亚马逊AWS官方博客
推出 Amazon Neptune Serverless — 一个完全托管的图形数据库,可为您的工作负载调整容量
Amazon Neptune 是一项完全托管的图形数据库服务,可帮助您轻松构建和运行使用高度互连数据集的应用程序。借助 Neptune,您可以使用开放和流行的图形查询语言来执行功能强大的查询,这些查询易于编写且在互联数据上表现良好。您可以将 Neptune 用于图表用例,例如推荐引擎、欺诈检测、知识图表、药物发现和网络安全。
Neptune 始终处于全面管理中,因而可处理耗时的任务,例如配置、补丁、备份、恢复、故障检测和修复。但是,管理数据库容量以获得最佳成本和性能需要您在工作负载特征发生变化时监控和重新配置容量。此外,许多应用程序具有大小不一或不可预测的工作负载,对于这些工作负载,数据库查询的数量和复杂性可能会发生显著变化。例如,社交媒体知识图谱应用程序的查询量可能会由于突然人气暴涨而激增。
推出 Amazon Neptune Serverless
今天,随着 Amazon Neptune Serverless 的推出,这一点将变得更加容易。Neptune Serverless 会随着您的查询和工作负载的变化自动扩缩,以精细的增量调整容量,以提供应用程序所需的恰当数量的数据库资源。这样,您只需为所用容量付费。您可以将 Neptune Serverless 用于开发、测试和生产工作负载,与预置峰值容量相比,可以最大限度降低数据库成本。
使用 Neptune Serverless,您可以快速、经济高效地为现代应用程序部署图表。您可以从一个小图开始,随着工作负载的增加,Neptune Serverless 将自动无缝扩展您的图形数据库以提供所需的性能。您无需管理数据库容量,而且现在可以运行图表应用程序,而不会造成因过度配置而导致成本增加或配置不足导致容量不足的风险。
使用 Neptune Serverless,您可以继续使用 Neptune 中已经推出的相同查询语言(Apache TinkerPop Gremlin、openCypher 和 RDF/SPARQL)和功能(例如快照、直播、高可用性和数据库克隆)。
我们来看看这些步骤的实际操作。
创建 Amazon Neptune Serverless 数据库
在 Neptune 控制台中,我选择导航窗格中的数据库,然后选择创建数据库。对于引擎类型,我选择 Serverless 并输入 my-database作为 DB(数据库)集群标识符。

我现在可以根据自己的工作负载配置 Neptune Serverless 可以使用的容量范围,以 Neptune 容量单位(NCU)表示。我现在可以选择一个模板来配置一些后续选项。我选择了 Production(生产)模板,该模板默认情况下会在不同的可用区中创建只读副本。Development and Testing(开发和测试)模板将通过没有只读副本和允许访问提供容量暴增的数据库实例来优化我的成本。


最后,我选择创建数据库。几分钟后,数据库就可以使用了。在数据库列表中,我选择数据库标识符来获取 Writer(写入器)和 Reader(阅读器)端点,稍后我将使用这些端点来访问数据库。
