- AWS Solutions Library›
- Guidance for Automated Geospatial Insights Engine on AWS
Guidance for Automated Geospatial Insights Engine on AWS
Overview
This Guidance shows how build an automated geospatial insights engine on AWS to improve supply and demand forecasting and risk management. Many industries depend upon intelligence and insights gained from processed geospatial and Earth-observation data from sources like satellite and aerial imagery and remote sensing. This Guidance couples this data with mechanistic and AI-powered models, so you can enhance forecasting, automate risk mitigation, and meet regulations.
How it works
This architecture diagram shows an overview of the automated geospatial analysis engine, specifically the key modules and their interactions.
Overview
This architecture diagram shows an overview of the automated geospatial analysis engine, specifically the key modules and their interactions.
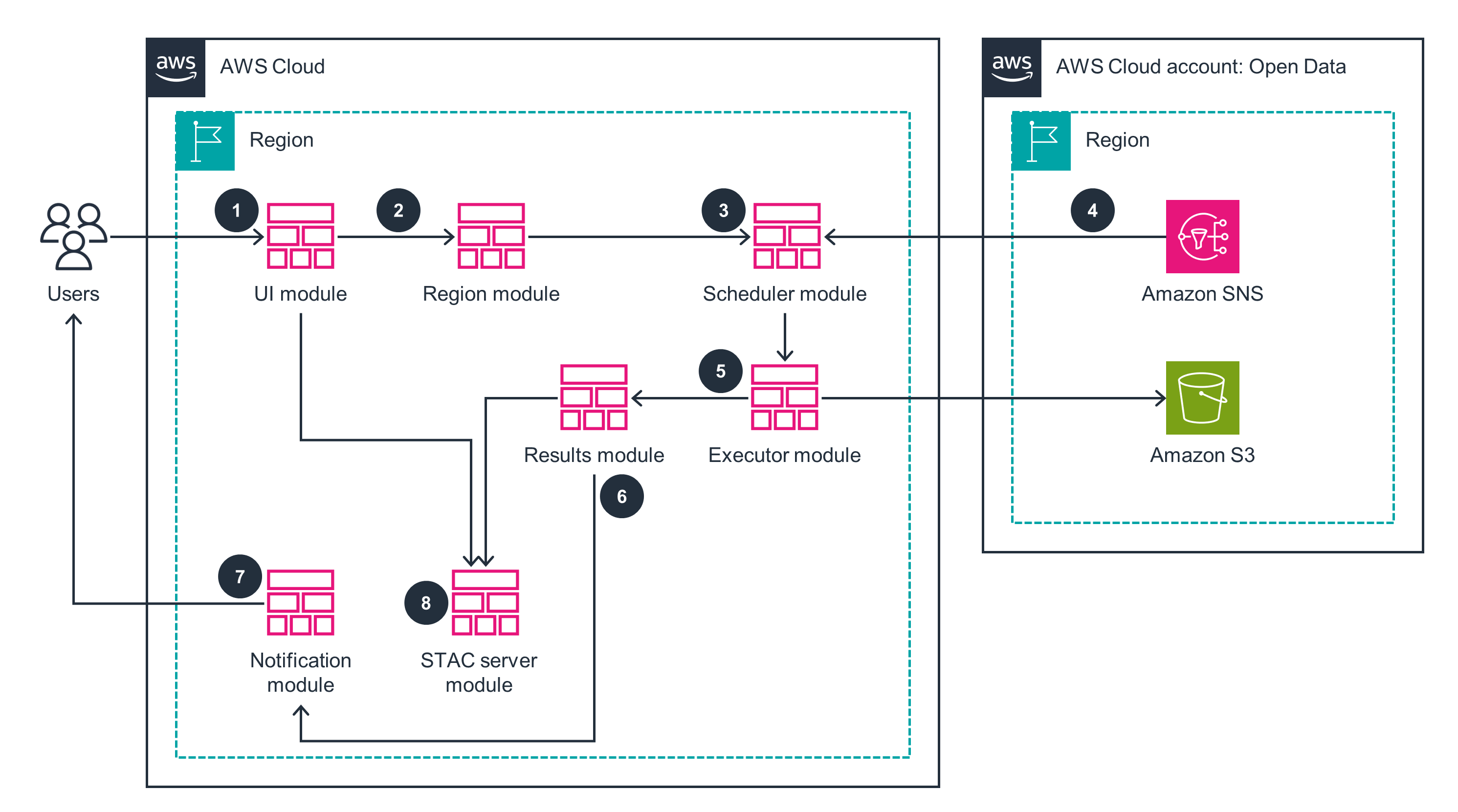
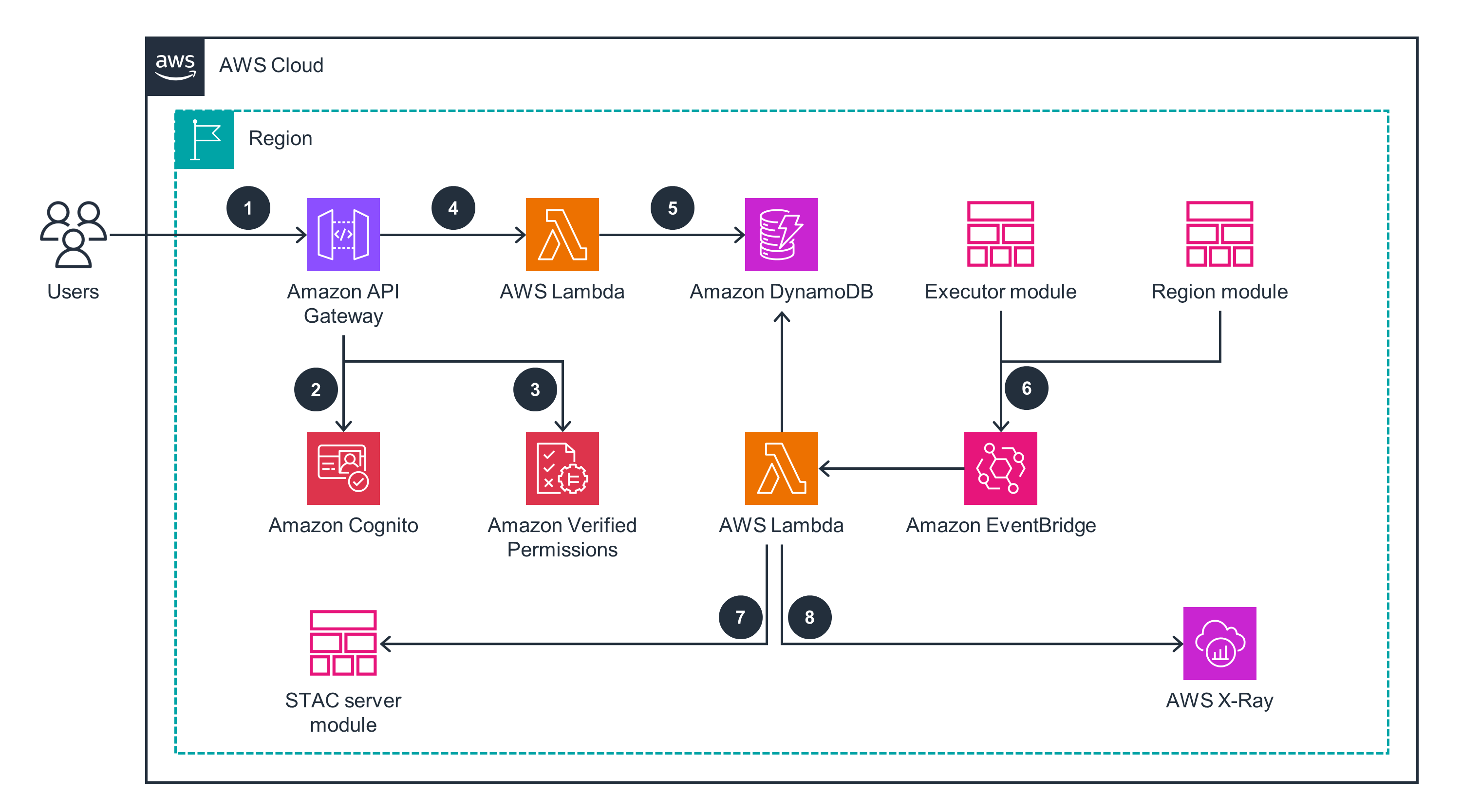
UI Module
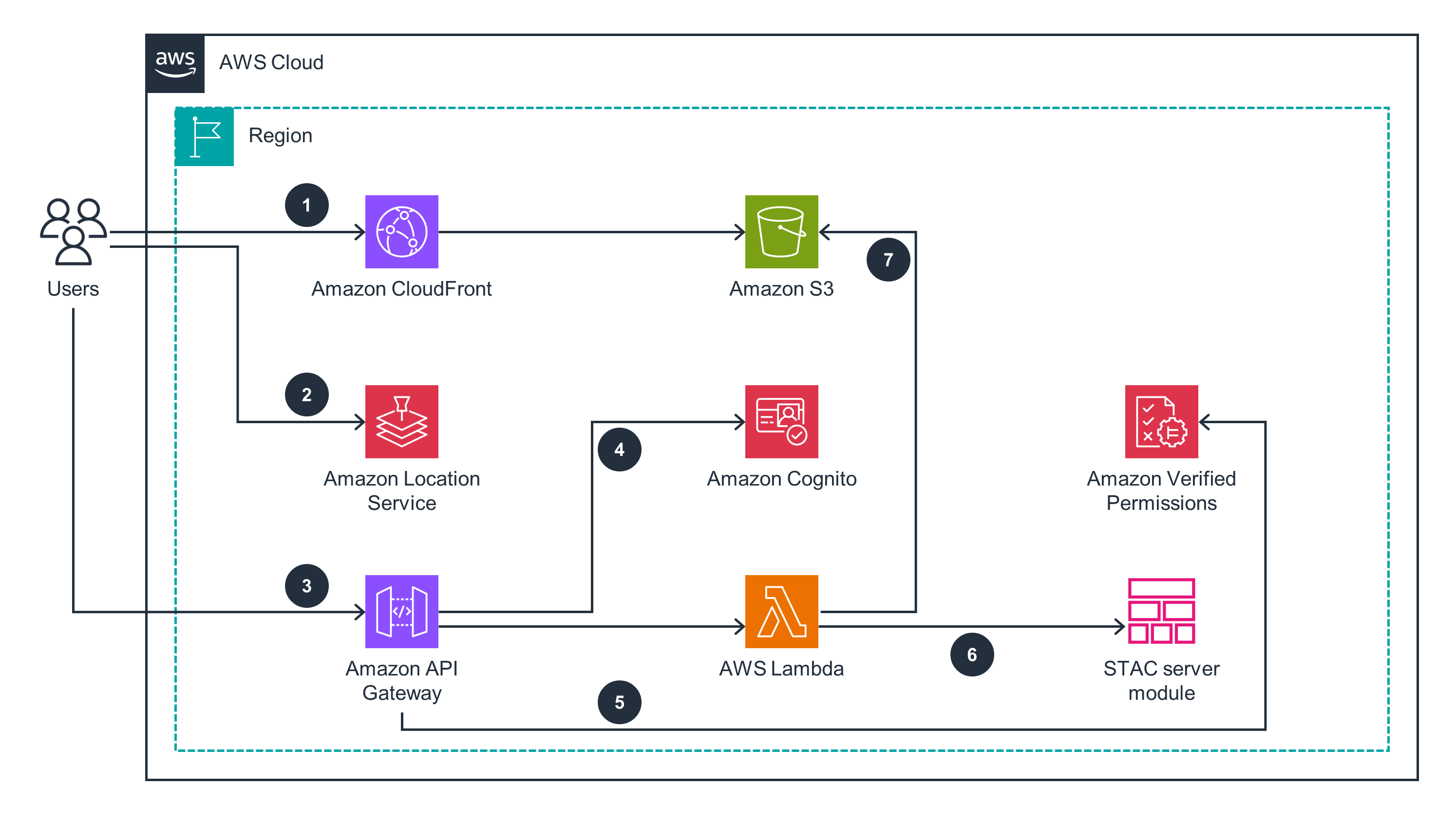
This architecture diagram shows how to set up the user interface (UI), manages authentication and authorization, and query analysis results.
