Amazon Web Services ブログ
Amazon EC2 C5 インスタンスと BigDL を使用してディープラーニングに低精度と量子化を使用
先日、AWS は最新世代の Intel Xeon Scalable Platinum プロセッサに基づいた大量の演算を行う新しい Amazon EC2 C5 インスタンスをリリースしました。このインスタンスは計算量の多いアプリケーション用に設計されており、C4 インスタンスに比べパフォーマンスを大幅に改善しています。また、vCPU あたりの追加メモリとベクトルおよび浮動小数点ワークロードの 2 倍のパフォーマンスを備えています。
今回のブログでは BigDL という Apache Spark を対象としたオープンソースの分散型ディープラーニングフレームワークが、大規模なディープラーニングのワークロードを大幅に改善する AWS C5 インスタンスの新機能を活用する方法について説明します。特に BigDL が C5 インスタンスを使用してどのように低精度や量子化を活用し、モデルサイズの削減を最大 4 倍に削減そして推論速度を約 2 倍も改善することを実現しているのか説明します。
C5 インスタンスでディープラーニングを使用する理由
新しい AWS C5 インスタンスは Intel Xeon Scalable プロセッサ機能を利用します。これには高頻度のプロセッサでのコア数の増加、高速なシステムメモリ、大きなコア単位の中レベルキャッシュ (MLC または L2 キャッシュ)、新しく幅広い SIMD 命令 (AVX-512) などが含まれています。こうした機能はディープラーニングに関与する数学演算を促進するように設計されているため、新しい C5 インスタンスを大規模なディープラーニングに対し優れたプラットフォームにしています。
BigDL は Intel が開発しオープンソースにした Apache Spark の分散型ディープラーニングフレームワークで、ユーザーが既存の Hadoop/Spark クラスターでディープラーニングアプリケーションの構築と実行を行えるようにします。2016 年 12 月にオープンソースとなってから、BigDL は業界および開発者コミュニティに渡り幅広く採用されてきました (例: Amazon, Microsoft、Cray、Alibaba、JD、MLSlistings、Gigaspaces など)。
BigDL は大規模なビッグデータプラットフォームで実行するように最適化されています。通常、これは分散型 Xeon ベースの Hadoop/Spark クラスターの上に構築されています。Intel Math Kernel Library (MKL) とハイパフォーマンス用のマルチスレッドコンピューティングを利用し、効率的なスケールアウトを実現するために基盤となる Spark フレームワークを使用します。その結果、AWS が提供する新たな C5 インスタンスの機能を効率的に活用することができ、従来のインスタンスファミリーに比べて大幅な速度改善が見られます。
低精度と量子化の活用
C5 インスタンスの使用による本来のパフォーマンス改善の他に BigDL 0.3.0 リリースはモデル量子化のサポートも含んでおり、低精度の計算を使用した推論を可能にしています。AWS から C5 インスタンスで実行した場合、モデルサイズの削減を最大 4 倍そして推論速度を約 2 倍も改善することを実現しています。
モデルの量子化とは?
量子化はオリジナル形式 (例: 32 ビットの浮動小数点) よりコンパクトかつ低精度な形式で数字を保存したり計算を行うテクノロジーの使用を意味する一般的な用語です。BigDL は、このタイプの低精度の計算を活用して推論用にトレーニング済みのモデルを量子化します。様々なフレームワーク (例: BigDL、Caffe、Torch、TensorFlow) でトレーニングした既存のモデルを使用したり、モデルパラメーターの量子化、よりコンパクトな 8 ビット形式を使用したデータ入力を行うことができ、高速な 8 ビット計算に AVX-512 ベクトル命令を適用することができます。
BigDL で量子化はどのように動作するのか?
