに設定されているS3イベント通知はオブジェクトのプレフィックスにinputを、サフィックスにcsvを指定しています。このイベントはnotification Lambda functionをトリガーします。これはAWS SAM templateのカスタムリソースの部分で作られたものです。
-
- SourceBucketのS3コンソール上でinput/を選択してinputフォルダへ移動し、その後アップロードを選択します。ファイルを追加を選択し、入力ファイル(testfile.csvをローカルにダウンロードしておいてください)を指定し、アップロードを選択します。
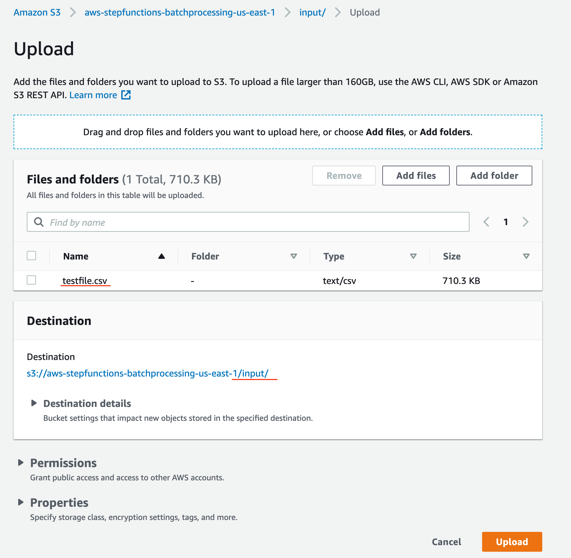
- SourceBucketのS3コンソール上でinput/を選択してinputフォルダへ移動し、その後アップロードを選択します。ファイルを追加を選択し、入力ファイル(testfile.csvをローカルにダウンロードしておいてください)を指定し、アップロードを選択します。
-
- 入力ファイルであるtestfile.csvのデータを確認します。
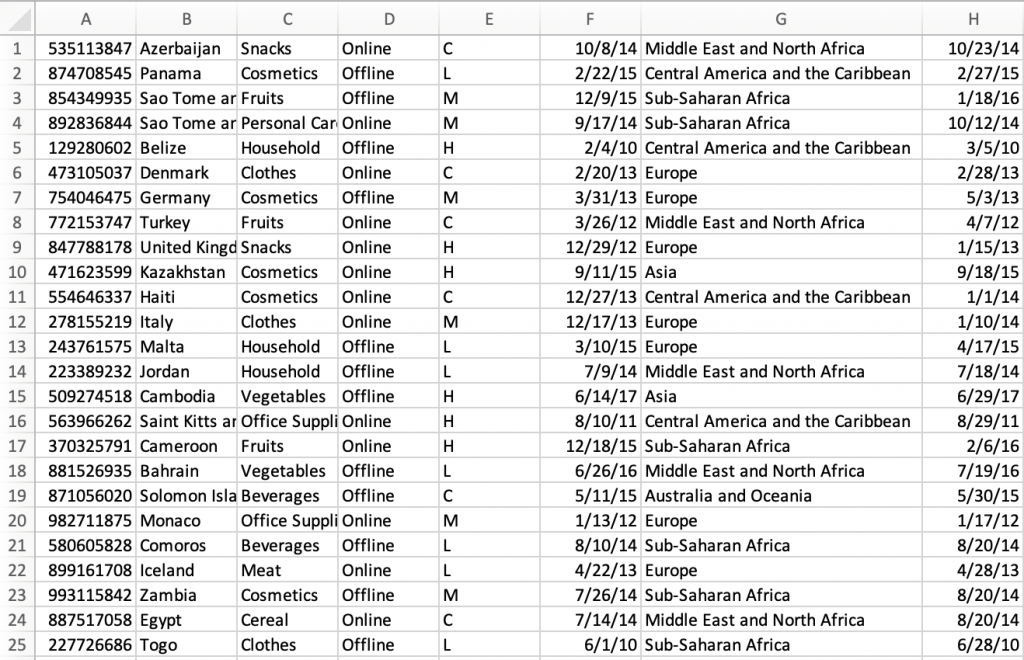
- 入力ファイルであるtestfile.csvのデータを確認します。

-
- オブジェクトがアップロードされたら、イベント通知がLambda関数を実行します。この関数がMain orchestratorワークフローを実行します。Step Functionsコンソール上でワークフローがrunning 状態になっていることを確認できます。

