Amazon Web Services 한국 블로그
Amazon Athena – 초단위 페타바이트급 동적 데이터 질의 서비스
(과거 1.44MB 플로피 디스크를 썼던 경험이 무색하게) 매일 우리는 매우 빠른 데이터량 성장에 놀라게 됩니다. 일상적으로 대량의 로그를 쌓고 질의하는 작업과 정형 혹은 반정형 데이터의 크기는 이미 페타바이트 규모입니다. 우리는 데이터의 위치를 찾아 로딩한 후 인덱싱을 통해 검색하는 일련의 과정을 빠르게 작업할 수 있는 방법을 찾고 있습니다. 이를 위해 높은 수준의 클라우드 솔루션을 가지고 있으며 모든 것이 수 분안에 처리될 수 있습니다.
Amazon Athena 소개
Amazon Athena는 Amazon S3에 저장되어 있는 페타데이터 규모의 데이터를 별도의 클러스터 구성 및 관리를 하지 않더라도 동적 질의를 할 수 있는 신규 서비스입니다. Amazon S3에 위치한 데이터를 지정만 하면, 내부 필드를 자동으로 인지해서 질의를 수행할 수 있습니다. 데이터를 옮기거나 별도 인덱스를 구성할 필요 없이 한 곳에서 할 수 있습니다.
Athena는 동적 질의 편집기를 통해 여러분이 손쉽게 작업을 할 수 있도록 도움을 주고 있으며, 표준 ANSI SQL 및 JOIN, 윈도 함수 등 고급 기능을 수행할 수 있습니다. Athena는 페이스북이 공개한 Presto를 기반으로 대부분 DDL (Data Definition Language)을 포함하는 PrestoSQL 역시 지원합니다.
Athena 서비스에 이면에서는 여러분이 보낸 질의를 병렬적으로 수백 또는 수천개의 코어를 통해 작업하여 결과를 (동적 혹은 JDBC/ODBC 커넥터를 통해) 초단위로 제공합니다.
Athana가 S3에 저장된 데이터를 직접 참조함으로서, 확장성 및 유연성 그리고 데이터 내구성, 데이터 보호 관점에서 이점을 얻을 수 있습니다. 예를 들어 KMS를 기반한 서버사이드 암호화를 통해 데이터 접근을 위해 IAM 정책을 정할 수 있습니다.
또한, Apache 로그, CSV, TSV, 일반 텍스트, JSON, Orc, Parquet 등 다양한 데이터 포맷을 지원할 뿐만 아니라 하나 이상의 S3 객체를 테이블로 지정할 수 있습니다. 각 Athena 데이터베이스는 하나 이상의 테이블로 구성되어 있는데 카탈로그 매니저를 통해 데이터 소스를 파악하고 추적할 수 있습니다.
Athena 사용해 보기
AWS 관리 콘솔을 통해 Amazon Athena 서비스를 선택하면, 아래와 같이 질의 편집기를 처음 보실 수 있습니다.
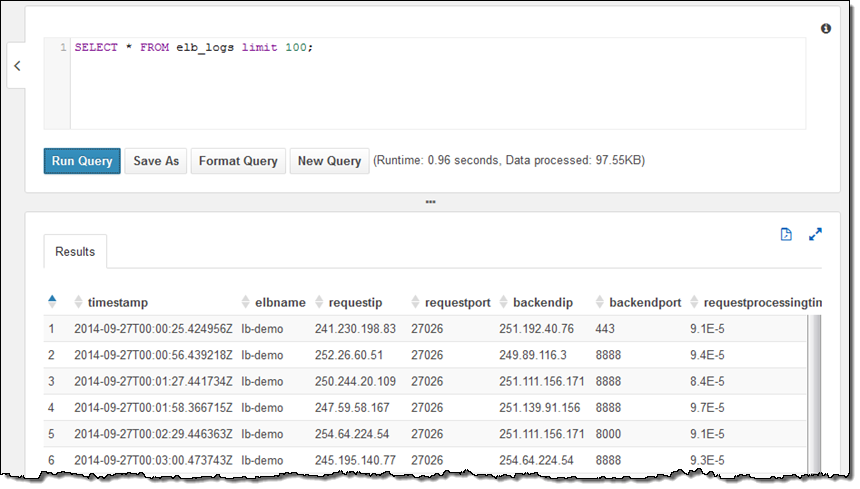
저의 계정은 이미 샘플 데이터베이스를 설정을 하였고, 데이터 베이스 내에는 elb_logs라는 테이블이 있습니다. 이제 간단한 질의문를 선택해서 Run Query를 누르면 됩니다. 몇 초 안에 결과가 바로 콘솔에 보이는 것을 보실 수 있습니다. 이제 결과를 CSV 파일 형태로 다운로드 할 수도 있습니다.
