亚马逊AWS官方博客
Amazon Fraud Detector 现已全面推出
公告的内容
Amazon Fraud Detector 现已全面推出! ?
如果您错过了 2019 re:Invent 周期间的公告,Amazon Fraud Detector 最初是在 2019 年 12 月 3 日以预览模式发布的。但今天,它已全面推出,供客户查看。
什么是 Amazon Fraud Detector?
Amazon Fraud Detector 是一项完全托管的服务,可用于轻松识别潜在的网络欺诈行为,例如在线支付欺诈和创建虚假账户。
你知道吗,每年全世界因网络欺诈造成的经济损失达数百亿美元?
开展网上业务的公司必须时刻警惕欺诈行为,比如伪造账户和用被盗信用卡进行支付。 他们识别欺诈者的一种方法是使用欺诈检测应用程序,其中一些应用程序使用了 Machine Learning (ML)。
进入 Amazon Fraud Detector! 这项服务使用您的数据、ML 并利用 Amazon 20 多年的欺诈检测专业知识自动识别潜在的网络欺诈行为,使您可以更快的抓获更多欺诈行为。您只需单击几下就可以创建一个欺诈检测模型,并且不需要任何 ML 经验,因为 Fraud Detector 可以为您处理所有繁重的 ML 工作。
工作原理…
“但它的工作原理是什么?”或许你会问。??♀️
非常高兴你提出这样的问题! 我们用 5 个主要步骤对它进行总结。???
- 步骤 1:定义您要评估是否具有欺诈性的事件。
- 步骤 2:上传您的历史事件数据集到 Amazon S3 中并选择一种欺诈检测模型类型。
- 步骤 3:Amazon Fraud Detector 将您的历史数据用作输入来构建自定义模型。该服务会自动检查和丰富数据,执行功能工程、选择算法、训练和调优您的模型并托管模型。
- 步骤 4:创建规则以基于模型预测接受、审查或收集更多信息。
- 步骤 5:从您的在线应用程序调用 Amazon Fraud Detector API,以接收实时欺诈预测并基于配置的检测规则采取措施。 (示例:电子商务应用程序可以发送电子邮件和 IP 地址,并从您的规则(例如审查)中接收欺诈评分以及输出)
我们来看一下演示…
我们来进行一下演示,以更好地了解它们是如何结合在一起的。在今天的博客文章中,我们将带您逐步了解两个主要组件:构建 Amazon Fraud Detector 模型和生成实时欺诈预测。
第 1 部分:构建 Amazon Fraud Detector 模型
我们首先将虚构生成的训练数据上传到 S3 存储桶中。事实上,用户指南中有示例数据集,我们可以使用。当我们下载该 CSV 文件后,我们需要将此训练数据放入 S3 存储桶中。


出于上下文考虑,我们也来打开这个 CSV 文件,看看里面有什么…

??注:使用 Amazon Fraud Detector,您最少能够选择 2 个变量来训练模型,而不仅仅是电子邮件和 IP 地址。(事实上,该模型最多支持 100 个输入!)
我们继续定义(创建)事件。事件本质上是特定事件的一组属性。我们对想要进行欺诈评估的事件的结构进行了定义。(Amazon Fraud Detector 评估“事件”是否存在欺诈。)
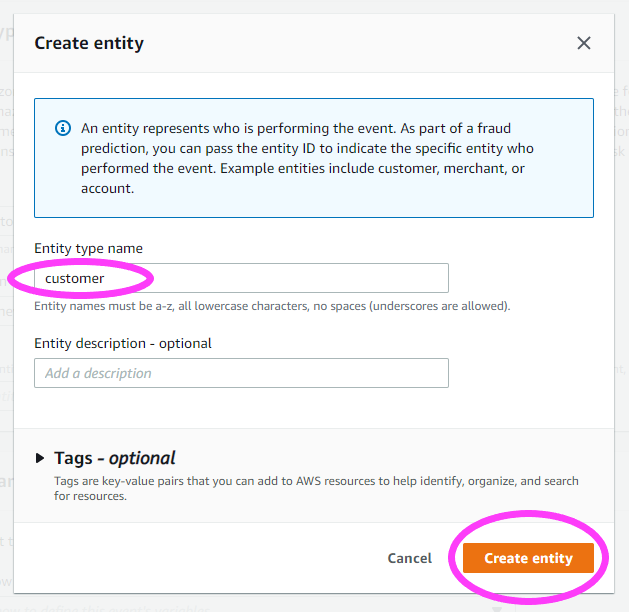
我们来创建一个新实体。此实体代表触发事件的人或物。