Region Module
This architecture diagram demonstrates the hierarchical structure of groups, regions, polygons, and states.
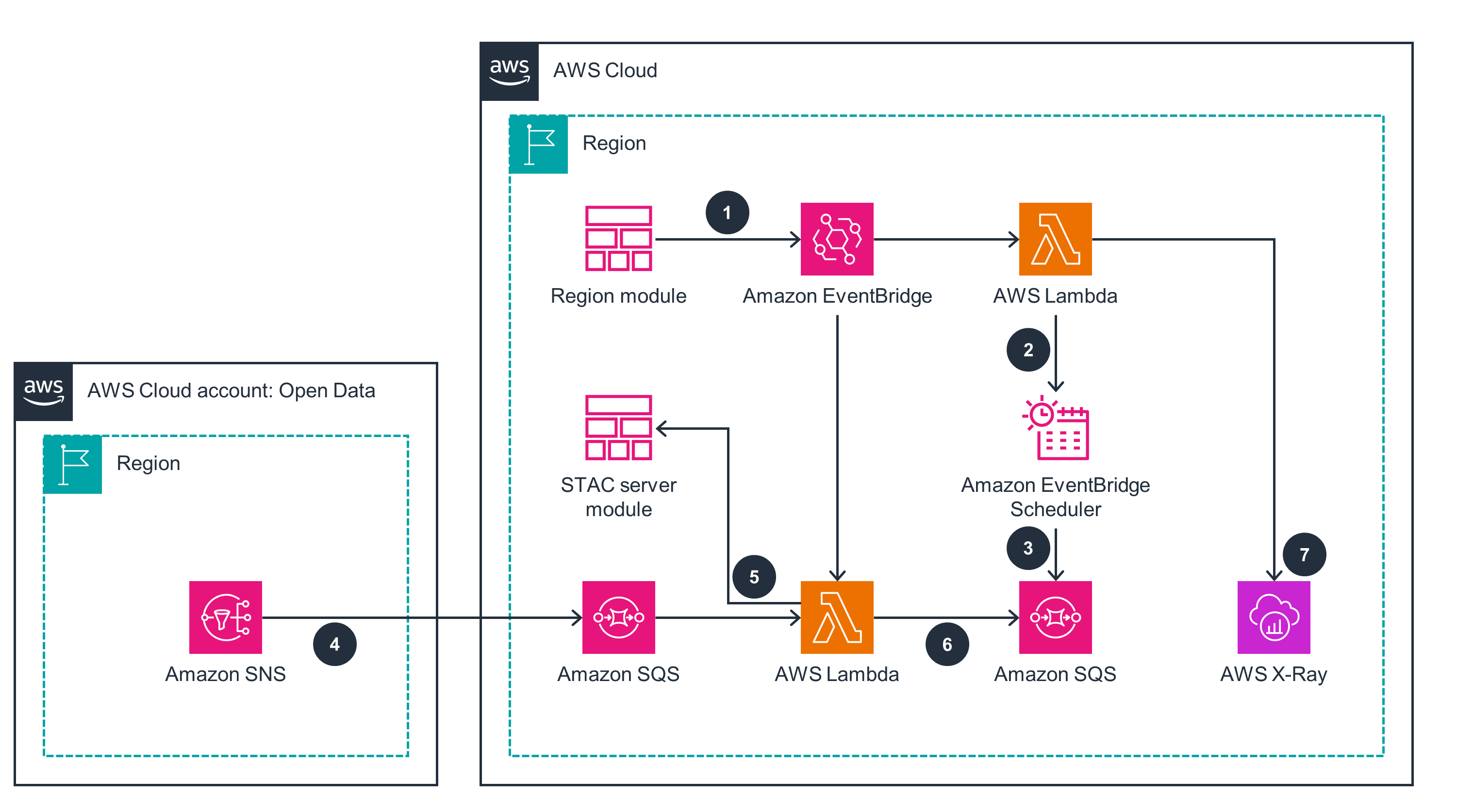
Scheduler Module
This architecture diagram shows how to schedule the engine's processing tasks, based on each region's processing configuration.