BigDL はユーザーが BigDL、Caffe、Torch、TensorFlow を使用してトレーニングした既存のモデルを直接ロードできるようにします。モデルのロードが完了すると、BigDL は選択したレイヤーいくつかのパラメーターを 8 ビット整数にして量子化したモデルを生成します。
モデル推論を実行する間、量子化したレイヤーはそれぞれ入力データを動的に 8 ビット整数にし、8 ビット計算 (GEMM など) を適用します。そして量子化したパラメーターやデータを使用し、その結果を逆量子化して 32 ビットの浮動小数点にします。こうしたオペレーションの多くは実装で結合することができ、結果として量子化と逆量子化のオーバーヘッドの推論時間が大幅に低下しています。
大方の既存の実装とは異なり、BigDL はローカル量子化スキームを使用してモデルの量子化を行います。つまり、パラメーターまたは入力データの小さなサブブロック (パッチまたはカーネルなど) といった小さいローカル量子化で、量子化と逆量子化のオペレーションを実行します。結果として、BigDL はモデル量子化で 8 ビットのような非常にビット数の低い整数を使用してモデル精度性の低下をきわめて抑えた状態 (0.1% 以下) にすることができ、素晴らしい効率性を達成しています。ブログ後半にリストした実際のベンチマーク設定の詳細を示した図をご覧ください。
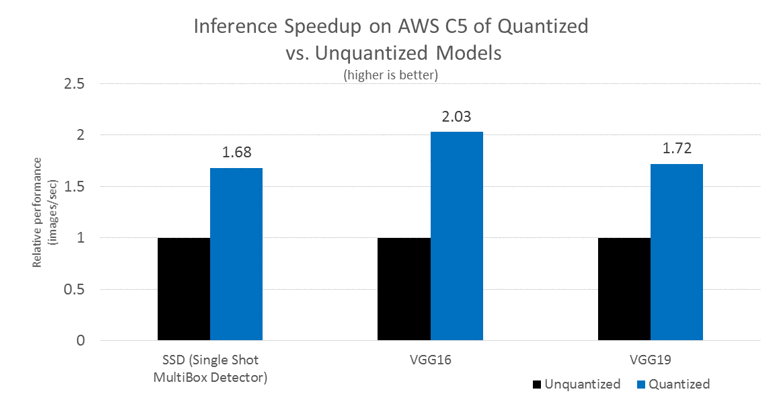
C5 推論スピードアップ: 相対値パフォーマンス (量子化 vs. 逆量子化モデル) – BigDL で量子化を使用、1.69~2.04x 推論のスピードアップ
C5 の 推論の正確性: (量子化 vs. 逆量子化モデル) – BigDL で量子化を使用、正確性の低下 0.1% 以下

モデルサイズ (量子化 vs. 逆量子化モデル) – BigDL で量子化を使用、モデルサイズ ~3.9 倍の削減

BigDL で量子化を使用する
BigDL でモデルを量子化するには、まず次のように既存のモデルをロードします (Caffe サポートや TensorFlow サポートの詳細については BigDL ドキュメントを参照してください)。
この後、モデルを量子化して次のように推論で使用することができます。
また、BigDL はトレーニング済みのモデルを量子化したモデルに変換するためのコマンドラインツール (ConvertModel) も提供しています。モデル量子化サポートの詳細については BigDL ドキュメントをご覧ください。
ぜひご自分でお試しください。
- 今すぐ AWS で BigDL を使い始めるには AWS Marketplace にアクセスしてください。
- BigDL とモデル量子化の詳細についてはこちらをご覧ください。
- Amazon EMR で BigDL を実行するには、過去のブログ記事「Apache Spark のディープラーニング、BigDL を AWS で実行 (Running BigDL, Deep Learning for Apache Spark, on AWS)」をご覧ください。
ベンチマーク設定の詳細:
| ベンチマークタイプ | 推論 |
| ベンチマークメトリックス | Images/Sec |
| フレームワーク | BigDL |
| トポロジー | SSD、VGG16、VGG19 |
| ノード数 | 1 |
| Amazon EC2 インスタンス | C5.18xlarge |
| ソケット | 2S |
| プロセッサ | “Skylake” 生成 |
| 有効にしたコア | 36c (c5.18xlarge) |
| メモリ合計 | 144 GB (c5.18xlarge) |
| ストレージ | EBS 最適化した GP2 |
| OS | RHEL 7.4 3.10.0-693.el7.x86_64 |
| HT | ON |
| Turbo | ON |
| コンピュータタイプ | サーバー |
| フレームワークバージョン | https://github.com/intel-analytics/BigDL |
| データセット、バージョン | COCO、Pascal VOC、Imagenet-2012 |
| パフォーマンスコマンド | images/sec で計測した推論スループット |
| データセットアップ | データはローカルストレージに保存され、トレーニング前にメモリでキャッシュされました |
| Oracle Java | 1.8.0_111 |
| Apache Hadoop | 2.7.3 |
| Apache Spark | 2.1.1 |
| BigDL | 0.3.0 |
| Apache Maven | 3.3.9 |
| Protobuf | 2.5 |
最適化の注意: Intel のコンパイラーは Intel マイクロプロセッサ特有ではない場合の最適化において、Intel 以外のマイクロプロセッサを同じ度合で最適化しない場合があります。これには SSE2、SSE3、SSSE3 命令のセットとその他の最適化も含まれます。Intel は Intel が製造していないマイクロプロセッサで行う最適化において可用性、機能性または有効性を保証していません。この製品におけるマイクロプロセッサに依存する最適化は Intel マイクロプロセッサで使用する場合を対象としています。Intel マイクロアーキテクチャ特有ではない一定の最適化は Intel マイクロプロセッサにリザーブドされています。同注意で触れた内容に関する特定の手順詳細については、該当製品のユーザーとリファレンスガイドをご覧ください。
Intel、Intel ロゴ、Xeon は米国および/またはその他の国における Intel Corporation の商標です。
今回のブログの投稿者について
Jason Dai 氏は Intel ビッグデータテクノロジーのシニアプリンシパルエンジニア兼チーフアーキテクトです。
Joseph Spisak 氏は、人工知能と機械学習に主眼を置いた AWS のパートナーエコシステムチームのリーダーです。