使用 Amazon Neptune Serverless
与配置的 Neptune 数据库相比,使用 Neptune Serverless 的方式并无区别。我可以使用 Neptune 支持的任何查询语言。在本演练中,我选择使用 openCypher,这是一种用于属性图的声明式查询语言,最初由 Neo4j 开发,于 2015 年开源,为 openCypher 项目做出了贡献。
为了连接到数据库,我在同一 AWS 区域启动了一个 Amazon Linux Amazon Elastic Compute Cloud (Amazon EC2) 实例,并将默认安全组和使我获得 SSH 访问权限得第二个安全组关联起来。
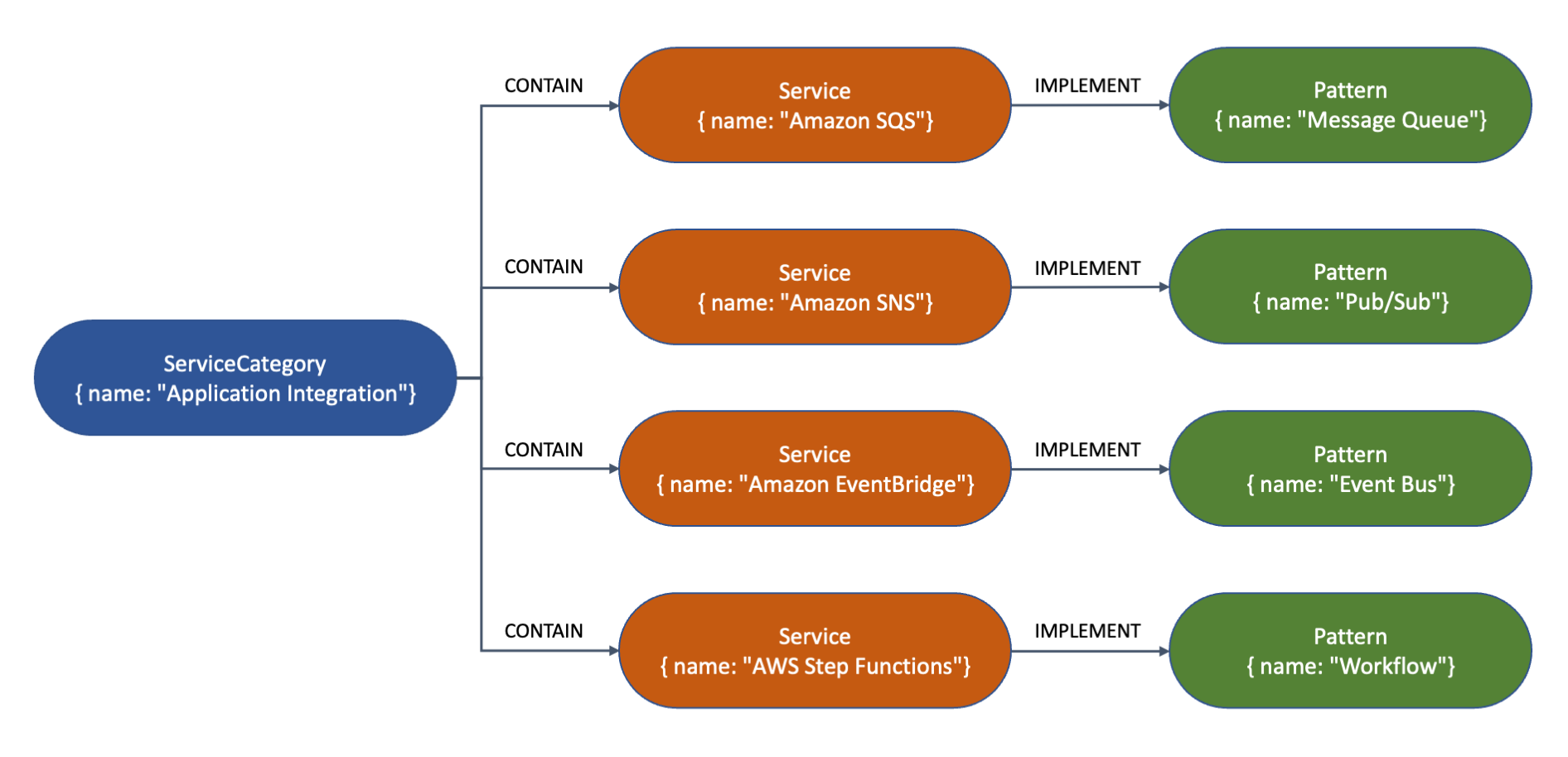
通过属性图,我可以表示连接的数据。在此情况下,我想创建一个简单的图表,显示某些 AWS 服务是如何成为服务类别的一部分,以及实施常见的企业集成模式。
我使用 curl 来访问 Writer(写入器)openCypher HTTPS 端点,然后创建几个代表模式、服务和服务类别的节点。为提高可读性,以下命令分为多行。
这是上一个命令创建的图表中节点及其关系的直观表示。类型(例如服务或模式)和属性(例如名称)均在每个节点内显示。箭头表示节点之间的关系,例如 CONTAIN(包含)或 IMPLEMENT(实现)。
现在,我查询数据库以获得一些洞察。要查询数据库,我可以使用写入器或读取器端点。首先,我想知道实现“消息队列”模式的服务的名称。请注意 openCypher 的语法与使用 MATCH 而非 SELECT 的 SQL 语法的相似之处。
{
"results" : [ {
"s.name" : "Amazon SQS"
} ]
}我使用以下查询来查看“应用程序集成”类别中有多少服务。这次,我使用 WHERE 子句来筛选结果。
{
"results" : [ {
"count(s)" : 4
} ]
}现在我已启动并运行了这个图形数据库,现在有许多选项。我可以在节点之间添加更多数据(服务、类别、模式)和更多关系。我可以专注于我的应用程序,让 Neptune Serverless 为我管理容量和基础架构。
可用性和定价
Amazon Neptune Serverless 现已在以下 AWS 区域上市:美国东部(俄亥俄州、弗吉尼亚北部)、美国西部(加利福尼亚北部、俄勒冈)、亚太地区(东京)和欧洲(爱尔兰、伦敦)。
使用 Neptune Serverless,您只需按实际用量付费。数据库容量经过调整,以 Neptune 容量单位(NCU)为单位提供所需的适量资源。每个 NCU 由大约 2 吉字节(GiB)的内存、相应的 CPU 和网络组成。NCU 的使用按秒计费。有关更多信息,请参阅 Neptune 定价页面。
拥有无服务器图形数据库开辟了许多新的可能性。要了解更多信息,请参阅 Neptune Serverless 文档。欢迎与我们分享您使用此新功能构建了什么!
使用 Neptune Serverless 简化处理高度连接数据的方式。
— Danilo