Amazon Web Services ブログ
Category: Database
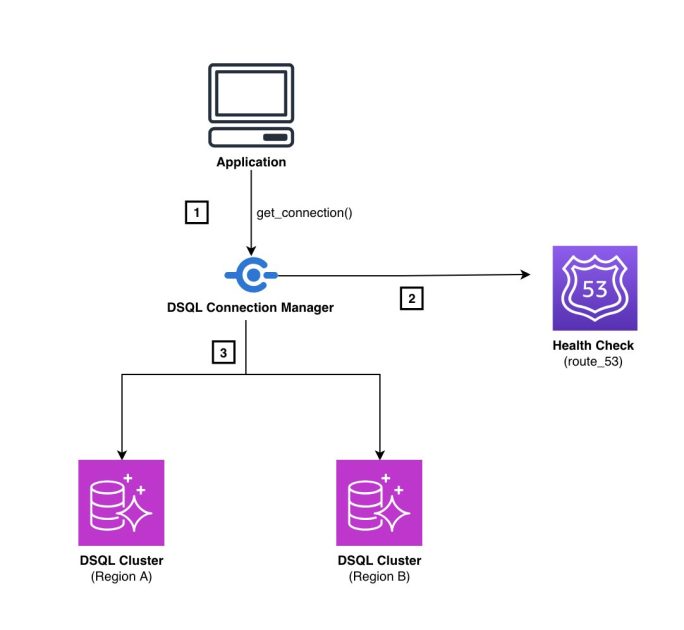
Amazon Aurora DSQL のマルチリージョンエンドポイントルーティングを実装する
Amazon Aurora DSQL のマルチリージョンクラスターにおいて、Route 53 ヘルスチェックとクライアント側レイテンシー測定を組み合わせた自動エンドポイントルーティングソリューションを実装する方法を紹介します。リージョナルエンドポイント障害時に自動的に正常なエンドポイントへフェイルオーバーし、アプリケーションの継続的なデータベースアクセスを実現します。

標準 JDBC ドライバーで AWS Advanced JDBC Wrapper を使い Amazon Aurora の高度な機能を活用する
本記事では、AWS Advanced JDBC Wrapper を使って標準 JDBC ドライバーに Amazon Aurora の高速フェイルオーバーや読み取り/書き込み分離などのクラウド機能を追加する方法を紹介します。最小限のコード変更で、既存の Java アプリケーションを段階的に拡張する手順を解説します。

Amazon RDS for SQL Server の CPU 最適化機能の探索
この投稿では、Amazon RDS for SQL Server の CPU 最適化機能を使用して vCPU 割り当てをカスタマイズし、特定のワークロードのコストを削減し、パフォーマンスを最適化する方法を説明します。CPU リソースを微調整することで、アプリケーションが必要とするパフォーマンスを維持しながら、より良いコスト最適化を実現できます。

Amazon RDS for SQL Server で Developer Edition のインスタンスを作成する
この投稿では、Amazon RDS 上で SQL Server Developer Edition の作成およびデプロイする方法として、インストールファイルの準備と Amazon S3 へのアップロードから、CEV の作成、そして最終的な RDS インスタンスの起動までのプロセスを紹介します。

AWS でのブロックチェーンインデクサーの構築
分散型金融 (DeFi) の取引判断には、ブロックチェーンの価格と流動性データが必要です。 しかし、ブロックチ […]

smart EuropeがAmazon Bedrockでカスタマーサポート業務を変革した方法
自動車メーカーにとって、新型車のリリース、無線通信(OTA)によるソフトウェアアップデート、コネクテッドサービスの開始は、新鮮な顧客体験を生み出します。これらのイノベーションは運転体験の向上に役立つ一方で、自動車所有者から車両の機能、充電機能、メンテナンス手順、デジタルサービスに関する多数の問い合わせを生み出します。
AWSはsmart Europeと協力し、smart.AI Case Handlerを開発しました。このツールは、問い合わせに関するインサイトとカスタマイズされた対応を提案することで、サポート担当者の効率を大幅に向上させます。
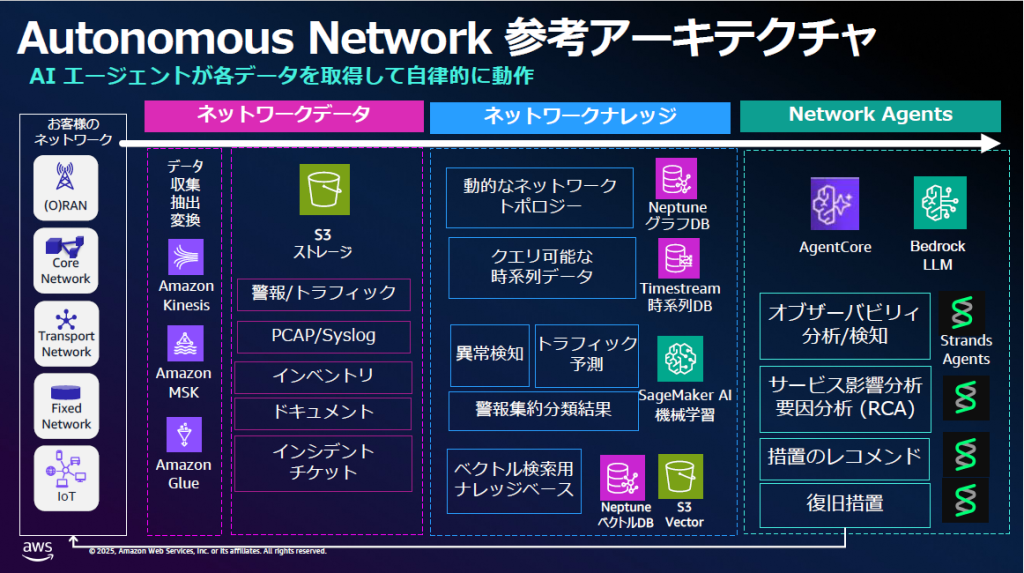
【開催報告】通信ネットワーク運用向け AI エージェントワークショップ開催しました! ( 2025 年 11 月 27 日 )
通信業界のネットワーク運用ではより安定した通信ネットワークを提供するために、障害の検知、要因特定、復旧を早期に […]
人に依存しないCRMによりEC事業者のLTV最大化を実現 Amazon Bedrock AgentCoreを活用したAIオートパイロット型CRM開発事例
株式会社ダイレクトマーケティングエージェンシー(以下、DMA)は、2006年の創業以来、ECビジネス支援エー […]
Rivian と Volkswagen Technology Group が Amazon Kinesis Video Streams で構築したリアルタイム車両セキュリティ
Rivian と Volkswagen Technology Group が、Amazon Kinesis Video Streams を活用して車両セキュリティの向上を実現した事例を紹介します。Rivian のギアガードフィーチャーの強化により、車内カメラからのリアルタイムビデオストリーミングがモバイルアプリから可能になりました。低遅延、高スケーラビリティ、堅牢なセキュリティなど Kinesis Video Streams の特徴が、車両オーナーに即時のビジュアルアクセスを提供することに貢献しています。WebRTC の活用、地域最適化されたシグナリングサーバー、コスト管理の工夫など、Rivian の設計の詳細も紹介しています。ドライバーの安全とプライバシーを第一に考えた、先進的な車載セキュリティソリューションの事例です。
Amazon RDS for MySQL と Amazon Aurora MySQL で高速な InnoDB パージを実現する
本記事は、”Achieve a high-speed InnoDB purge on Amazon […]