亚马逊AWS官方博客
云中的 Oracle 到 PostgreSQL 迁移:如何设置 PostgreSQL 环境以协助完成迁移
AWS 云中的 Oracle 到 PostgreSQL 迁移可能是一个复杂度极高的多阶段流程 – 从评估阶段直到移交阶段,涉及到不同的技术和技能。为了更好地理解这其中的复杂性,请参阅 AWS 数据库博文:数据库迁移 – 开始迁移之前应该了解些什么?
这篇博文是系列文章的第二篇。我们在之前的博文迁移流程和基础设施注意事项中讨论了准备迁移流程和基础设施设置注意事项,以获得最佳性能。第二篇博文讨论了为实现一次性迁移以及通过变更数据捕获 (CDC) 方法继续复制,设置源 Oracle 数据库的配置和环境。适当配置 Oracle 数据库组件以捕获源数据库中的变更使我们能够构建成功的 AWS Database Migration Service (AWS DMS)服务环境。本系列的第三篇也是最后一篇博文涉及目标 PostgreSQL 数据库环境的设置,即使用 AWS DMS 进行数据库迁移流程中的终端节点。
AWS DMS 是一种服务,用于将 Amazon RDS 中的本地数据库或 Amazon EC2 上的数据库迁移到 Amazon RDS 或 Amazon Aurora 数据库。AWS DMS 可以处理同构迁移(例如Oracle 到 Oracle)以及异构迁移,例如 Oracle 到 AWS 云中的 MySQL 或 PostgreSQL。
设置 DMS 就像管理员从 AWS 管理控制台访问 AWS DMS 一样简单。然后,管理员定义一个数据库源,数据将从该数据库源传输到数据库目标以接收数据。
使用 AWS DMS,您可以在几分钟内启动复制任务。AWS DMS 监控数据复制过程,为管理员提供实时性能数据。如果服务在多可用区实例设置中的复制期间检测到网络或主机故障,则会自动预置替代主机。在数据库迁移期间,AWS DMS 保持源数据库正常运行。即使传输中断,源仍然保持运行,从而最大限度地减少应用程序停机时间。
虽然 DMS 设置相对简单,但在开始之前,我们建议您了解两个重要 DMS 流程的工作,即完全加载和变更数据捕获 (CDC) 迁移方法。
适用于 Oracle 数据库源的 AWS DMS 流程
AWS DMS 是一种纯数据迁移服务 – 不要将其误认为是双向数据库复制服务。AWS DMS 在源处传输所有对象和执行的变更。它不会将任何变更或修改迁移到像索引这样的对象。它也没有探讨冲突解决方案。但是,它确实迁移了迁移数据所需的架构变更,例如列添加。
AWS DMS 创建执行迁移所需的目标架构对象。但是,AWS DMS 采用极简方法,仅创建有效迁移数据所需的对象。换句话说,AWS DMS 创建表和主键,在某些情况下还创建唯一索引。但是,它不会创建从源迁移数据不需要的任何对象。例如,它不会创建二级索引、非主键约束或数据默认值。
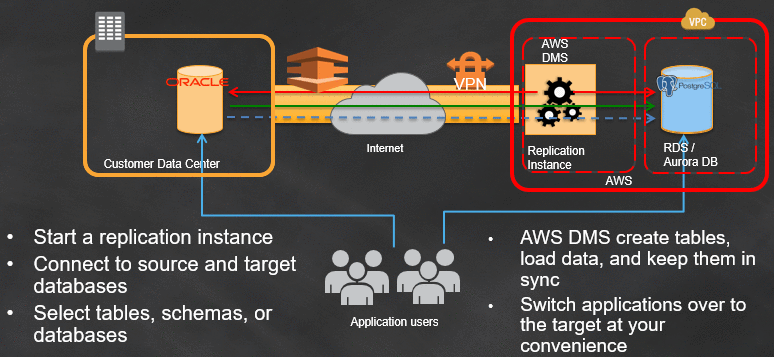
任何数据迁移都是企业内部的关键操作。迁移失败可能会带来很多麻烦,因为迁移可能耗时且昂贵。在着手任何 AWS DMS 迁移项目之前,请确保了解完全加载和变更数据捕获 (CDC) 的重要 DMS 流程步骤的高层次视角,如下所述。
仅完全加载
对于仅完全加载,适用以下流程:
- 使用 AWS Schema Conversion Tool (AWS SCT) 迁移数据定义语言 (DDL):在目标数据库上创建架构,类似于源数据库。有关 AWS SCT 的更多信息,请参阅其文档。
- 删除或禁用目标中的所有外键约束和触发器。您可以通过生成表 DDL 并禁用外键约束或临时删除它们来手动执行此操作。
- 借助此方法使用 AWS DMS 启动加载:
- 设置迁移类型 – 迁移现有数据并复制正在进行的变更。
- 设置目标表准备模式 – 截断(如果目标上有数据)或不执行任何操作(如果目标表没有数据)。
- 在复制中包含 LOB 列 – 对于 LOB 列大小不到 32 KB 的表,使用受限 LOB 模式(使用默认设置)。对 LOB 列大小超过 32 KB 的表使用受限LOB 模式(采用自定义设置)。
- 完全加载完成后停止任务 – 完成完全加载后停止任务。
- 启用日志记录。
- 手动为目标数据库中的表创建辅助对象。
在前面的步骤 3 中,DMS 在迁移数据时经历了三个阶段:
- 在批量加载中完全迁移表数据。这是使用迁移表的完整数据(例如 10 亿条记录)的最有效方法。
- 在 T2、C4 或 R4 DMS 实例上保持和缓存表中发生的变更,直到所有数据都迁移到目标,然后应用缓存的变更。有时,DMS 实例类型可能会成为性能瓶颈。因此,我们建议您在适当考虑迁移方案后选择实例类型:
- T2 实例:专为偶尔有性能突发需求的轻型工作负载而设计。主要用于小型间歇性工作负载的测试迁移。
- C4 实例:专为计算密集型工作负载而设计,具有同类最佳的 CPU 性能。主要用于执行异构迁移和复制时(例如,Oracle 到 PostgreSQL)的 CPU 密集型应用。
- R4 实例:专为内存密集型工作负载而设计。这些实例包括每个 vCPU 具有更多的内存。使用 DMS 进行的高吞吐量事务系统的持续迁移或复制会消耗大量 CPU 和内存。
- 在 CDC(持续复制)阶段迁移变更。如果在迁移的完全加载阶段包含辅助索引,则会产生维护和迁移相关对象的额外开销。
如需在应用变更期间使用辅助索引,我们可以将任务设置为在完全加载阶段完成后停止,然后再开始应用缓存变更。然后,我们可以在添加索引后执行完全加载的任务设置。
具有 CDC 的完全加载
- 步骤 1-3 与前面的仅完全加载相同。
- 停止任务(有关自动步骤,请参阅以下内容)。
- 添加所有辅助对象并启用外键约束。
- 恢复任务以捕获变更。
在前面的步骤 4 中,您可以设置以下选项以在完全加载完成后停止迁移任务:
StopTaskCachedChangesApplied– 将此选项设置为 true 可在完成完全加载和应用缓存变更后停止任务。StopTaskCachedChangesNotApplied– 将此选项设置为 true 可在应用缓存变更之前停止任务。
在任务停止后和应用缓存变更之前,我们可以创建所有辅助对象,以确保数据完整性和更好的 CDC 性能(最小化延迟)。
只有在应用缓存变更之后和开始持续复制之前,才可以启用外键。因此,在这种情况下,我们在应用缓存变更后停止任务。此步骤仅适用于事务模式下,而非批量加载模式下的迁移任务。在这种情况下,不要启用触发器,因为变更已在源处捕获并由 DMS 应用。如果启用触发器,则会执行重复插入,从而导致不一致。但是,有时用户使用触发器来审计数据迁移,这可能会显著影响性能。
使用 AWS DMS CDC 流程以持续方式将Oracle 复制为源时,DMS 提供了两种读取日志的方法:Oracle LogMiner 和Oracle Binary Reader。AWS 数据库博文AWS DMS 现支持将用于 Amazon RDS for Oracle 和 Oracle Standby 的 Binary Reader 作为源中描述了 Binary Reader 的使用方法。
默认情况下,AWS DMS 使用 Oracle LogMiner 进行变更数据捕获 (CDC)。或者,您可以使用 Binary Reader。Binary Reader 绕过 LogMiner 并直接读取日志。与 LogMiner 相比,Binary Reader 可大幅提高性能并减少 Oracle 服务器上的负载。但是,除非您拥有非常活跃的 Oracle 数据库,否则我们建议使用 Oracle LogMiner 迁移 Oracle 数据库。
AWS DMS 通过在文件系统中创建生成和存储存档日志的临时目录来使用 Binary Reader。在大多数情况下,这是 USE_DB_RECOVERY_FILE_DEST 指示的目录位置。迁移任务停止后,将删除此目录。
在将 AWS DMS 用于 Oracle 源数据库之前,请在源 Oracle 数据库上执行以下基本任务:
- 设置 Oracle DMS 用户权限 – 您必须为AWS DMS 用户提供 Oracle 用户帐户。用户帐户必须具有 Oracle 数据库的读/写权限。请注意以下事项:
- 授予权限时,使用对象的实际名称(例如,包括下划线的
V_$OBJECT),而不是对象的同义词(例如,没有下划线的V$OBJECT)。有关授予 DMS 用户的访问权限的信息,请参阅 DMS 文档中的将 Oracle 数据库用作 AWS DMS 的源 。 - 另外确保您登录以使用 DMS 服务的 IAM 用户具有查看日志所需的所有权限。有关这些权限的更多信息,请参阅 DMS 文档中的使用 AWS DMS 所需的 IAM 权限。