How it works - continued
Executor Module
This architecture diagram demonstrates the execution of the region analysis invoked by the schedule module.
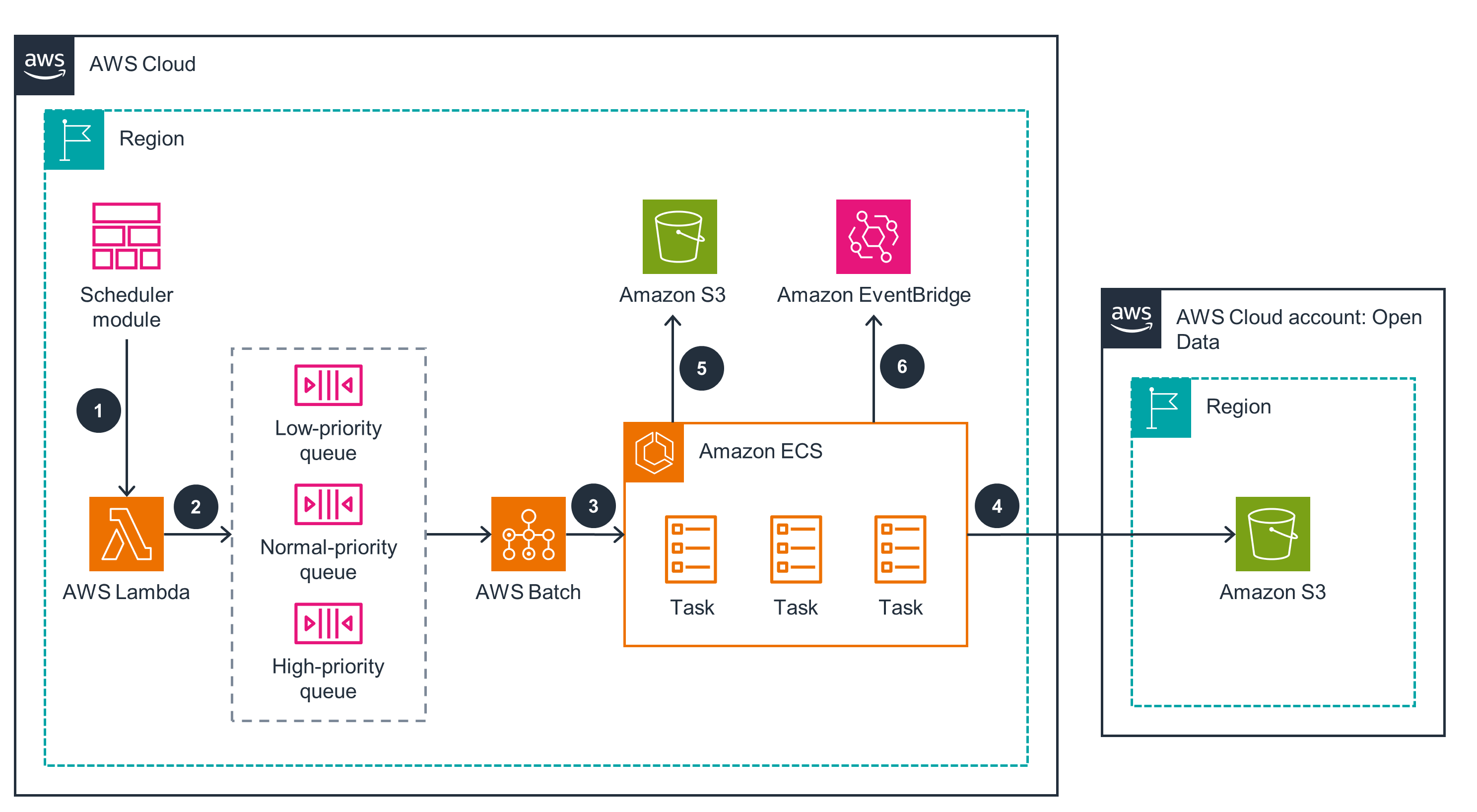
Results Module
This architecture diagram shows how to transform data into STAC items, publish them to the STAC server, and map execution results to corresponding regions.
