亚马逊AWS官方博客
使用 AWS CDK 从 Amazon SageMaker JumpStart 部署生成式人工智能模型
机器学习(ML)范式转变的种子已经存在了几十年,但是随着几乎无限的计算容量随时可用、数据的大量激增以及机器学习技术的快速进步,各行各业的客户正在迅速采用和使用机器学习技术来实现业务转型。
就在最近,生成式人工智能应用程序吸引了所有人的注意力和想象力。在机器学习的广泛采用方面,我们确实正处于一个激动人心的转折点,我们相信,每一种客户体验和应用程序都将通过生成式人工智能得到重塑。
生成式人工智能是一种能够创造新内容和新想法的人工智能,包括对话、故事、图像、视频和音乐。与所有人工智能一样,生成式人工智能由机器学习模型提供支持,这些模型是基于庞大的数据语料库进行预训练的超大型模型,通常称为根基模型(FM)。
根基模型的规模和通用性使其有别于传统的机器学习模型,后者通常执行特定任务,如文本情绪分析、图像分类和趋势预测。
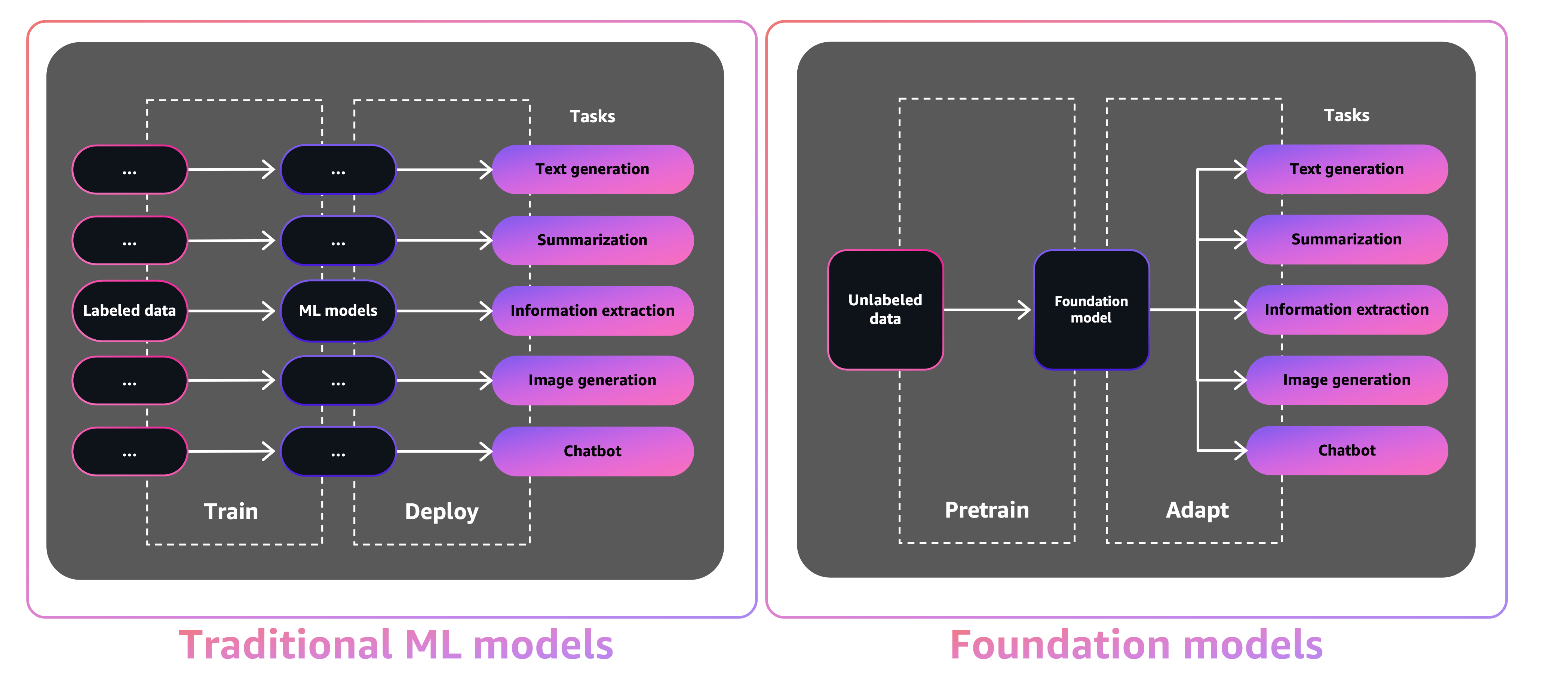
对于传统的机器学习模型,为了完成每项特定任务,您需要收集带标签的数据、训练模型并部署该模型。对于根基模型,您无需为每个模型收集带标签的数据并训练多个模型,而是可以使用相同的预训练根基模型来适应各种任务。您还可以自定义根基模型以执行与您的业务相关的特定领域功能,所使用的数据和计算量仅为从头开始训练模型所需的一小部分。
生成式人工智能有可能通过彻底改变内容的创建和消费方式来颠覆许多行业。原创内容制作、代码生成、客户服务提升和文档摘要是生成式人工智能的典型使用案例。
Amazon SageMaker JumpStart 为各种问题类型提供预训练的开源模型,协助您开始使用机器学习。您可以在部署前逐步训练和调整这些模型。JumpStart 还提供用于为常见使用案例设置基础设施的解决方案模板,以及使用 Amazon SageMaker 进行机器学习的可执行的示例 notebook。
