Amazon Web Services ブログ
Apache Airflow、Genie、および Amazon EMR でビッグデータワークフローのオーケストレーションを行う: Part 1
AWS 上でビッグデータの ETL ワークフローを実行している大企業は、多数の内部エンドユーザーにサービスを提供できるようなスケールで運用しており、何千もの同時パイプラインを実行しています。このことは、新しいフレームワークと、ビッグデータ処理フレームワークの最新のリリースに遅れずについていくため、ビッグデータプラットフォームを更新し、拡張する点での継続的なニーズと相まって、ビッグデータプラットフォームの管理を簡素化することと、ビッグデータアプリケーションへの容易なアクセスを促すことの両方を可能にする、効率的なアーキテクチャと組織構造を要求しています。
この投稿では、一元管理型のプラットフォームチームが、幾千もの同時 ETL ワークフローへのサービスを提供するビッグデータプラットフォームを維持するのを助け、そのことを達成するために必要な運用タスクを簡素化するアーキテクチャについて紹介します。
アーキテクチャコンポーネント
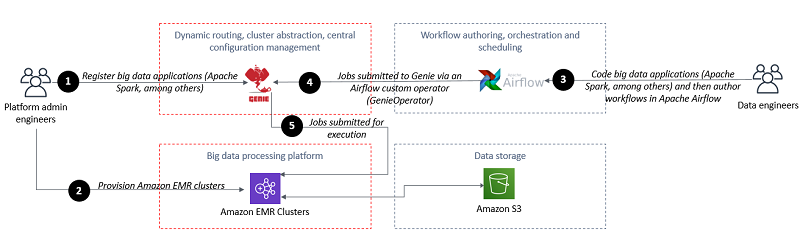
高いレベルにおいては、このアーキテクチャは、ビッグデータプラットフォームに ETL ワークフローのオーサリング、オーケストレーション、そして実行能力を提供するため、Amazon EMR と関連した 2 つのオープンソーステクノロジーを利用しています。Genie は、同時ビッグデータジョブの送信、動的なジョブのルーティング、中央設定管理、そして Amazon EMR クラスタの抽象化のための集中管理型 REST API を提供します。Apache Airflow は、複雑なデータパイプラインのオーサリング、スケジュールおよびモニタをプログラム的に行うことを可能にする、ジョブオーケストレーションのためのプラットフォームを提供します。Amazon EMR は、Apache Hadoop、Apache Spark、および他のビッグデータフレームワークの実行とスケーリングを可能にする、マネージドクラスタプラットフォームを提供します。
次の図は、アーキテクチャを示しています。
Apache Airflow
Apache Airflow は、ビッグデータワークフローのオーサリングとオーケストレーションのためのオープンソースツールです。
Apache Airflow を使えば、データエンジニアは有向非巡回グラフ (DAG) を定義できます。DAG はワークフローを実行する方法を記述するもので、Python で書かれています。ワーフローは、独立して実行されるタスクをグループ化する DAG としてデザインされます。DAG はタスク間の関連性と依存関係を追跡します。
演算子は、ワークフロー内の単一タスクを定義するテンプレートを定義します。Airflow は一般的なタスクのための演算子を提供します。また、ユーザーはカスタムの演算子を定義することもできます。この投稿では、タスクを Genie に送信するためのカスタム演算子 (GenieOperator) について説明します。
タスクは、演算子のパラメータ化されたインスタンスです。演算子はインスタンス化されるとタスクと呼ばれます。タスクインスタンスは、タスクの特定の実行を表します。タスクには、関連付けられている DAG、タスク、および特定の時点があります。
DAG とタスクは、オンデマンドで実行することも、DAG の cron 式で定義された特定の時間に実行されるようスケジュールすることもできます。
Apache Airflow の詳細については、Apache Airflow のドキュメントのコンセプトを参照してください。
Genie
Genie は Netflix によるオープンソースツールで、基礎となる Amazon EMR クラスタへのアクセスを抽象化することにより、設定管理機能と動的なジョブのルーティングを実現しています。
Genie は、Apache Hadoop MapReduce や Apache Spark などのビッグデータアプリケーションからジョブを送信するための REST API を提供します。Genie は基礎となるクラスタのメタデータ、およびクラスタ内で実行されるコマンドとアプリケーションを管理します。
