Amazon Web Services ブログ
Amazon SageMaker の Horovod またはパラメータサーバーでTensorFlow 分散トレーニングを簡単に起動する
Amazon SageMaker は、TensorFlow を含む一般的なディープラーニングフレームワークをすべてサポートしています。クラウド内の TensorFlow プロジェクトの 85% 以上が AWS で実行されています。プロジェクトの多くはすでに Amazon SageMaker で実行されています。これは、Amazon SageMaker が TensorFlow モデルのホスティングとトレーニングにもたらす大きな利便性によるものです。これには、Horovod とパラメータサーバーを使用した完全マネージド型の分散トレーニングが含まれます。
お客様は、1 週間以上かかる大規模なデータセットのトレーニングモデルにますます関心を持ってきています。この場合、クラスター内の複数のマシンまたはプロセスにトレーニングを分散することにより、プロセスを高速化できる可能性があります。この記事では、Amazon SageMaker により、トレーニングクラスターを直接管理する費用や困難なしに、TensorFlow を使用して分散トレーニングを迅速にセットアップおよび起動する方法について説明します。
TensorFlow バージョン 1.11 以降では、Amazon SageMaker の事前作成された TensorFlow コンテナを使用できます。Python トレーニングスクリプトを提供し、ハイパーパラメータを指定し、トレーニングハードウェア設定を指定するだけです。Amazon SageMaker は、トレーニングクラスターをスピンアップし、トレーニングが終了したらクラスターを破棄するなど、残りの作業を行います。この機能は「スクリプトモード」と呼ばれます。 スクリプトモードは、すぐに使用できる以下の 2 つの分散トレーニングアプローチを現在サポートしています。
- オプション #1: TensorFlow のネイティブパラメータサーバー (TensorFlow バージョン 1.11 以降)
- オプション #2: Horovod (TensorFlow バージョン 1.12 以降)
次のセクションでは、これらの TensorFlow 分散トレーニングオプションを Amazon SageMaker のスクリプトモードで有効にするために必要な手順の概要を説明します。
オプション 1: パラメータサーバー
分散トレーニングの一般的なパターンの 1 つは、1 つまたは複数の専用プロセスを使用して「ワーカー」プロセスによって計算された勾配を収集してから、それらを集計して、更新された勾配を非同期的にワーカーに配布し戻すことです。このプロセスは、パラメータサーバーと呼ばれます。
Amazon SageMaker スクリプトモードの TensorFlow パラメータサーバークラスターでは、クラスター内の各インスタンスが 1 つのパラメータサーバープロセスと 1 つのワーカープロセスを実行します。次の図に示すように、各パラメータサーバーはすべてのワーカーと通信します (「全体全」) (Meet Horovod: Uber’s Open Source Distributed Deep Learning Framework for TensorFlow より):
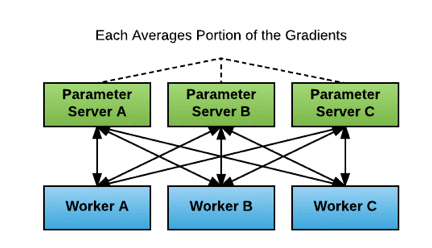
Amazon SageMaker スクリプトモードでは、パラメータサーバーの実装は非同期です。各ワーカーは、他のワーカーの更新を待たずに、勾配を計算し、パラメータサーバーに個別に勾配の更新を送信します。
実際には、通常、非同期更新による過度の悪影響はありません。遅れをとるワーカーは、古い勾配を提出する可能性があり、これはトレーニングの収束に悪影響を及ぼす可能性があります。通常、これは学習率を下げることで管理できます。プラス面としては、他のワーカーを待つ必要がないため、非同期更新によりトレーニングが高速化される可能性があります。
Amazon SageMaker スクリプトモードを使用する場合は、パラメータサーバークラスターを自分で設定および管理する必要はありません。Amazon SageMaker の事前構築済み TensorFlow コンテナには、パラメータサーバーで使用するための組み込みスクリプトモードオプションが備わっています。このオプションを使用すると、時間を節約し、クラスター管理の複雑さを軽減できます。
