AWS 기술 블로그
Amazon Bedrock Knowledge base로 30분 만에 멀티모달 RAG 챗봇 구축하기 실전 가이드
생성형 AI의 발전과 함께, 맞춤형 데이터를 기반으로 AI의 답변을 생성하는 RAG (Retrieval-Augmented Generation, 검색 증강 생성) 기법이 함께 주목받고 있습니다. RAG는 대규모 언어 모델이 응답을 생성하기 전에 학습 데이터 소스 외부의 맞춤형 지식 베이스를 참조하도록 하는 프로세스를 말합니다. RAG를 활용하면 모델을 다시 학습 시킬 필요 없이 특정 도메인이나 조직의 내부 지식을 기반으로 LLM 기능을 확장할 수 있고, 근거 없는 답변을 생성하는 환각(Hallucination)을 줄여 생성형 AI의 정확도를 높이는 비용 효율적인 접근 방식입니다.
Amazon Bedrock 역시 RAG 구축을 위한 손쉬운 방법으로 Knowledge base 기능을 지원하고 있습니다. Amazon Bedrock Knowledge base를 이용하면 클릭 몇 번으로 FM을 OpenSearch와 같은 RAG용 데이터 소스에 연결하여 원하는 문서 기반의 AI를 만들고 테스트할 수 있습니다.

그리고, 이러한 RAG 시스템이 복잡한 실제 애플리케이션에 적용되기 위해서는 이미지나 표에 있는 데이터도 잘 검색할 수 있는 능력, 즉 멀티모달 처리 성능이 중요합니다. 지금까지 멀티모달 성능을 갖춘 RAG를 구현하기 위해서는 여러 데이터 전처리 작업을 거쳐야 했지만, 지난 2024년 7월 10일에 Bedrock에 새로 추가된 ‘Chunking and parsing configurations’의 고급 파싱 옵션 설정을 통해 손쉽게 멀티모달 RAG를 구현할 수 있게 되었습니다.
이에 본 포스팅에서는 Amazon Bedrock Knowledge base를 활용해 고성능 멀티모달 RAG를 손쉽게 구축하는 방법에 대해 알아보고, 이렇게 구축한 RAG를 아래 그림과 같은 챗봇 애플리케이션 형태로 EC2에 배포하는 방법을 코드와 함께 단계별로 소개합니다. 또한 ‘Chunking and parsing configurations’의 고급 파싱 옵션을 추가한 RAG와, 그렇지 않은 일반 RAG의 멀티모달 성능을 비교해보며 이 기능이 얼마나 손쉬우면서도 강력한지 알아보겠습니다.

평소 다음과 같은 질문을 갖고 계셨던 분들이라면 해당 포스팅을 읽고 직접 따라해보시기를 추천 드립니다.
- “RAG를 어떻게 구현해야 할까요?”
- “Amazon Bedrock을 이용해 RAG를 구현했는데, 이를 어떻게 실제 애플리케이션(e.g. 챗봇)과 통합할 수 있나요?”
- “검색하고자 하는 문서에 이미지나 표가 포함되어 있어 RAG의 검색 성능이 떨어집니다. 어떻게 성능을 높일 수 있을까요?”
Step 1. Knowledge base와 연동할 S3 소스 버킷 생성
먼저 Bedrock Knowledge base와 연동할 S3 버킷을 생성해야 합니다. 해당 링크를 클릭해 us-west-2 (오레곤) 리전에서 AWS S3 Console에 접속해 새로운 버킷을 생성할 수 있습니다. 이후 단계에서 Bedrock Knowledge base를 생성할 때 해당 버킷 이름을 활용해야 하므로 고유하면서 기억하기 쉬운 이름을 입력하고, 그 외 설정은 기본값으로 두고 버킷을 생성합니다.
버킷 생성이 완료되면, RAG를 통해 검색하고자 하는 문서를 해당 버킷에 미리 업로드해두겠습니다.
(본 실습에서는 50장 분량의 EC2 사용자 가이드 PDF를 내려받아 업로드했습니다: ec2_userguide_1-50.pdf)

Step 2. Bedrock Knowledge base 생성하기
Bedrock model access 요청하기
Bedrock Console에 접근해, 가장 먼저 Bedrock 서비스를 통해 사용하고자 하는 파운데이션 모델 (FM)에 대해 액세스를 요청해야 합니다. 아래 스크린샷과 같이 왼쪽 사이드바에서 Model access를 클릭해 액세스 요청 페이지에 접속합니다.