Genie はクラスタに 1 つ以上のタグを関連付けることにより、クラスタの処理へのアクセスを抽象化します。また、ビッグデータフレームワークがサポートしているアプリケーションやコマンドのメタデータの詳細にタグを関連付けることもできます。Genie は特定のタグに対するジョブの送信を受け取ると、クラスタとコマンドのタグの組み合わせを基に、それぞれのジョブを動的に正しい EMR クラスタにルーティングします。
Genie のデータモデル
Genie はビッグデータ環境のリソースに関連付けられたメタデータをキャプチャするためのデータモデルを提供します。
アプリケーションのリソースとは、ジョブをクラスタに送信する Genie のノード上のビッグデータプラットフォームでサポートされるアプリケーションのインストールと設定を行うための、再利用が可能なバイナリ、設定ファイル、セットアップファイルのことです。Genie がジョブを受け取ると、Genie のノードはアプリケーションに関連付けられたすべての依存関係、設定ファイル、およびセットアップファイルをダウンロードして、それをジョブの作業ディレクトリに保存します。アプリケーションはコマンドにリンクされます。それらはコマンドの実行の前に必要とされるバイナリと設定を表しているからです。
コマンドリソースは、コマンドラインを使用して作業をクラスタに送信するときの、またコマンドを実行するのにどのアプリケーションが PATH 環境変数で利用可能になっている必要があるかを示すパラメータです。コマンドリソースは、メタデータコンポーネントを相互に結びつける接着剤と言えます。たとえば、Hive コマンドを表すコマンドリソースは、hive-site.xml を含んでおり、コマンドを実行するのに必要な Hive および Hadoop のバイナリを提供する、アプリケーションリソースのセットと関連付けられます。さらに、コマンドリソースは、それが実行可能であるクラスタにリンクされます。
クラスタリソースは実行クラスタの詳細を特定します。これには接続の詳細、クラスタのステータス、タグ、および付加的なプロパティが含まれます。クラスタリソースは、開始時に Genie に登録することができ、終了時には自動的に登録解除します。クラスタは、その上で実行できる 1 つ以上のコマンドにリンクされます。コマンドがクラスタにリンクされると、Genie はクラスタへのジョブの送信を開始できます。
最後に、ジョブリソースのタイプは 3 種類あります。ジョブリクエスト、ジョブ、そしてジョブ実行です。ジョブリクエストリソースは、ジョブを実行するための詳細を伴う、送信のリクエストを表します。ジョブリクエストは、リクエスト内で送信されたパラメータに基づいて作成されます。ジョブリソースは、コマンド、クラスタ、ジョブに関連付けられたアプリケーションなどの詳細をキャプチャします。加えて、ジョブリソースでは、ステータス、開始時刻、および終了時刻も利用可能です。ジョブ実行リソースは管理上の詳細を提供するので、ジョブがどこで実行されるのかを理解できます。
詳細については、Genie リファレンスガイドのデータモデルを参照してください。
Amazon EMR と Amazon S3
Amazon EMR は、AWS 上で Apache Hadoop および Apache Spark などのビッグデータフレームワークの実行をシンプル化するマネージドクラスタプラットフォームで、膨大な量のデータの処理と分析を行えるようにします。詳細については、Amazon EMR アーキテクチャの概要およびAmazon EMR の概要を参照してください。
データは、スケーラブルなパフォーマンスを発揮でき、使いやすい特徴を備え、ネイティブ暗号化とアクセスコントロールの機能を持つオブジェクトストレージサービスである Amazon S3 に保存されます。S3 の詳細については、データレイクストレージプラットフォームとしての Amazon S3 (英語) を参照してください。
アーキテクチャの深い探求
このアーキテクチャと深い関わりがある 2 つの職種は、プラットフォーム管理エンジニアとデータエンジニアです。
プラットフォーム管理エンジニアは、すべてのコンポーネントに対する管理者アクセス権を持っています。そのため、クラスタの追加や削除、プラットフォームがサポートするアプリケーションやコマンドの設定を行えます。
