Amazon Web Services ブログ
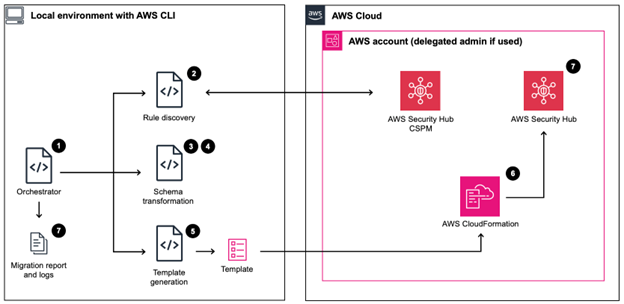
Security Hub CSPM から Security Hub への自動化ルール移行ガイド
AWS Security Hub の新バージョンでは OCSF スキーマが採用され、旧バージョン (Security Hub CSPM) の ASFF ベースの自動化ルールを移行する必要があります。この記事では、既存の自動化ルールを自動的に検出し、OCSF スキーマに変換し、AWS CloudFormation テンプレートを生成する移行ソリューションを紹介します。ホームリージョンモードとリージョン別モードの 2 つのデプロイオプションをサポートし、ルールの順序も維持されます。

Amazon Inspector がトークンファーミングキャンペーンに関連する 15 万件以上の悪意ある npm パッケージを検出
Amazon Inspector のセキュリティリサーチャーが、npm レジストリにおいて tea.xyz トークンファーミングキャンペーンに関連する 15 万件以上の悪意あるパッケージを発見しました。これはオープンソースレジストリ史上最大規模のパッケージフラッディングインシデントの 1 つです。AI とルールベースの検出を組み合わせた手法により、脅威アクターが暗号通貨報酬を得るために自動生成したパッケージを特定し、OpenSSF との迅速な連携で対応を実現しました。

月刊AWS製造 2026年1月号
3号目となった月間 AWS 製造ブログでは、re:Invent 2025 の注目セッションを中心に、re:Invent 特集としてお届けします。先月号はこちらです。未読の方はあわせてご覧ください。
このブログでは開催予定のイベントや直近1カ月に発表された製造関連のブログ・サービスのアップデート・事例などをお届けしています。国内だけでなく海外の情報も含めていますので、リンク先には英語の記事・動画も含まれていますが、解説を加えていますのでご興味あればぜひご覧ください。

プロパティベーステストが見つけた、私が決して発見できなかったセキュリティバグ
本記事では、Kiro の仕様駆動開発ワークフローを使用したチャットアプリケーション開発において、プロパティベーステスト(PBT)が従来のテスト手法では発見困難なセキュリティバグをどのように発見したかをお伝えします。75 回目のテスト反復で __proto__ というプロバイダー名が JavaScript プロトタイプの誤った処理を露呈し、ランダム生成による体系的な入力空間の探索が、手動コードレビューや単体テストでは見逃されるエッジケースを効果的に発見できることを実例とともに紹介します。