아래와 같이 Model access 페이지에서 ‘Enable specific models’를 클릭합니다.

본 실습에서 사용할 모델은 아래와 같습니다. 해당 모델을 선택한 후 Next (다음)을 클릭합니다.
- Claude 3 Sonnet
- Titan Embeddings G1 – Text
- Titan Text Embeddings V2

Access 신청을 원하는 모델이 잘 선택되었는지 확인 후 Submit (제출)을 클릭해 신청을 완료합니다. 일부 모델은 Access를 부여받기까지 시간이 소요될 수 있습니다. Access 신청이 완료되면 아래와 같이 Access Status 가 Access granted 로 변경됩니다.
Bedrock knowledge base 생성 및 S3 데이터 소스 연결하기
이제 Bedrock Knowledge base를 생성할 준비가 되었습니다. Bedrock Console의 좌측 사이드바에서 Knowledge bases (지식 기반)을 클릭해 생성 화면에 접속하고, ‘Create knowledge base’ 버튼을 클릭합니다.
아래와 같이 설정하고, ‘Next (다음)’ 버튼을 눌러 다음 설정으로 이동합니다.
다음은 Knowledge base의 Data source를 설정하는 단계입니다. ‘Browse S3’ 버튼을 클릭하고, 앞서 [Step 1]에서 생성했던 버킷을 선택해줍니다.

검색 성능을 높이기 위해 Chunking and parsing configurations 설정하기
앞에서 잠시 언급한 것처럼, 지난 7월 10일에 Bedrock Knowledge base에 새로 추가된 ‘Chunking and parsing configurations’ 설정으로 이미지나 표 형태의 데이터에 추가 파싱을 통해 멀티모달 처리 성능을 높일 수 있게 되었습니다. 이 옵션에는 설정할 수 있는 여러 기능이 있지만, 그 중에서 오늘 살펴볼 ‘LLM을 활용한 고급 파싱 기능 (Use foundation model for parsing)’은 PDF와 같이 구조화되지 않은 문서에서 정보를 markdown 형태로 구조화하고, 이미지 및 테이블이 포함하고 있는 정보도 검색 가능한 텍스트 형태로 인덱싱하는 데 도움이 됩니다.
아래와 같이 ‘Chunking and parsing configurations’를 ‘Custom’으로 선택하고, Parsing strategy에서 ‘Use foundation model for parsing’ 체크박스를 체크한 뒤, 파싱에 사용할 모델을 ‘Claude 3 Sonnet v1’과 ‘Claude 3 Haiku v1’ 중 하나로 선택합니다. (해당 실습에서는 Sonnet v1 모델을 사용합니다)
위 스크린샷에서 빨간 사각형으로 표시한 부분이 파싱을 위해 LLM에 전달하는 프롬프트입니다. 해당 프롬프트는 원하는 대로 수정할 수 있지만, 해당 실습에서는 기본으로 주어지는 프롬프트를 그대로 사용했습니다. 기본 프롬프트의 내용을 요약하면 아래와 같습니다.
- 각 페이지를 주의 깊게 살피고, 헤더, 본문 텍스트, 각주, 표, 이미지 및 페이지 번호 등 페이지에 있는 모든 요소를 식별해 마크다운 형식으로 변환합니다.
- 메인 제목에는 #, 섹션에는 ##, 하위 섹션에는 ### 등을 사용 (기타 가이드 생략)
- Visualization (이미지 등) 요소를 발견한 경우, 이에 대한 자세한 설명을 작성합니다.
- Table (표) 요소를 발견할 경우, 마크다운 테이블로 변환합니다.
- (중략)
이와 같이 LLM 파싱 기능은 문서를 검색 가능한 형태로 임베딩하기에 앞서 위와 같은 프롬프트를 활용해 LLM이 구조를 재정의하게 함으로써 텍스트는 물론 이미지 및 표에 대한 검색 성능을 높일 수 있습니다. 문서 처리에 LLM을 사용하는 것이므로 대용량 문서에 활용할 때에는 비용을 고려하는 것이 좋습니다.
위 설정 후 스크롤을 아래로 내려 Chunking strategy를 선택할 수 있습니다. 해당 게시물에서는 ‘Hierarchical chunking’를 선택했습니다. 이후 token size 설정은 모두 기본값으로 두고 ‘Next’를 클릭합니다.
이밖에 Chunking and parsing configurations에서 설정할 수 있는 다양한 Chunking 전략 및 메타데이터 프로세싱 설정과 관련해서는 다음 블로그 게시물을 참고하시면 좋습니다. 대상 문서의 크기, 종류 및 기타 특성을 고려해 상황에 맞는 Chunking 옵션을 선택하는 것이 RAG의 성능을 높이는 데 도움이 됩니다.