データエンジニアは、自分が好むフレームワーク (Apache Spark、Apache Hadoop MR、Apache Sqoop、Apache Hive、Apache Pig、および Presto) でビッグデータアプリケーションを書くこと、そして DAG を表す python スクリプトのオーサリングに集中しています。
高いレベルでは、プラットフォーム管理エンジニアのチームは、サポートされているビッグデータアプリケーションとその依存関係の準備をし、それらを Genie に登録します。プラットフォーム管理エンジニアのチームは、Amazon EMR クラスタを立ち上げ、起動時に Genie に登録します。
プラットフォーム管理エンジニアのチームは、それぞれの Genie メタデータリソース (アプリケーション、コマンド、およびクラスタ) を、Genie のタグと関連付けます。たとえば、クラスタのリソースを、名前が environment で、値が “Production Environment”、“Test Environment”、または “Development Environment” であるタグと関連付けることができます。
データエンジニアはワークフローを Airflow DAG としてそのオーサリングを行い、カスタムの Airflow Operator である GenieOperator を使用して、タスクを Genie に送信します。彼らはタグの組み合わせを用いて、自分たちが実行しているタスクのタイプと、加えてタスクをどこで実行するかを識別します。例えば、“Production Environment” タグにより識別される環境で、Apache Spark 2.4.3 を実行する必要があるとしましょう。そのためには、次のコードのように、Airflow GenieOperator で、クラスタとコマンドのタグを設定します。
(cluster_tags=['emr.cluster.environment:production'],command_tags=['type:spark-submit','ver:2.4.3'])
次の図は、このアーキテクチャを示しています。
この図の番号と対応しているワークフローは次のとおりです。
- プラットフォーム管理エンジニアは、サポートされているアプリケーション (Spark-2.4.5、Spark-2.1.0、Hive-2.3.5 など) のバイナリと依存関係の準備を行います。プラットフォーム管理エンジニアは、コマンド (spark-submit, hive) の準備も行います。プラットフォーム管理エンジニアは、アプリケーションとコマンドを Genie に登録します。さらに、プラットフォーム管理エンジニアは、コマンドとアプリケーションを関連付け、ステップ 2 (下記) が完了すると、コマンドをクラスタのセットにリンクします。
- Amazon EMR クラスタは、スタートアップ時に Genie に登録します。
- データエンジニアは Airflow DAG のオーサリングを行い、Genie のタグを用いて、環境、アプリケーション、コマンドまたはそれらの任意の組み合わせを参照します。ワークフローのコードで、データエンジニアは GenieOperator を使用します。GenieOperator はジョブを Genie に送信します。
- ワークフローの実行は、スケジュールによってトリガされます。または、データエンジニアが手動でワークフローの実行をトリガします。ワークフローを構成するジョブは Genie に送信され、ジョブをどこで実行するかを指定する Genie タグのセットを基にして実行されます。
- クライアントのゲートウェイとして動作する Genie のノードは、作業ディレクトリを設定し、すべてのバイナリと依存関係をそこに設定します。Genie は、提供された Genie タグと関連付けられているクラスタに、ジョブを動的にルーティングします。Amazon EMR クラスタがジョブを実行します。
Apache Airflow と Genie によってサポートされている承認と認証の機構の詳細については、Apache Airflow の文書の セキュリティ と、Genie の文書の セキュリティ を参照してください。 このアーキテクチャパターンにより、Amazon EMR クラスタへの SSH アクセスは公開されません。EMR ファイルシステム (EMRFS) を経由して Amazon S3 のデータにアクセスするいくつかのレベルの詳細については、Amazon S3 への EMRFS リクエストの IAM ロールを設定するを参照してください。