Kiro のマルチルートワークスペース:1 つのプロジェクト内だけでなく、複数のプロジェクトにまたがって作業する
本記事では、Kiro の新しいマルチルートワークスペース機能により、複数のプロジェクトを単一の IDE ウィンドウで効率的に管理する方法をお伝えします。共有ライブラリとメインアプリケーション、複数のマイクロサービス、モノレポのパッケージなど、関連するプロジェクトを同時に編集する際の課題を解決し、各ルートが独立性を保ちながら統合された開発環境を提供する仕組みと、その設定方法や実際の活用例を詳しく説明します。
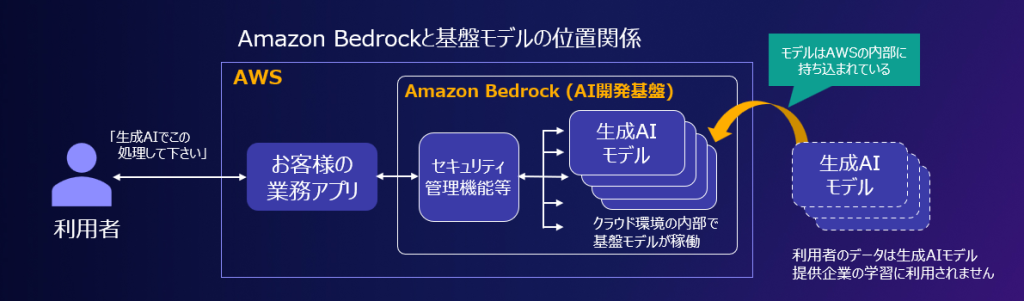
Amazon Bedrock は ISMAP の言明対象であることについての考え方
はじめに ISMAP ポータルサイトに、「生成AIサービスに関する留意点について」が追加されていますが、その内 […]
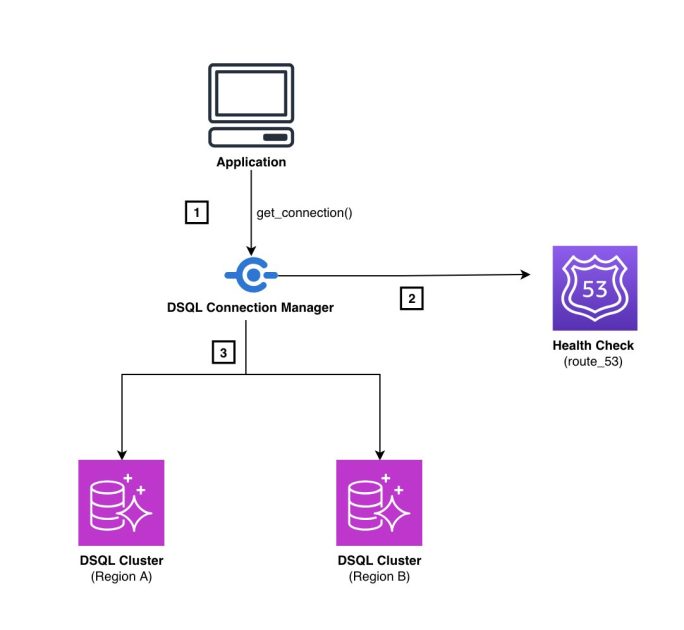
Amazon Aurora DSQL のマルチリージョンエンドポイントルーティングを実装する
Amazon Aurora DSQL のマルチリージョンクラスターにおいて、Route 53 ヘルスチェックとクライアント側レイテンシー測定を組み合わせた自動エンドポイントルーティングソリューションを実装する方法を紹介します。リージョナルエンドポイント障害時に自動的に正常なエンドポイントへフェイルオーバーし、アプリケーションの継続的なデータベースアクセスを実現します。

IAM Policy Autopilot: ビルダーと AI コーディングアシスタントに IAM ポリシーの専門知識を提供するオープンソースツール
AWS は IAM Policy Autopilot を発表しました。これは AI コーディングアシスタントがベースラインとなる IAM ポリシーを迅速に作成できるよう支援するオープンソースの静的解析ツールです。アプリケーションコードをローカルで解析し、AWS SDK 呼び出しに基づいてアイデンティティベースポリシーを生成します。MCP サーバーまたは CLI として利用でき、Kiro、Amazon Q Developer、Cursor などの AI コーディングアシスタントと統合可能です。クロスサービス依存関係も理解し、Access Denied エラーのトラブルシューティングも支援します。

サプライチェーン攻撃への防御策: Chalk/Debug 侵害と Shai-Hulud ワームの対応事例から
npm パッケージの Chalk/Debug 侵害と Shai-Hulud ワームという 2 つのサプライチェーン攻撃事例を解説します。これらの攻撃は、オープンソースパッケージレジストリの信頼チェーンを悪用し、何百万ものシステムに影響を与える可能性がありました。インシデント対応の手順として、依存関係の監査、シークレットのローテーション、ビルドパイプラインの確認、Amazon Inspector による検出、SBOM の適用などを紹介します。また、AWS が OpenSSF と連携して脅威インテリジェンスを共有し、コミュニティ全体のセキュリティ向上に貢献している取り組みについても説明します。

標準 JDBC ドライバーで AWS Advanced JDBC Wrapper を使い Amazon Aurora の高度な機能を活用する
本記事では、AWS Advanced JDBC Wrapper を使って標準 JDBC ドライバーに Amazon Aurora の高速フェイルオーバーや読み取り/書き込み分離などのクラウド機能を追加する方法を紹介します。最小限のコード変更で、既存の Java アプリケーションを段階的に拡張する手順を解説します。