Amazon Web Services ブログ
Gluon Time Series でニューラル時系列モデルを作る
オープンソース版 Gluon Time Series (GluonTS) の一般公開したことを喜んでお知らせいたします。これは、Amazon の研究者達が、深層学習をベースにした時系列モデルの構築、評価、比較のために開発した、Python のツールキットです。GluonTS は、Apache MXNet のための Gluon インターフェースをベースにしており、時系列モデルの構築を、シンプルかつ効率的にするコンポーネントを提供します。
今回のブログでは、このツールキットの主要な機能を解説すると共に、GluonTS を時系列予測問題に応用する方法も示します。
時系列モデルのユースケース
その名前が示すとおり、時系列モデルとは時刻でインデクスされたデータポイントの集合のことです。多くの多様なアプリケーションにおいて、時系列は自然と生み出されています。典型的なものとしては、基本プロセスから生じるデータを、固定的な時間間隔で測定する場合があります。
例えば、毎営業日の終わりに、小売業者は各製品が単体でいくつ売れたか計算し、記録しておくでしょう。これは、各製品の日々の販売数についての時系列データとなります。電力会社の場合なら、1時間毎など固定的な時間間隔で、各家庭が消費する電力量を測定するでしょう。これは、電力消費に関する時系列データを集めることになります。AWS のお客様であれば、ご使用のリソースやサービスに関係する複数のメトリクスを、Amazon CloudWatch を使い記録するでしょう。それは、メトリクスの時系列を集めることになります。
一般的な時系列は、次に示すように、測定された値を縦軸の目盛りに、時刻を横軸に取る形式となります。
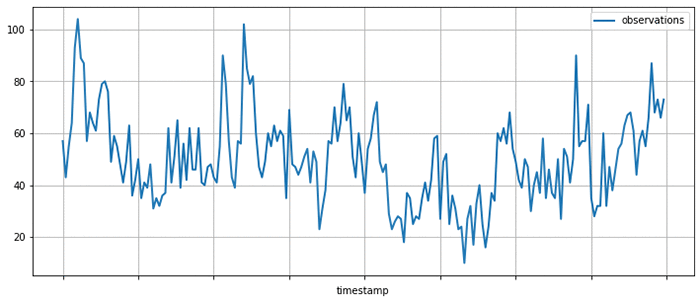
時系列データが入手できたら、それについていくつかの論点を考えることができます。
- その時系列は将来どう変わってゆくか? 予測
- 特定時刻における時系列の動きに変則性があるか? 異常検出
- 与えられた時系列はどのグループに分類されるか? 時系列の分類
- いくつか欠測値があった場合、その値は何であったか? 補完
GluonTS では、時系列モデルの構築を簡素化しているので、前出のような問題に対処することが容易になります。モデルとは、時系列の基礎に存在するプロセスを数学的に記述したものです。これまで、多数の時系列モデルが提案されてきていますが、GluonTS では、これらのテクニックの中でも、機械学習を応用した特定のサブセットにフォーカスしています。
GluonTS の主要機能とコンポーネント
GluonTS では、深層学習ベースの時系列モデル構築を簡素かつ効率的に行える、多数のコンポーネントが用意されています。これらのモデルには、自然言語処理や画像処理など他の領域で使われるものと同じ、多くの構成ブロックがモデルとして利用されています。
時系列モデルを処理する深層学習モデルには、Long Short-Term Memory (LSTM) セルを基本とした再帰型ニューラルネットワークや、コンボリュージョン、アテンション機構などのコンポーネントが一般的に含まれますそのため、Apache MXNet などのモダンな深層学習フレームワークが、モデルの開発と実験をするための便利な基盤として使えるようになっています。
しかし、時系列モデリングには、その応用領域に特化したコンポーネントも、しばしば必要とされます。GluonTS では、そういった時系列モデリングに独特なコンポーネントを、MXNet のための Gluon インターフェース上で提供します。GluonTS が持つ特徴としては以下が挙げられます、
- 新規モデル構築のための高レベルなコンポーネント。Sequence to Sequence モデルなどの一般的なニューラルネットワーク構造、モデリングや変動確率分布のためのコンポーネントを含みます
- 時系列データのためのデータ取り込みと反復処理。モデル適用前のデータを変換する機構を含みます
- 複数の先進的ニューラル予測モデルの実装参考例
- 予測モデルの評価および比較を行うツール
現状では、モデル実装例とその周辺ツールのいくつかは、予測ユースケースを想定したものとなっていますが、 GluonTS が持つほとんどの構成ブロックは、前に挙げた時系列モデリングのユースケースのいずれにも利用することが可能です。
