Amazon Web Services ブログ
Apache MXNet 用のモデルサーバーのご紹介
今週初めに、AWS はディープラーニングモデルを提供する Apache MXNet の上に構築されるオープンソースのコンポーネントである、Apache MXNet 用のモデルサーバーの提供開始を発表しました。Apache MXNet は、機械学習のための使いやすく簡潔な API を備えた、高速でスケーラブルなトレーニングおよび推論フレームワークです。Apache MXNet 用のモデルサーバーにより、エンジニアは MXNet モデルを簡単、迅速、大規模に提供することができます。
Apache MXNet 用のモデルサーバーとは
Apache MXNet (MMS) 用のモデルサーバーは、推論のディープラーニングモデルを大規模なデプロイするタスクを簡略化するために設計された、オープンソースのコンポーネントです。推論のモデルをデプロイすることは、ささいなタスクではありません。さまざまなモデルアーティファクトの収集、提供スタックのセットアップ、ディープラーニングフレームワークの初期化と設定、エンドポイントの公開、リアルタイムメトリクスの出力、カスタム前処理および後処理コードの実行をはじめ、数多くのエンジニアリングタスクがあります。各タスクが必要以上に複雑にならないこともありますが、モデルのデプロイに関連する全体的な労力は、デプロイプロセスが時間のかかる面倒なものとなる要因として十分です。
MMS により、AWS はディープラーニングモデルのデプロイプロセスを大幅に簡略化する、Apache MXNet 用のオープンソースのエンジニアリングツールセットを提供します。モデルのデプロイに MMS を使用することにより得られる主要な機能を以下に示します。
- MXNet モデルを提供するために必要なすべてをカプセル化する単一の「モデルアーカイブ」にすべてのモデルアーティファクトをパッケージ化し、エクスポートするためのツール。
- HTTP 推論エンドポイント、MXNet ベースのエンジンを含むサービススタックの自動セットアップ。このすべては、ホストする特定のモデルに対して自動的に設定されます。
- スケーラブルなモデルの提供用に NGINX、MXNet、および MMS で設定された、事前設定済みの Docker イメージ。
- モデルの初期化から、前処理と推論を経てモデルの出力の後処理に至る、推論実行パイプラインの各ステップをカスタマイズする機能。
- レイテンシー、リソース使用率、エラーを含む、推論サービスとエンドポイントをモニタリングするリアルタイムのオペレーションメトリクス。
- Java、JavaScript、C# など一般的なスタックのクライアントコードの簡単な統合と自動生成を可能にする、OpenAPI 仕様のサポート。
MMS は PyPi パッケージを通じて、またはモデルサーバーの GitHub レポジトリから直接利用でき、Mac および Linux で実行されます。スケーラブルな本稼働のユースケースでは、MMS GitHub レポジトリで提供される事前設定済み Docker イメージの使用をお勧めします。
次の図は、リファレンスアーキテクチャの例を示しています。
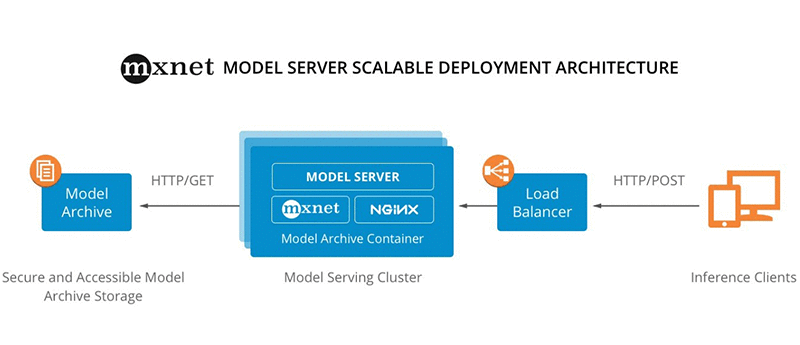
モデル提供のクイックスタート
MMS; の使用開始は簡単です。以下の例で示します。この例では、MMS Model Zoo で一般公開されている事前トレーニング済みの SqueezeNet v1.1 オブジェクト検出モデルを利用します。
使用を開始するには、Python が必要です。これは MMS の唯一の前提条件です。Python がインストールされていない場合は、Python のウェブサイトの手順に従って、Python 2.7 または 3.6 をインストールします。
次に、PyPi を使用して選択したマシンに MMS をインストールします。MMS では Mac および Linux オペレーティングシステムがサポートされています。
モデルの提供は、MMS を実行し、モデルアーカイブ URL またはローカルファイルでそれを指すことにより行われます。
このコマンドを実行すると、MMS プロセスが開始され、モデルアーカイブのダウンロードと解凍、モデルアーティファクトによるサービスの設定が行われた後で、ポート 8080、localhost の /squeezenet/predict エンドポイント経由で受信リクエストのリッスンが開始されます (ホストとポートは設定可能です)。
新しく作成されたサービスをテストするため、HTTP 経由で推論リクエストを送信し、イメージの分類をモデルに要求してみましょう。
次のようなレスポンスが表示され、モデルは 85% の確立で、イメージ内のオブジェクトを「Egyptian cat」として識別します。
モデル提供の理解を深めるため、サーバードキュメントを参照してください。
提供用のモデルのエクスポート