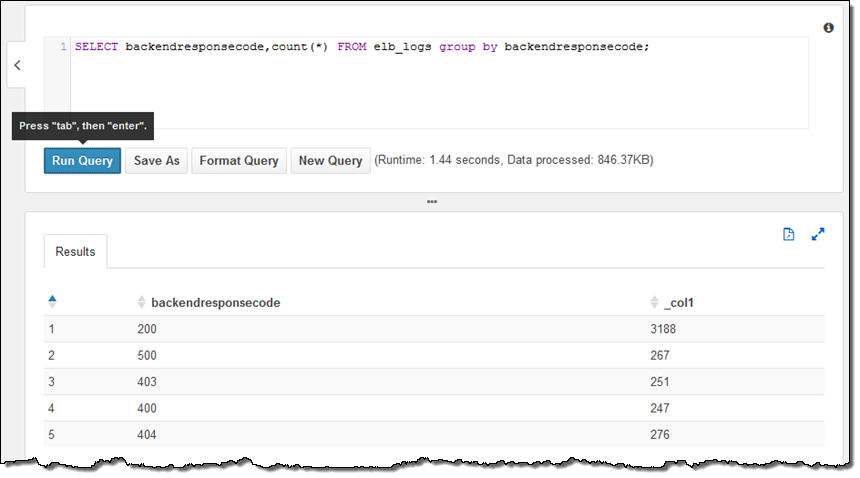
샘플 테이블은 Elastic Load Balancing의 로그 파일로서 HTTP 상태 코드로 분석할 수 있습니다.
URL은 아래와 같습니다.
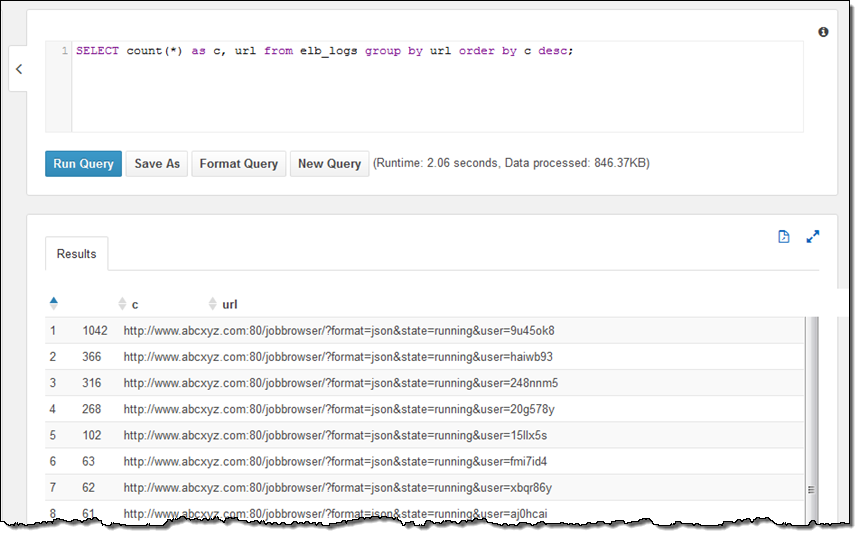
테이블 정의 지점은 S3 버킷이고 버킷 내 모든 객체를 encompass 합니다. 만일 새로운 로그 파일이 동적 세션에 들어오게 되면, 자동으로 순서에 따라 질의가 포함됩니다. (테이블 정의에 대해서는 아래에서 설명하겠습니다.)
