Amazon Web Services 한국 블로그

AWS Elemental Inference, 모바일 시청자를 위한 라이브 비디오 변환 서비스 출시
오늘 AWS는 라이브 및 온디맨드 비디오 방송을 자동으로 변환하고 대규모 시청자 참여를 극대화하는 완전 관리형 AI 서비스인 AWS Elemental Inference를 발표합니다. 출시와 함께 AWS Elemental Inference를 사용해 동영상 콘텐츠를 모바일 및 소셜 플랫폼에 최적화된 세로 형식으로 실시간 변환할 수 있습니다. AWS Elemental Inference를 통해 방송사와 스트리머는 수작업 후반 편집이나 AI 전문 지식 없이도 TikTok, Instagram […]

AWS 주간 소식 모임: Claude Sonnet 4.6 in Amazon Bedrock, Kiro, GovCloud 리전, 신규 Agent Plugins 출시 등
지난주 저희 팀은 미국 새너제이에서 열린 개발자 주간에서 많은 개발자들을 만났습니다. 제 동료인 Vinicius Senger는 Kiro를 활용해 인간과 AI가 공동 개발자로 협업하는 새로운 애플리케이션 구축 및 진화 방식인 ‘재탄생 소프트웨어’를 주제로 훌륭한 기조연설을 했습니다. 다른 동료들은 프로덕션에 바로 사용할 수 있는 AI 에이전트의 구축 및 배포에 대해 발표했습니다. 참석자들은 에이전트 메모리, 다중 에이전트 패턴, 메타 […]

Amazon EC2 HPC8a 인스턴스 정식 출시, 5세대 AMD EPYC 프로세서 기반 고성능 컴퓨팅 워크로드용
오늘은 최대 4.5GHz의 주파수를 갖춘 최신 5세대 AMD EPYC 프로세서로 구동되는 새로운 고성능 컴퓨팅(HPC) 최적화 인스턴스 유형인 Amazon Elastic Compute Cloud(Amazon EC2) Hpc8a 인스턴스의 정식 출시를 발표합니다. 이러한 인스턴스는 전산 유체 역학, 더 빠른 설계 반복을 위한 시뮬레이션, 촉박한 운영 시간 내에서의 고해상도 날씨 모델링, 빠른 결과 도출이 필요한 복잡한 충돌 시뮬레이션 등 컴퓨팅 집약적인 […]

Amazon SageMaker Inference, 사용자 지정 Amazon Nova 모델 추론 서비스 제공
AWS NY Summit 2025에서 Amazon SageMaker AI의 Amazon Nova 사용자 지정 기능을 발표한 이래, 고객들은 Amazon SageMaker Inference에서 오픈 웨이트 모델을 사용자 지정할 때와 동일한 기능을 Amazon Nova에서도 요구해 왔습니다. 또한 프로덕션 워크로드에 요구되는 인스턴스 유형, 오토 스케일링 정책, 컨텍스트 길이, 동시성 설정 등에 대해 사용자 지정 모델 추론을 더 효과적으로 제어하고 더 높은 유연성을 […]
AWS 주간 소식 모음: Amazon EC2 M8aZn 인스턴스, Amazon Bedrock 신규 오픈 웨이트 모델 출시 등
저는 2021년에 AWS에 합류했고, 그 이후로 Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스 패밀리가 빠른 속도로 성장하는 것을 지켜보았는데, 아직도 놀라울 따름입니다. AWS Graviton 기반 인스턴스부터 특화된 가속 컴퓨팅 옵션에 이르기까지 몇 달에 한 번씩 성능 한계를 뛰어넘는 새로운 인스턴스 유형이 등장하는 것처럼 느껴집니다. 2026년 2월 현재 AWS는 1,160개 이상의 Amazon EC2 인스턴스 유형을 제공하고 있으며, […]
AWS 주간 소식 모음: Amazon Bedrock, Claude Opus 4.6 모델 지원, AWS Builder ID 애플 로그인 지원 등
다음은 AWS에서 애플리케이션을 구축하고 확장하며 혁신하는 데 도움이 될 수 있는 지난주 주목할 만한 출시 및 업데이트입니다. 지난주 출시 제품 지난주 주목할 만한 출시 사항을 소개합니다. 먼저 컴퓨팅 및 네트워킹 인프라 관련 소식입니다. Amazon EC2 C8id, M8id 및 R8id 인스턴스 출시: 새로운 Amazon EC2 C8id, M8id 및 R8id 인스턴스는 사용자 지정 Intel Xeon 6 프로세서를 […]