我们继续了解 Event Variables(事件变量)。我们将从训练数据集中选择变量。这样一来,我们可以使用之前提到的 CSV 文件并拉入标题中。

对于 IAM role(IAM 角色)部分,我们创建一个新角色。我将使用与我刚创建的存储桶相同的名称“fraud-detector-training-data”。

现在,我们可以上传之前提到的 CSV 文件,以拉入标题中。

由于我们将定义模型,我们必须至少定义两个标签。
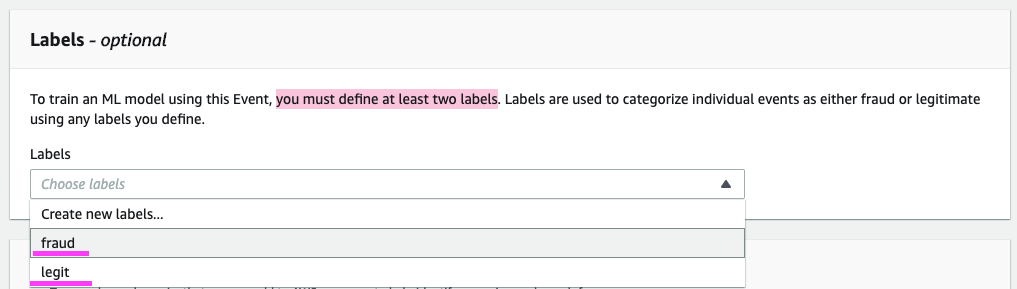
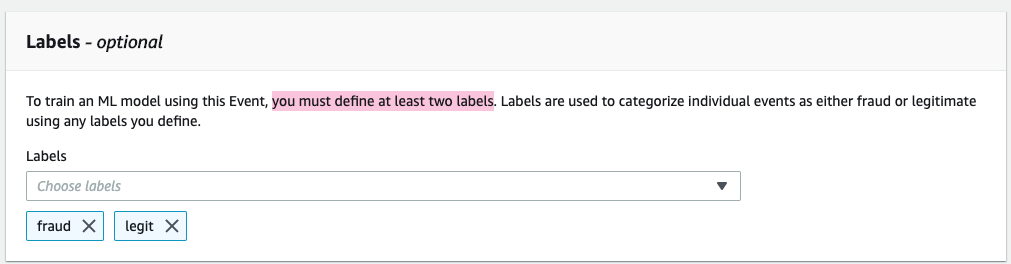
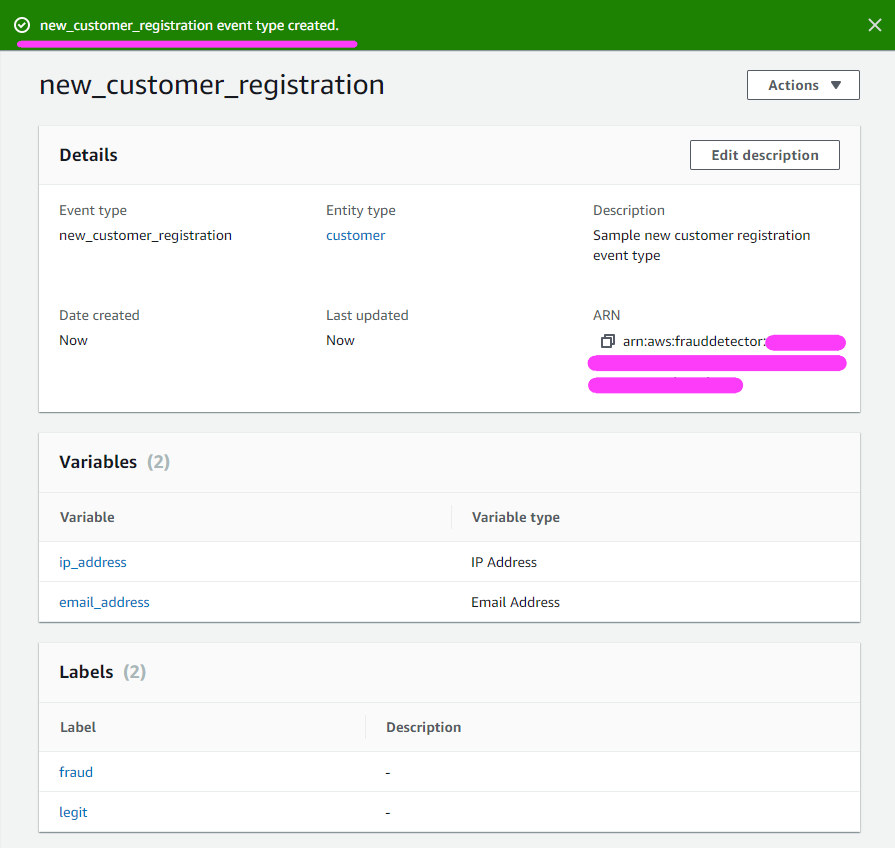
最后,我们来创建事件!