JumpStart 提供 600 多个预训练模型,而且每天都在增加,使开发人员能够快速轻松地将尖端的机器学习技术融入自己的生产工作流程中。您可以通过 Amazon SageMaker Studio 中的 JumpStart 登录页面访问预训练模型、解决方案模板和示例。您也可以使用 SageMaker Python SDK 访问 JumpStart 模型。有关如何以编程方式使用 JumpStart 模型的信息,请参阅在预训练模型中使用 SageMaker JumpStart 算法。
2023 年 4 月,AWS 推出了 Amazon Bedrock,这项服务提供了一种通过 AI21 Labs、Anthropic 和 Stability AI 等初创企业的预训练模型构建生成式人工智能驱动应用程序的方法。Amazon Bedrock 还提供对 Titan 根基模型的访问权限,这是由 AWS 内部训练的一系列模型。借助 Amazon Bedrock 的无服务器体验,您可以轻松找到满足自己需求的模型,快速上手,使用自己的数据私人定制根基模型,并使用您熟悉的 AWS 工具和功能(包括与 SageMaker 机器学习功能的集成,如用于测试不同模型的 Amazon SageMaker Experiments 和用于大规模管理根基模型的 Amazon SageMaker Pipelines)轻松将这些模型集成并部署到您的应用程序中,而无需管理任何基础设施。
在这篇文章中,我们将展示如何使用 AWS Cloud Development Kit(AWS CDK)从 JumpStart 部署图像和文本生成式人工智能模型。AWS CDK 是一个开源软件开发框架,用于使用 Python 等熟悉的编程语言定义云应用程序资源。
我们从 JumpStart 的 Hugging Face 中,使用 Stable Diffusion 模型进行图像生成操作,使用 FLAN-T5-XL 模型进行自然语言理解(NLU)和文本生成操作。
解决方案概览