콘솔에서 테이블 설명을 하기 위한 질의문을 실행 해보겠습니다. 그리고, 테이블과 필드명을 선택해서 질의에 값을 넣을 수 있습니다.
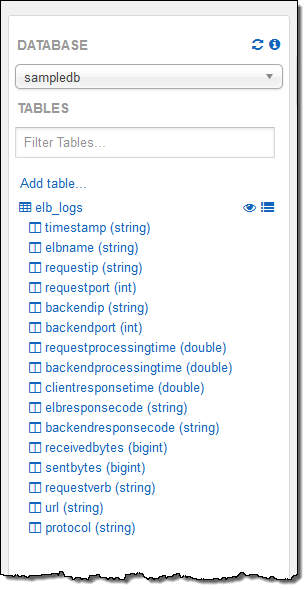
질의문을 저장하여 제가 원하는 작업을 마칩니다.
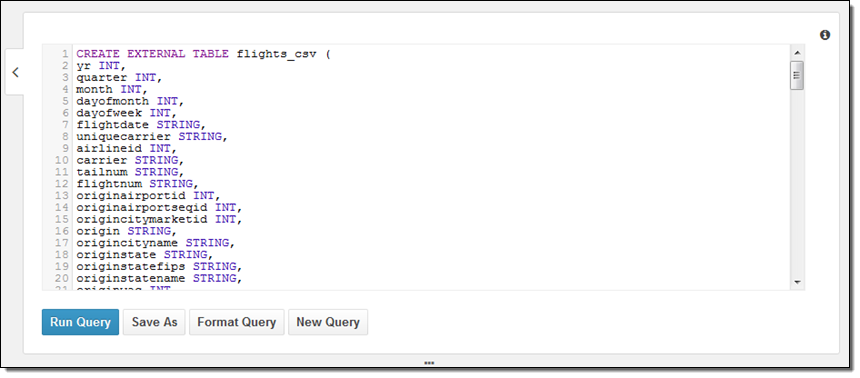
다음으로는 어떻게 데이터베이스를 만들고, 직접 데이터를 참조시키는지에 대해 배워 보겠습니다. 여기에는 두 가지 방법이 있습니다. 하나는 DDL 정의를 하는 것과 단계적 마법사 기능입니다. 동료로 부터 아래와 같은 간단한 샘플 DDL을 받았습니다.
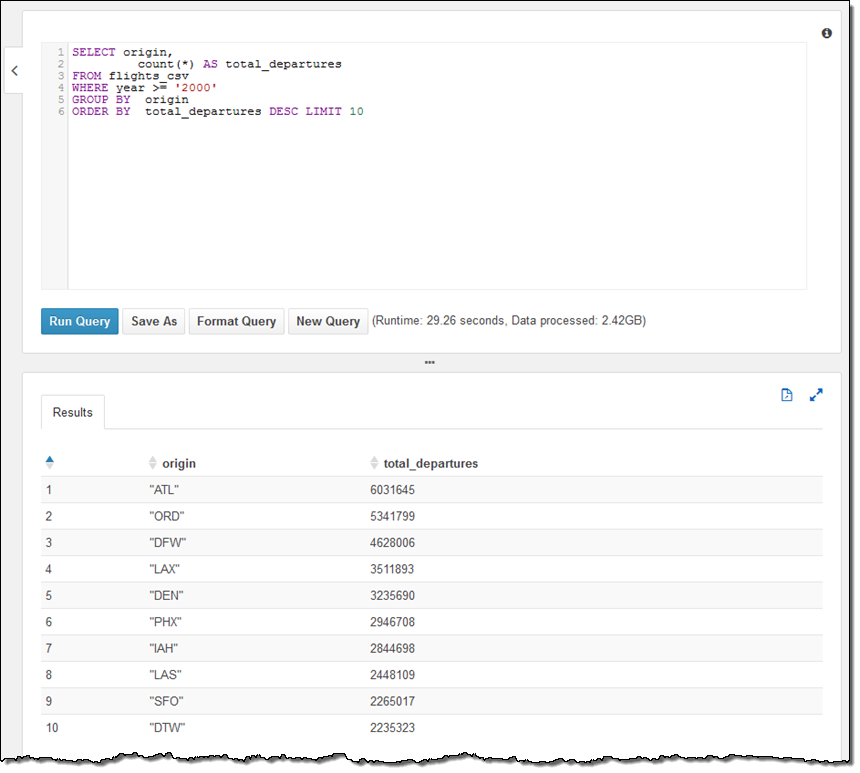
더 관심 있는 것은 질의문이구요. 아래와 같이 구성할 수 있습니다.