- オブジェクトがアップロードされたら、イベント通知がLambda関数を実行します。この関数がMain orchestratorワークフローを実行します。Step Functionsコンソール上でワークフローがrunning 状態になっていることを確認できます。
-
- 個々のステートマシンを選択し、追加の情報を確認します。
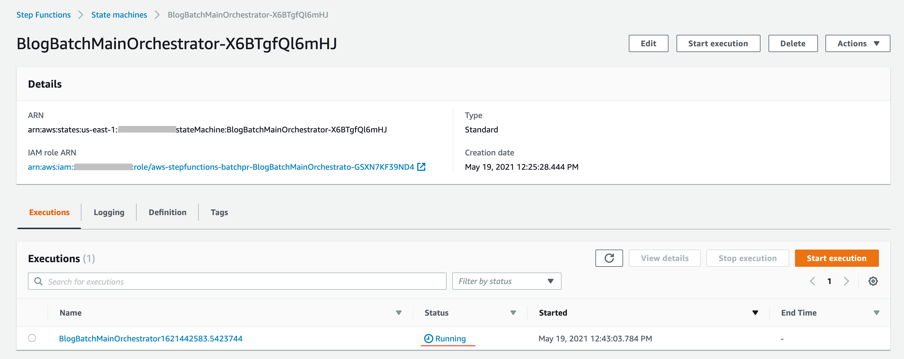
- 個々のステートマシンを選択し、追加の情報を確認します。
-
- 数分後、BlogBatchMainOrchestratorとBlogBatchProcessChunkの両ワークフローの全ての実行が完了します。BlogBatchMainOrchestratorは一回の実行、BlogBatchProcessChunkは複数の実行が行われています。これは、BlogBatchMainOrchestratorがチャンクされたファイルの回数分BlogBatchProcessChunkを呼び出しているためです。
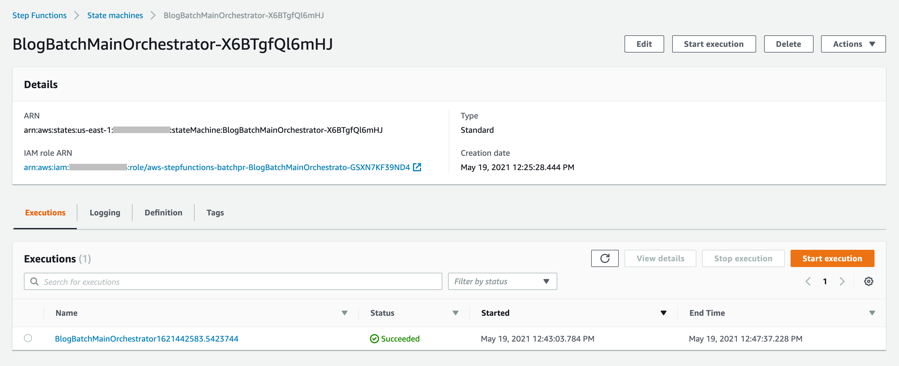
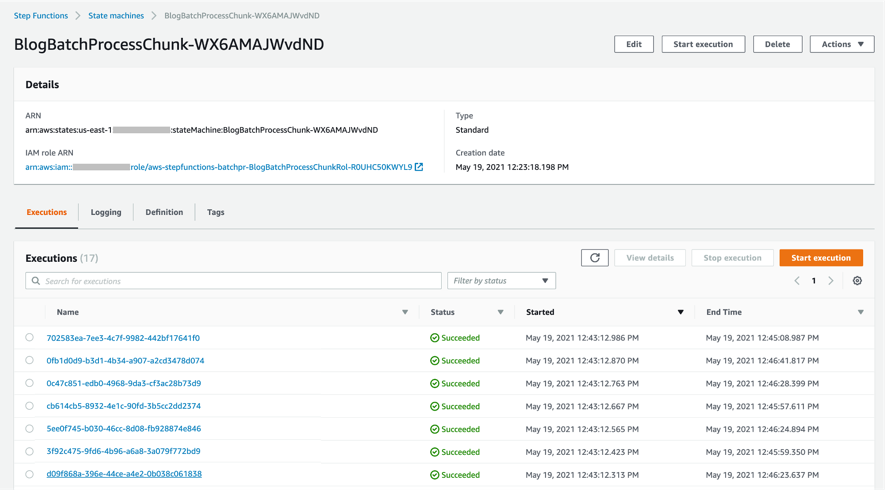
- 数分後、BlogBatchMainOrchestratorとBlogBatchProcessChunkの両ワークフローの全ての実行が完了します。BlogBatchMainOrchestratorは一回の実行、BlogBatchProcessChunkは複数の実行が行われています。これは、BlogBatchMainOrchestratorがチャンクされたファイルの回数分BlogBatchProcessChunkを呼び出しているためです。
出力の確認