임베딩 모델 선택 및 벡터 DB로서의 OpenSearch serverless 생성하기
사용할 Embedding 모델을 선택할 수 있으며, 해당 실습에서는 Titan text Embeddings v2 모델을 선택합니다. Vector dimensions 역시 RAG의 정확도 및 속도를 결정하는 요인이므로, 기본 제공되는 값 외에 원하는 값으로 설정이 가능합니다. 해당 게시물에서는 기본값인 1024를 사용합니다.
Vector database로는 ‘Quick create a new vector store’ 옵션을 선택해 OpenSearch Serverless를 새로 생성해줍니다. 이후 ‘Next (다음)’ 버튼을 눌러 검토 단계로 이동하고, 검토 후 ‘Create knowledge base’ 버튼을 클릭해 Knowledge base를 생성합니다. 설정한 내용대로 Knowledge base를 구성하고 OpenSearch Serverless를 생성하는 데에 수 분이 소요됩니다.


생성한 Knowledge Base에 S3의 데이터 Sync 하고 테스트하기
Knowledge base가 성공적으로 생성되었습니다. Data source에 앞서 [Step 1]에서 만들었던 S3 bucket이 연결되어 있는 것을 확인할 수 있습니다. 해당 Data source를 선택한 뒤, ‘Sync’ 버튼을 클릭해 버킷 내의 데이터를 Knowledge base로 연동해주겠습니다. 데이터의 크기에 따라 수 분에서 수 시간이 소요될 수 있습니다.
오른쪽의 ‘Test knowledge base’ 사이드바에서 생성한 Knowledge base를 테스트해볼 수 있습니다. ‘Select model’ 버튼을 클릭합니다.
아래와 같은 창이 나타나면, Anthropic의 Claude 3 Sonnet 모델을 선택하고, ‘Apply’ 버튼을 눌러 설정을 완료해줍니다.
이제 오른쪽 사이드바에서 Knowledge base를 테스트할 준비가 되었습니다.
Step 3. 콘솔에서 RAG를 테스트해보기
앞서 S3 소스 버킷에 올렸던 EC2 user guide PDF에서 17페이지에 있는 ‘EC2 보안 모범사례’에 대해 질의하기 위해 아래 질문을 입력해보겠습니다.
EC2 모범사례 중 '보안' 관점에서의 사례를 순서대로 알려줘
질문 결과, 오른쪽 그림과 같이 문서에 있는 내용을 순서대로 올바르게 답변을 하는 것을 확인할 수 있습니다.
위 그림에서 표시한 것처럼 ‘Show source details’ 하이퍼링크를 클릭하면 아래와 같이 문서의 내용 중 어떤 청크에서 해당 답이 검색 되었는지를 확인하실 수 있습니다. 내용을 확인해보면 위의 단계에서 LLM을 활용한 파싱 기능에서 설정했던 instruction 프롬프트와 같이, 메인 제목에는 #, 섹션에는 ##, 하위 섹션에는 ###을 사용해 후처리된 문서의 형식을 확인하실 수 있습니다.

