使用 HPC(高性能计算)应对计算流体动力学 (CFD) 的挑战已成为惯例。随着近一二十年间,HPC 工作站向超级计算机的发展变缓,计算集群正不断地取代单独的大型 SMP(共享内存处理)超级计算机的地位,并且已成为“新常态”。另外,一项更加新的创新——云技术,同样也大幅提升了总的计算吞吐量。
这一篇博文将向您介绍在数分钟内于运行 Ansys Fluent(一款市售的计算流体动力学软件包)的 AWS 上完成 HPC 集群设置的
最佳
优良实践。此外您还能看到一些安装 Ansys Fluent 并运行您的首个作业的示例脚本。“最佳指南”是一种相对称呼,在云技术中更是如此,因为存在能以不同方式组合达成相同目的的诸多可能性(亦称为服务)。仅在需要使用特定的应用程序特性或应用程序功能的情况下,才能判定某种选择是否优于另一种。举例来说,“高性能并行文件系统 (Amazon FSx) 优于 NFS 共享”这一判断在绝大部分 HPC 工作负载中是成立的,但在另一些情形中(例如 !I/O 密集型应用程序,或者创建小型 HPC 集群来运行少量和/或小型作业)NFS 共享已经绰绰有余,并且此种方式更加廉价,设置简单。在此篇博文中我们将分享我们视作
最佳
优良实践的方法,以及其他一些您在实践中可能会考虑的可用替代选择。
我们将会使用的主要集群组件是以下的 AWS 服务:
注:我们在 re:Invent 2018 上发布了 Elastic Fabric Adapter (EFA),最近又在多个 AWS 区域中推出了该服务。EFA 这种网络设备可挂载到您的 Amazon EC2 实例以加速 HPC 应用程序的运行,降低延迟并使其更均匀,带来比基于云的 HPC 系统通常使用的 TCP 传输方式更高的吞吐量。其提升了对于扩展 HPC 应用程序至关重要的实例间通信的性能,并为在现有 AWS 网络基础设施上运行做了优化。Ansys Fluent 尚不适合与 EFA 共用,因此本篇博文中不会全面介绍这一具体的网络设备。
注意:ANSYS Fluent 是一款需要许可证的市售软件包。本文假定您已获得在 AWS 上使用(或通过 AWS 访问)Ansys Fluent 的许可证。此外,下文的安装脚本还需要您拥有 Ansys 安装包 。您可以在“下载 – 当前发行版本”下方下载当前发行版本的 Ansys。
第一步:创建一个自定义 AMI
为了加速集群的创建,更重要的是,为了缩短计算节点的启动时间,良好做法是创建一个部分软件包已预安装并且设置已完成配置的自定义 AMI。
- 以已有 AMI 为基础开始工作,记下您计划部署集群区域的适用 AMI ID,详情请见我们的 AMI 区域列表。例如,我们在弗吉尼亚州 (us-east-1) 使用 CentOS7 开始工作,则 AMI ID 为
ami-0a4d7e08ea5178c02。
- 打开 AWS 控制台并在偏好区域(即选择 AMI 的区域)中启动一个实例,按前述方式使用 AMI ID。
- 确保您的实例可以从互联网访问,并且具有公共 IP 地址。
- 为实例分配一个允许其从 S3(或从特定的 S3 存储桶)下载文件的 IAM 角色。
- 可选择标记实例(即 Name = Fluent-AMI-v1)。
- 配置安全组以允许端口 22 上的入站连接。
- 如果您需要为 AWS ParallelCluster 创建自定义 AMI 方法的额外细节,请参阅官方文档 Building a custom AWS ParallelCluster AMI。
- 实例就绪后,通过 SSH 进行连接并以 root 身份运行以下命令:
yum -y update
yum install -y dkms zlib-devel libXext-devel libGLU-devel libXt-devel libXrender-devel libXinerama-devel libpng-devel libXrandr-devel libXi-devel libXft-devel libjpeg-turbo-devel libXcursor-devel readline-devel ncurses-devel python python-devel cmake qt-devel qt-assistant mpfr-devel gmp-devel htop wget screen vim xorg-x11-drv-dummy xorg-x11-server-utils libXp.x86_64 xorg-x11-fonts-cyrillic.noarch xterm.x86_64 openmotif.x86_64 compat-libstdc++-33.x86_64 libstdc++.x86_64 libstdc++.i686 gcc-c++.x86_64 compat-libstdc++-33.i686 libstdc++-devel.x86_64 libstdc++-devel.i686 compat-gcc-34.x86_64 gtk2.i686 libXxf86vm.i686 libSM.i686 libXt.i686 xorg-x11-fonts-ISO8859-1-75dpi.no xorg-x11-fonts-iso8859-1-75dpi.no libXext gdm gnome-session gnome-classic-session gnome-session-xsession xorg-x11-server-Xorg xorg-x11-drv-dummy xorg-x11-fonts-Type1 xorg-x11-utils gnome-terminal gnu-free-fonts-common gnu-free-mono-fonts gnu-free-sans-fonts gnu-free-serif-fonts alsa-plugins-pulseaudio alsa-utils
yum -y groupinstall "GNOME Desktop"
yum -y erase initial-setup gnome-initial-setup initial-setup-gui
#a reboot here may be helpful in case the kernel has been updated
#this will disable the ssh host key checking
#usually this may not be needed, but with some specific configuration Fluent may require this setting.
