亚马逊AWS官方博客
使用 Amazon MSK Connect、Apache Flink 和 Apache Hudi 创建低延迟的源到数据湖管道
近年来,我们已经从整体式架构向微服务架构转变。微服务架构使应用程序更易于扩展和更快开发,从而实现创新并加快新功能的上市。但是,这种方法会导致数据存在于不同的孤岛中,这使得执行分析变得困难。为了获得更深入和更丰富的洞察,您应该将不同孤岛中的所有数据集中到一个地方。
- 当记录存储在 Amazon S3 上的开放数据格式文件(例如 JSON、ORC 或 Parquet)中时,很难应用记录级更新或删除。
- 在任务需要以低延迟写入数据的串流使用场景中,行式格式(例如 JSON 和 Avro)最适合。但是,使用这些格式扫描许多小文件会降低读取查询性能。
- 在源数据架构频繁更改的使用场景中,通过自定义代码维护目标数据集的架构既困难又容易出错。
Apache Hudi 提供了解决这些挑战的好方法。Hudi 在第一次写入记录时会建立索引。Hudi 使用这些索引来查找进行了更新(或删除)的文件。这使得 Hudi 无需扫描整个数据集,即可执行快速的 upsert(或删除)操作。Hudi 提供了两种表类型,每种类型都针对特定场景进行了优化:
- 写入时复制(COW)– 这些表通常用于批处理。在这种类型中,数据以列式格式(Parquet)存储,并且每次更新(或删除)都会在写入期间创建一个新版本的文件。
- 读取时合并(MOR)– 使用列式(例如 Parquet)和行式(例如 Avro)文件格式的组合来存储数据,旨在显示近乎实时的数据。
存储在 Amazon S3 中的 Hudi 数据集可与其他 AWS 服务本机集成。例如,您可以使用 AWS Glue(请参阅使用 AWS Glue 自定义连接器写入 Apache Hudi 表)或 Amazon EMR(请参阅 Amazon EMR 中可用的 Apache Hudi 新功能)写入 Apache Hudi 表。这些方法需要深入了解 Hudi 的 Spark API,并且需要具备编程技能,这样才能构建和维护数据管道。
在这篇文章中,我展示了另一种使用最少编码处理串流数据的方式。这篇文章中的步骤演示了如何在没有事先了解 Flink 或 Hudi 的情况下使用 SQL 语言构建完全可扩展的管道。通过编写熟悉的 SELECT 查询,您可以查询和浏览多个数据流中的数据。您可以联接来自多个流的数据,然后将结果具体化为 Amazon S3 上的 Hudi 数据集。
解决方案概览
下图提供了本博文中介绍的解决方案的整体架构。我会在后面的章节中详细说明组件和步骤。
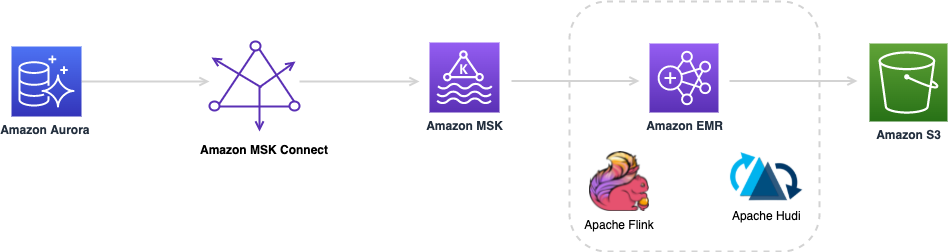
使用 Amazon Aurora MySQL 数据库作为源,并使用具有 MSK Connect 实验中所述设置的 Debezium MySQL 连接器作为更改数据捕获(CDC)复制器。本实验将引导您完成设置堆栈的步骤,以便使用 Amazon MSK Connect 和 MySQL Debezium 源 Kafka 连接器将 Aurora 数据库 salesdb 复制到 Amazon Managed Streaming for Apache Kafka(Amazon MSK)集群。
2021 年 9 月,AWS 宣布 MSK Connect 用于运行完全托管的 Kafka Connect 集群。借助 MSK Connect,只需单击几下,您就可以轻松部署、监控和扩展连接器,这些连接器可将数据从外部系统(例如数据库、文件系统和搜索索引)移入和移出 Apache Kafka 和 MSK 集群。现在,您可以使用 MSK Connect 构建从多个数据库源到 MSK 集群的完整 CDC 管道。