- 授予权限时,使用对象的实际名称(例如,包括下划线的
- 启用存档日志 – 如需将 Oracle 与 AWS DMS 一起使用,源数据库必须处于
ARCHIVELOG模式。 - 启用补充日志 – 如果计划使用完全加载和 CDC 任务,请设置补充日志记录以捕获用于复制的变更。
本地 Oracle 源代码
使用本地 Oracle 源时,请注意以下事项。
启用存档日志模式
Oracle 数据库可以两种模式之一运行 — NOARCHIVELOG 或 ARCHIVELOG。默认情况下,数据库在 NOARCHIVELOG 模式下创建。在 ARCHIVELOG 模式下,数据库在填充后会复制所有 ONLINE REDO 日志。这些归档重做日志副本使用 Oracle ARCH 进程创建。ARCH 进程将归档重做日志文件复制到一个或多个归档日志目标目录。
检查以下命令,以查看数据库是否已更改为在 ARCHIVELOG 模式下运行。
启用补充日志记录
重做日志文件用于实例恢复和介质恢复。此类操作所需的数据会自动记录在重做日志文件中。但是,基于重做的应用程序可能需要在重做日志文件中记录其他列。记录其他列的过程称为补充日志记录。
默认情况下,Oracle 数据库不提供任何补充日志记录,如果没有补充日志记录,则无法使用 LogMiner。因此,您需要在生成日志文件之前启用最少的补充日志记录,然后由 LogMiner 进行分析。
以下示例描述了使用 LogMiner 时可能需要其他列的情况:
- 将重构的 SQL 语句应用于其他数据库的应用程序必须通过唯一识别该行的一组列来识别更新语句(例如,主键)。此类应用程序无法通过
V$LOGMNR_CONTENTS返回的重构 SQL 中显示的ROWID来识别该语句。这是因为一个数据库中的ROWID 值与另一个数据库中的ROWID值不同,因此没有意义。 - 应用程序可能需要记录整行的前映像,而不仅仅是已修改的列,以便更有效地跟踪行变更。
补充日志组可以由系统生成的或由用户定义。有两种类型的补充日志组可确定日志组中列的记录时间:
- 无条件补充日志组 – 无论更新是否影响任何指定列,都会在更新行时记录指定列的前映像。此类组有时称为 ALWAYS 日志组。
- 有条件补充日志组 – 仅当日志组中的至少一个列更新时,才会记录所有指定列的前映像。
除了两种类型的补充日志记录外,还有两个级别的补充日志记录:
- 数据库级补充日志记录 – 使用此类日志记录可确保 LogMiner 具有支持各种表结构(如簇表和索引组织表)的最少信息。涉及的命令是
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA。 - 要迁移的每个表的表级补充日志记录 – 对于数据库中具有主键的所有表,请使用以下命令:
此命令创建系统生成的无条件补充日志组,该日志组基于表的主键。
补充日志记录会导致数据库在更新包含主键的行时将行主键的所有列放在重做日志文件中。即使主键中的值没有更改,也会发生此放置。在某些情况下,表可能没有主键但具有一个或多个非空唯一索引键约束或索引键。在这些情况下,选择一个唯一索引键用于记录,作为唯一识别正在更新的行的方法。
如果表既没有主键也没有非空唯一索引键,则除了 LONG 和 LOB 之外的所有列均进行补充记录。这样做等同于为该行的补充日志记录指定 ALL。
因此,我们建议您在使用数据库级主键补充日志记录时,将所有或大多数表定义为具有主键或唯一索引键。您可以通过对每个表执行以下命令来启用此功能:
命名唯一列以及用于过滤重做记录的列:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (…) COLUMNS;ALTER TABLE table_name ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
采用 ALL 或表单独分配方式为补充日志记录分配主键和唯一键列:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (FOREIGN KEY) COLUMNS;ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (UNIQUE) COLUMNS;
