Amazon Web Services ブログ
Category: Database

【開催報告】第9回鉄道技術展2025 AWS出展報告
2025年11月26日から29日の4日間、千葉県の幕張メッセにて「第9回鉄道技術展2025(Mass-Tran […]

AWS Game Dev Toolkit でゲーム開発インフラ構築を簡単に
本記事は、2026年 1 月 22 日に公開された “Game development infrastruct […]

AWS で DER アグリゲーター向けのスケーラブルな DERMS ソリューションを構築する
エネルギー環境が分散型モデルへと進化する中、分散型エネルギーリソース (DER) は、エネルギー市場のさまざまなプレーヤー (電力会社、立法機関、アグリゲーター、消費者、サービスプロバイダー) に課題と機会の両方をもたらしています。
さまざまな関係者が Amazon Web Services (AWS) を活用して DER を最大限に活用する方法について、一連のブログを計画しています。最初のブログでは、アグリゲーターが事業の成長に合わせて拡張できる堅牢な分散型エネルギーリソース管理システム (DERMS) を構築するために、AWS サービスがどのように役立つかを探ります。

Amazon RDS for SQL Server での追加のストレージボリューム設定
この投稿では、Amazon RDS for SQL Server インスタンス向けの追加ストレージボリューム機能を紹介し、実用的な実装シナリオを説明します。追加ストレージボリュームは、ワークロードタイプ別にデータを整理する柔軟性を提供し、専用の IOPS 割り当てによってパフォーマンスを向上させ、高可用性と耐久性を維持しながらストレージを独立してスケールすることができます。

Amazon Aurora PostgreSQL および Amazon RDS for PostgreSQL のバージョン 13 からのアップグレード戦略
本記事は 2026 年 1 月 27 日 に公開された「Strategies for upgrading Am […]

RDS for Db2 でトラブルシューティングに必要な情報を収集する
本記事では、Amazon Relational Database Service (Amazon RDS) f […]

LangGraph と Amazon DynamoDB で耐久性のある AI エージェントを構築する
本記事は 2026 年 01 月 13 日 に公開された “Build durable AI ag […]
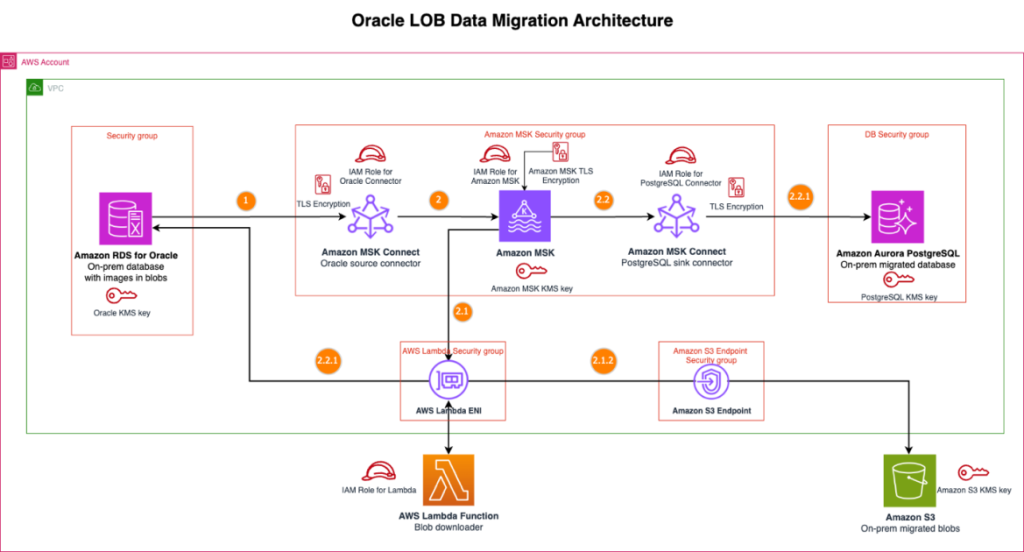
Oracle から Amazon Aurora PostgreSQL および Amazon S3 への大容量バイナリオブジェクト移行を効率化する Kafka ベースのソリューション
Amazon MSK、Amazon Aurora PostgreSQL-Compatible Edition、Amazon MSK Connect を使用して、Oracle データベースから AWS への大容量バイナリオブジェクト (LOB) 移行を効率化するストリーミングソリューションを紹介します。

ニフティ株式会社、Amazon RDS for Oracle への移行によりシステム環境のランニングコストを77%削減
ニフティグループでは、Amazon RDS に移行することで、システム環境のコストを77%削減しました。また、運用・保守作業の効率化、メンテナンス時期の柔軟な選択が可能になり、システムの安定性とセキュリティも向上しました。さらに、若手エンジニアの育成機会の創出にもつながっています。
寄稿:東京証券取引所が挑む膨大な取引データの処理 – AWS 活用で実現した次世代データ分析基盤
本稿は、株式会社日本取引所グループ(以下「JPX」)傘下の株式会社東京証券取引所(以下「東証」)による「膨大な […]