Amazon MSK 是一项完全托管式服务,可用于轻松构建和运行使用 Apache Kafka 处理串流数据的应用程序。使用 Apache Kafka 时,您可以从数据库更改事件或网站点击流等来源捕获实时数据。然后,您可以构建管道(使用 Apache Flink 等流式传输处理框架),将其传输到持久性存储或 Amazon S3 等目标。
Apache Flink 是用于构建有状态流式传输和批处理管道的常用框架。Flink 提供了不同层次的抽象,以涵盖广泛的使用场景。有关更多信息,请参阅 Flink 概念。
Flink 还提供了不同的部署模式,具体取决于您选择的资源提供者(Hadoop YARN、Kubernetes 或独立)。有关详细信息,请参阅部署。
在这篇文章中,我们使用 SQL 客户端工具作为一种用 SQL 语法创作 Flink 任务的交互式方式。sql-client.sh 编译任务并将其提交到 Amazon EMR 上长时间运行的 Flink 集群(会话模式)。根据脚本的不同,sql-client.sh 要么实时显示任务的表格格式输出,要么返回长时间运行任务的任务 ID。
通过以下简要步骤来实现解决方案:
- 创建 EMR 集群。
- 使用 Kafka 和 Hudi 表连接器配置 Flink。
- 开发实时提取、转换和加载(ETL)任务。
- 将管道部署到生产环境中。
先决条件
这篇文章假设您的环境中有一个正在运行的 MSK Connect 堆栈,其中包含以下组件:
- 托管数据库的 Aurora MySQL。在这篇文章中,您将使用示例数据库
salesdb。 - 在 MSK Connect 上运行的 Debezium MySQL 连接器,以 Amazon Virtual Private Cloud(Amazon VPC)中的 Amazon MSK 结尾。
- 在 VPC 中运行的 MSK 集群。
如果您没有 MSK Connect 堆栈,请按照 MSK Connect 实验设置中的说明进行操作,并确认源连接器会将数据更改复制到 MSK 主题。
您还需要能够直接连接到 EMR 领导节点。Session Manager 是 AWS Systems Manager 的一项功能,可为您提供基于浏览器的交互式和一键式 shell 窗口。Session Manager 还使您可以遵守要求对托管节点进行受控访问的公司策略。要了解如何通过此方法连接到账户中的托管节点,请参阅设置 Session Manager。
如果无法选择 Session Manager,您也可以使用 Amazon Elastic Compute Cloud(Amazon EC2)私有密钥对,但您需要在公有子网中启动集群并提供入站 SSH 访问。有关更多信息,请参阅使用 SSH 连接到主节点。
创建 EMR 集群
在撰写本文时,Apache Hudi 的最新发布版本为 0.10.0。Hudi 发行版 0.10.0 与 Flink 发行版 1.13 兼容。您需要 Amazon EMR 发行版 emr-6.4.0 及更高版本,它随 Flink 发行版 1.13 一起提供。要使用 AWS 命令行界面(AWS CLI)启动安装了 Flink 的集群,请完成以下步骤:
- 创建一个包含以下内容的文件
configurations.json: - 在私有子网(推荐)或在托管 MSK 集群的相同 VPC 的公有子网中创建 EMR 集群。使用