このアーキテクチャが可能にするユースケース
以下のユースケースは、このアーキテクチャが提供する機能を実証しています。
ダウンタイムなしでアップグレードとデプロイを管理し、最新のオープンソースのリリースを採用する
大規模な組織においては、データプラットフォームを使用しているチームは、異種フレームワークと、異なるバージョンを使用しています。このアーキテクチャを使用すれば、ダウンタイムなしでアップグレードをサポートし、短時間でオープンソースフレームワークの最新バージョンを提供できます。
Genie と Amazon EMR が、このユースケースを可能にする主要なコンポーネントです。Amazon EMR のサービスチームは、短いリリースサイクルで Amazon EMR 上で動作するオープンソースフレームワークの最新バージョンを追加できるように努力しているので、ユーザーは、自社の内部チームのニーズである、自分が好むオープンソースフレームワークの最新機能への要求に応え続けることができています。
オープンソースフレームワークの新しいバージョンが利用できるようになると、ユーザーはそれをテストし、新しいサポートバージョンとその依存関係を Genie に追加して、古いクラスタ内のタグを新しいクラスタに移動することが必要になります。新しいクラスタが新たなジョブ送信を受け付け、古いクラスタはまだ実行されていたジョブを終了させます。
さらに、Genie はアプリケーションバイナリとその依存関係の保管場所を一元化するので、Genie でバイナリと依存関係をアップグレードすると、アップストリームのクライアントも自動的にアップグレードされます。Genie を使用すれば、アップストリームのクライアントすべてをアップグレードする必要はなくなります。
一元化された設定、ジョブおよびクラスタのステータス、そしてロギングを管理
数千ものジョブと複数のクラスタから構成される世界において、ユーザーは、特定のジョブがどこで実行されているかを識別し、ロギングの詳細に素早くアクセスする事が必要です。このアーキテクチャにより、データプラットフォーム上のジョブが実行されている場所、ジョブのロギング、クラスタ、およびその設定に対する見通しがよくなります。
ビッグデータプラットフォームにプログラム的にアクセスする
このアーキテクチャは、Genie の REST API に基づいて、ジョブの送信場所を 1 箇所にまとめることを可能にします。基礎となっているクラスタへのアクセスは、管理タスクに加えてクラスタへのジョブ送信を可能にする、一連の API を通じて抽象化されます。ある REST API 呼び出しが、Genie へのジョブ送信を非同期的に行います。受け付けられると、ジョブ ID が返されるので、それを用いてジョブのステータスを取得し、API またはウェブ UI を通じてプログラム的に出力することが可能になります。Genie ノードは、作業ディレクトリを設定し、ジョブを個別のプロセスで実行します。
また、このアーキテクチャを、ビッグデータアプリケーションと、Apache Airflow DAG のために、継続的インテグレーションと継続的デリバリー (CI/CD) のパイプラインに統合することができます。
スケーラブルなクライアントゲートウェイと同時ジョブ送信を可能にする
Genie のノードはクライアントゲートウェイ (エッジノード) として動作し、水平スケーリングにより、ジョブをデータプラットフォームに送信するために用いられるクライアントゲートウェイのリソースが、要求を満たせるようにします。さらに、Genie は同時ジョブ送信も可能にします。
このアーキテクチャをいつ使用するか
このアーキテクチャは、一時的クラスタの代わりに、複数の大規模な、マルチテナントの処理クラスタを使用している組織に推奨されます。組織がいつ、常時稼働のクラスタと一時的クラスタのどちらがよいかを考慮するべきかについて説明することは、この投稿の範囲を超えています (EMR Airflow Operator を使用して、Amazon EMR クラスタを立ち上げ、Genie への登録、ジョブの実行、そしてそれらの分割を行わせることができます)。このアーキテクチャでは、リザーブドインスタンスを使用するべきです。詳細については、リザーブドインスタンスを使用するを参照してください。
このアーキテクチャは、数千のジョブを同時に実行することが必要な多くの内部チームをサポートしていて、ビッグデータプラットフォームを管理し、維持するために、中央プラットフォームチームを設けることを選択した組織に特に推奨されます。