時系列予測のための GluonTS
より明確な説明をするために、GluonTS にバンドルされることになった時系列モデルの 1 つを取り上げ、その使いかたを見てみましょう。これは、現実世界の時系列データで予測を行うためのものです。
この例では、DeepAREstimatorを使用します。これには、DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks の論文で提案された DeepAR モデルを実装しています。1 つ以上の時系列が与えられることで、このモデルは次の prediction_length 値を、先行して与えられた context_length 値から予測します。予測領域内の各時刻に一意の値を予測する代わりに、このモデルは各出力点のためのパラメトリックな確率分布を変数として表示します。
モデルに訓練済みのモデルアーティファクトをカプセル化するため、GluonTS では、Estimator と Predictorという抽象化されたペアを使います。これは、他の機械学習フレームワークを使う人にとってもなじみあるものでしょう。Estimator は、データセットを使い訓練できるモデルを表します。これは後に Predictor を呼び出し、表面化していないデータを予測させます。
いくつかのハイパーパラメータを与えて、DeepAREstimator オブジェクトのインスタンス化をします。
- 時系列の頻度 (この例では 5 分とするので、
freq="5min"となります) - 予測の長さ (36 の時間ポイントで長さは 3 時間になります)
訓練プロセスの詳細設定を行うために、Trainer オブジェクトを使うこともできます。引数として他のハイパーパラメータを設定し、さらにモデルの性質を定義することも可能ですが、出発点として分かりやすくするために、ここではデフォルトの値のまま進めていきます。
現実のデータを使ったモデルの訓練
Estimator の設定をしたので、いくつかデータを与えてモデルの訓練を始められます。大量にあるツイートの中から自由に使えるデータセットして、AMZN というティッカーシンボルについて言及したものを使ってみましょう。これは、以下のように Pandas を使って、取得および表示させることができます。
GluonTS では、異なる入力フォーマットからのデータに単一的なアクセスができる、Dataset という抽象オブジェクトを提供しています。ここでは、ディクショナリーの一覧としてメモリに格納されたデータにアクセスするため、ListDatasetを使用します。GluonTS においては、文字列キーを任意の値にマッピングしているディクショナリーでは、すべての Dataset が Iterable です。
モデルの訓練に使うため、データは 2015 年 4 月 5 日までを切り出します。この日付以降のデータは、後にモデルテストのために使用します。
データセットが手に入ったので、estimator を使い、その train メソッドを呼び出せるようになりました。訓練プロセスが終了すれば、Predictor で予測処理を作成できます。
モデルの評価
それでは、訓練の最後に扱った時刻の後に続く時間領域の予測をプロットするために、predictor を使ってみましょう。これは、モデルが生み出す結果の品質について、安定感を得るためには良い方法です。
前のものと同じ基本データセットを使用しつつ、訓練で使った時間領域より後のデータを使い、テスト用インスタンスをいくつか作成していきます。
次のプロット結果を見るとお分かりのとおり、このモデルは確率的な予測値を算出するものです。ここには、モデルが予測結果をどの程度妥当だと評価しているか示されており、後にこの予測結果を基に行われる意思決定に不確かさまで考慮できるという点で、このプロットには重要性があります。
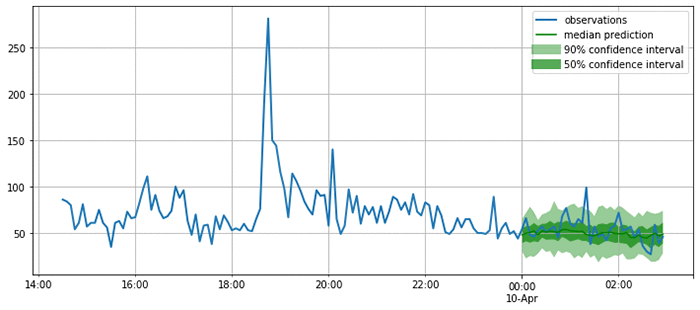
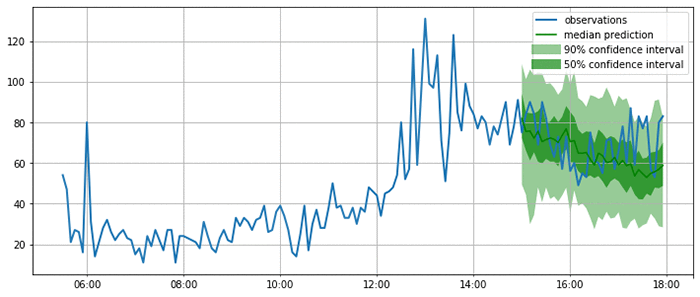
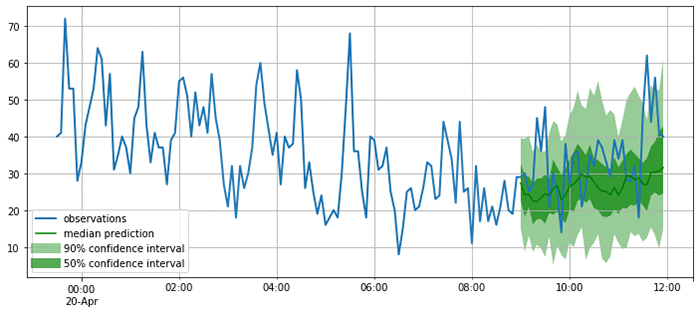
ここまでで、妥当性が認められ満足できる予測処理が行われるようになったので、多種のメトリクスを使いながら、テストセット内の全時系列について予測処理の品質評価を計算できます。GluonTS では、モデル評価を実行するコンポーネント、Evaluator を提供しています。これは、MSE、MASE、symmetric MAPE、RMSE、そして (加重) 分位損失など、一般的に使われるエラーメトリクスを生成します。