--name选项输入集群的名称,并使用--ec2-attributes选项指定 EC2 密钥对的名称和子网 ID。请参阅以下代码: - 等到集群状态变为
Running(正在运行)。 - 使用 Amazon EMR 控制台或 AWS CLI 检索领导节点的 DNS 名称。
- 通过 Session Manager 或在 Linux、Unix 和 Mac OS X 上使用 SSH 和 EC2 私有密钥连接至领导节点。
- 使用 SSH 进行连接时,领导节点的安全组必须允许端口 22。
- 确保 MSK 集群的安全组具有可接受来自 EMR 集群安全组的流量的入站规则。
使用 Kafka 和 Hudi 表连接器配置 Flink
Flink 表连接器使您可以在使用表 API 对流式传输操作编程时连接至外部系统。Source 连接器提供对流式传输服务(包括作为数据源的 Kinesis 或 Apache Kafka)的访问。Sink 连接器允许 Flink 将串流处理结果发送到外部系统或存储服务(例如 Amazon S3)。
在您的 Amazon EMR 领导节点上,下载以下连接器并将其保存在 /lib/flink/lib 目录中:
- Source 连接器 – 从 Apache 存储库下载 flink-connector-kafka_2.11-1.13.1.jar。Apache Kafka SQL 连接器允许 Flink 从 Kafka 主题读取数据。
- Sink 连接器 – Amazon EMR 发行版 emr-6.4.0 随附了 Hudi 发行版 0.8.0。但是,在这篇文章中,您需要 Hudi Flink 捆绑连接器发行版 0.10.0,它与 Flink 发行版 1.13 兼容。从 Apache 存储库下载 hudi-flink-bundle_2.11-0.10.0.jar。它还包含多个文件系统客户端,包括用于与 Amazon S3 集成的 S3A。
开发实时 ETL 任务
在这篇文章中,您使用 Debezium 源 Kafka 连接器将示例数据库 salesdb 的数据更改流式传输到您的 MSK 集群。您的连接器会在 JSON 中生成数据更改。有关更多详细信息,请参阅 Debezium 事件反序列化。Flink Kafka 连接器可以通过在表选项中使用 debezium-json 设置 value.format 来反序列化 JSON 格式的事件。除了插入之外,此配置还提供对数据更新和删除的完全支持。
您可以使用 Flink SQL API 构建一个新的任务。您可以使用这些 API 处理串流数据,类似于关系数据库中的表。此方法中指定的 SQL 查询会持续对源串流中的数据事件运行。由于 Flink 应用程序会消耗来自串流的无界数据,因此输出会不断变化。为了将输出发送到另一个系统,Flink 会向下游 sink 运算符发出更新或删除事件。因此,当您使用 CDC 数据或编写需要更新或删除输出行的 SQL 查询时,必须提供支持这些操作的 sink 连接器。否则,Flink 任务将以错误结束,并显示以下消息:
启动 Flink SQL 客户端
使用之前在 configurations.json 文件中指定的配置在 EMR 集群上启动 Flink YARN 应用程序:
命令成功运行后,您就可以编写第一个任务了。运行以下命令来启动 sql-client:
您的终端窗口看起来像下面的屏幕截图。

设置任务参数
运行以下命令来设置此会话的检查点间隔:
定义源表