-
- S3コンソールを開き、処理が完了した後に新しく作られたフォルダーを確認します。
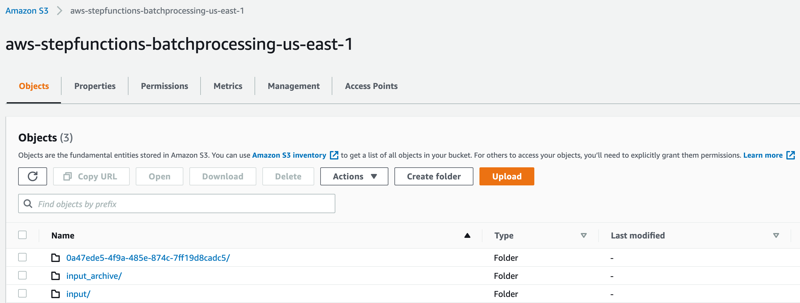
処理が完了した後には以下のサブフォルダーが作成されます:- input_archive – 入力オブジェクトのアーカイブフォルダー
- 0a47ede5-4f9a-485e-874c-7ff19d8cadc5 – ユニークなUUIDで名付けられたサブフォルダーです。実行している環境によって名前が変わっているため注意が必要です。今回の例では0a47から始まるIDで名付けられています。バッチ実行の中で作成されたオブジェクトを格納するためのものです。
- S3コンソールを開き、処理が完了した後に新しく作られたフォルダーを確認します。
-
- 0a47ede5-4f9a-485e-874c-7ff19d8cadc5(実行環境によって異なるUUID)のフォルダーを選択します。.
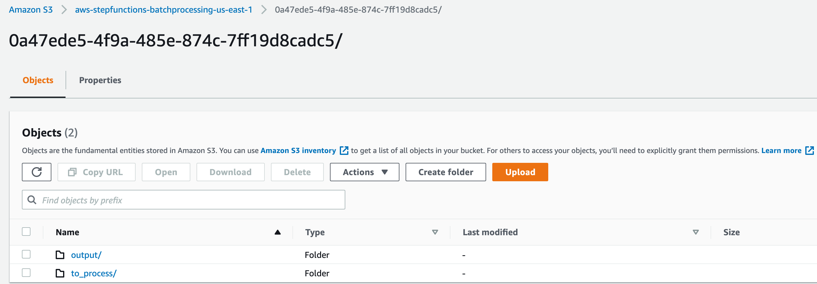
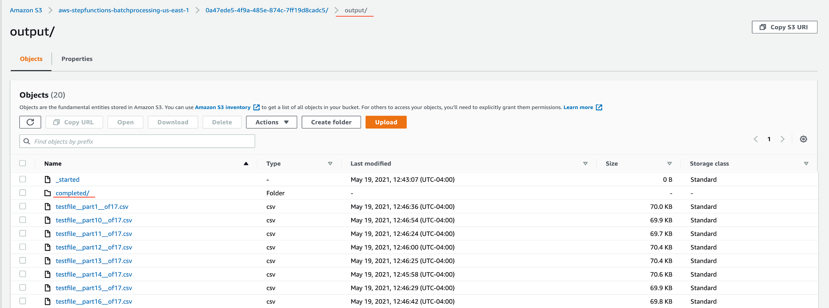
output – このフォルダは完成した出力オブジェクトや管理目的などのファイル、処理済みのチャンクファイルが格納されています。
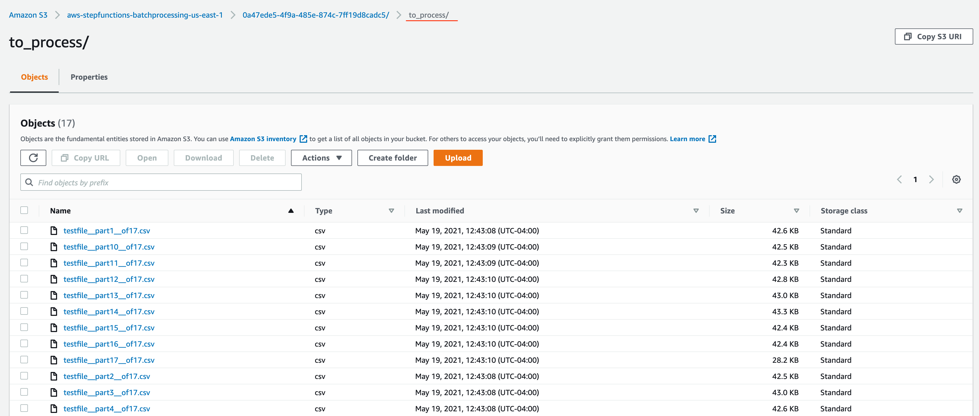
to_process – このフォルダは元の入力ファイルから分割して作られたオブジェクトが格納されています。
- 0a47ede5-4f9a-485e-874c-7ff19d8cadc5(実行環境によって異なるUUID)のフォルダーを選択します。.