次のコード例は、スクリプトモードでパラメータサーバークラスターをセットアップする方法を示しています。Amazon SageMaker TensorFlow Estimator オブジェクトの distributions パラメータの値として「parameter_server」を指定します。Amazon SageMaker スクリプトモードは、トレーニングクラスターの各インスタンスでパラメータサーバースレッドを起動し、各インスタンスの個別のワーカースレッドでトレーニングコードを実行します。複数のインスタンスで分散トレーニングジョブを実行するには、train_instance_count を 1 よりも大きい数に設定します。
スクリプトモードでパラメータサーバーベースの分散トレーニングを使用する方法の例については、GitHub の「TensorFlow 分散トレーニングオプション」の例を参照してください。
オプション #2: Horovod
Horovod は、分散型深層学習のためのオープンソースフレームワークです。TensorFlow および他のいくつかのディープラーニングフレームワークで使用できます。パラメータサーバーと同様に、Amazon SageMaker は Horovod クラスターのセットアップを自動化し、適切なコマンドを実行して、クラスターを自分で直接管理する必要なく、トレーニングがスムーズに進むようにします。
Horovod のクラスターアーキテクチャは、パラメータサーバーアーキテクチャとは異なります。パラメータサーバーアーキテクチャでは、送信されるデータの量がプロセスの数に比例する、全対全の通信モデルを使用することを思い出してください。対照的に、Horovod は送信されるデータの量はクラスターノードの数にほぼ比例する Ring-AllReduce を使用します。これは、各ノードに複数の GPU がある (したがって複数のワーカープロセスがある) クラスターでトレーニングする場合により効率的です。
さらに、上記のパラメータサーバーの更新プロセスは非同期ですが、Horovod では更新は同期です。すべてのプロセスが現在のバッチの計算を完了すると、各プロセスで計算された勾配は、すべてのプロセスがすべてのプロセスからのバッチの勾配の完全なセットを持つまで、リングを循環します。
この時点で、各プロセスはローカルモデルの重みを更新するため、次のバッチで作業を開始する前に、すべてのプロセスは同じモデルの重みを持ちます。次の図は、Ring-AllReduce の仕組みを示しています (Meet Horovod: Uber’s Open Source Distributed Deep Learning Framework for TensorFlow より) :

Horovod は、高性能クラスター内のノード間の通信を管理するための一般的な標準である Message Passing Interface (MPI) を採用し、GPU レベルの通信に NVIDIA の NCCL ライブラリを使用しています。
Horovod フレームワークは、Ring-AllReduce クラスターセットアップの多くの困難を取り除き、いくつかの一般的なディープラーニングフレームワークと API で動作します。たとえば、一般的な Keras API を使用している場合、tf.Estimator などの中間 API に変換せずに、参照 Keras 実装または tf.keras を直接 Horovod と使用できます。
Amazon SageMaker スクリプトモードでは、Horovod は TensorFlow バージョン 1.12 以降で使用できます。スクリプトモードで Horovod を使用すると、Amazon SageMaker TensorFlow コンテナが MPI 環境をセットアップし、mpirun コマンドを実行してクラスターノードでジョブを開始します。スクリプトモードで Horovod を有効にするには、Amazon SageMaker TensorFlow Estimator とトレーニングスクリプトを変更する必要があります。Horovod でトレーニングを設定するには、Estimator の distributions パラメータで次のフィールドを指定します。
- 有効 (bool):
Trueに設定すると、MPI がセットアップされ、mpirunコマンドが実行されます。 - processes_per_host (int): MPI が各ホストで起動するプロセスの数。このフラグをマルチ GPU トレーニングに設定します。
- custom_mpi_options (str): このフィールドで渡される
mpirunフラグはすべてmpirunコマンドに追加され、Horovod トレーニングのために Amazon SageMaker によって実行されます。
各ホストで MPI が起動するプロセスの数は、選択したインスタンスタイプで使用可能なスロット数を超えてはなりません。