删除关键列的数据库补充日志记录不会影响任何现有的表级补充日志组。
如需检查是否已启用数据库级主键、唯一索引、日志记录等,请运行以下命令:
检查内部部署或 EC2 Oracle 数据库是否已启用补充日志记录:
创建 SQL 语句以为所有表添加主键:
我们还建议您保留足够的存档日志文件至少 24 小时:
此外,请查看 RMAN 进程以获取 24 小时备份日志:
Amazon RDS for Oracle 源
使用 Amazon RDS for Oracle 作为源时,请确保首先为 Amazon RDS for Oracle 实例启用自动备份:
如需将其删除,请使用以下命令:
在某些情况下,迁移任务启动后,您可能会创建一个没有主键的新表。在这种情况下,我们建议您在源 Oracle 终端节点连接属性中添加“addSupplementalLogging=Y”。这样做意味着 DMS 会捕获表中所有已变更的列。此添加需要“alter any table”特权和独占锁定才能更改表。
如果启用“addSupplementalLogging=Y”而不使用“alter any table”权限,DMS 将返回错误。但是,如果使用主键创建表并执行此操作,则 DMS 不会返回错误,因为 DMS 不会为该表的所有列添加补充日志记录。
因为启用“addSupplementalLogging=Y”需要对源表进行独占锁定,所以最好手动启用。
RDS Oracle 采用 CDC 模式
如需在 CDC 模式下为 RDS Oracle 源执行迁移,您需要满足以下先决条件:
- 使用 Oracle Binary Reader 版本 2.4.2R1 或更高版本。
- 使用 Oracle 版本 11.2.0.4.v11 及更高版本,或 12.1.0.2.v7 及更高版本。执行此操作时,请使用“ORCL”默认名称来创建 RDS Oracle 实例。否则,以下流程无法成功运行。
- 如需创建所需的符号链接服务器目录,请运行以下流程。有关此流程的详细信息,请参阅 DMS 文档中的访问事务日志。
- 如果您计划使用 Binary Reader 方法,请使用 RDS Oracle 的事件条件动作 (ECA) 。在一行中输入以下所有选项。
- 在数据库级别为主键创建补充日志记录:
- 至少在过去 24 小时内保留 DMS 任务的存档日志:
执行以下命令,以便 RDS Oracle 手动切换日志
从 Oracle ASM 迁移数据
Oracle 自动存储管理 (ASM) 数据库框架为 Oracle 数据库文件提供卷管理器和文件系统。它支持单实例 Oracle 数据库和 Oracle Real Application Clusters (Oracle RAC) 配置。ASM 具有直接在数据库内管理文件系统和卷的工具。您可以在 AWS 数据库博客文章如何使用AWS DMS 从 Oracle ASM 迁移到 AWS中找到有关从 ASM 迁移的详细信息。
在 Oracle ASM 架构中,DMS 设置必须创建一个临时目录来配置 Binary Reader 以进行变更处理。由于磁盘组和数据范围由单独的 ASM 实例管理,因此 AWS DMS 还需要连接到此ASM 实例。此外,此 ASM 实例还应接受来自 DMS 复制实例的流量。AWS DMS 创建了一个用于迁移的相关目录。
如需将 Oracle ASM 设置为 AWS DMS 的源(参见 DMS 文档中的详细信息),请使用以下额外连接属性。这些配置 Binary Reader 用于 ASM 的变更处理。
当前述属性与 Oracle ASM 源一起使用时,如果测试连接成功,但不是迁移。在这种情况下,您可能会在迁移任务日志中看到以下错误:
Oracle ASM 源的额外连接属性字段应类似于以下内容:
server_address 值与创建相关终端节点时提供的服务器名称值相同。
此外,在使用 ASM 实例时,密码字段要求您提供尝试迁移的 Oracle 实例的密码。您还需要提供连接到 ASM 实例的密码。您可以使用逗号分隔字段中的两个密码:
CDC 处理速度
在 ASM 环境中,访问重做日志通常很慢。之所以速度低,是因为 API 操作负责在单次调用中只读取最多 32 千字节的块。此外,使用 LogMiner 通过 AWS DMS 设置 ASM 以进行持续复制时,性能下降问题可能会产生高延迟。如果存在连接问题或源实例出现故障,迁移有时无法正常恢复。