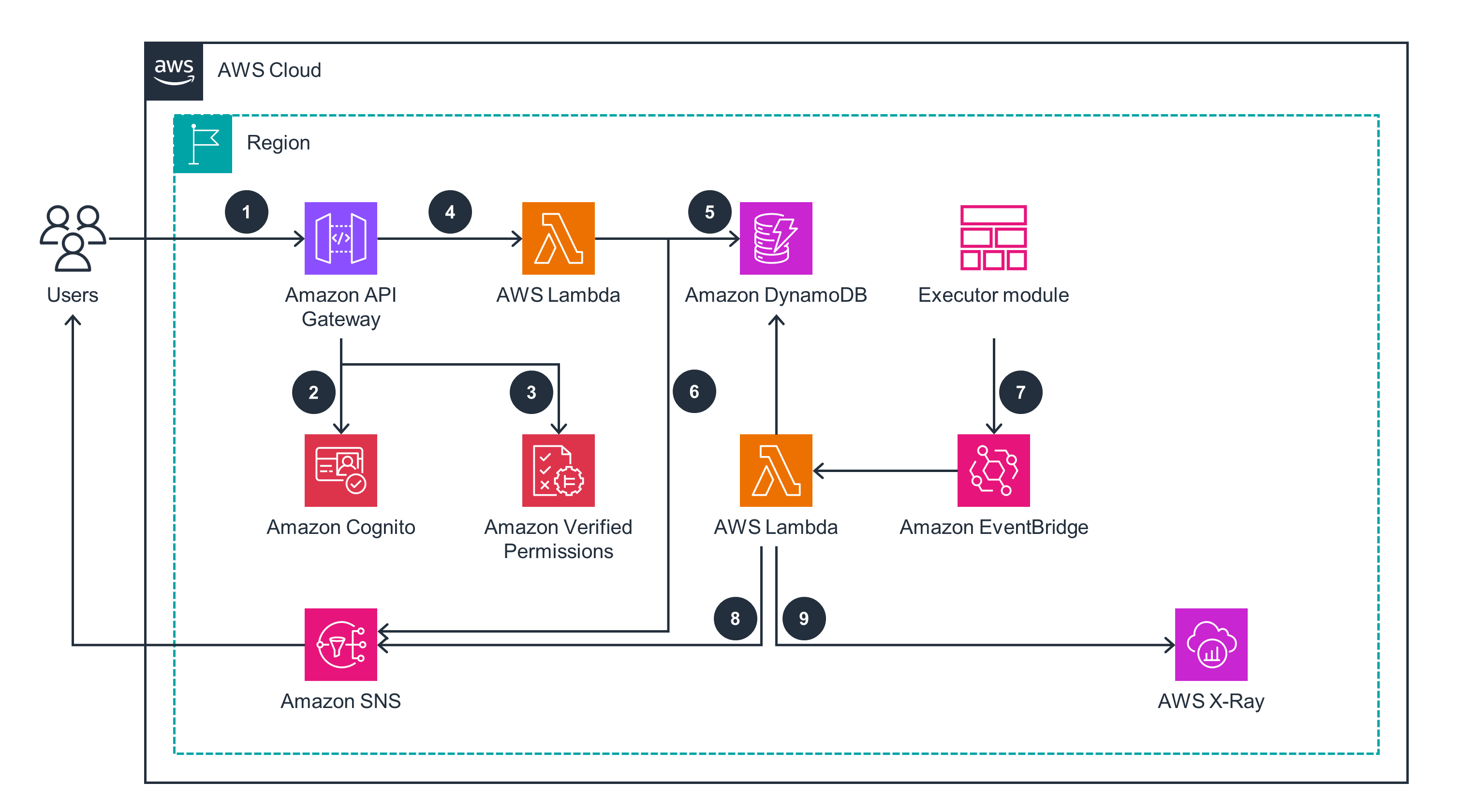
Notification Module
This module shows how to manage subscriptions to notifications generated by other modules.
