Amazon Web Services ブログ
Category: Database

AWS Lambda と Amazon DynamoDB を使用したクロスアカウントストリーム処理の簡素化
本記事は 2026 年 02 月 09 日 に公開された “Simplify cross-acco […]
Terraform の新機能: Amazon DynamoDB のグローバルセカンダリインデックスのドリフトを管理する
Amazon DynamoDB のグローバルセカンダリインデックス (GSI) のキャパシティを Terraf […]
【寄稿】CO2 排出量可視・削減サービス「e-dash」を支えるサーバーレスアーキテクチャと IaC 戦略
こんにちは、AWS ソリューションアーキテクトの松本 敢大です。 本日は、三井物産発の環境系スタートアップである e-dash 株式会社様が提供する CO2 排出量可視化・削減サービスプラットフォーム「e-dash」のシステム構築事例をご紹介します。e-dash 株式会社 プロダクト開発部部長の佐藤様、プロダクト開発部の伊藤様、竹内様に、AWS を活用したモダンなアプリケーション開発の取り組みについてお話を伺いました。

AI を活用したゲーム制作: 静的なコンセプトからインタラクティブなプロトタイプへ
AI を活用することで、ゲーム開発の初期段階でコンセプトをインタラクティブにし、数分でプレイ可能なプロトタイプを作成できます。AWS re:Invent 2025 で紹介する Agentic Arcade は、マルチエージェントオーケストレーション、プログラマティックアセット生成、セマンティック検索を組み合わせ、開発サイクルの早い段階で創造的な方向性を探索し検証する方法を示します。
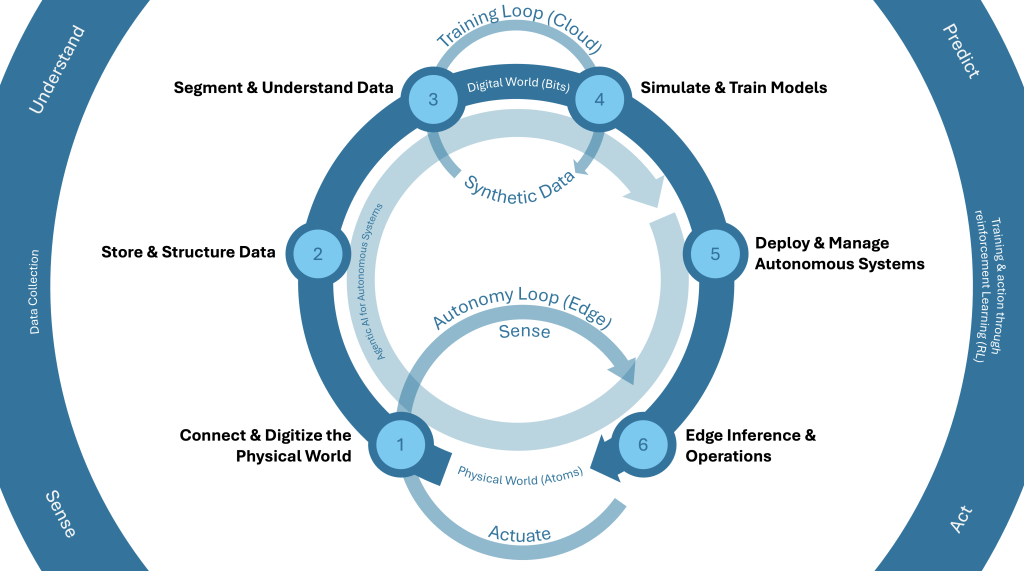
フィジカル AI: 自律型インテリジェンスに向けた次なる基盤を築く
AWS の Physical AI フレームワークは、デジタル世界と物理世界を橋渡しする自律システムを構築するための包括的なアプローチです。物理世界の接続とデジタル化、データの保存と構造化、データのセグメント化と理解、シミュレーションとトレーニング、デプロイと管理、エッジ推論と運用の 6 つの相互接続された機能を通じて、継続的な学習サイクルを作り出し、自律型経済への移行を支援します。

Amazon Aurora PostgreSQL の共有プランキャッシュの使用
Aurora PostgreSQL の共有プランキャッシュ機能により、高並行性環境で汎用 SQL プランのメモリ消費を大幅に削減できます。プラン重複を解消することで、40GB のメモリ負荷を 400MB まで削減し、より小さなインスタンスでより多くの接続を実行できます。

AWS Weekly Roundup: Amazon Bedrock エージェントワークフロー、Amazon SageMaker プライベート接続など (2026 年 2 月 2 日)
2026 年 1 月 26 日週、私たちはラバ祭りを祝いました。これは、旧正月まで残りわずかであることを告げる […]
Oracle Database@AWS 日本で提供開始
2025 年 12 月 、オラクル・コーポレーションと Amazon Web Services (AWS) は […]
Amazon DynamoDB グローバルテーブルが AWS アカウント間のレプリケーションをサポート
本記事は 2026 年 02 月 03 日 に公開された “Amazon DynamoDB glo […]
ディップ株式会社 Exadataから Amazon RDS for Oracleへの移行でコスト56%削減を実現
ディップ株式会社は、求人情報サイト「バイトル」や「はたらこねっと」などの運営や、中小企業の労働力を改善する D […]