Web 应用程序基于 Streamlit 构建,Streamlit 是一个开源 Python 库,可轻松创建和共享用于机器学习和数据科学的完美定制 Web 应用程序。我们使用 Amazon Elastic Container Service(Amazon ECS)和 AWS Fargate 托管 Web 应用程序,并通过应用程序负载均衡器访问这种应用程序。Fargate 是一种技术,可与 Amazon ECS 配合使用,无需管理服务器、集群或虚拟机即可运行容器。生成式人工智能模型端点是从 Amazon Elastic Container Registry(Amazon ECR)中的 JumpStart 映像启动的。模型数据存储在 JumpStart 账户中的 Amazon Simple Storage Service(Amazon S3)上。Web 应用程序通过 Amazon API Gateway 和 AWS Lambda 函数与模型进行交互,如下图所示。
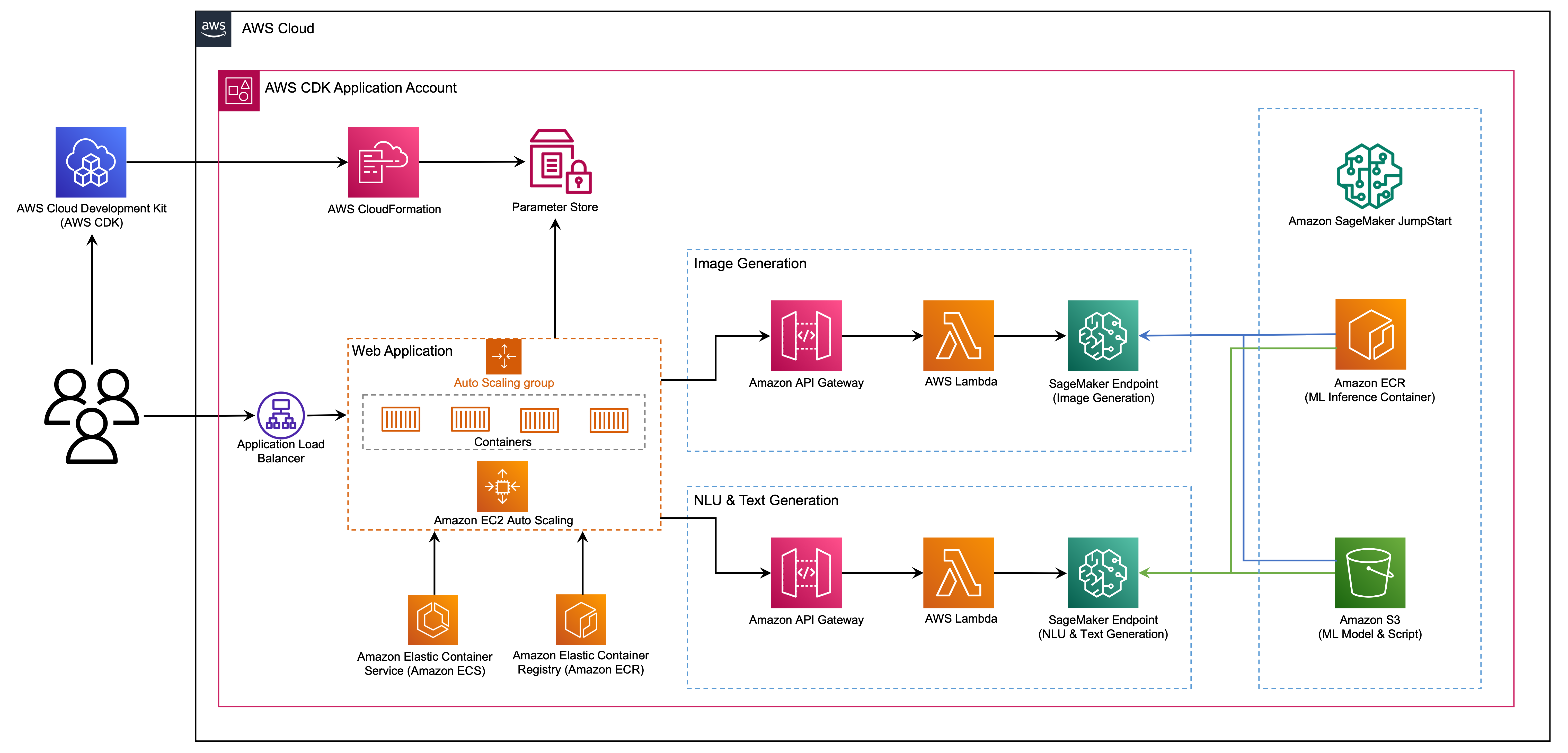
API Gateway 为 Web 应用程序和其他客户端提供标准的 RESTful 接口,同时屏蔽与模型接口的 Lambda 函数。这简化了使用模型的客户端应用程序代码。在此示例中,API Gateway 端点可公开访问,因此可以扩展此架构来实施不同的 API 访问控制并与其他应用程序集成。
在这篇文章中,我们将引导您完成以下步骤:
- 在本地计算机上安装 AWS 命令行界面(AWS CLI)和 AWS CDK v2。
- 克隆并设置 AWS CDK 应用程序。
- 部署 AWS CDK 应用程序。
- 使用图像生成人工智能模型。
- 使用文本生成人工智能模型。
- 在 AWS 管理控制台上查看已部署的资源。
我们在这篇文章末尾的附录中概述了这个项目中的代码。
先决条件
您必须具备以下先决条件:
- AWS 账户
- AWS CLI v2
- Python 3.6 或更高版本