これらのメトリクスでは、ほかのモデルが生成した結果との比較や、自分の予測アプリケーションが抱えるビジネス的要求事項の考察などが行えます。例えば、seasonal naive メソッドを使い予測処理を行ったとします。このモデルでは、データには固定的な周期性 (この例では、週基準で2016の時間ステップ) があると仮定しており、これを基に過去の測定値をコピーすることで予測結果を生成します。
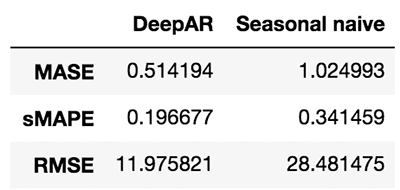
これらのメトリクスを合わせて見ることで、基本的な手法もしくは先進的なモデルと比べ、自分のモデルがどうか知ることができます。結果を改善したい場合は、アーキテクチャかハイパーパラメータを細かく修正していきます。
GluonTS の成長にご協力を!
このブログで触れたのは、GluonTS が提供する機能の中でも小さなサブセットのみです。さらに探求したい場合は、tutorials や他の examples などをチェックしてみることをお勧めします。
GluonTS は、Apache ライセンスの下でオープンソースとて公開されています。当社では、バグ報告やプルリクエストなど、コミュニティからの報告を歓迎するとともにお願いしております。今すぐにでも、GluonTS の GitHub レポジトリーへお越しください!
著者について
 Jan Gasthausは、AWS の AI ラボで働くシニア機械学習サイエンティストで、機械学習モデル、アルゴリズム、そしてシステムの設計、それらの大規模なデプロイのために情熱を注いでいます。
Jan Gasthausは、AWS の AI ラボで働くシニア機械学習サイエンティストで、機械学習モデル、アルゴリズム、そしてシステムの設計、それらの大規模なデプロイのために情熱を注いでいます。
 Lorenzo Stellaは、AWS AI ラボチームのアプライドサイエンティストです。機械学習と最適化技法が、彼の主な研究分野です。彼は、予測処理のための確率的で深層的モデルを研究しています。
Lorenzo Stellaは、AWS AI ラボチームのアプライドサイエンティストです。機械学習と最適化技法が、彼の主な研究分野です。彼は、予測処理のための確率的で深層的モデルを研究しています。
 Tim Januschowskiは、AWS AI ラボの機械学習科学マネージャーです。彼は、Amazon で働き始めて以来、予測処理について研究を続けてきました。また、需要予測やサーバー能力の予測など広範囲な予測問題に対し、エンドツゥエンドのソリューションを生み出しています。
Tim Januschowskiは、AWS AI ラボの機械学習科学マネージャーです。彼は、Amazon で働き始めて以来、予測処理について研究を続けてきました。また、需要予測やサーバー能力の予測など広範囲な予測問題に対し、エンドツゥエンドのソリューションを生み出しています。
 Richard Lee は、AWS AI ラボのプロダクトマネージャーです。彼は、人々を取り巻く世界に人工知能がどのような影響を与えるかについて、強い関心をもっており、すべての人がそれに触れられるようにするのだという、使命感を持っています。彼はパイロットでもあり、化学と自然の愛好家、そして料理の初心者です。
Richard Lee は、AWS AI ラボのプロダクトマネージャーです。彼は、人々を取り巻く世界に人工知能がどのような影響を与えるかについて、強い関心をもっており、すべての人がそれに触れられるようにするのだという、使命感を持っています。彼はパイロットでもあり、化学と自然の愛好家、そして料理の初心者です。
 Syama Sundar Rangapuram は、AWS AI ラボで働く機械学習サイエンティストです。機械学習と最適化技法が、彼の主な研究分野です。予測分野においては、確率モデルや、コールドスタート問題に重点をおいたデータドリブンモデルの研究などを行っています。
Syama Sundar Rangapuram は、AWS AI ラボで働く機械学習サイエンティストです。機械学習と最適化技法が、彼の主な研究分野です。予測分野においては、確率モデルや、コールドスタート問題に重点をおいたデータドリブンモデルの研究などを行っています。