たとえば、Estimator オブジェクトを作成して、それぞれ 1 つの GPU/プロセスを持つ 2 つのホストで Horovod 分散トレーニングを起動する方法を次に示します。
Estimator オブジェクトの変更に加えて、トレーニングスクリプトに次の追加も行う必要があります。MPI が有効かどうかに基づいて、変更を条件付きにすることができます。
hvd.init ()を実行します。config.gpu_options.visible_device_listを使用して、このプロセスで使用されるサーバー GPU を固定します。プロセスごとに 1 つの GPU の一般的なセットアップでは、これをローカルランクに設定できます。その場合、サーバー上の最初のプロセスが最初の GPU を割り当て、2 番目のプロセスが 2 番目の GPU を割り当てと続きます。- ワーカーの数によって学習率をスケールします。同期分散トレーニングの有効なバッチサイズは、ワーカーの数に応じてスケールする必要があります。学習率の増加は、増加したバッチサイズを補います。
hvd.DistributedOptimizerでオプティマイザーをラップします。分散オプティマイザーは、勾配計算を元のオプティマイザーに委任し、allreduce を使用して勾配を平均化してから、その平均化された勾配を適用します。- コード
hvd.BroadcastGlobalVariablesHook (0)を追加して、初期変数状態をランク 0 から他のすべてのプロセスにブロードキャストします。この最初のブロードキャストにより、トレーニングの開始時にすべてのワーカーが (ランダムな重みを持つか、チェックポイントから復元された) 一貫した初期化を確実に受けるようにします。あるいは、MonitoredTrainingSessionを使用していない場合、グローバル変数の初期化後にhvd.broadcast_global_variablesop を実行できます。 - 他のワーカーがチェックポイントを破損しないように、コードを変更してワーカー 0 のみにチェックポイントを保存します。これを行うには、
hvd.rank() != 0の場合、checkpoint_dir=Noneをtf.train.MonitoredTrainingSessionに渡します。
Horovod の詳細については、「Horovod GitHub リポジトリ」を参照してください。スクリプトモードでの Horovod の使用例については、GitHub の TensorFlow 分散トレーニングオプションの例を参照してください。
分散トレーニングオプションの選択
クラスターの分散トレーニングに移行する前に、複数の GPU を備えた単一のマシンで最初にスケールアップを試みたことを確認してください。単一のマシン上の複数の GPU 間の通信は、複数のマシン間のネットワークを介した通信よりも高速です。詳細については、AWS ホワイトペーパー「Power Machine Learning at Scale」を参照してください。
単一のマシン内でより多くの GPU を使用してスケールアップするのではなく、クラスターにスケールアウトする必要がある場合、次の考慮事項は、パラメータサーバーオプションと Horovod のどちらを選択するかです。この選択は、使用している TensorFlow のバージョンに一部依存します。
- Amazon SageMaker スクリプトモードの TensorFlow バージョン 1.11 以降では、パラメータサーバーを使用できます。
- Horovod を使用するには、TensorFlow バージョン 1.12 以降を使用する必要があります。
次の表は、各オプションのパフォーマンスに関する一般的なガイドラインをまとめたものです。これらのルールは絶対的なものではなく、最終的に、最適な選択は特定のユースケースに依存します。通常、パフォーマンスは、トレーニング中に勾配の更新を共有するのにかかる時間に大きく依存します。同様に、これはモデルサイズ、勾配サイズ、GPU 仕様、およびネットワーク速度の影響を受けます。
| より良い CPU パフォーマンス | より良い GPU パフォーマンス | |
|
勾配を共有するのに比較的長い時間 (より多くの勾配/より大きなモデルサイズ) |
パラメータサーバー | パラメータサーバー、またはマルチ GPU を備えた単一インスタンス上の Horovod |
|
勾配を共有するのに比較的短い時間 (より少ない勾配/より小さなモデルサイズ) |
パラメータサーバー | Horovod |