Amazon EC2 C8id, M8id, R8id 인스턴스 정식 출시, 최대 22.8TB 로컬 NVMe 스토리지 지원
작년에 Amazon Elastic Compute Cloud(Amazon EC2) C8i 인스턴스, M8i 인스턴스, R8i 인스턴스를 출시했습니다. 이러한 인스턴스는 지속적인 올코어 3.9GHz 터보 주파수로 AWS에서만 사용할 수 있는 사용자 지정 Intel Xeon 6 프로세서 기반입니다. 이러한 인스턴스는 동급 Intel 프로세서 중 가장 뛰어난 성능과 가장 빠른 메모리 대역폭을 클라우드에 제공합니다. 오늘은 호스트 서버에 물리적으로 연결된 최대 22.8TB의 NVMe 기반 […]
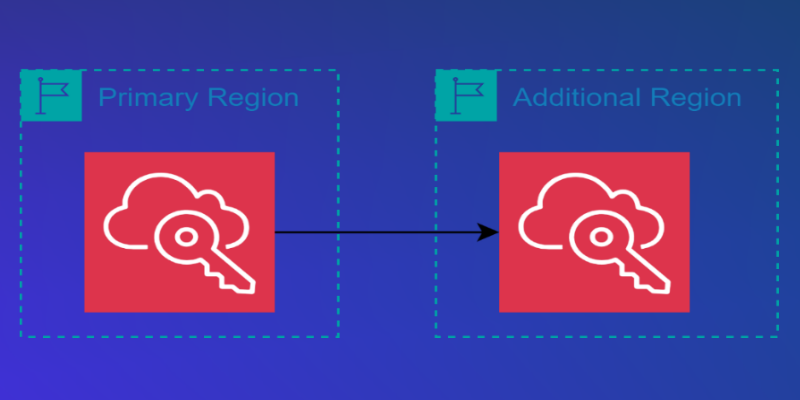
AWS IAM Identity Center, AWS 계정 액세스 및 애플리케이션 사용을 위한 다중 리전 복제 지원
오늘 AWS는 추가 AWS 리전에서 AWS 계정 액세스와 관리형 애플리케이션 사용을 가능하게 하는 AWS IAM Identity Center 다중 리전 지원 기능의 정식 출시를 발표합니다. 이 기능을 사용하면 Microsoft Entra ID, Okta와 같은 외부 ID 제공업체(IdP)에 연결된 IAM Identity Center 조직 인스턴스에서 현재 기본 리전에 있는 직원 ID, 권한 세트, 기타 메타데이터를 추가 리전으로 복제하여 AWS […]
AWS 주간 소식 모음: Amazon Bedrock 에이전트 워크플로, Amazon SageMaker 프라이빗 연결 등
지난주에는 중국 전통 달력에서 음력 설을 앞둔 마지막 단계를 알리는 절기인 라바절이 있었습니다. 중국의 많은 사람들에게 이 시기는 한 해를 정리하고 되돌아보며 앞으로 다가올 시간에 대비하고, 지난 한 해가 남긴 것을 마무리하고, 시선을 미래로 돌리는 시기입니다. 미래를 바라보면, 다음 주에는 봄의 시작이자 24절기 중 첫 번째 절기인 입춘이 다가옵니다. 중국 전통에서 봄은 성장의 시작이자 새로운 […]
AWS 주간 소식 모음: Amazon EC2 G7e 인스턴스, Amazon Corretto 업데이트 등
안녕하세요! 2026년 첫 게시물입니다. 제 집 앞 차량 진입로를 파내는 모습을 지켜보면서 글을 쓰고 있습니다. 독자 여러분은 어디에 계시든 안전하고 따뜻하고, 데이터가 순조롭게 이동하고 있기를 기원합니다. 이번 주에는 GPU 집약적 워크로드를 실행하는 고객에게 희소식이 있습니다. NVIDIA 최신 Blackwell 아키텍처 기반의 최신 그래픽 및 AI 추론 인스턴스가 출시됩니다. 몇 가지 서비스 강화 요소와 리전 확장 외에, […]