멀티모달 성능을 테스트해보기
LLM을 활용한 파싱으로 RAG의 멀티모달 성능이 어떻게 개선되었는지 조금 더 알아볼까요?
조금 더 복잡한 PDF를 S3 버킷에 올리고 Knowledge base에 질문해봅시다. S3 소스 버킷에 아래의 ‘상록초등학교 설명회 연수자료’ PDF 문서를 업로드하고, 위 과정을 반복해 Knowledge base를 Sync 시켜줍니다. Bedrock Knowledge base는 소스 버킷 내의 여러 개의 문서를 참조할 수 있습니다.
– 업로드할 문서: school_edu_guide.pdf
해당 문서 9페이지에 나와있는 ‘출석인정결석 기준’에 대한 정보를 질문해보겠습니다. 아래와 같이 복잡한 표 안에, 학생 본인이 입양된 경우에는 출석인정결석 일수가 20일이라는 정보가 표시되어 있습니다. 그러므로 아래와 같이 질문해보겠습니다.
학생 본인이 입양된 경우, 출석인정결석을 며칠이나 인정받을 수 있나요?

아래는 LLM 파싱 기능을 활성화하지 않은 Knowledge base와, 해당 기능을 활성화한 Knowledge base에서 각각 검색한 결과입니다. 해당 기능을 활성화하지 않았던 Knowledge base에서는 “검색 결과에서 명확히 언급되지 않았습니다.”라는 답변이 나온 반면, 해당 기능을 활성화한 Knowledge base에서는 ‘20일’이라는 명확하고 올바른 정보를 찾아 답변하고 있습니다. 답변을 가져온 Source chunk를 확인해보면, 원본 문서에 있던 표 형태의 데이터가 LLM에 의해 Markdown 형태로 후처리되어 인덱싱되었고, 관련 내용 검색 시 이 내용이 검색된 것을 확인하실 수 있습니다.
해당 문서 1페이지에 나와있는 ‘상록초등학교 학교상’에 대한 정보를 질문해보겠습니다. 아래와 같이 이미지 안에, “참여와 즐거운 배움의 열기로 신나는 학교”라고 학교상이 제시되어 있고, 그 아래에 학생상, 교사상, 학부모상도 이미지로 표시되어 있습니다. 그러므로 아래와 같이 질문해보겠습니다.
상록초등학교의 학교상, 학생상, 교사상을 알려줘

같은 방식으로, 아래는 LLM 파싱 기능을 활성화하지 않은 Knowledge base와 해당 기능을 활성화한 Knowledge base에서 각각 검색한 결과입니다. 해당 기능을 활성화하지 않았던 Knowledge base에서는 “상록초등학교의 학생상, 교사상에 대한 정보를 찾을 수 없습니다.”라는 답변이 나온 반면, 해당 기능을 활성화한 Knowledge base에서는 올바른 정보를 찾아 답변하고 있습니다. 답변을 가져온 Source chunk를 확인해보면, LLM에 의해 이미지에 대한 설명이 작성되었고 이 내용이 검색된 것을 확인하실 수 있습니다.
현재까지의 아키텍처 구성
현재까지 구성한 아키텍처는 아래와 같습니다. 아래 보라색 화살표(1)와 같이, RAG에 활용하고자 하는 문서를 데이터 소스로 사용할 S3 버킷에 업로드하고 Knowledge base에 Sync하는 과정을 거치면 OpenSearch Serverless 벡터 스토어에 데이터가 검색 가능한 형태로 인덱싱됩니다. 이후 하늘색 화살표(2)와 같이, 콘솔에서 Bedrock Knowledge base에 질의하는 과정을 테스트해 보았습니다.