cat <<\EOF >> /etc/ssh/ssh_config
StrictHostKeyChecking no
UserKnownHostsFile /dev/null
EOF
#set higher limits, usefull when running Fluent (and in general HPC applications) on multiple nodes via mpi
cat <<\EOF >> /etc/security/limits.conf
* hard memlock unlimited
* soft memlock unlimited
* hard stack 1024000
* soft stack 1024000
* hard nofile 1024000
* soft nofile 1024000
EOF
#stop and disable the firewall
systemctl disable firewalld
systemctl stop firewalld
#install the latest ENA driver, ATM 2.1.1
cd /tmp
wget https://github.com/amzn/amzn-drivers/archive/ena_linux_2.1.1.tar.gz
tar zxvf ena_linux_2.1.1.tar.gz
mv amzn-drivers-ena_linux_2.1.1 /usr/src/ena-2.1.1
cat <<EOF > /usr/src/ena-2.1.1/dkms.conf
PACKAGE_NAME="ena"
PACKAGE_VERSION="2.1.1"
AUTOINSTALL="yes"
REMAKE_INITRD="yes"
BUILT_MODULE_LOCATION[0]="kernel/linux/ena"
BUILT_MODULE_NAME[0]="ena"
DEST_MODULE_LOCATION[0]="/updates"
DEST_MODULE_NAME[0]="ena"
CLEAN="cd kernel/linux/ena; make clean"
MAKE="cd kernel/linux/ena; make BUILD_KERNEL=\${kernelver}"
EOF
dkms add -m ena -v 2.1.1
dkms build -m ena -v 2.1.1
dkms install -m ena -v 2.1.1
dracut -f —add-drivers ena
#reboot again, and make sure that after the reboot the ena driver is up to date (run modinfo ena to check)
#install the latest version of NICE DCV (at the moment it is 2017.4)
cd /tmp
wget https://d1uj6qtbmh3dt5.cloudfront.net/server/nice-dcv-2017.4-6898-el7.tgz
tar xzvf nice-dcv-2017.4-6898-el7.tgz
cd nice-dcv-2017.4-6898-el7
yum install -y nice-dcv-server-2017.4.6898-1.el7.x86_64.rpm nice-dcv-gltest-2017.4.216-1.el7.x86_64.rpm nice-xdcv-2017.4.210-1.el7.x86_64.rpm
#install this additional package only in case you are running on an instance equipped with GPU
yum install -y nice-dcv-gl-2017.4.490-1.el7.i686.rpm nice-dcv-gl-2017.4.490-1.el7.x86_64.rpm
# Add the line "blacklist = /usr/bin/Xorg" to section [gl] of /etc/dcv/dcv-gl.conf
# to fix an incompatibility introduced with the latest versions of Xorg and Nvidia driver
sed -i 's|\[gl\]|&\nblacklist = /usr/bin/Xorg|' /etc/dcv/dcv-gl.conf
#Clean up the instance before creating the AMI.