このアーキテクチャは、そこまで大きくない組織や、そのようなスケールで成長することを予期していない組織にとっては、意味がないでしょう。クラスタの抽象化と、一元化設定管理がもたらすメリットは、数千の同時ワークフローと数百のチームが存在する、無秩序になりかねない環境で構造化されたアクセスを可能にするという点で、理想的なものです。
このアーキテクチャはまた、数時間かかる、または互いに重なっているワークフローが高い割合で存在していて、それらとともに異種フレームワーク (Apache Spark、Apache Hive、Apache Pig、 Apache Hadoop MapReduce、Apache Sqoop、または Presto) をサポートしている組織に推奨されます。
組織が Apache Spark だけに依存していて、上記で説明した推奨事項に従っている場合にも、このアーキテクチャはやはり当てはまるでしょう。ジョブの送信、クラスタの抽象化、動的ジョブルーティング、または一元化設定管理のための一元化 REST API の必要性を正当化するだけのスケールのない組織の場合には、Apache Livy に Amazon EMR を加えたものが適切なオプションになるかもしれません。Genie には独自のスケーラブルなインフラストラクチャがあり、エッジクライアントのように動作します。このことは、Genie は Amazon EMR マスターインスタンスリソースの競合とはならないのに対し、Apache Livy は競合となることを意味しています。
組織のワークフローの大部分が、数が少なく、短命なジョブであるなら、サーバーレスの処理レイヤー、サーバーレスのアドホッククエリレイヤーを選択するか、またはワークフローごとに専用の一時 Amazon EMR クラスタを使用するのがより適切かもしれません。組織のワークフローの大部分が、数千の短命なジョブから構成されている場合も、このアーキテクチャはやはり当てはまります。クラスタの立ち上げと終了の必要がなくなるからです。
このアーキテクチャは、コンポーネントのパフォーマンスを最適化するため、処理プラットフォームのフルコントロールを求める組織にも推奨されます。さらに、このアーキテクチャは、CI/CD パイプラインを通し、そのワークフローで一元化されたガバナンスを施行する必要のある組織にも推奨されます。
異なるオーケストレーションオプションを評価することや、Airflow をオーケストレーションレイヤーとして採用することのメリットを説明することは、この投稿の範囲を超えています。アーキテクチャを採用することを考慮する場合には、既存のスキルセットと、ツールを採用するための時間も考慮してください。Genie のオープンソースとしての性質は、他のオーケストレーションツールとの統合を許すかもしれません。このアーキテクチャを別のオーケストレーションツールとともに採用することが望ましければ、そのルートを評価することもオプションとなるでしょう。
まとめ
この投稿では、Apache Airflow、Genie、および Amazon EMR を使用して、ビッグデータワークフローを管理する方法について説明しました。アーキテクチャコンポーネント、アーキテクチャがサポートするユースケース、およびいつそれを使うかについても取り上げました。投稿の第 2 部では、デモ環境をデプロイして、Genie を設定し、Apache Airflow のために GenieOperator を使用するためのステップを案内します。
著者について
 Francisco Oliveira は、AWS のシニアビッグデータソリューションアーキテクトです。オープンソーステクノロジーと AWS を使用したビッグデータソリューションの構築に力を注いでいます。余暇には、新しいスポーツに挑戦したり、旅行や国立公園に出かけたりします。
Francisco Oliveira は、AWS のシニアビッグデータソリューションアーキテクトです。オープンソーステクノロジーと AWS を使用したビッグデータソリューションの構築に力を注いでいます。余暇には、新しいスポーツに挑戦したり、旅行や国立公園に出かけたりします。
 Jelez Raditchkov は AWS のプラクティスマネージャです。
Jelez Raditchkov は AWS のプラクティスマネージャです。