複雑さも考慮事項です。パラメータサーバーは、インスタンスごとに 1 つの GPU に使用するのが簡単です。ただし、マルチ GPU インスタンスを使用するには、各タワーを異なる GPU に割り当てて複数のタワーをセットアップする必要があります。「タワー」は、単一のモデルレプリカの推論と勾配を計算するための関数です。これは、完全なデータセットのサブセットに対するモデルトレーニングのコピーです。タワーには、ある形式のデータ並列処理が含まれます。Horovod はデータの並列処理も採用していますが、実装の詳細を抽象化します。
最後に、クラスターサイズによって違いが生じます。多くの GPU を備えた大規模なクラスターでは、パラメータサーバーの全体全の通信がネットワーク帯域幅を圧倒する可能性があります。他の悪影響の中でも、スケーリングの効率が低下する可能性があります。このような状況では、Horovod の方が適している場合があります。
追加の考慮事項
この記事のサンプルコードは、比較的小さな CIFAR-10 データセットを含む 1 つの大きな TFRecord ファイルで構成されています。ただし、特にパイプモードを使用している場合は、大きなデータセットではデータを複数のファイルにシャードする必要があります (次の 2 番目の項目を参照)。シャーディングは、Amazon S3 データソースをマニフェストファイルまたは ShardedByS3Key として指定することで実現できます。また、Amazon SageMaker は、次に示すように、非常に大規模なデータセットに対して分散トレーニングをより効率的にする他の方法を提供します。
- VPC トレーニング: VPC 内で Horovod トレーニングを実行すると、ノード間のネットワークレイテンシーが改善され、Horovod トレーニングジョブのパフォーマンスと安定性が向上します。VPC 内で分散トレーニングを実施する方法については、サンプルノートブック「Amazon SageMaker TensorFlow のスクリプトモードを使用した Horovod 分散トレーニング」を参照してください。
- パイプモード: 大規模なデータセットの場合、パイプモードを使用すると、起動時間とトレーニング時間が短縮されます。パイプモードは、ディスクに保存せずに、トレーニングデータを Amazon S3 からアルゴリズムに (Linux FIFO として) 直接ストリーミングします。Amazon SageMaker の TensorFlow でパイプモードを使用する方法の詳細については、「PipeModeDataset を使用したパイプモードでのトレーニング」を参照してください。
- Amazon FSx for Lustre と Amazon EFS: ファイルモードでの大規模なデータセットのパフォーマンスは、状況によっては Amazon FSx for Lustre または Amazon EFS を使用すると改善される場合があります。詳細については、関連するブログ記事を参照してください。
まとめ
Amazon SageMaker は、分散トレーニングをより迅速かつ簡単に使用できるようにする複数のツールを提供します。パラメータサーバーも Horovod もニーズに合わない場合は、Bring Your Own Container (BYOC) アプローチを使用して、別の分散トレーニングオプションをいつでも指定できます。Amazon SageMaker を使用すると、ユースケースとデータセットに最適なツールを柔軟に組み合わせることができます。
スクリプトモードで Tensorflow 分散トレーニングを開始するには、Amazon SageMaker コンソールにアクセスします。新しい Amazon SageMaker ノートブックインスタンスを作成するか、既存のインスタンスを開きます。次に、このブログ記事で参照した分散トレーニングのサンプルをインポートし、パラメータサーバーオプションと Horovod オプションを比較対照します。
著者について
 Rama Thamman は、AWS R&D およびイノベーションソリューションアーキテクチャチームの R&D マネージャーです。彼はお客様と協業して、スケーラブルなクラウドと AWS ついての機械学習ソリューションを構築しています。
Rama Thamman は、AWS R&D およびイノベーションソリューションアーキテクチャチームの R&D マネージャーです。彼はお客様と協業して、スケーラブルなクラウドと AWS ついての機械学習ソリューションを構築しています。
 Brent Rabowsky は AWS のデータサイエンスに焦点を当てており、彼の専門知識を活用して AWS のお客様がそのデータサイエンスプロジェクトを実行できるようにサポートしています。
Brent Rabowsky は AWS のデータサイエンスに焦点を当てており、彼の専門知識を活用して AWS のお客様がそのデータサイエンスプロジェクトを実行できるようにサポートしています。