/usr/local/sbin/ami_cleanup.sh
#shutdown the instance
shutdown -h now
现在您可以通过 AWS CLI(或 AWS Web 控制台)创建您的 AMI 了:
aws ec2 create-image --instance-id i-1234567890abcdef0 --name "Fluent-AMI-v1" --description "This is my first Ansys Fluent AMI"
输出将如下所示:
{
"ImageId": "ami-1a2b3c4d5e6f7g"
}
记住 AMI id。稍后 AWS ParallelCluster 配置文件中将会用到。
创建/复用 VPC、子网以及安全组
下一步,创建或复用已有 VPC。注意 vpc-ID 和 subnet-ID。有关为 AWS ParallelCluster 创建并配置 VPC 方法的更多信息,可参阅网络配置。
您可以使用单个子网同时用于主实例和计算实例,或者使用两个子网:一个公共子网上为主实例,一个私有子网上为计算实例。
下方的配置文件展示了在单个子网上运行集群的方法,如此架构图所示:
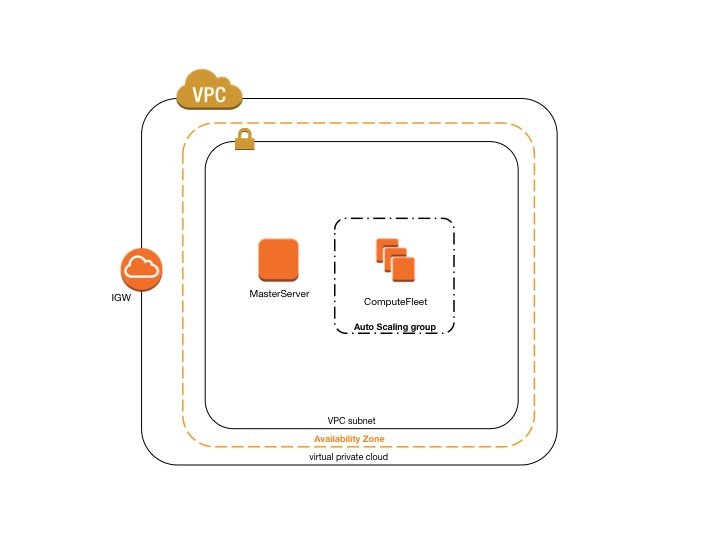
还要创建一个开启 8443 端口的临时安全组。这将用于允许与使用 NICE DCV 作为远程桌面流协议的主节点建立入站连接。
创建集群配置文件和后安装脚本
现在您可以开始编写配置文件了。在您本地 PC 上打开一个文本文件,并将下方代码粘贴进去。(此处为示例,您可能要依照偏好修改其中一些参数。您还要将占位符 <XXX> 替换为您自己的设置。)
[aws]
aws_region_name = <your-preferred-region>
[global]
sanity_check = true
cluster_template = fluent_cluster_test1
update_check = true
[vpc vpc-us-east-1]
vpc_id = vpc-<VPC-ID>
master_subnet_id = subnet-<Subnet-ID>
additional_sg=sg-<Security-Group-ID>
[cluster fluent_cluster]
key_name = <Key-Name>
vpc_settings = vpc-us-east-1
compute_instance_type=c5n.18xlarge
master_instance_type=g3.4xlarge
initial_queue_size = 0
max_queue_size = 10
maintain_initial_size = true
scheduler=sge
cluster_type = ondemand
s3_read_write_resource=arn:aws:s3:::<Your-S3-Bucket>*
post_install = s3://<Your-S3-Bucket>/fluent-post-install.sh
placement_group = DYNAMIC
placement = compute
master_root_volume_size = 64
compute_root_volume_size = 20
base_os = centos7
extra_json = { "cluster" : {"cfn_scheduler_slots" : "cores" } }
tags = {"Name" : "fluent_cluster_test1"}
fsx_settings = parallel-fs
custom_ami = ami-<AMI-ID>
[fsx parallel-fs]
shared_dir = /fsx
storage_capacity = 3600
import_path = s3://<Your-S3-Bucket>
imported_file_chunk_size = 1024
export_path = s3://<Your-S3-Bucket>/export
让我们来详细研究一下该配置中的某些设置:
- aws_region_name = 选择正确的 AWS 区域对于您远程桌面会话的可用性至关重要:您与所选区域的地理距离越近,网络延迟就越低,可用性和交互性也就越好。如果您不清楚距您最近的 AWS 区域,可使用简单的 CloudPing 服务来确定哪个区域的延迟最低。
- initial_queue_size=0。此设置用于定义集群的初始大小。在此示例中其值为 0(您可以根据自己的需要任意修改)。0 意味着当您首次提交作业时,您的作业在队列中将处于待处理状态。当在集群中添加节点时,作业将转变为运行状态。AWS ParallelCluster 默认情况下会每 5 分钟检视一次计划程序队列,并根据运行待处理作业所需的槽数添加(或删除)节点。