- node.js 14.x 或更高版本
- AWS CDK v2
- Docker v20.10 或更高版本
您可以从本地计算机部署本教程中的基础设施,也可以使用 AWS Cloud9 作为部署工作站。AWS Cloud9 预装了 AWS CLI、AWS CDK 和 Docker。如果选择 AWS Cloud9,请从 AWS 控制台创建环境。
假设您让资源运行 8 个小时,完成这篇文章的估计费用为 50 美元。请务必删除在这篇文章中创建的资源,避免持续收费。
在本地计算机上安装 AWS CLI 和 AWS CDK
如果本地计算机上还没有 AWS CLI,请参阅安装或更新 AWS CLI 的最新版本以及配置 AWS CLI。
使用以下节点软件包管理器命令全局安装 AWS CDK 工具包:
运行以下命令,验证安装是否正确并打印 AWS CDK 的版本号:
确保在本地计算机上安装了 Docker。发出以下命令以验证版本:
克隆并设置 AWS CDK 应用程序
在本地计算机上,使用以下命令克隆 AWS CDK 应用程序:
导航到项目文件夹:
在部署应用程序之前,让我们回顾一下目录结构:
stack 文件夹包含 AWS CDK 应用程序中每个堆栈的代码。code 文件夹包含 Lambda 函数的代码。存储库还包含位于 web-app 文件夹下的 Web 应用程序。
cdk.json 文件告诉 AWS CDK 工具包如何运行应用程序。
此应用程序在 us-east-1 区域中进行了测试,但此应用程序应适用于任何在 app.py 中指定了所需服务和推理实例类型 ml.g4dn.4xlarge 的区域。
设置虚拟环境
此项目的设置与标准 Python 项目类似。使用以下代码创建 Python 虚拟环境:
使用以下命令激活虚拟环境:
如果您使用的是 Windows 平台,请按如下方式激活虚拟环境:
激活虚拟环境后,将 pip 升级到最新版本:
安装所需的依赖项:
在部署任何 AWS CDK 应用程序之前,需要在您的账户和要部署到的区域中引导空间。要在默认区域中进行引导,请发出以下命令:
如果要部署到特定账户和区域,请发出以下命令:
有关此设置的更多信息,请访问 AWS CDK 入门。
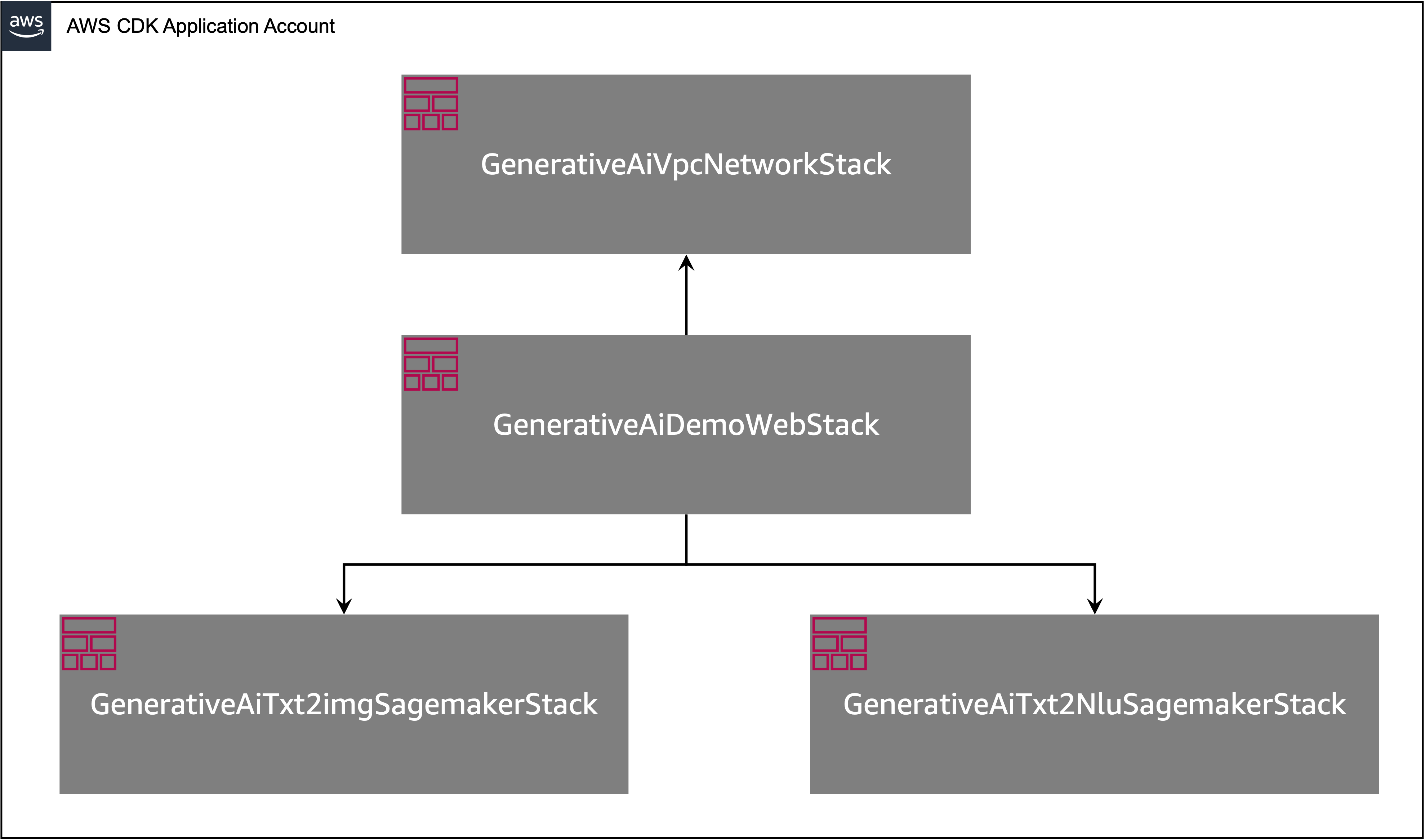
AWS CDK 应用程序堆栈结构
AWS CDK 应用程序包含多个堆栈,如下图所示。
可以使用以下命令列出 AWS CDK 应用程序中的堆栈:
以下是其他有用的 AWS CDK 命令:
- cdk ls – 列出应用程序中的所有堆栈
- cdk synth – 发出合成的 AWS CloudFormation 模板
- cdk deploy – 将此堆栈部署到默认 AWS 账户和区域
- cdk diff – 将已部署的堆栈与当前状态进行比较
- cdk docs – 打开 AWS CDK 文档
下一节将向您展示如何部署 AWS CDK 应用程序。
部署 AWS CDK 应用程序
AWS CDK 应用程序将根据工作站配置部署到默认区域。如果您想在特定区域强制部署,请相应地设置 AWS_DEFAULT_REGION 环境变量。
此时,您可以部署 AWS CDK 应用程序。首先启动 VPC 网络堆栈:
如果出现提示,请输入 y 继续部署。您应该会看到堆栈中正在预置的 AWS 资源列表。此步骤大约需要 3 分钟才能完成。
然后启动 Web 应用程序堆栈:
分析堆栈后,AWS CDK 将显示堆栈中的资源列表。输入 y 继续部署。此步骤大约需要 5 分钟。
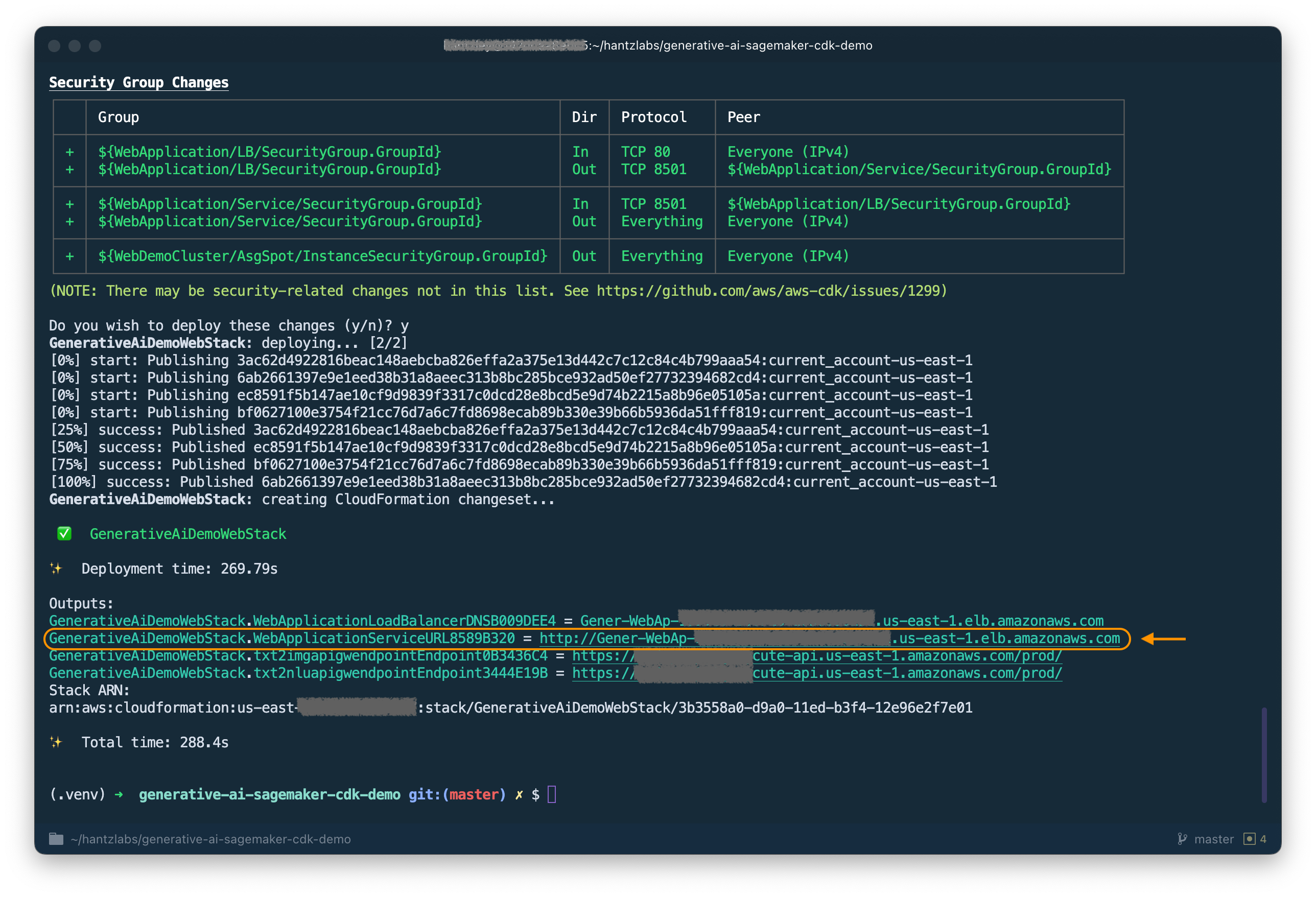
记下输出中的 WebApplicationServiceURL 以便稍后使用。您也可以在 AWS CloudFormation 控制台的 GenerativeAiDemoWebStack 堆栈输出中进行检索。
现在,启动图像生成人工智能模型端点堆栈:
此步骤大约需要 8 分钟。图像生成模型端点已部署,我们现在可以使用此端点。