PARTITIONED BY (year STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION 's3://us-east-1.elasticmapreduce.samples/flights/cleaned/gzip/';
데이터는 연간으로 분리되어 있기 때문에, 메타 데이터 설정을 마무리하기 위해 아래 부속 질의를 하나 더 해야 합니다.
MSCK REPAIR TABLE flights_csv;위 예제는 2000년 부터 지금까지 가장 인기 있는 출발 공항이 있는 도시 10개를 추출하는 질의문입니다.
또한, Athena가 제공하는 테이블 마법사를 통해 (Catalog Manager에서 접근 가능) 테이블을 생성할 수 있습니다. 이 경우, 테이블 이름과 원하는 위치를 지정해주면 됩니다.
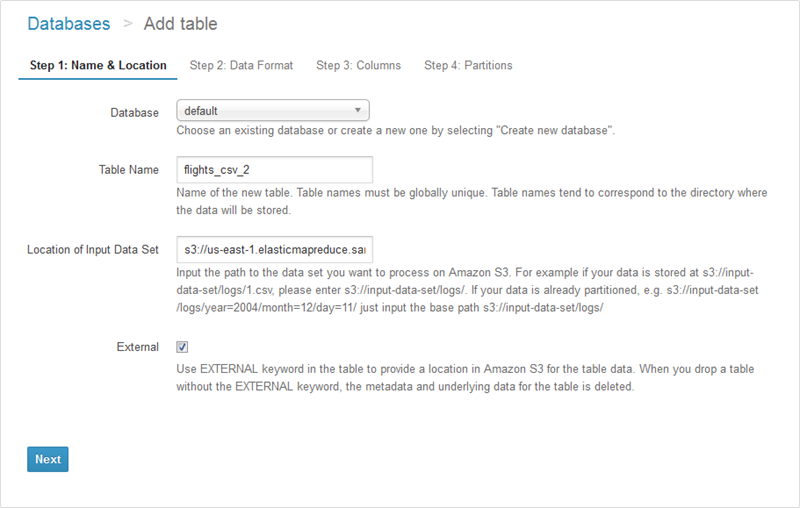
그다음 포맷을 지정합니다.
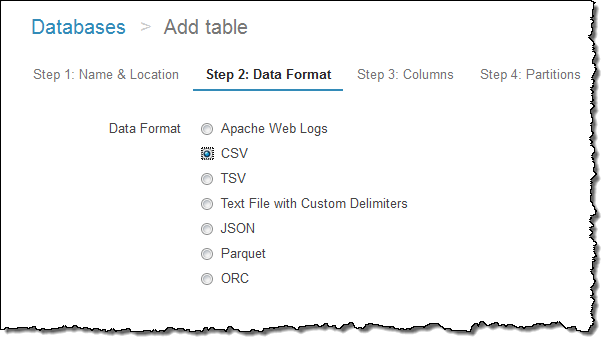
각 컬럼의 이름과 형식을 지정합니다.