- compute_instance_type = c5n.18xlarge。此设置用于定义集群计算节点的实例类型。此配置文件显示为 c5n.18xlarge。这是(在撰文时)最适合紧密耦合工作负载的实例。C5n.18xlarge 具有最佳的价格/性能比,及最佳的内存/核心比,还有一点很重要的是,它可用于 EFA。其他适用的实例是(最新的)c5.24xlarge 和 c4.8xlarge,两者价格都与 C4n.18xlarge 相近,但不支持 EFA。如果您想要构建自己的网格,并且需要更高的内存/核心比,m5.24xlarge 或 r5.24xlarge 是不错的选择,但其价格存在差异。最后,由于使用了定制的 Intel® Xeon® 可扩展处理器(可维持最高为 4.0 GHz 的全核频率),z1d.12xlarge 实例可以发挥出最大的效能,是所有云实例中速度最快的。不管实例类型为何,我们的建议是始终为所有实例类型选择最大大小。一般而言,紧密耦合工作负载的可扩展性受限于网络带宽(及延迟),因此为您的实例选择最大大小,可以通过每一个单独实例使用尽可能多的核心来减少跨节点通信。
- master_instance_type = g3.4xlarge。此设置用于定义集群主节点(或登录节点)的实例类型。在此示例中,我们选择配有 GPU (Nvidia M60) 的实例,因为我们还想要在作业完成之后进行数据后处理。后处理应用通常需要一个 GPU 来渲染复杂的 3D 图像。如果您不想执行任何后处理(或者您的后处理不需要 GPU),则可以选择与计算节点相同的实例类型(可能只是大小略小),或者您可以选择适合构建网格的实例类型(m5.24xlarge 或 r5.24xlarge)。
- placement_group = DYNAMIC 和 placement = compute 两者用于告知 AWS 我们想要使用集群置放组,以及只有计算节点需要位于相同的置放组中,主节点不需要。在启用 NFS 共享,计算节点与主节点之间的延迟需要尽可能低时,将主节点也放置于相同的置放组中是一种良好做法。在我们示例中,我们不使用 NFS 共享,而是使用 FSx。
- extra_json = { “cluster” : {“cfn_scheduler_slots” : “cores” } } 此语句连同下方后安装脚本开头的 for 循环一起用于禁用超线程。绝大部分的 HPC 应用程序无法从超线程中获益。但是,如果禁用超线程而不使用此行语句,SGE 将无法正确地将槽映射到核。
- custom_ami = ami-<AMI-ID> 该设置将告知 AWS ParallelCluster 使用您先前创建的 AMI。
- [fsx parallel-fs] 该部分包含定义您的基于 FSx 的并行高性能文件系统的设置。
- post_install = s3://<Your-S3-Bucket>/fluent-post-install.sh.该设置定义在所有实例创建之后,在实例上运行的脚本的位置。下方是一个针对此处案例调整过的脚本示例;您可以原样使用,也可以根据需要进行修改:
#!/bin/bash
#source the AWS ParallelCluster profile
. /etc/parallelcluster/cfnconfig
#disable hyper-threading
for cpunum in $(cat /sys/devices/system/cpu/cpu*/topology/thread_siblings_list | cut -s -d, -f2- | tr ',' '\n' | sort -un); do
echo 0 > /sys/devices/system/cpu/cpu$cpunum/online
done
case "${cfn_node_type}" in
MasterServer)
#save the instance type
instanceType=$(curl http://169.254.169.254/latest/meta-data/instance-type)
if [[ $instanceType == *"g3"* ]]; then
# configure Xorg to use the Nvidia GPU with the right driver
nvidia-xconfig -preserve-busid -enable-all-gpus
#Configure the GPU settings to be persistent
nvidia-persistenced
#Disable the autoboost feature for all GPUs on the instance
nvidia-smi -auto-boost-default=0
#Set all GPU clock speeds to their maximum frequency.