Step 4. EC2에 Streamlit 챗봇 애플리케이션 배포하기
마지막으로, 위에서 생성한 RAG를 챗봇 애플리케이션 형태로 사용할 수 있도록 EC2에 배포해봅시다. AWS CDK를 이용해 간단한 Streamlit 애플리케이션을 EC2에 배포할 것입니다. 위에서 생성한 Bedrock Knowledge base의 ID를 CDK 배포 시 파라미터로 입력하면, 해당 값이 Systems Manager Parameter Store에 저장되어 챗봇을 배포한 EC2 인스턴스에서 이 값에 접근해 RAG에 질의할 수 있도록 하는 간단한 애플리케이션입니다. 따라서 CDK로 스택을 배포하고 나면 아래와 같은 아키텍처가 완성됩니다.
전제 조건
만약 CDK 설정이 어려운 상황일 경우, Github 링크의 가이드를 통해 CDK 대신 수동으로 EC2 애플리케이션을 배포하는 방법을 따라하실 수 있습니다. 아래의 환경이 세팅되어 있지 않다면, 위 링크의 가이드를 통해 아래 설정을 별도로 하지 않고도 애플리케이션을 구성할 수 있으니 편하신 방법으로 구성해주세요.
CDK 스택을 배포하려면 아래의 과정이 로컬 환경에 준비되어 있어야 합니다.
- Linux 기반 OS (*이 글이 게시되는 현재 Windows 배포 스크립트가 없습니다).
- NodeJS(버전 18 이상) 및 NPM이 설치되어 있어야 합니다. 설치되어 있는지 확인하려면 다음 명령을 실행하세요.
$ npm -v && node -v7.24.2
v18.16.1- AWS Cloud Development Kit(AWS CDK)가 설치되어 있어야 합니다. 설치되어 있는지 확인하려면 다음 명령을 실행하세요. 설치되어 있지 않다면,
npm install -g aws-cdk로 설치할 수 있으며, 자세한 내용은 자습서를 참고해 설치를 완료해주세요.
$ cdk --version
2.124.0 (build 4b6724c)- 백엔드 리소스를 실행할 AWS 계정과 AWS Command Line Interface(AWS CLI)(v2)가 설치 및 구성되어 있어야 합니다. AWS CLI가 컴퓨터에 설치 및 구성되었는지 확인하려면 다음 명령을 실행하세요. 기본 사용자로 설정되어 있어야 합니다. 이 사용자가 백엔드 리소스를 배포할 수 있는 권한이 있는지 확인합니다.
$ aws sts get-caller-identity
{
"UserId": "AIDxxxxxxxxxxxxxxxT34",
"Account": "12345678XXXX",
"Arn": "arn:aws:iam::12345678XXXX:user/admin"
}AWS CDK 스택 배포 방법
아래 명령어를 입력해 준비된 CDK 코드를 Github에서 clone 받고, 필요한 패키지를 설치한 뒤, CDK 스택을 배포하기 전에 부트스트랩을 실행합니다. cdk bootstrap 실행 후 아래 스크린샷과 같이 Environment bootstrapped. 라는 메시지가 출력되면 배포를 위한 준비가 완료된 것입니다.
$ $ git clone https://github.com/aws-samples/kr-tech-blog-sample-code.git
$ cd kr-tech-blog-sample-code/cdk_bedrock_rag_chatbot
$ npm install
$ cdk bootstrap aws://<Account ID>/us-west-2
이후 Bedrock 콘솔에서 생성한 Knowledge base의 ID를 복사한 뒤,
아래 명령어의 ENTER_YOUR_KNOWLEDGE_BASE_ID 자리에 붙여넣어 실행합니다. 이후 스크린샷과 같이 ‘Do you wish to deploy these changes (y/n)?’가 나오면 y를 입력해 스택을 배포합니다.
$ cdk deploy --parameters knowledgeBaseId=ENTER_YOUR_KNOWLEDGE_BASE_ID약 5분 뒤, 모든 스택이 배포되고나면 아래와 같이 배포된 EC2의 public ip가 터미널에 출력됩니다. 해당 IP를 클릭해 Streamlit 애플리케이션에 접속할 수 있습니다. 위에서 cdk deploy 명령어를 실행할 때 Knowledge base ID를 함께 넣어주었기 때문에 이 챗봇 애플리케이션은 생성했던 Knowledge base와 연동됩니다.
만약 배포가 안 됐다면 아래 내용을 확인해보시길 바랍니다.
- EC2에 애플리케이션을 완전히 배포하는 데에 약 5분 정도가 추가로 소요될 수 있습니다. 출력된 IP를 클릭했을 때 오류가 발생한다면 약 5분 뒤 다시 접속해보세요.
- 접속이 안 된다면 https:// 가 아니라 http:// 로 올바르게 접속했는지 확인해보세요.