为了使用 AWS DMS 为 Oracle ASM 源提高速度并使迁移更加稳健,我们建议使用具有 DMS 复制功能的 Binary Reader。在此方法中,DMS 将存档日志从 ASM 复制到 Oracle 服务器上的本地目录。然后,DMS 可以使用 Binary Reader 读取复制的日志。
这里唯一的要求是,本地目录应位于底层Linux 文件系统上,而不是位于 ASM 实例上。
还有另外一些快速方法可提高 CDC 速度:
- 您不能在表的 DDL 或主键中使用诸如“
tag”之类的保留字。 - 您必须在 PostgreSQL 目标上拥有一个主键才能进行更新或删除,以批量模式运行并获得更佳的性能。
- 最好首先使用排序键和主键来预创建表,然后使用“截断”或“不执行任何操作”作为表制备模式。您的排序键可以是复合键或交错键,具体取决于查询的模式。
- 您的分配密钥应该是偶数或密钥,不能是
ALL。 - 如需提高性能,请将“
BatchApplyPreserveTransaction”设置为 false。
DMS 与 Oracle RAC、DMS 副本和 ASM配置
您的 Oracle 数据库必须能够从临时文件夹写入和删除。如果 Oracle 源数据库是 Oracle RAC 集群,则临时文件夹必须位于 Oracle RAC 中所有节点均可访问的文件共享上。如果选择 Binary Reader 方法来访问临时文件夹,则该文件夹不必是共享网络文件夹。
如果多个任务使用相同的临时文件夹,则可能会发生冲突(例如,一个任务需要访问另一个任务已删除的重做日志)。为防止此类冲突,在任何给定时间应只有一个 DMS 任务可访问同一个临时文件夹。但是,您可以为每个任务在同一根文件夹下创建不同的子文件夹。例如,不是将 /mnt/dms 指定为两个任务的临时文件夹,而是可以为一个任务指定 /temp/dms/task1,为另一个任务指定 /temp/dms/task2。
使用临时文件夹时,请确保删除 DMS 处理的归档重做日志文件。删除这些可确保重做日志不会累积在临时文件夹中。确保文件系统中有足够的空间来创建临时文件夹。如果正在运行多个任务,请用所需的磁盘空间乘以任务数,因为每个任务都有自己的临时文件夹。
执行以下步骤以使用 DMS 复制功能设置Binary Reader 访问权限:
- 在 Oracle 服务器上选择一个临时文件夹。如前所述,如果您的源是 Oracle RAC,则所有 RAC 节点都应该能够访问该文件夹。该文件夹应具有 Oracle 用户和 Oracle 组(例如,DBA)的读取、写入和删除权限。
- 授予 DMS 用于连接 Oracle 的用户以下权限。下列最后一个权限允许使用
COPY_FILE方法将存档重做日志复制到临时文件夹。 - 如果您希望 AWS DMS 创建和管理 Oracle 目录,请授予以下权限。如前所述,AWS DMS 需要使用目录对象将重做日志复制到临时文件夹并从临时文件夹中将其删除。如果您授予以下权限,AWS DMS 将使用
DMSREP_前缀创建 Oracle 目录。如果您不授予此权限,则需要手动创建相应的目录。目录应指向归档重做日志和临时文件夹路径。如果手动创建目录,则无需将DMSREP_前缀附加到目录名称。
- 创建 Oracle 源终端节点时,如果指定的 DMS 用户不是创建 Oracle 目录的用户,请提供以下附加权限(示例如下):
读取指定为源目录的 Oracle 目录对象(即,如果使用 BFILE 方法从临时文件夹读取,则为 ASM 归档重做日志路径和临时文件夹)。- 在复制过程中指定为目标目录的目录对象(即临时文件夹)上
写入。
- 如需防止旧的重做日志累积在临时文件夹中,请将 AWS DMS 配置为处理后从临时文件夹中删除重做日志文件。使用 Oracle 文件组和 Oracle
DBMS_FILE_GROUP包执行删除操作。 - 确保 AWS DMS 具有从 ASM 读取联机重做日志所需的 ASM 访问权限(即