nvidia-smi -ac 2505,1177
else
cd /etc/X11/
#download a dummy xorg.conf,
#This is used by instances without GPU
wget -q https://xpra.org/xorg.conf
fi
#set the system to run the graphical mode (init 5)
systemctl set-default graphical.target
#and start GDM
systemctl enable gdm.service
systemctl start gdm.service
sleep 2
#enable and start also DCV
systemctl enable dcvserver.service
systemctl start dcvserver.service
sleep 2
#create a NICE DCV session
dcv create-session --owner centos --user centos test1
echo "centos:<YourPassword>" | chpasswd
;;
ComputeFleet)
#nothing here, for now
;;
esac
注:将占位符 <YourPassword> 替换为您自己的密码。该密码将仅用于通过 NICE DCV 执行连接。要通过 SSH 进行连接,您仍然需要使用配置文件中定义的私有密钥。
注:目前所提及的一些服务,尤其是 FSx 和 C5n,都是非常新的服务,它们可能只能用于某些区域。请查看区域表格来了解您偏好的区域是否拥有所有必要的服务。如果 C5n 不可用,可选择 C4.8xlarge 或 C5.18xlarge。如果 FSx 不可用,则使用 NFS 共享,不使用 EBS。下方的示例代码片段启用了 NFS 共享,而没有使用 IO1 卷类型。IO1 是一种 I/O 密集型高性能 SSD 卷,用于提供最高为 50 IOPS/GB(最大为 64,000 IOPS)的一致基线性能,每卷最高可提供 1,000 MB/s 的吞吐量(即 1TB 最高可提供 50,000 IOPS)。您也可以将 GP2 视作一种成本更低的替代方案,它具有数毫秒的延迟,提供 3 IOPS/GB 的一致基线性能(最低 100 IOPS),最大 16,000 IOPS,每卷可提供最高为 250 MB/s 的吞吐量。参阅 ParallelCluster 文档的 EBS 部分可了解更多内容。
[ebs shared-fs]
volume_size = <size in GB>
shared_dir = /shared
#ebs_snapshot_id =
volume_type = io1
volume_iops = <number of IOPS>
您还需要将 fsx_setting 参数注释掉:
#fsx_settings = parallel-fs
并将其替换为:
在使用 NFS 时,留意其会限制扩展性;当有成千上万的客户端需要同时访问文件系统时,FSx 特别有用。(如果您计划运行数个作业,每个作业使用多个节点,则此情形并不罕见。)
部署您的首个集群
现在您已经拥有了为 Ansys Fluent 创建首个 AWS ParallelCluster 的所有基础组件,您只需要将后安装脚本上传到您的 S3 存储桶中:
aws s3 cp fluent-post-install.sh s3://<Your-S3-Bucket>/fluent-post-install.sh
注:确保将您的后安装脚本上传到配置文件中指定的存储桶。
后安装脚本上传完成后,您可以通过运行以下命令行,使用先前定义的 ParallelCluster 配置文件创建集群:
pcluster create -c fluent.config fluent-test -t fluent_cluster -r <your-preferred-region>
注:如果这是您使用 AWS ParallelCluster 进行的首次测试,您需要额外的说明了解如何开始,则可以参阅这一篇 ParallelCluster 操作入门的博文,和/或 AWS ParallelCluster 文档。
安装 Ansys Fluent
现在是时候连接您集群的主节点,并安装 Ansys 套件了。您将需要使用先前命令输出结果中的公共 IP 地址。
您可以使用 SSH 和/或 DCV 连接主节点。
- 通过 SSH:
ssh -i /path/of/your/ssh.key centos@<public-ip-address>
- 通过 DCV:打开浏览器并连接
https://<public-ip-address>:8443 您可以使用“centos”作为用户名,并使用在后安装脚本中定义的密码。
在您登录后,获得 root 身份(sudo su - 或 sudo -i)并在 /fsx 目录下安装 Ansys 套件。您可以手动安装,也可以使用下方的示例脚本。
注意:我们已经在配置文件的 FSx 部分定义了 import_path = s3://<Your-S3-Bucket>。这将告知 FSx 从 <Your-S3-Bucket> 预加载所有数据。我们建议您预先向 S3 复制 Ansys 安装文件以及其他所有您可能用到的文件或软件包,这样所有这些文件都将位于集群的 /fsx 目录下供您使用。以下示例使用了 Ansys iso 安装文件。您可以使用 tar 或 iso 文件,这两种文件都可以从 Ansys 网站的“下载 → 当前发布版本”之下下载。
#!/bin/bash
#check the installation directory
if [ ! -d "${1}" -o -z "${1}" ]; then
echo "Error: please check the install dir"
exit -1
fi
ansysDir="${1}/ansys_inc"
installDir="${1}/"
ansysDisk1="ANSYS2019R2_LINX64_Disk1.iso"
ansysDisk2="ANSYS2019R2_LINX64_Disk2.iso"
# mount the Disks
disk1="${installDir}/AnsysDisk1"
disk2="${installDir}/AnsysDisk2"
mkdir -p "${disk1}"
mkdir -p "${disk2}"
echo "Mounting ${ansysDisk1} ..."