출력 결과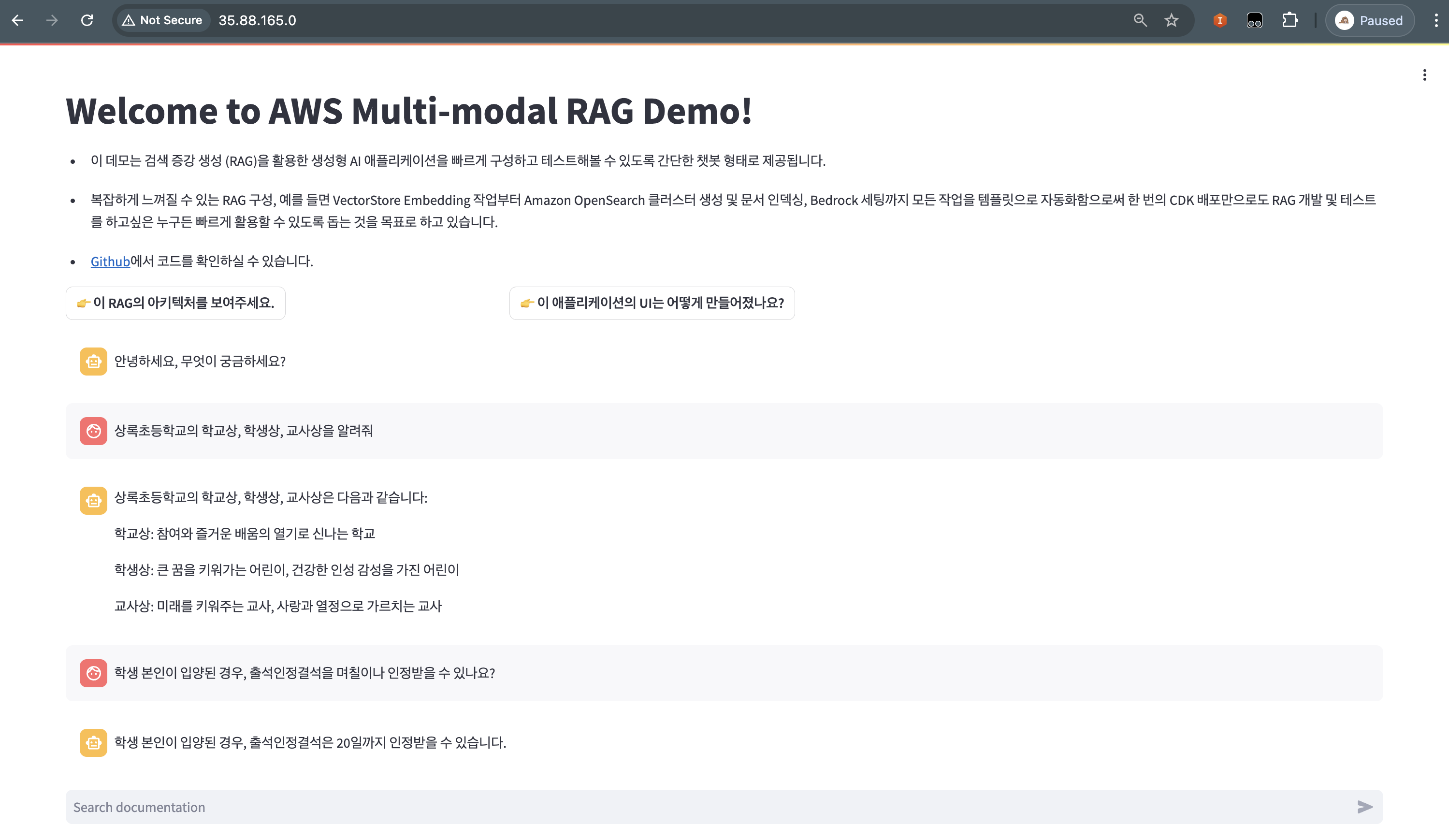
마무리
이와 같이, Amazon Bedrock의 Knowledge base를 사용하면 가장 간편하게 RAG를 구성하실 수 있습니다. 본 게시글에서는 Bedrock을 이용해 RAG를 구성하는 방법을 단계별로 살펴보았고, 마지막 단계에서 CDK를 이용해 곧바로 사용 가능한 챗봇 애플리케이션을 EC2에 배포함으로써 AWS에서 RAG 챗봇을 구축하는 과정을 A부터 Z까지 함께 알아보았습니다. 여기에 더해, 최근 Bedrock에 새로 추가된 Chunking and parsing configurations 내의 고급 파싱 기능 (Use foundation model for parsing) 옵션을 활성화함으로써 RAG의 멀티모달 성능을 개선하는 방법을 함께 알아보고, 이 설정을 추가한 RAG와 그렇지 않은 일반 RAG의 성능을 비교하여 이 기능이 얼마나 손쉬우면서도 강력한지 알아보았습니다. 이전에 멀티모달 성능을 갖춘 RAG를 구현하기 위해서는 복잡한 데이터 전처리 작업을 거쳐야 했던 것을 고려하면, 해당 옵션은 처음 RAG 구축을 시작하는 분들에게 가장 손쉬운 솔루션이 될 수 있습니다.
Bedrock Knowledge base를 프로덕션 애플리케이션에 도입하길 고려하고 계시다면, 아래 사용량에 대한 할당량 (Quota) 공식 문서를 참고해주세요. 예를 들어, LLM을 활용한 파싱 기능을 활성화한 경우 현재 기준 (2024년 10월) PDF 파일 형식만 지원되며, 데이터 소스 당 파일 개수는 최대 100개까지로 제한됩니다. 그러므로 해당 옵션을 적용하려면 먼저 문서를 PDF 파일 형식에 맞춰 변환해야 합니다. 해당 기능을 사용하지 않을 경우에는 업로드할 수 있는 파일 수에 제한은 없습니다.
- Bedrock Service quota 알아보기: https://docs.aws.amazon.com/ko_kr/general/latest/gr/bedrock.html#limits_bedrock
- Bedrock Knowledge base 데이터에 지원되는 문서 형식 및 제한 알아보기: https://docs.aws.amazon.com/ko_kr/bedrock/latest/userguide/knowledge-base-ds.html#kb-ds-supported-doc-formats-limits
- Bedrock quota 증가 요청하기: https://docs.aws.amazon.com/ko_kr/bedrock/latest/userguide/quotas.html#quotas-increase
더 나아가, Multi modal RAG 구축과 관련해 좀 더 세밀한 옵션을 직접 구성하고 RAG의 성능을 높이고자 하는 분이라면 아래의 Advanced RAG 워크샵을 참고해보세요. 프로덕션 RAG를 구축하는 데 도움이 되는 다양한 기술이 설명되어 있습니다. AWS에서 RAG를 구축하는 데 본 포스팅이 도움이 되길 바랍니다.
- Amazon Bedrock Q&A multi-modal chatbot with Advanced RAG 워크샵: https://github.com/aws-samples/multi-modal-chatbot-with-advanced-rag