Deploy with confidence
Ready to deploy? Review the sample code on GitHub for detailed deployment instructions to deploy as-is or customize to fit your needs.
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
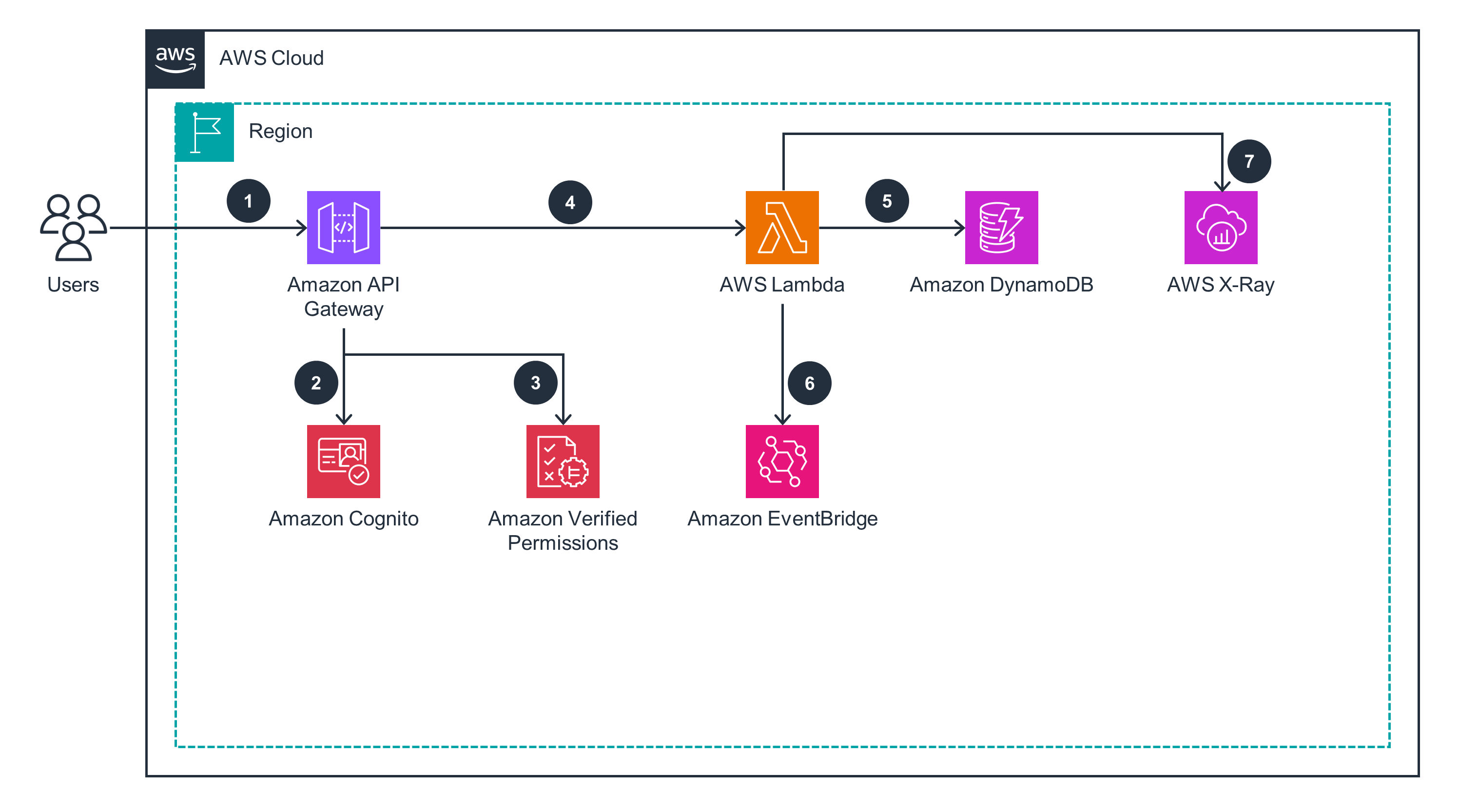
X-Ray provides complete tracing and monitoring capabilities to help you identify performance bottlenecks and troubleshoot issues. It enables you to visualize and analyze the components of this Guidance, such as API calls, Lambda functions, and AWS Step Functions workflows. Finally, AWS CloudFormation provisions and manages the required resources, enabling automated deployments and changes.
Amazon Cognito provides secure user authentication mechanisms so that only authorized users can access your applications and resources. AWS Identity and Access Management (IAM) policies and roles let you control access to resources according to the principle of least privilege. Additionally, Verified Permissions provides a centralized and efficient system for managing access to your custom applications. Through a policy-based approach that uses the Cedar policy language for defining fine-grained permissions, it promotes consistency and maintainability in the authorization process. It also separates the authorization process from the application code so that you can easily update and manage permissions.
Read the Security whitepaperAWS Batch automatically scales the number of compute resources based on the number of jobs in the queue. As a result, this Guidance provisions the right amount of resources for satellite image processing, reducing the risk of job failures due to resource constraints. Amazon SQS and EventBridge maintain durability and persistence by decoupling components through asynchronous messaging and by storing messages redundantly across multiple Availability Zones. This makes applications more resilient: if an individual component fails, messages are temporarily stored in the queue and processed when the component recovers.