- output/completedフォルダから処理後のオブジェクトを選択し開きます。
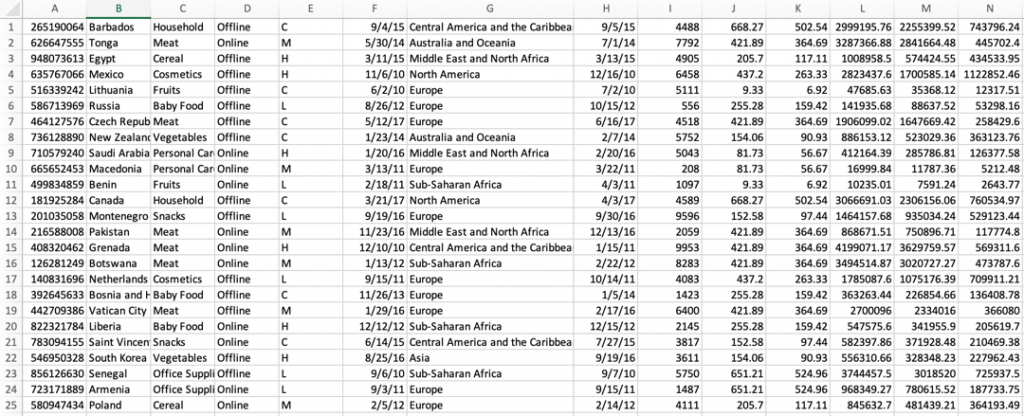
出力オブジェクトであるtestfile.csvを確認します。API呼び出しでDynamoDBから取得した追加データがカラムI〜カラムNに付加されています。

完了後のワークフローの確認
Step Functionsコンソールを開き、BlogBatchMainOrchestratorとBlogBatchProcessChunkのステートマシンを見ていきます。各ステートマシンの実行の一つを選択し、グラフインスペクターを確認してください。それぞれのstateの実行結果を見ることができます。
BlogBatchMainOrchestrator:

BlogBatchProcessChunk:

バッチ処理のパフォーマンス
今回のユースケースでは、入力の大きさごとにバッチの完了までに以下の時間がかかっています:
| レコード数 | バッチ完了までの時間 |
| 10 k | 5 minutes |
| 100 k | 7 minutes |
バッチのパフォーマンスはLambdaのメモリ設定やファイル内のデータなど他の様々な要因にに依存しています。Profiling functions with AWS Lambda Power Tuningの記事に、更に情報がありますので参照してみてください。
結論
この記事では、どのようにStep Functionsの機能や統合を使ってバッチ処理のソリューションをオーケストレーションできるかを紹介しました。2つのStep Functionsワークフローを使ってバッチを実装しました。一つは元ファイルを分割するワークフローでもう一つは分割した各チャンクファイルを処理するためのものでした。
このバッチプロセスアプリケーション全体のパフォーマンスは入力ファイルを複数のチャンクに分割することによって向上させることができます。各チャンクは別々のステートマシンで処理されていきます。Map stateを利用して各行を並列に処理することにより、ワークフローのパフォーマンスをさらに向上させることができます。
ぜひこちらのリポジトリからコードをダウンロードして、サーバーレスバッチ処理システムを構築してみてください。
その他のリソース:
- Orchestration examples with Step Functions
- Create a Serverless Workflow
- Building Business Workflows with AWS Step Functions
- Using a Map State to Call Lambda Multiple Times
サーバーレスについて他に学びたいことがあれば、Serverless Landをご覧になってみてください。
この記事の翻訳はソリューションアーキテクトの野村 侑志が担当しました。原文はこちらです。