使用图像生成人工智能模型
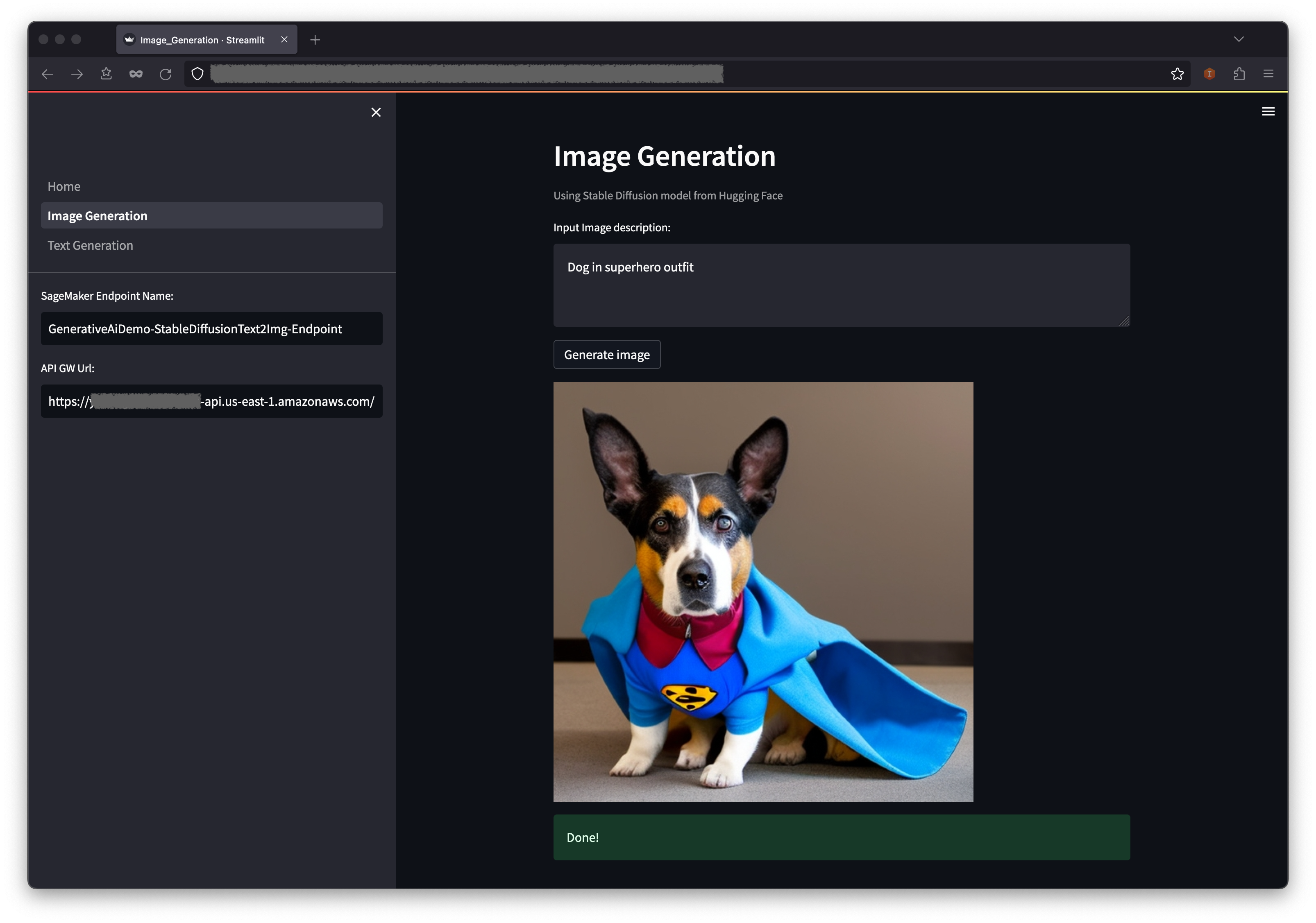
第一个示例演示了如何使用 Stable Diffusion,这是一种功能强大的生成式建模技术,可以根据文本提示创建高质量的图像。
- 在浏览器中使用
GenerativeAiDemoWebStack输出中的WebApplicationServiceURL访问 Web 应用程序。
- 在导航窗格中,选择图像生成。
- SageMaker 端点名称和 API GW Url 字段将预先填入,但您可以根据需要更改图像描述的提示。
- 选择生成图像。
- 应用程序将调用 SageMaker 端点。这需要几秒钟时间。此时将显示一张具有图像描述中的特征的图片。
使用文本生成人工智能模型
第二个示例围绕着使用 FLAN-T5-XL 模型(一种根基模型或大型语言模型(LLM))实现文本生成的上下文学习,同时还解决了广泛的自然语言理解(NLU)和自然语言生成(NLG)任务。
某些环境可能会限制一次启动的端点数量。在这种情况下,您可以一次启动一个 SageMaker 端点。要在 AWS CDK 应用程序中停止 SageMaker 端点,必须先销毁已部署的端点堆栈,然后再启动其他端点堆栈。要关闭图像生成人工智能模型端点,请发出以下命令:
然后启动文本生成人工智能模型端点堆栈:
在提示符处输入 y。
启动文本生成模型端点堆栈后,完成以下步骤:
- 返回 Web 应用程序,然后在导航窗格中选择文本生成。
- 输入上下文字段预填充的是客户与座席之间关于客户电话问题的对话,但您也可以根据需要输入自己的上下文。
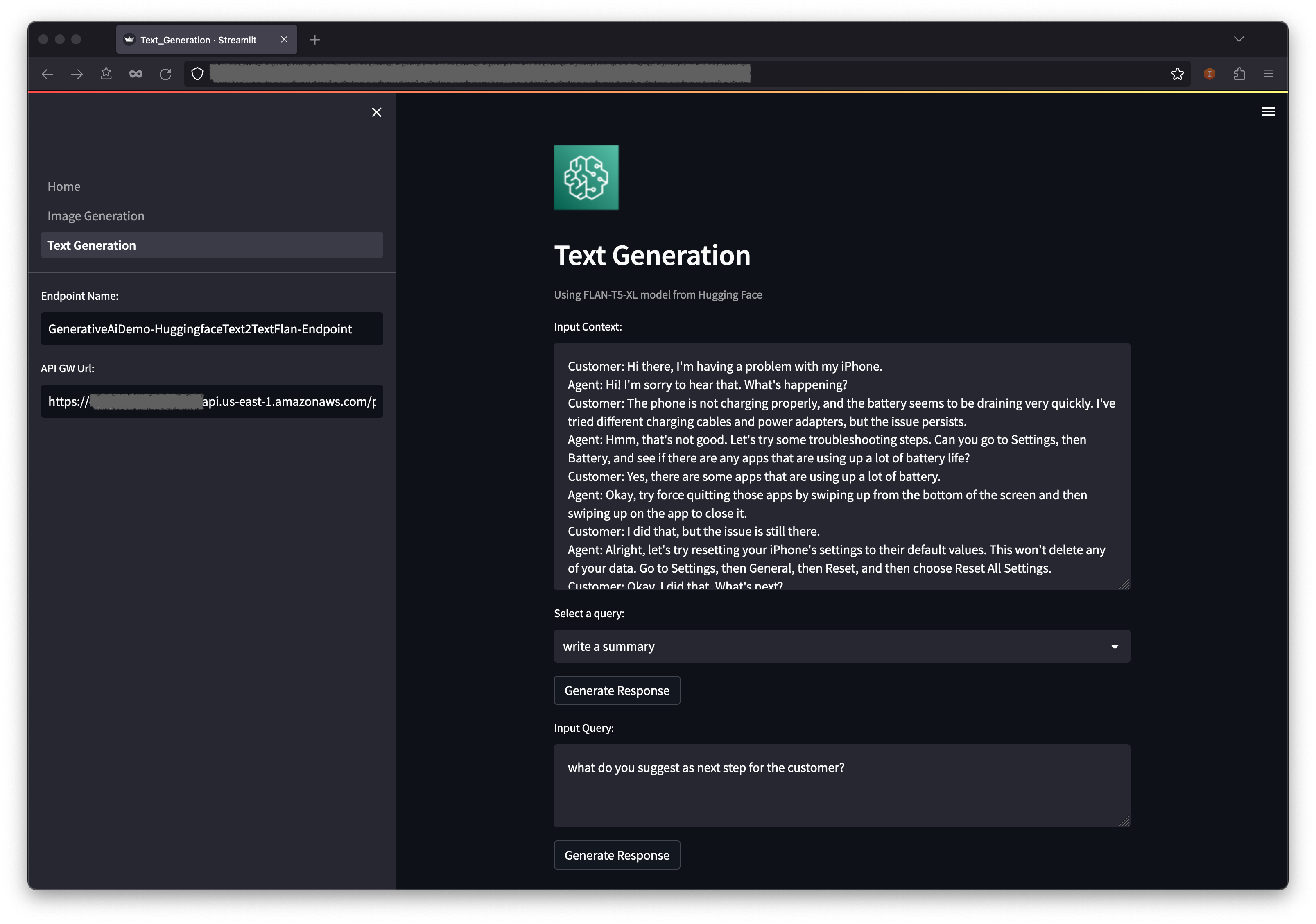
- 在上下文下方的下拉菜单中,您可以找到一些预填充的查询。选择一个查询,然后选择生成响应。
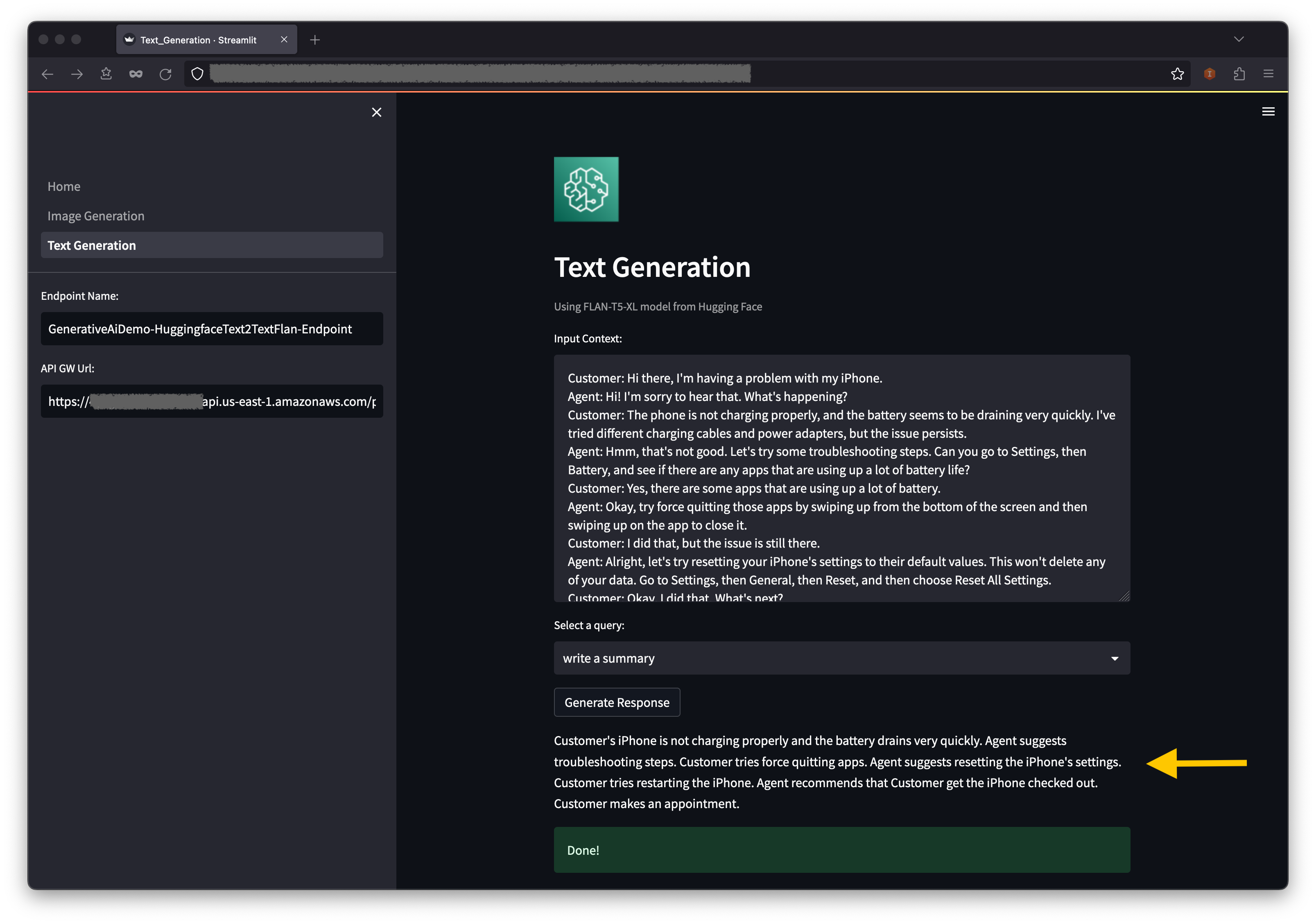
- 您也可以在输入查询字段中输入自己的查询,然后选择生成响应。