如果一切顺利,我们将看到一个绿色的条,提醒我们事件已成功创建!
现在,是时候创建模型了。


我们来花点时间定义模型详细信息。我们确保选择以前创建的事件类型。

我们继续配置训练并确保选择 Fraud(欺诈)和 Legitimate(合法)标签下的标签。(这使我们可以将分类分开,以便模型可以学会区分这两个表。)

模型需要 30-40 分钟,最多需要数小时,具体取决于数据集大小。此示例数据集大约需要 40 分钟来训练模型。
在本篇博客文章中,我们假设已跳过 40 分钟训练已完成模型的时间。??
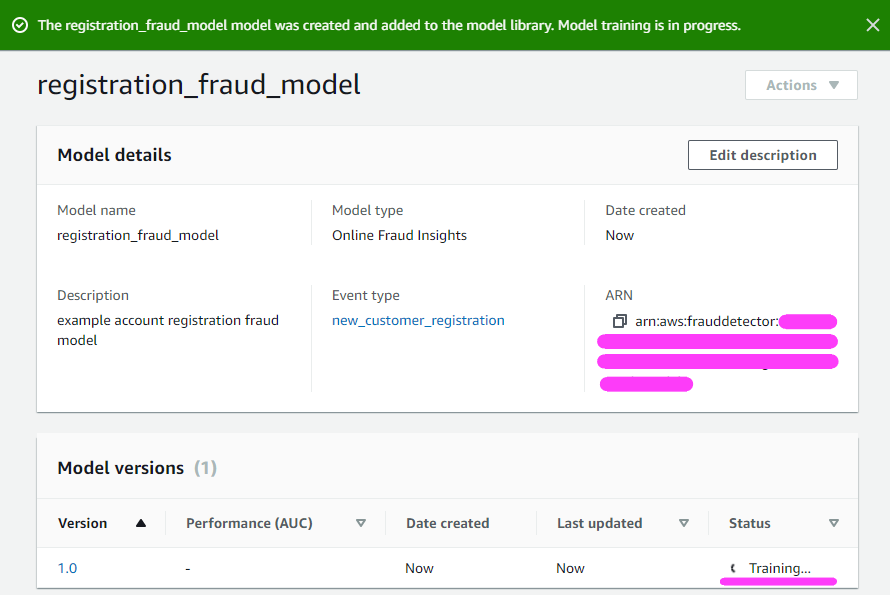
您还可以查看您的模型性能指标!