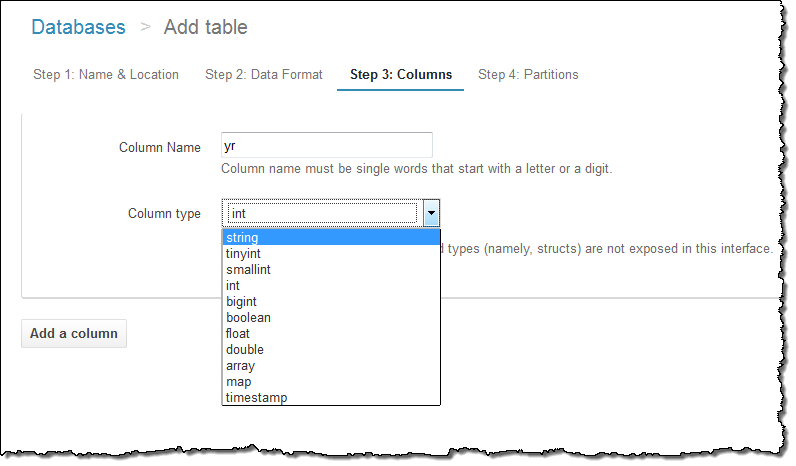
파티션 모델을 지정합니다.
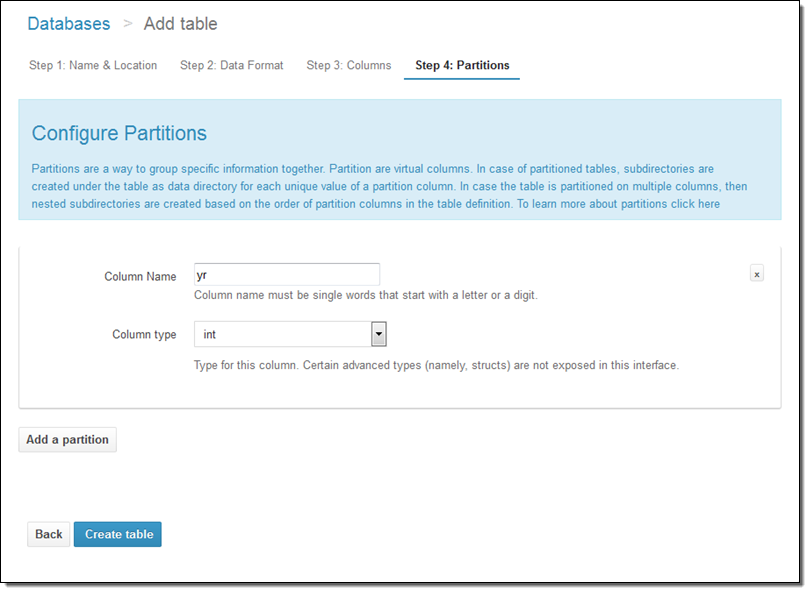
Athena는 그 밖에도 많은 신선한 기능이 있는데, 향후에 더 자세히 알려드릴려고 합니다. 우선 그 중에서도 질의 저장 기능, 질의 기록, 및 Catalog Manager에 대해서만 잠깐 살펴 보겠습니다.
앞에서 보셨다시피 Saved Queries를 누르면, 질의 시 저장했던 질의문을 모두 보실 수 있습니다.
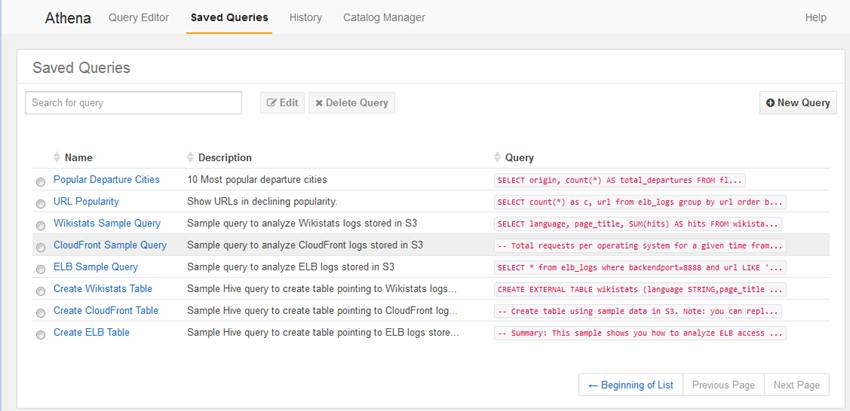
그대로 사용할 수도 있고, 편집해서 다시 질의할 수도 있습니다.