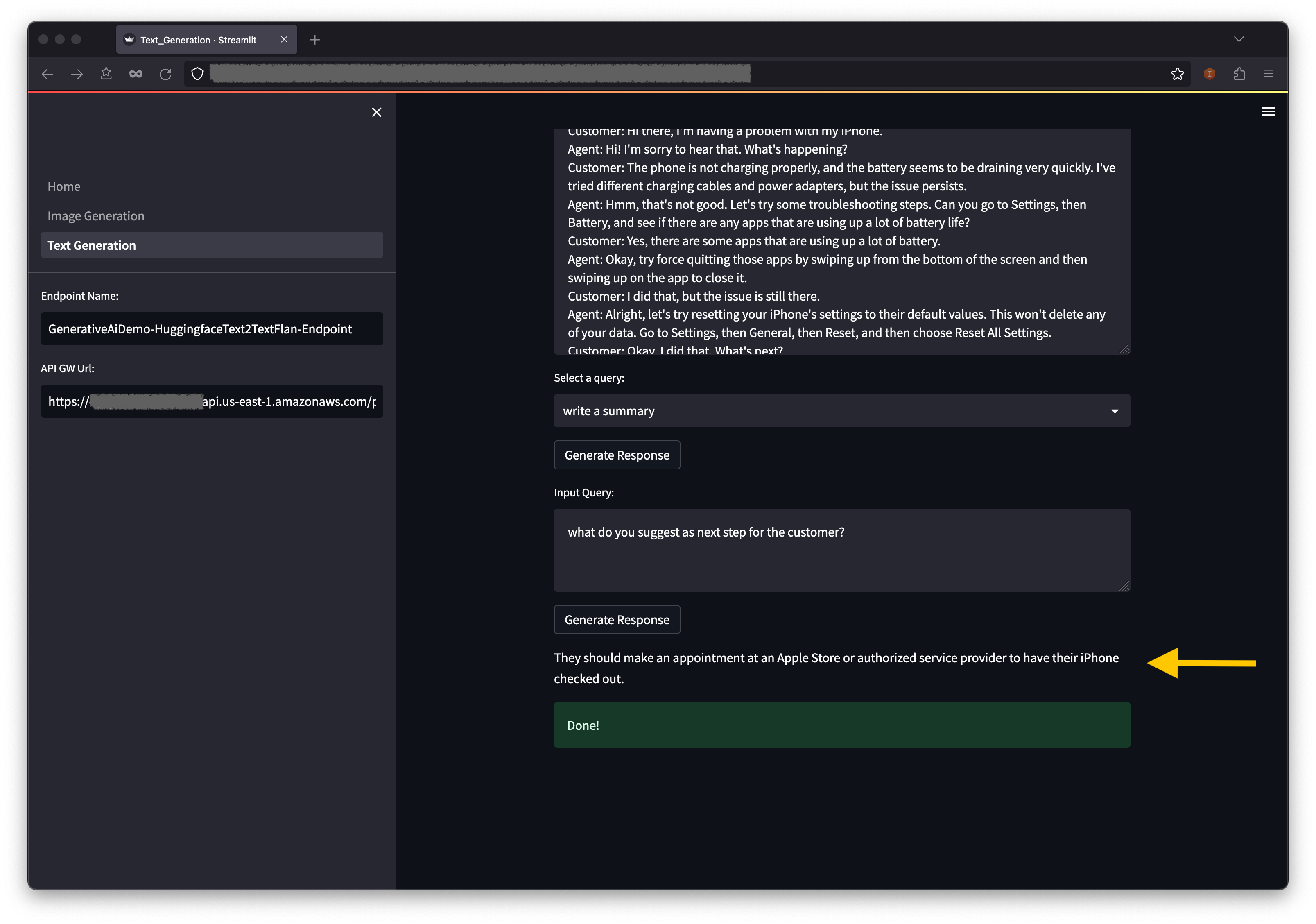
在控制台上查看已部署的资源
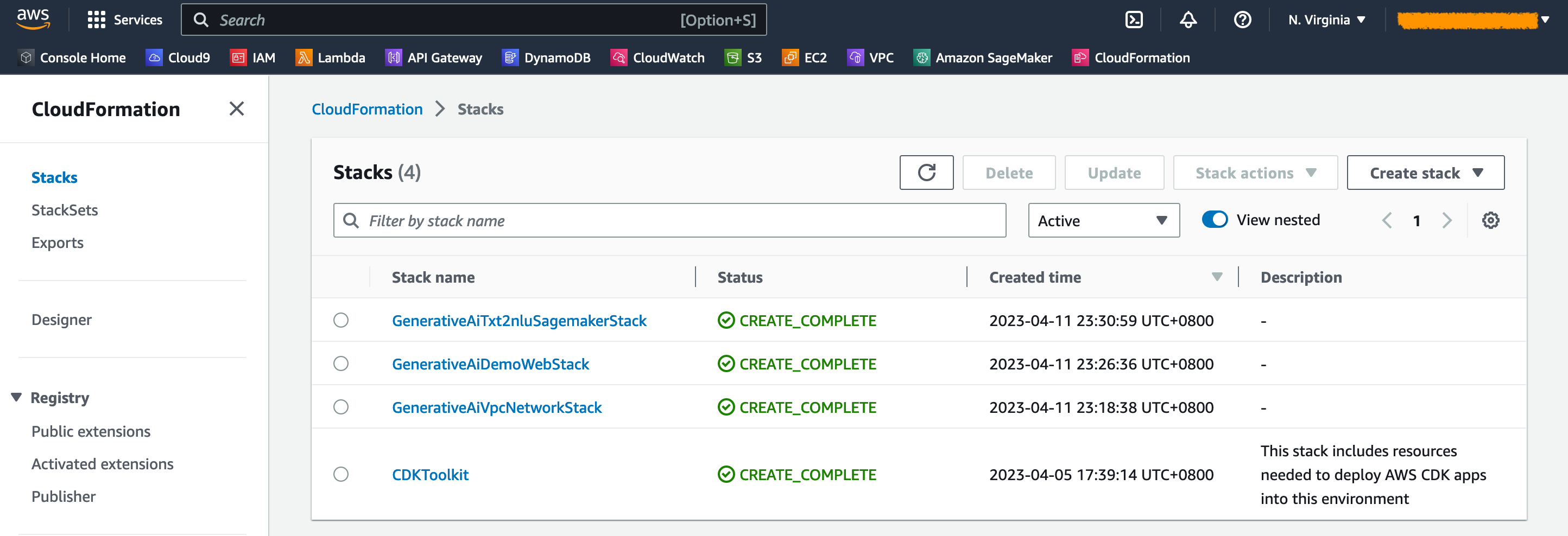
在 AWS CloudFormation 控制台上,选择导航窗格中的堆栈以查看部署的堆栈。
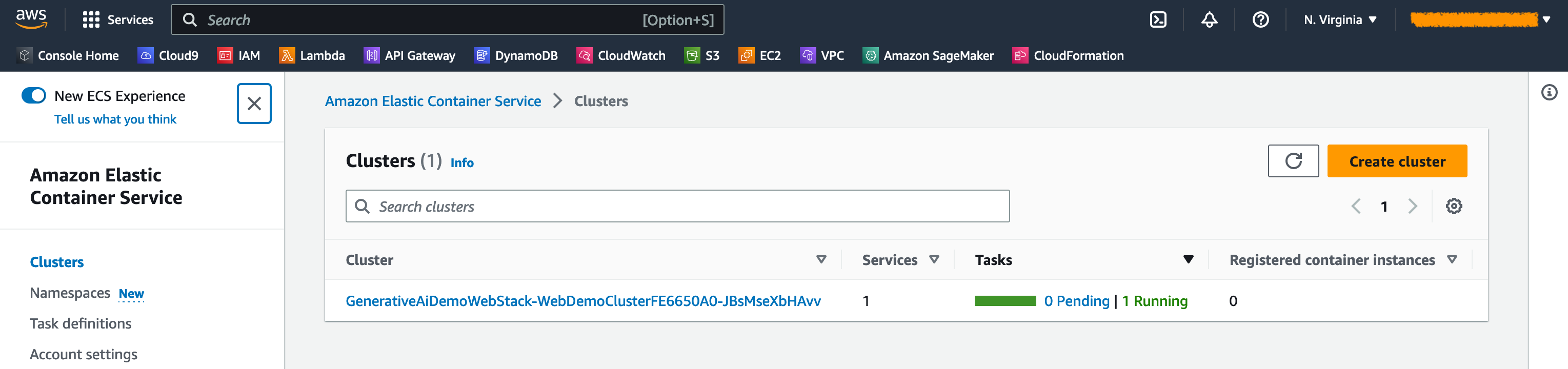
在 Amazon ECS 控制台上,您可以在集群页面上查看集群。
在 AWS Lambda 控制台上,您可以在函数页面上查看函数。
在 API Gateway 控制台上,您可以在 API 页面上查看 API Gateway 端点。
在 SageMaker 控制台上,您可以在端点页面上查看已部署的模型端点。
启动堆栈时,会生成一些参数。这些参数存储在 AWS Systems Manager Parameter Store 中。要查看这些参数,请在 AWS Systems Manager 控制台的导航窗格中选择 Parameter Store。
清理
为避免不必要的成本,请在工作站上使用以下命令清理创建的所有基础设施:
在提示符处输入 y。此步骤大约需要 10 分钟。检查控制台上的所有资源是否都已删除。同时删除 AWS CDK 在 Amazon S3 控制台上创建的资产 S3 存储桶以及 Amazon ECR 上的资产存储库。
总结
如本文所示,您可以使用 AWS CDK 在 JumpStart 中部署生成式人工智能模型。我们展示了使用由 Streamlit、Lambda 和 API Gateway 提供支持的用户界面的图像生成示例和文本生成示例。
现在,您可以在 JumpStart 中使用预训练的人工智能模型来构建生成式人工智能项目。您还可以扩展此项目,针对自己的使用案例对根基模型进行微调,并控制对 API Gateway 端点的访问。
我们邀请您在 GitHub 上测试解决方案并为此项目做出贡献。请在评论中分享您对本教程的看法!