从概念上讲,使用 SQL 查询处理串流需要将事件解释为表中的逻辑记录。因此,使用 SQL API 读取或写入数据之前的第一步是创建源表和目标表。表定义包括连接设置和配置,以及定义串流中对象的结构和序列化格式的架构。
在这篇文章中,您将创建三个源表。每个表对应于 Amazon MSK 中的一个主题。您还可以创建一个目标表,将输出数据记录写入存储在 Amazon S3 上的 Hudi 数据集。
在 'properties.bootstrap.servers' 选项中将 BOOTSTRAP SERVERS ADDRESSES 替换为您自己的 Amazon MSK 集群信息,然后在 sql-client 终端中运行以下命令:
默认情况下,sql-client 将这些表存储在内存中。它们仅在活动会话期间有效。每当 sql-client 会话过期或您退出时,都需要重新创建表。
定义 sink 表
以下命令创建目标表。在此表中,指定 'hudi' 作为连接器。其余的 Hudi 配置在 CREATE TABLE 语句的 with (...) 部分中设置。要了解更多信息,请参阅 Flink SQL 配置的完整列表。将 S3URI OF HUDI DATASET LOCATION 替换为 Amazon S3 中的 Hudi 数据集位置,然后运行以下代码:
从多个主题验证 Flink 任务的结果
对于 SELECT 查询,sql-client 会将任务提交给 Flink 集群,然后在屏幕上实时显示结果。运行以下 SELECT 查询以查看您的 Amazon MSK 数据:
此查询联接三个串流,并汇总按每条客户记录分组的客户订单计数。几秒钟后,您应该会在终端中看到结果。注意在 Flink 任务消耗来自源串流的更多事件时终端输出会发生怎样的变化。
将结果汇到 Hudi 数据集中
要获得完整的管道,您需要将结果发送到 Amazon S3 上的 Hudi 数据集。为此,请在 select 查询前面添加一条 insert into CustomerHudi 语句:
这次,sql-client 在提交任务后会断开与集群的连接。客户端终端不必等待任务的结果,因为它会将结果汇入 Hudi 数据集。即使您停止了 sql-client 会话,任务仍会继续在 Flink 集群上运行。
请稍等几分钟,直至任务生成到 Amazon S3 的 Hudi 提交日志文件。然后导航到您在 Amazon S3 中为 CustomerHudi 表指定的位置,这里包含按 MKTSEGMENT 列分区的 Hudi 数据集。在每个分区中,您也可以找到 Hudi 提交日志文件。这是因为您将表类型定义为 MERGE_ON_READ。在这个模式下使用默认配置时,在出现五个增量提交日志后 Hudi 会将提交日志合并到更大的 Parquet 文件中。有关更多信息,请参阅表和查询类型。您可以通过将表类型更改为 COPY_ON_WRITE 或指定自定义压缩配置来更改此设置。
查询 Hudi 数据集
您也可以使用 Hudi Flink 连接器作为 source 连接器,从存储在 Amazon S3 上的 Hudi 数据集读取。为此,您可以对 CustomerHudi 表运行 select 语句,或者为 connector 指定 hudi,创建一个新表。path 必须指向 Amazon S3 上现有 Hudi 数据集的位置。将 S3URI OF HUDI DATASET LOCATION 替换为您的位置,然后运行以下命令创建一个新表:
注意使用 _hoodie_ 前缀的额外列名。这些列由 Hudi 在写入过程中添加,用以维护每条记录的元数据。另请注意表定义的 WITH 部分传递的额外 “hoodie.datasource.query.type” 读取配置。这样可以确保从 Hudi 数据集的实时视图读取。运行以下命令:
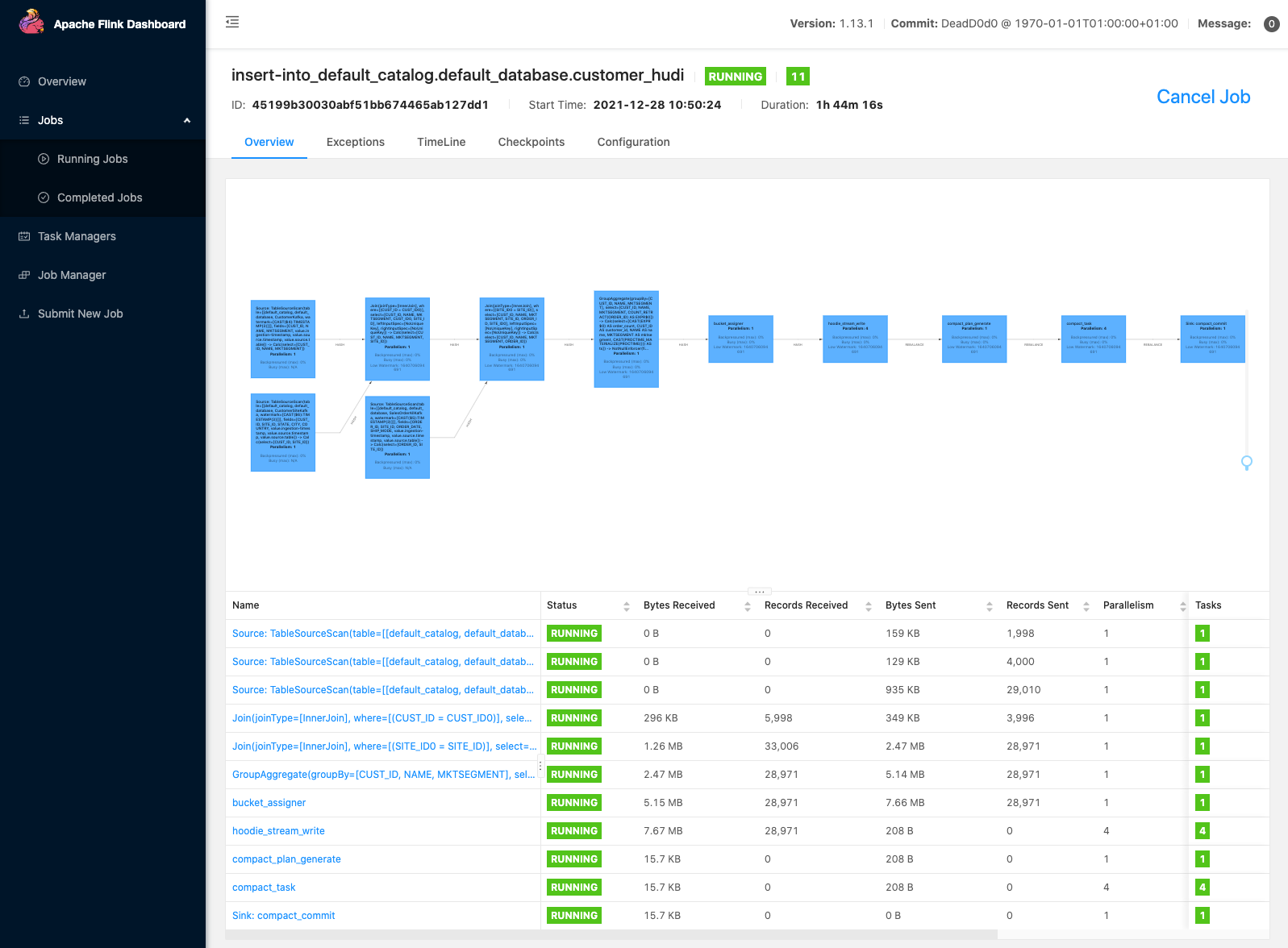
终端会在 30 秒内显示结果。导航到 Flink Web 界面,在这里您可以看到一个由 select 查询启动的新 Flink 任务(请参阅下文,了解如何找到 Flink Web 界面)。它会扫描 Hudi 数据集中提交的文件,并将结果返回给 Flink SQL 客户端。
使用 mysql CLI 或您喜欢的 IDE 连接至托管在 Aurora MySQL 上的 salesdb 数据库。对 SALES_ORDER_ALL 表运行一些 insert 语句:
几秒钟后,Amazon S3 上的 Hudi 数据集中会出现一个新的提交日志文件。Debezium for MySQL Kafka 连接器捕获更改并生成 MSK 主题的事件。Flink 应用程序会使用主题中的新事件,并相应地更新 customer_count 列。然后,它将更改的记录发送到 Hudi 连接器,以便与 Hudi 数据集合并。
Hudi 支持不同的写操作类型。默认操作是 upsert,它最初会将记录插入到数据集中。当过程中出现带有现有密钥的记录时,它将被视为更新。如果您希望将数据集与源数据库同步,并且不出现重复记录,则此操作非常有用。
找到 Flink Web 界面
Flink Web 界面帮助您查看 Flink 任务的配置、图表、状态、异常错误、资源利用率等等。要访问它,首先您需要设置一个 SSH 隧道并在浏览器中激活代理,以便连接到 YARN 资源管理器。在连接到资源管理器之后,您可以选择托管 Flink 会话的 YARN 应用程序。选择 Tracking UI(追踪界面)列下面的链接,导航到 Flink Web 界面。有关更多信息,请参阅找到 Flink Web 界面。
将管道部署到生产环境中
我推荐使用 Flink sql-client 以交互方式快速构建数据管道。它是试验、开发或测试数据管道的不错选择。但是,对于生产环境,我建议将 SQL 脚本嵌入到 Flink Java 应用程序中,然后在 Amazon Kinesis Data Analytics 上运行它。Kinesis Data Analytics 是一项用于运行 Flink 应用程序的完全托管式服务;它具有内置的弹性伸缩和容错能力,可为您的生产应用程序提供所需的可用性和可扩展性。GitHub 上提供了一个 Flink Hudi 应用程序,它包含这篇文章中的脚本。我建议您访问这个存储库,比较一下在 sql-client 和 Kinesis Data Analytics 中运行的区别。
清理
为避免产生持续费用,请完成以下清理步骤:
- 停止 EMR 集群。
- 删除您使用 MSK Connect 实验设置创建的 AWS CloudFormation 堆栈。
结论
构建数据湖是打破数据孤岛和运行分析以从所有数据中获取洞察的第一步。在事务数据库和数据湖中的数据文件之间同步数据并非易事,而且需要花费大量精力。在 Hudi 增加对 Flink SQL API 的支持之前,Hudi 客户必须具备编写 Apache Spark 代码并在 AWS Glue 或 Amazon EMR 上运行代码所需的技能。在这篇文章中,我向您展示了一种新方法,您可以使用 SQL 查询以交互方式了解流式传输服务中的数据,并加快数据管道的开发过程。
要了解更多信息,请访问 Amazon EMR 上的 Hudi 文档。