Amazon DataZone: Integrations
Amazon DataZone integrations are split into four categories:
Producer data sources
Publish data from built-in data sources for the AWS Glue Data Catalog and Amazon Redshift. For all other types of sources, you can define a custom asset type and use Amazon DataZone public APIs to publish those assets. For the integration with AWS Glue data quality, the data source can be used to bring in the data quality scores on a schedule.
Analytics tools
Work with services like Amazon Athena and Amazon Redshift Query Editor so that you can work directly with data from the query editors. This capability is easily extensible using APIs to customize other third-party tools. Amazon DataZone can share project access context with these tools.
Access fulfillment
Automatically fulfill and manage permissions for AWS Lake Formation managed AWS Glue tables and Amazon Redshift tables and views. For all other assets, Amazon DataZone emits standard events related to user actions, such as subscription requests or approvals. You can use these standard events to integrate with other AWS services or third-party solutions for custom integrations.
Machine learning (ML) tools
Work with Amazon SageMaker to easily gain access to data and ML assets. You can easily perform ML tasks and publish newly created data and ML assets to your business data catalog. Learn more about how Amazon SageMaker supports ML governance.
Key features
Open all-
Catalog data that resides in the AWS Glue Data Catalog or Amazon Redshift with rich metadata and business context. Through AWS Glue connectors, Amazon DataZone can access data across AWS, third-party services, on premises, and other services through Amazon AppFlow.
-
Amazon DataZone automates Lake Formation to help data consumers access controls for the requested resources. For Amazon DataZone managed assets, fulfillment of data access to the underlying tables (according to the policies applied by data publishers) is taken care of without the need for an administrator or data movement.
-
Give seamless access to analytics tools, such as Amazon Athena and Amazon Redshift Query Editor, to analysts and line-of-business end users to discover, prepare, transform, analyze, and visualize data. Users get a personalized view of their data with an out-of-console application or APIs.
-
Make it easy for users to govern access to infrastructure, data, and ML resources based on a business problem. By integrating the ML building experience from Amazon SageMaker Studio with data governance capabilities from Amazon DataZone, users can catalog, discover, share, and access data and ML assets.
Govern data in your data lakes
Centrally manage and scale fine-grained data access permissions with AWS.
View the infographic
Metadata management with Amazon DataZone and AWS Glue
You may already be using AWS Glue Data Catalog to manage your technical metadata. Learn how to manage a technical metadata catalog that integrates with a business data catalog by combining AWS Glue Data Catalog and Amazon DataZone.
Amazon DataZone and AWS Glue for metadata management
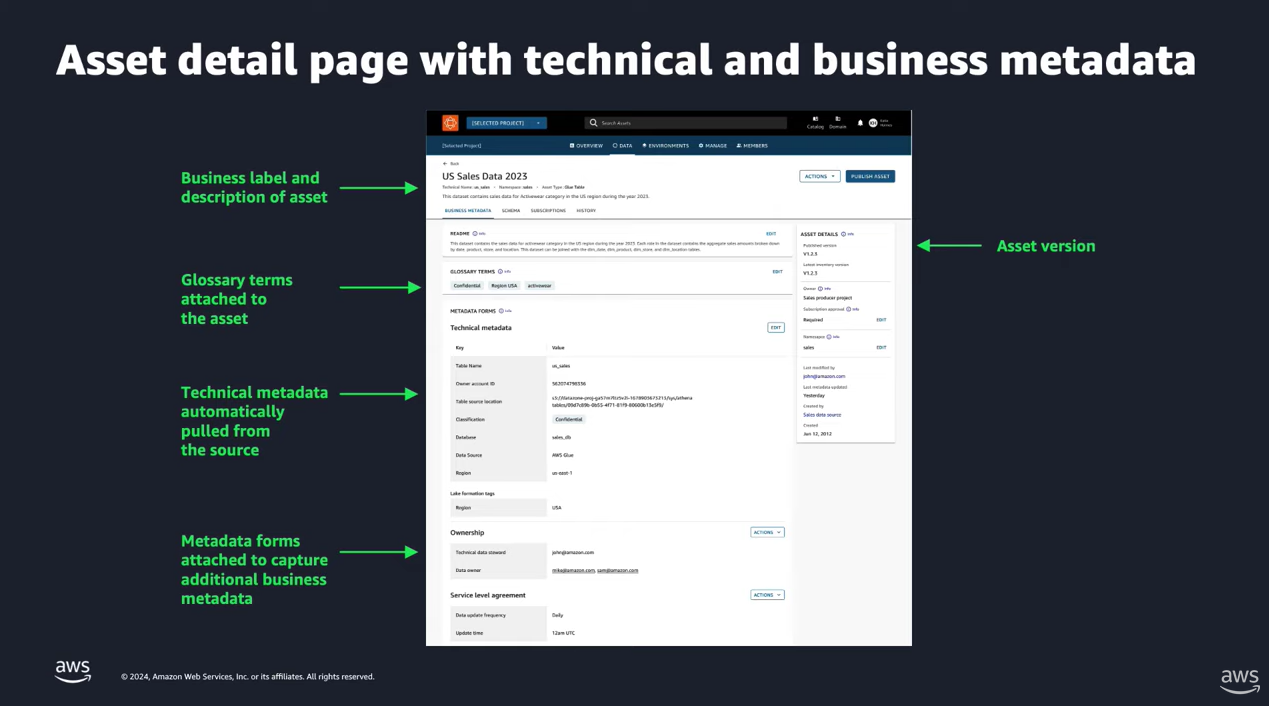
Unify your data landscape by managing metadata with Amazon DataZone and AWS Glue
You need a robust, holistic metadata management solution to make your data discoverable for users, engines, and models. Streamline discovery, management, and analysis with Amazon DataZone and AWS Glue Data Catalog.
View the infographic