SYSASM或SYSADM权限)。此权限必不可少,因为从 ASM 读取联机重做日志是使用 Oracle DBMS_DISKGROUP 程序包中的函数执行的。执行此操作需要 SYSASM 或 SYSADM 权限。您还可以通过打开命令提示符窗口并发布以下语句来验证 ASM 帐户访问权限:从 Oracle 11g 第 2 版 (11.2.0.2) 开始,必须为 AWS DMS 用户授予访问 ASM 帐户的
SYSASM权限。对于较旧的支持版本,授予SYSDBA权限应已足够。 - 选择存档重做日志目标标识符。此数字是复制应读取的归档重做日志的目标 ID。该值应与 v $ archived_log 中的 DEST_ID 编号相同。然后在源终端节点上添加以下属性:
其中
nn是 DMS 中连接字符串的目标 ID。 - 设置 Oracle ASM 源终端节点,以便额外的连接属性字段如下所示:
这是一个示例:
还有一些额外的注意事项。首先,如果您手动创建目录并且 Oracle 源终端节点中指定的 Oracle 用户不是创建 Oracle 目录的用户,请授予READ ON DIRECTORY权限。
如果 Oracle 源终端节点中指定的 Oracle 用户不是创建 Oracle 目录的用户,则还需要以下附加权限:
读取指定为源目录的 Oracle 目录对象(即,如果使用 BFILE 方法从临时文件夹读取,则为 ASM 归档重做日志路径和临时文件夹)- 在复制过程中指定为目标目录的目录对象(即临时文件夹)上
写入
运行以下命令:
此外,运行以下命令:
另一个示例如下:
对于带有 ASM 的 Oracle RAC,请确保正确配置 ASM 服务器的源终端节点 IP 地址。使用服务器的公共 IP 地址和 asm_server 的内部 IP 地址会导致错误消息,因为迁移任务无法连接。
对于带有 ASM 的 Oracle RAC,请使用以下配置:
- 使用以下连接属性:
useLogminerReader=N;asm_user=<asm_username e.g. sysadm>;asm_server=<first_RAC_server_ip_address>/<ASM service name e.g. +ASM or +APX> - 使用以下逗号分隔的密码字段:
- 如果将 RDS Oracle Binary Reader 模式与非 ASM 设置搭配使用,请使用以下额外连接属性:
Oracle Log Miner 可以与 Oracle RAC 搭配使用,从线程 1 和 2 中提取 DML 和 DDL 变更。使用带或不带 ASM 的 LogMiner for Oracle RAC 时,无需额外的连接属性 (ECA)。在 2.3 版本中,DMS 开始为 LogMiner 和 Binary Reader 支持此功能(“additionalArchivedLogDestid=2”)。
小结
本博文概述了配置和设置源 Oracle 数据库以迁移到 PostgreSQL 环境所需的迁移步骤。我们在迁移构建流程的此部分中使用 AWS Database Migration Service (AWS DMS) 和 AWS Schema Conversion Tool (AWS SCT)。
有关此迁移的最后阶段所涉及的步骤,请参阅本系列的最后一篇博文PostgreSQL 环境的目标数据库注意事项。
致谢
如果没有以下各位贡献者的全面审核和坚持反馈,本博文也就无法面世:Silvia Doomra、Melanie Henry、Wendy Neu、Eran Schitzer、Mitchell Gurspan、Ilia Gilderman、Kevin Jernigan、Jim Mlodgenski、Brownlee、Ed Murray 和Michael Russo。
关于作者
 Mahesh Pakala自 2014年 4 月起一直在 Amazon 工作。在加入亚马逊之前,他曾在 Ingres、Oracle Corporation 和 Dell Inc. 等公司工作,为具有战略意义的大型客户提供高可用性可扩展应用程序设计、异构云应用程序迁移的建议,并协助其调优系统性能。
Mahesh Pakala自 2014年 4 月起一直在 Amazon 工作。在加入亚马逊之前,他曾在 Ingres、Oracle Corporation 和 Dell Inc. 等公司工作,为具有战略意义的大型客户提供高可用性可扩展应用程序设计、异构云应用程序迁移的建议,并协助其调优系统性能。