许可证摘要
此示例代码根据修改后的 MIT 许可证提供。有关更多信息,请参阅 LICENSE 文件。另外,请查看 Hugging Face 上 stable diffusion 和 flan-t5-xl 模型的相应许可证。
Original URL: https://aws.amazon.com/blogs/machine-learning/deploy-generative-ai-models-from-amazon-sagemaker-jumpstart-using-the-aws-cdk/
关于作者
 Hantzley Tauckoor 是 APJ 合作伙伴解决方案架构负责人,常驻新加坡。他在信息通信技术行业拥有 20 年的工作经验,涉及多个职能领域,包括解决方案架构、业务发展、销售策略、咨询和领导能力。他领导着一支由高级解决方案架构师组成的团队,协助合作伙伴开发联合解决方案,培养技术能力,并在客户将应用程序迁移到 AWS 并实现应用程序现代化的过程中,指导合作伙伴完成实施阶段。
Hantzley Tauckoor 是 APJ 合作伙伴解决方案架构负责人,常驻新加坡。他在信息通信技术行业拥有 20 年的工作经验,涉及多个职能领域,包括解决方案架构、业务发展、销售策略、咨询和领导能力。他领导着一支由高级解决方案架构师组成的团队,协助合作伙伴开发联合解决方案,培养技术能力,并在客户将应用程序迁移到 AWS 并实现应用程序现代化的过程中,指导合作伙伴完成实施阶段。
 Kwonyul Choi 是总部位于首尔的韩国美容护理平台初创企业 BABITALK 的首席技术官。在此之前,Kownyul 曾在 AWS 担任软件开发工程师,专注于 AWS CDK 和 Amazon SageMaker。
Kwonyul Choi 是总部位于首尔的韩国美容护理平台初创企业 BABITALK 的首席技术官。在此之前,Kownyul 曾在 AWS 担任软件开发工程师,专注于 AWS CDK 和 Amazon SageMaker。
 Arunprasath Shankar 是 AWS 的高级人工智能/机器学习专业解决方案架构师,协助全球客户在云中有效、高效地扩展人工智能解决方案。在业余时间,Arun 喜欢看科幻电影和听古典音乐。
Arunprasath Shankar 是 AWS 的高级人工智能/机器学习专业解决方案架构师,协助全球客户在云中有效、高效地扩展人工智能解决方案。在业余时间,Arun 喜欢看科幻电影和听古典音乐。
 Satish Upreti 是亚太地区合作伙伴组织的 PSA 迁移负责人和安全专家。Satish 在本地私有云和公有云技术领域拥有 20 年的丰富经验。自 2020 年 8 月以迁移专家的身份加入 AWS 以来,他为 AWS 合作伙伴提供了广泛的技术建议和支持,协助他们规划和实施复杂的迁移。
Satish Upreti 是亚太地区合作伙伴组织的 PSA 迁移负责人和安全专家。Satish 在本地私有云和公有云技术领域拥有 20 年的丰富经验。自 2020 年 8 月以迁移专家的身份加入 AWS 以来,他为 AWS 合作伙伴提供了广泛的技术建议和支持,协助他们规划和实施复杂的迁移。
附录:代码演练
在本节中,我们将概述此项目中的代码。
AWS CDK 应用程序
AWS CDK 主应用程序包含在根目录下的 app.py 文件中。此项目由多个堆栈组成,因此我们必须导入这些堆栈:
我们定义生成式人工智能模型,并从 SageMaker 获取相关的 URI:
函数 get_sagemaker_uris 从 JumpStart 检索所有模型信息。请参阅 script/sagemaker_uri.py。
然后,我们实例化堆栈:
首先启动的堆栈是 VPC 堆栈 GenerativeAiVpcNetworkStack。Web 应用程序堆栈 GenerativeAiDemoWebStack 依赖于 VPC 堆栈。依赖关系是通过参数传递 vpc=network_stack.vpc 实现的。
有关完整代码,请参阅 app.py。
VPC 网络堆栈
在 GenerativeAiVpcNetworkStack 堆栈中,我们创建一个 VPC,其公有子网和私有子网跨两个可用区:
有关完整代码,请参阅 /stack/generative_ai_vpc_network_stack.py。
Web 应用程序堆栈演示
在 GenerativeAiDemoWebStack 堆栈中,我们启动 Lambda 函数和相应的 API Gateway 端点,Web 应用程序通过这些端点与 SageMaker 模型端点进行交互。请参阅以下代码片段:
Web 应用程序经过容器化并通过 Fargate 托管在 Amazon ECS 上。请参阅以下代码片段:
有关完整代码,请参阅 /stack/generative_ai_demo_web_stack.py。
图像生成 SageMaker 模型端点堆栈
GenerativeAiTxt2imgSagemakerStack 堆栈从 JumpStart 创建图像生成模型端点,并将端点名称存储在 Systems Manager Parameter Store 中。Web 应用程序将使用此参数。请参阅以下代码:
有关完整代码,请参阅 /stack/generative_ai_txt2img_sagemaker_stack.py。
NLU 和文本生成 SageMaker 模型端点堆栈
GenerativeAiTxt2nluSagemakerStack 堆栈从 JumpStart 创建 NLU 和文本生成模型端点,并将端点名称存储在 Systems Manager Parameter Store 中。Web 应用程序也将使用此参数。请参阅以下代码:
有关完整代码,请参阅 /stack/generative_ai_txt2nlu_sagemaker_stack.py。
Web 应用程序
Web 应用程序位于 /web-app 目录中。这是一个 Streamlit 应用程序,根据 Dockerfile 进行了容器化:
要了解有关 Streamlit 的更多信息,请参阅 Streamlit 文档。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。