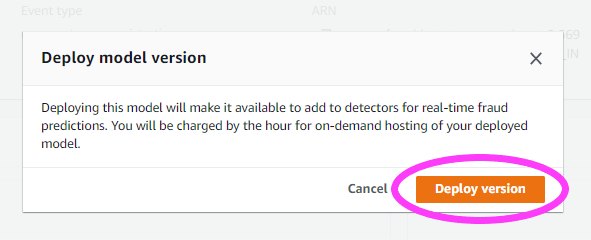
现在,我们可以继续部署模型。

弹出的模型要求我们确认这是我们想要部署的版本。
第 2 部分:生成实时欺诈预测
是时候生成实时欺诈预测了! 准备好了吗?
此时,您已经拥有了一个满意的已部署模型,并且想要将它用于获取预测。
我们必须构建检测器,检测器是您的模型和规则的容器,是您想要用于评估事件的检测逻辑。
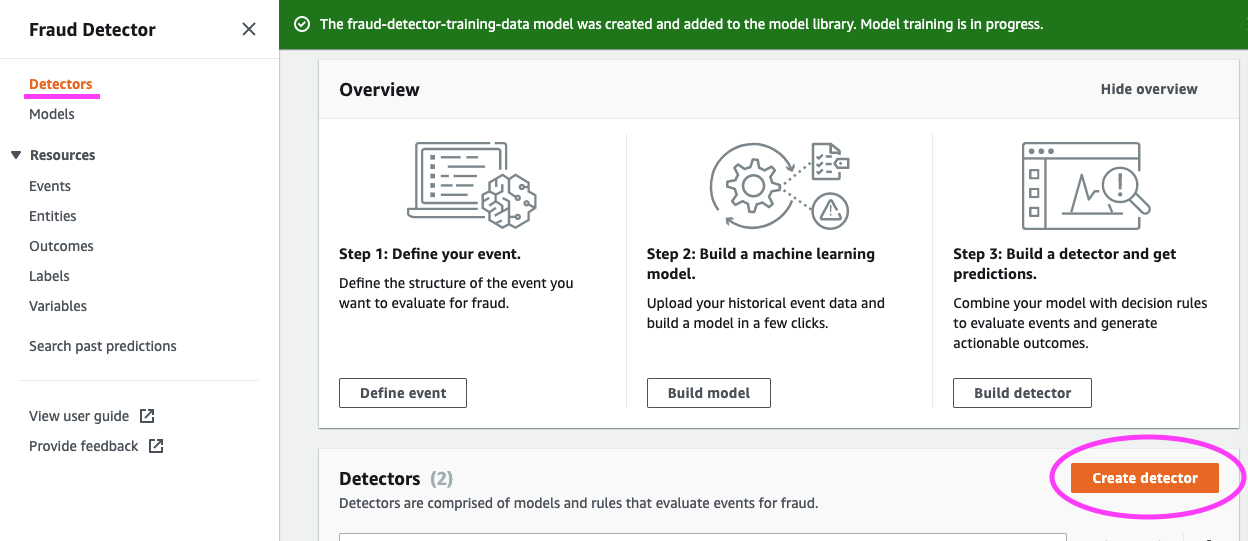
我们继续来定义检测器详细信息。
我们还要确保选择以前创建的事件。
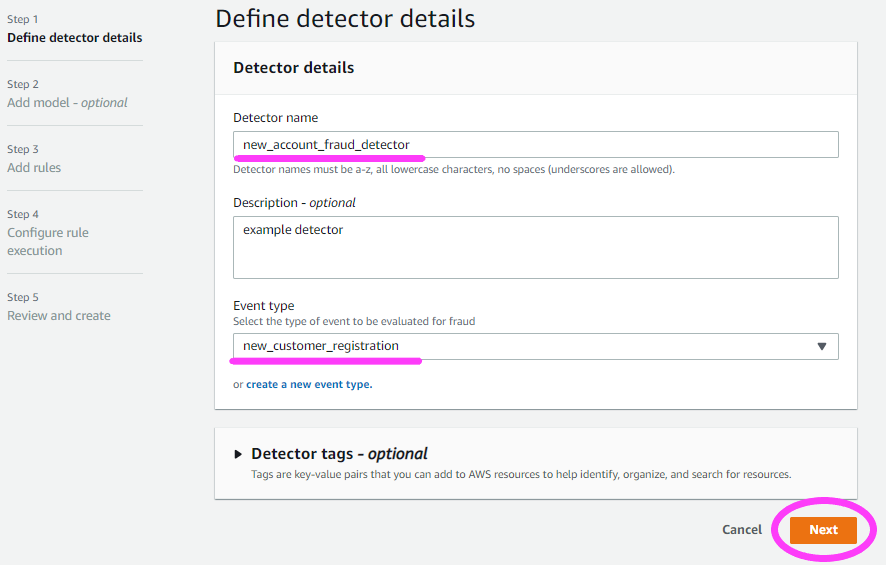
现在,我们选择模型。
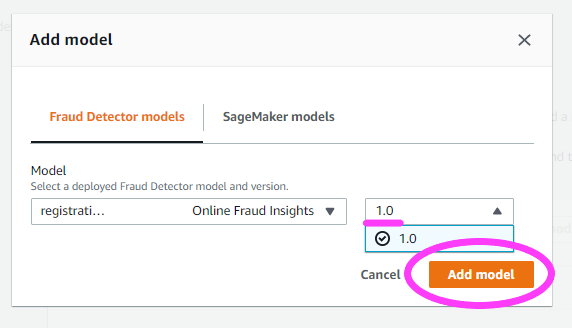
我们继续来制定一些阈值规则。
这些规则可说明模型的输出。它们还决定了探测器的输出。
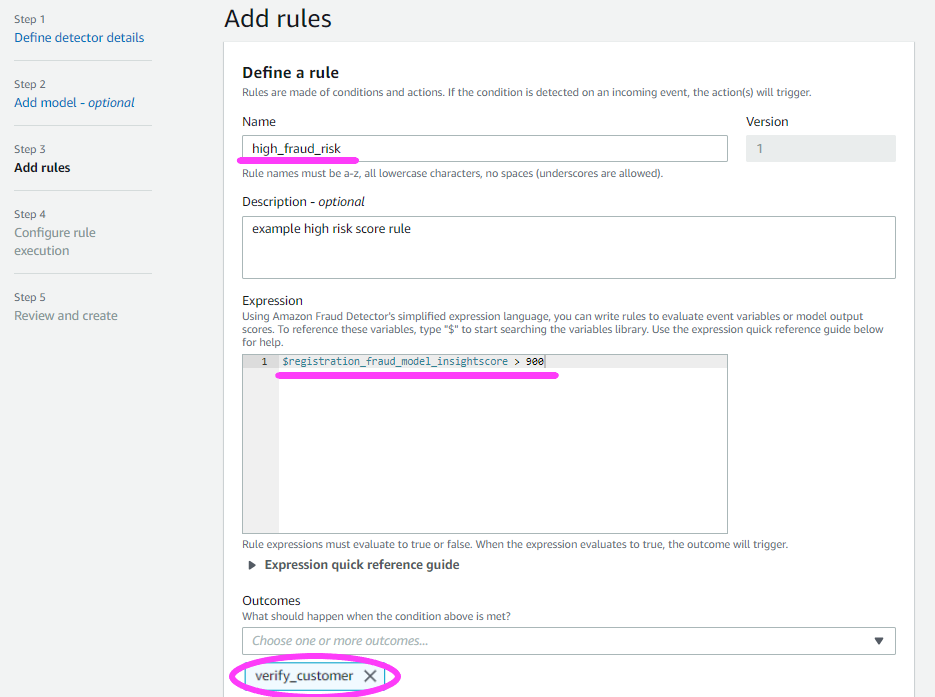
我们再来指定两个规则。
除了 high_fraud_risk 标签之外,我们还想添加 low_fraud_risk 和 medium_fraud_risk 标签。