DynamoDB lets you define a partition key (and an optional sort key) for your table to enhance performance efficiency. By using defined keys to distribute your data across servers and partitions in addition to using appropriate indexes, you can optimize data access patterns. Additionally, Amazon S3 offers seamless scalability, enabling your applications to handle high request rates effortlessly. For example, each partitioned Amazon S3 prefix can sustain at least 3,500 requests per second for PUT, COPY, POST, and DELETE operations. Each prefix can also sustain up to 5,500 requests per second for GET and HEAD operations. Because there are no restrictions on the number of prefixes you can create within a bucket, you can partition your data effectively to achieve optimal performance and scalability. And by encoding the region, polygon, or results ID in the file prefix when storing satellite analysis images, you can enable parallel processing and listing.
The serverless and event-driven nature of Lambda , EventBridge , Amazon SQS , and AWS Batch means that they automatically scale based on demand and don’t overprovision capacity. This helps you optimize costs, because you only pay for the resources you use. Additionally, EventBridge and Amazon SQS remove the need for you to set up polling-based architectures, helping you further reduce costs.
This Guidance uses serverless services for compute and storage—including Lambda , AWS Batch , and DynamoDB —so they automatically scale to zero when not in use. This removes the need for always-on infrastructure and reduces the overall environmental impact of your workloads. Additionally, Lambda uses AWS Graviton2 processors, which are designed to be more energy-efficient than traditional x86-based processors. They consume less power while delivering comparable performance, reducing your carbon emissions.
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages