Amazon Web Services 한국 블로그

몇 초 만에 Amazon Aurora PostgreSQL 서버리스 데이터베이스를 만들어보세요!
AWS의 데이터베이스 부문 VP, Colin Lazier는 re:Invent 2025에서 아이디어를 즉각적으로 실제 환경에 반영하여 개념 단계에서 애플리케이션 운영 단계까지 빠르게 진행하는 것이 중요하다고 강조했습니다. 고객들은 이미 프로덕션 환경에 바로 사용 가능한 Amazon DynamoDB 테이블과 Amazon Aurora DSQL 데이터베이스를 몇 초 만에 생성할 수 있습니다. Colin은 Amazon Aurora Serverless 데이터베이스도 이와 같은 속도로 생성할 수 있다는 것을 […]

AWS 주간 소식 모음: NVIDIA Nemotron 3 Super 모델 Amazon Bedrock 탑재, Nova Forge SDK, Amazon Corretto 26 출시 등
안녕하세요. 이번에 처음으로 AWS 주간 요약을 맡게 된 Daniel Abib입니다. 저는 AWS의 Senior Specialist Solutions Architect로, 생성형 AI와 Amazon Bedrock를 주로 담당합니다. 솔루션 아키텍처, 소프트웨어 개발 및 클라우드 아키텍처 분야에서 28년 이상의 경험을 쌓았고, 스타트업과 대기업이 Amazon Bedrock을 통해 생성형 AI의 성능을 활용할 수 있도록 지원하는 역할을 맡고 있습니다. 저는 AWS에서 6년 반 이상 근무하면서 […]

AWS 클라우드 20년 – 시간이 쏜살같이 지났네요!
AWS가 20주년을 맞이했습니다! 꾸준한 혁신을 거듭해 온 AWS는 현재 240여 개의 포괄적인 클라우드 서비스를 제공하며, 매년 수백만 명의 고객을 위해 수천 개의 새로운 기능을 계속 출시하고 있습니다. 그동안 이 블로그에는 4,700여 개의 게시물이 올라왔는데, 이는 Jeff Barr가 10주년 기념 게시물을 작성한 이후 두 배 이상 증가한 수치입니다. 내 인생을 바꾼 AWS 지금으로부터 20년 전인 2006년 […]
AWS 주간 소식 모음: Amazon S3 20주년, Amazon Route 53 Global Resolver 정식 출시 등
지난주, Amazon S3가 2006년 3월 14일 정식 출시된 지 정확히 20년이 되었습니다. Amazon Simple Storage Service는 종종 클라우드 인프라를 정의한 기본 스토리지 서비스로 여겨지지만, 단순한 객체 스토리지 서비스로 시작한 S3는 이제 그 범위와 규모가 훨씬 더 커졌습니다. 2026년 3월 현재 Amazon S3는 500조 개 이상의 객체를 저장하고 있으며, 전 세계적으로 수백 엑사바이트 규모의 데이터를 대상으로 […]
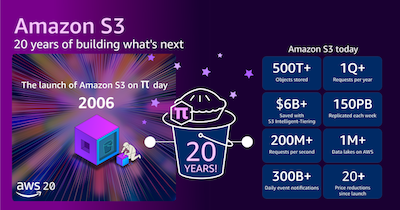
Amazon S3의 20년 역사와 차세대 서비스 방향
20년 전 오늘, 2006년 3월 14일에 Amazon Simple Storage Service(Amazon S3)는 새로운 소식 페이지에 게시된 한 단락의 간단한 발표와 함께 조용히 출범했습니다. Amazon S3는 개발자가 웹 스케일 컴퓨팅을 쉽게 구현할 수 있도록 설계된 인터넷용 스토리지입니다. Amazon S3는 언제 어디서든, 웹에 원하는 양의 데이터를 저장하고 검색하는 데 사용할 수 있는 간단한 웹 서비스 인터페이스를 제공합니다. 이를 […]

Amazon S3 범용 버킷용 계정 리전별 네임스페이스 소개
오늘은 자체 계정의 리전 네임스페이스에서 범용 버킷을 만들어 데이터 스토리지 크기와 범위 요구 사항이 늘어남에 따라 버킷 생성과 관리를 간소화해 주는 Amazon Simple Storage Service(Amazon S3) 새 기능을 발표합니다. 여러 AWS 리전에서 범용 버킷 이름을 생성하면서도 원하는 버킷 이름을 항상 사용할 수 있도록 보장할 수 있습니다. 이 기능을 사용하면 요청한 버킷 이름에 계정의 고유한 접미사를 […]
AWS 주간 소식 모음: Amazon Connect Health, Bedrock AgentCore Policy, GameDay Europe 등
AWS Student Community 케냐에 가입하세요! 지난주는 놀라움의 연속이었습니다. 케냐 전역에서 열린 모임, 실습 워크숍, 진로 토론은 메루 과학 기술 대학교에서 열린 AWS Student Community Day로 절정에 달했습니다. 이 행사에서는 제 동료 Veliswa와 Tiffany가 기조연설을 맡았으며 GitOps에서 클라우드 네이티브 엔지니어링, 그리고 대량의 AI 에이전트 구축에 이르는 다양한 세션이 진행되었습니다. JAWS Days 2026은 3월 7일에 1,500명 이상의 […]

Amazon Lightsail 기반 OpenClaw 출시 – 자율 프라이빗 AI 에이전트를 실행해보세요!
Amazon Lightsail 기반 OpenClaw가 정식 출시되었음을 발표합니다. 이제 OpenClaw 인스턴스를 시작하여 브라우저를 페어링하고, AI 기능을 활성화하며, 선택적으로 메시징 채널을 연결할 수 있습니다. Lightsail OpenClaw 인스턴스는 Amazon Bedrock을 기본 AI 모델 제공자로 사용하도록 사전 구성되어 있습니다. 설정을 완료하면 AI 어시스턴트와 즉시 채팅을 시작할 수 있습니다. 추가 구성은 필요하지 않습니다. OpenClaw는 사용자의 컴퓨터에서 직접 실행되어 개인 디지털 […]
AWS 주간 소식 모음: OpenAI 파트너십, AWS Elemental Inference, Strands Labs 등
지난 한 주 동안 저는 AI-DLC(AI 기반 수명 주기) 워크숍을 통해 고객들이 비즈니스를 혁신하도록 지원하는 일에 깊이 몰두했습니다. 2026년 내내 저는 다양한 고객을 대상으로 이러한 세션을 진행하며, 조직이 측정 가능한 비즈니스 가치를 제공하는 AI 사용 사례를 식별하고, 우선순위를 정하며, 실제 구현까지 연결할 수 있도록 구조화된 프레임워크를 안내하는 특권을 누렸습니다. AI-DLC는 기업이 AI 실험 단계에서 프로덕션 […]

AWS Security Hub Extended, 엄선된 파트너 솔루션을 통한 풀 스택 엔터프라이즈 보안 기능 출시
지난 AWS re:Invent 2025에서는 Amazon GuardDuty와 Amazon Inspector를 비롯한 AWS 보안 서비스를 단일 환경으로 통합하는 완전히 새로워진 AWS Security Hub를 도입했습니다. 이 통합 환경은 보안 조사 결과를 자동으로, 지속적으로 조합 분석하여 중요한 보안 위험의 우선순위를 지정하고 대응할 수 있도록 지원합니다. 오늘은 엔드포인트, ID, 이메일, 네트워크, 데이터, 브라우저, 클라우드, AI 및 보안 운영 전반에서 풀 스택 […]