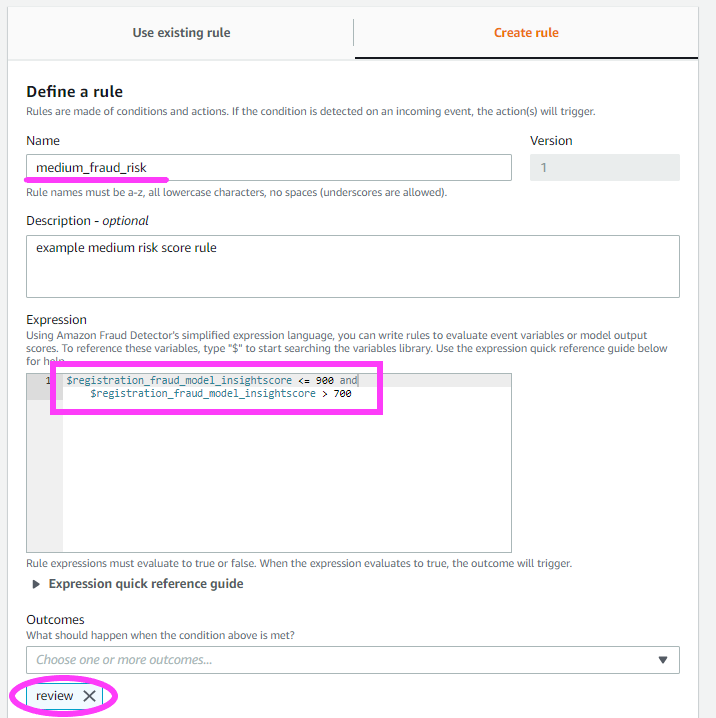
请记住,这些规则阈值只是示例。当您为自己的检测器创建规则时,您应该基于您的模型、数据和业务使用适当的值。
现在,在本博文的示例中,这些特定阈值从来不会同时匹配。