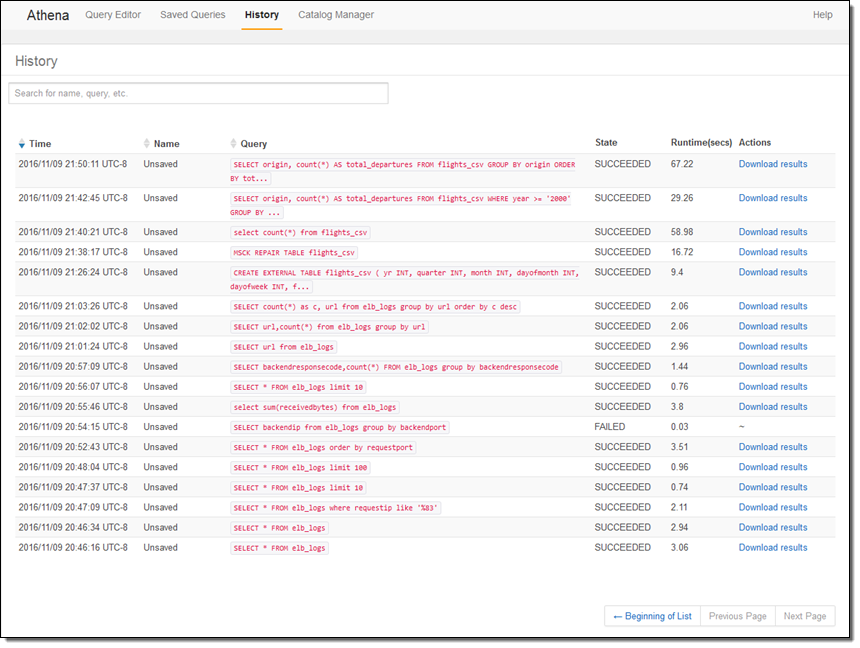
History를 누르면, 이전 질의 기록 뿐만 아니라 생성된 데이터 다운로드도 가능합니다.
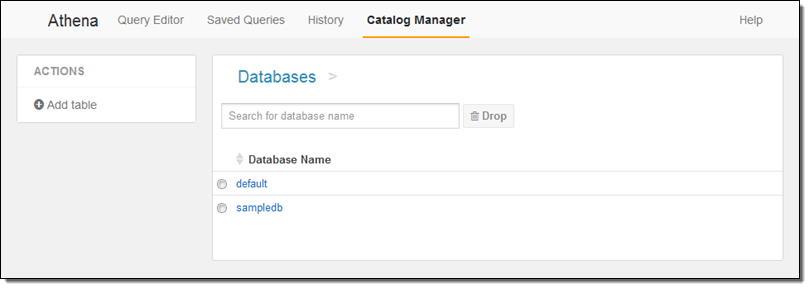
Catalog Manager에서는 기존 데이터베이스 및 신규 데이테베이스 및 테이블 생성이 가능합니다.
이 블로그 글에서 주로 화면으로 보이는 동적 기능 측면만 언급했지만, JDBC나 ODBC 커넥터를 통해 여러분이 지금 사용중인 비지니스 인텔리전스 분석 도구와 결합할 수 있다는 점을 염두해 주시기 바랍니다.
정식 출시
Amazon Athena는 US East (Northern Virginia), US West (Oregon), EU (Ireland)에 오늘 정식 출시합니다. (다른 AWS 리전에 대해서는 가능한 빠르게 출시가 가능하도록 지속적으로 확대해 나갈 예정입니다.)
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 Amazon Athena – Interactively Query Petabytes of Data in Seconds의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.