 Konstantinos Benidis は、AWS AI ラボで働くアプライドサイエンティストです。彼の研究分野は、機械学習、最適化、そして金融工学などです。彼は、予測処理のための確率的で深層的モデルを研究しています。
Konstantinos Benidis は、AWS AI ラボで働くアプライドサイエンティストです。彼の研究分野は、機械学習、最適化、そして金融工学などです。彼は、予測処理のための確率的で深層的モデルを研究しています。
 Alexander Alexandrov は、AWS AI ラボチームと TU-Berlin のために働く博士候補生です。彼は、スケーラブルなデータ管理、データ解析アプリケーション、そして DSL の最適化などに強い関心があります。
Alexander Alexandrov は、AWS AI ラボチームと TU-Berlin のために働く博士候補生です。彼は、スケーラブルなデータ管理、データ解析アプリケーション、そして DSL の最適化などに強い関心があります。
 David Salinas は、AWS AI ラボチームのシニアアプライドサイエンティストです。彼は、予測問題や NLP など、多様なアプリケーションに深層学習を応用する研究をしています。
David Salinas は、AWS AI ラボチームのシニアアプライドサイエンティストです。彼は、予測問題や NLP など、多様なアプリケーションに深層学習を応用する研究をしています。
 Danielle Robinson は、AWS AI ラボチームのアプライドサイエンティストです。彼女は、深層学習のメソッドと古典的な統計手法を組み合わせ、予測問題に取り組んでいます。彼女は、数値線形代数学や数値最適化、さらに数値的 PDE などにも関心があります。
Danielle Robinson は、AWS AI ラボチームのアプライドサイエンティストです。彼女は、深層学習のメソッドと古典的な統計手法を組み合わせ、予測問題に取り組んでいます。彼女は、数値線形代数学や数値最適化、さらに数値的 PDE などにも関心があります。
 Yuyang (Bernie) Wang は、Amazon AI ラボのシニア機械学習サイエンティストです。主に、大規模な確率的機械学習の予測アプリケーションについて研究しています。彼の研究範囲は、統計的機械学習、数値線形代数学、そしてランダム行列理論などにもおよびます。予測分野における Yuyang の研究は、実践的なアプリケーションから基礎理論までの、あらゆる側面をカバーしています。
Yuyang (Bernie) Wang は、Amazon AI ラボのシニア機械学習サイエンティストです。主に、大規模な確率的機械学習の予測アプリケーションについて研究しています。彼の研究範囲は、統計的機械学習、数値線形代数学、そしてランダム行列理論などにもおよびます。予測分野における Yuyang の研究は、実践的なアプリケーションから基礎理論までの、あらゆる側面をカバーしています。
 Valentin Flunkert は、AWS AI ラボの機械学習サイエンティストです。彼は、ビジネスの諸問題を解決する機械学習システムの開発に強い関心があります。彼は Amazon で、多種にわたる機械学習と予測問題について研究を続けてきました。
Valentin Flunkert は、AWS AI ラボの機械学習サイエンティストです。彼は、ビジネスの諸問題を解決する機械学習システムの開発に強い関心があります。彼は Amazon で、多種にわたる機械学習と予測問題について研究を続けてきました。
 Michael Bohlke-Schneider は、AWS AI ラボと Fulfillment Technology で働くデータサイエンティストです。SageMaker の予測アルゴリズムを研究開発し、またビジネス問題への予測処理の応用なども行っています。
Michael Bohlke-Schneider は、AWS AI ラボと Fulfillment Technology で働くデータサイエンティストです。SageMaker の予測アルゴリズムを研究開発し、またビジネス問題への予測処理の応用なども行っています。
 Jasper Schulz は、AWS AI ラボで働くソフトウェア開発エンジニアです。
Jasper Schulz は、AWS AI ラボで働くソフトウェア開発エンジニアです。