这意味着,任一个规则执行模式都适合在我们当前的示例中使用。

哇! 我们已经创建好自己的检测器。

现在,我们来点击 Rules(规则)选项卡。
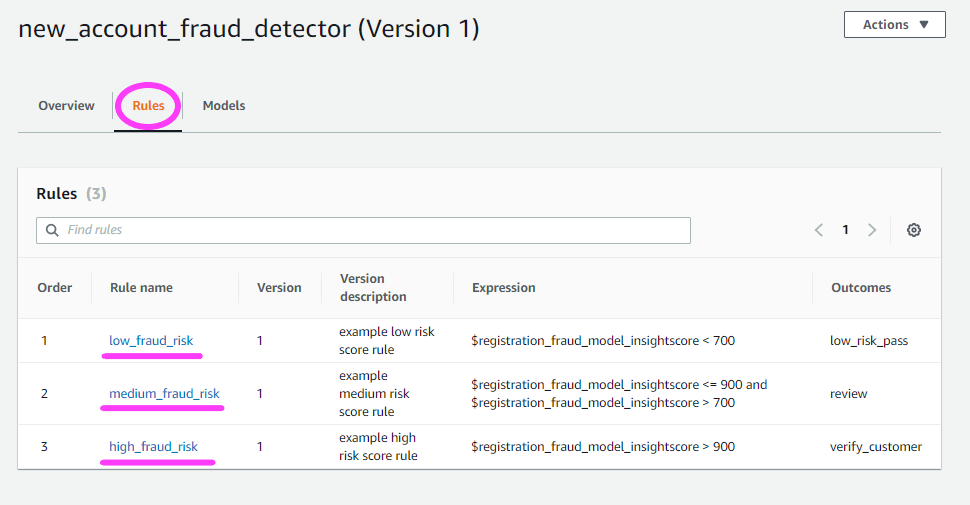
我们还可以在 Models(模型)选项卡下查看我们有哪些模型。