MMS は、MMS モデルアーカイブ形式でパッケージ化されたモデルを提供します。これには、モデルアーティファクトをパッケージ化し、単一のモデルアーカイブファイルをエクスポートするコマンドラインインターフェイス mxnet-model-export が含まれます。エクスポートされたモデルアーカイブは、モデルを提供するために必要なすべてのアーティファクトとメタデータをカプセル化します。これは、提供エンドポイントを初期化するときに MMS によって消費されます。提供のために追加のモデルメタデータまたはリソースは必要ありません。
次の図はエクスポートプロセスを示しています。

図に示すように、モデルアーカイブをパッケージ化するために必要な必須のアーティファクトは、モデルのニューラルネットワークアーキテクチャとパラメータ (レイヤー、演算子、ウェイト) と、サービスの入出力データ型およびテンソル形状の定義です。ただし、現実のユースケースでモデルを使用するには、ニューラルネットワーク以上のものが必要になります。たとえば、多くのビジョンモデルでは、モデルに渡す前に入力イメージの前処理および変換が必要になります。別の例として、通常、分類結果をソートおよび切り捨てるために後処理を必要とする分類モデルがあります。これらの要件に対応し、モデルアーカイブへのモデルの完全なカプセル化を可能にするため、MMS はカスタム処理コードと補助ファイルをアーカイブにパッケージ化して、それらにファイルを実行時に利用可能にできます。この強力なメカニズムにより、完全な処理パイプラインをカプセル化するモデルアーカイブを生成できます。入力の前処理から開始し、推論のカスタマイズを経て、ネットワークの出力でクラスラベル ID を適用した直後に、ネットワーク経由でクライアントに返されます。
モデルアーカイブのエクスポートの詳細については、MMS エクスポートのドキュメントを参照してください。
詳細と貢献
MMS は、使いやすさ、柔軟性、およびスケーラビリティを実現するように設計されています。提供エンドポイントの設定、リアルタイムのメトリクスとログ記録、事前設定されたコンテナイメージなど、このブログ投稿の説明以外にも追加機能を備えています。
MMS の詳細を学習するには、「Single Shot MultiBox Detector (SSD) チュートリアル」から始めることをお勧めします。このチュートリアルでは、SSD モデルのエクスポートと提供について説明しています。その他の例と追加のドキュメントが、レポジトリのドキュメントフォルダで利用できます。
当社が MMS をさらに開発、拡大する際に、質問、リクエスト、貢献を通じたコミュニティへの参加を歓迎いたします。awslabs/mxnet-model-server レポジトリに移動して開始してください。
その他の参考資料
AWS と MXNet の詳細情報をご覧ください。
- AWS、Apache MXNet の ディープラーニングエンジンのマイルストーンである 1.0 のリリースに対し新しいモデル提供機能の追加を含む貢献
- Apache MXNet で ONNX をサポート
- Amazon EMR での Apache MXNet および Apache Spark を使用した分散推論
今回のブログの投稿者について
 Hagay Lupesko は AWS Deep Learning のエンジニアリングマネージャーです。開発者やサイエンティストがインテリジェントアプリケーションを構築できるようにするディープラーニングツールの構築を担当しています。読書やハイキング、家族と時間を過ごすことが趣味です。
Hagay Lupesko は AWS Deep Learning のエンジニアリングマネージャーです。開発者やサイエンティストがインテリジェントアプリケーションを構築できるようにするディープラーニングツールの構築を担当しています。読書やハイキング、家族と時間を過ごすことが趣味です。
 Ruofei Yu は AWS Deep Learning のソフトウェアエンジニアです。ソフトウェアエンジニアやサイエンティスト向けの革新的なディープラーニングツールの構築を担当しています。友人や家族と時間を過ごすことが趣味です。
Ruofei Yu は AWS Deep Learning のソフトウェアエンジニアです。ソフトウェアエンジニアやサイエンティスト向けの革新的なディープラーニングツールの構築を担当しています。友人や家族と時間を過ごすことが趣味です。
 Yao Wang は AWS Deep Learning のソフトウェアエンジニアです。ソフトウェアエンジニアやサイエンティスト向けの革新的なディープラーニングツールの構築を担当しています。ハイキング、読書、音楽を楽しむことが趣味です。
Yao Wang は AWS Deep Learning のソフトウェアエンジニアです。ソフトウェアエンジニアやサイエンティスト向けの革新的なディープラーニングツールの構築を担当しています。ハイキング、読書、音楽を楽しむことが趣味です。