mount -o loop "${installDir}/${ansysDisk1}" "${disk1}"
echo "Mounting ${ansysDisk2} ..."
mount -o loop "${installDir}/${ansysDisk2}" "${disk2}"
# INSTALL Ansys WB
echo "Installing Ansys ${ansysver}"
"${disk1}/INSTALL" -silent -install_dir "${ansysDir}" -media_dir2 "${disk2}"
echo "Ansys installed"
umount -l "${disk1}"
echo "${ansysDisk1} unmounted..."
umount -l "${disk2}"
echo "${ansysDisk2} unmounted..."
echo "Cleaning up temporary install directory"
rm -rf "${disk1}"
rm -rf "${disk2}"
echo "Installation process completed!"
注意:如果您决定使用 EBS 共享选项,而非 FSx,则在 Ansys 安装完成后,您可能想要创建 EBS 卷的快照以便在其他集群中复用。您可以通过 web 控制台创建快照:
- 打开 Amazon EC2 控制台。
- 选择导航窗格中的快照。
- 选择创建快照。
- 在创建快照页面中选择要创建快照的卷。
- (可选)选择向快照添加标签。每个标签需要提供一个标签键和一个标签值。
- 选择创建快照。
如果使用 CLI:
aws ec2 create-snapshot --volume-id vol-xyz --description "This is the snapshot of my Ansys installation"
如果您想要复用已有的快照,则在 AWS ParallelCluster 配置文件的 ebs 部分添加以下参数:
ebs_snapshot_id = snap-XXXX
有关更多信息,请参见 Amazon EBS 快照。
运行您的首个 Ansys Fluent 作业
最后,您可以通过 qsub 提交以下脚本,来运行您的首个作业。以下是使用 14 C5n.18xlarge 实例运行作业的方法示例:qsub -pe mpi 360 /fsx/ansys-run.sh
ansys-run.sh可以是:
#!/bin/bash
#$ -N Fluent
#$ -j Y
#$ -S /bin/bash
export ANSYSLI_SERVERS=2325@<your-license-server>
export ANSYSLMD_LICENSE_FILE=1055@<your-license-server>
basedir="/fsx"
workdir="${basedir}/$(date "+%d-%m-%Y-%H-%M")-${NSLOTS}-$RANDOM"
mkdir "${workdir}"
cd "${workdir}"
cp "${basedir}/f1_racecar_140m.tar.gz" .
tar xzvf f1_racecar_140m.tar.gz
rm -f f1_racecar_140m.tar.gz
cd bench/fluent/v6/f1_racecar_140m/cas_dat
${basedir}/ansys_inc/v194/fluent/bin/fluentbench.pl f1_racecar_140m -t${NSLOTS} -cnf=$PE_HOSTFILE -part=1 -nosyslog -noloadchk -ssh -mpi=intel -cflush
注意:您可能想要将基准文件 f1_racecar_140m.tar.gz 或其他想要使用的数据集复制到 S3,以便其能在 FSx 预加载供您使用。
小结
虽然此博文主要关注点为安装、设置、运行 Ansys Fluent,但也可将其中做法稍加修改用于运行其他 CFD 应用程序,以及其他使用消息传递接口 (MPI) 标准的应用程序,例如 OpenMPI 或 Intel-MPI。我们很乐意帮助您,代您在 AWS 上运行此等 HPC 应用程序,然后与您分享我们的最佳实践,您可以通过 AWS Docs GitHub 存储库或电子邮件随时随地提交您的请求。
最后,请不要忘记 AWS ParallelCluster 是一个以社区为中心的项目。我们欢迎所有人提交拉取请求或通过 GitHub 问题提供反馈。用户的反馈对于 AWS 来说极为重要,因为正是这些反馈推动了每一项服务及功能的发展!