如果我们返回 Overview(概述)选项卡,我们甚至可以运行快速测试! 我们可以运行测试,以从检测器的输出中采样。
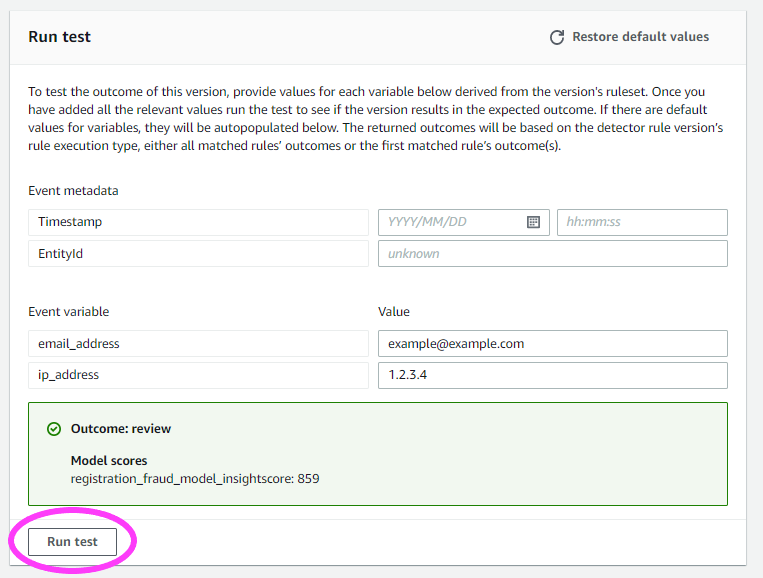
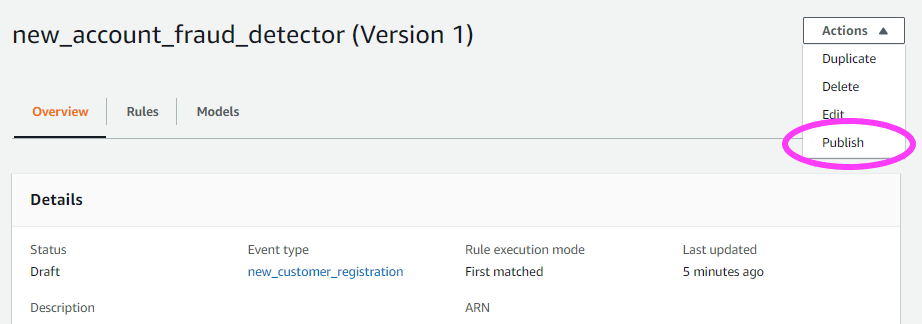
当我们准备就绪后,我们可以发布此版本的检测器使其成为活动版本。每个检测器一次都可以有一个活动版本。
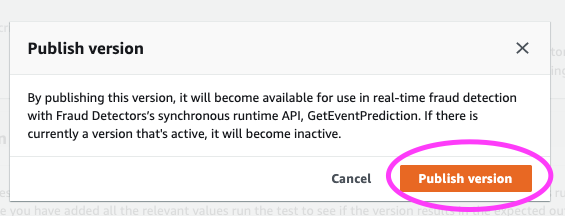
弹出模型要求我们确认我们已准备好发布此版本。
下一步是运行实时预测! 我们来用 Amazon SageMaker 笔记本展示一次性示例预测,看看它会是什么样子。
我们移动到 Amazon SageMaker 控制台,并转到 Notebook(笔记本)实例。
在此情况下,您可以看到,我已经有一个 Jupyter 笔记本,已准备好运行。
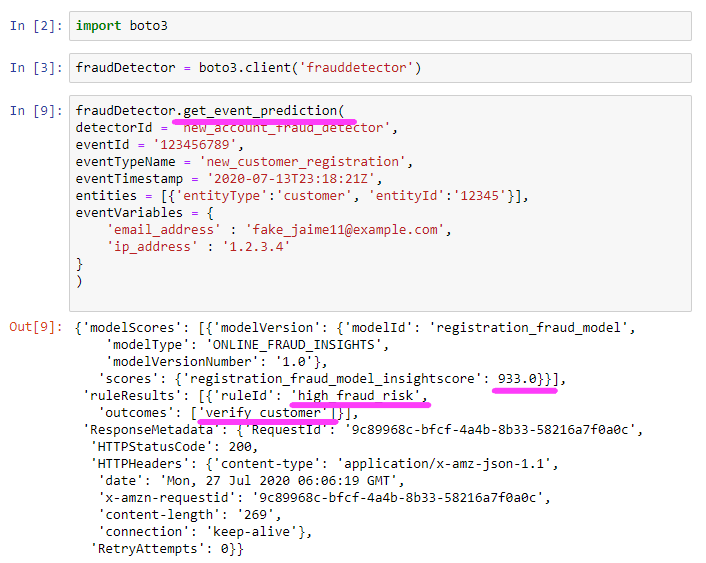
我们将要运行 get_event_prediction 数据块。这是我们的主运行时 API,客户可以使用脚本来调用它,以运行一批示例预测。或者,客户还可以将此 API 集成到他们的应用程序中以生成实时预测,并根据风险动态调整用户体验。
运行此数据块之后,我们收到下面几个模型评分结果。
我们在此检测器中有 1 个模型,它返回的评分为 933。根据我们创建的规则,这意味着我们认为此交易返回的是 high_fraud_risk。
我们再回到 Amazon Fraud Detector 控制台并查看检测器中的规则。
从检测器规则中,我们可以看到,如果风险评分超过 900,则结果应为 verify_customer。

循环到此完成!
现在,我们确认,您可以实时调用此检测器并获得自己的欺诈预测。
? 最后…
Amazon Fraud Detector 现已向客户全面推出,可以与很多 AWS 服务集成,例如 Amazon CloudWatch、AWS CloudTrail、AWS PrivateLink 等。
要了解 Amazon Fraud Detector 的更多信息,请访问网站和开发人员指南。
感谢阅读!
~Alejandra ??♀️? y Canela ?